






本文供个人电脑安装hadoop学习使用,系统:Windows,版本:hadoop-2.7.7
1 前提:
已安装Java并配好环境变量,注意Java的安装位置不要有空格,否则可能hadoop-env.cmd会找不到对应的JAVA_HOME。如非要安装在Program Files目录下,写JAVA_HOME时可尝试用双引号将Program Files引起来,或者使用progra~1替换该部分。
Java安装过程分两次进行。第一次安装的是jdk,第二次安装的是jre(jre可以不用安装,不过建议都进行安装) https://www.bilibili.com/read/cv17946643/
2 下载安装包 hadoop-2.7.7.tar.gz 来源:
https://archive.apache.org/dist/hadoop/common/
或从 https://hadoop.apache.org/release/ 也可。
3 使用tar命令解压hadoop-2.7.7.tar.gz
tar zxvf hadoop-2.7.7.tar.gz (使用管理员身份运行cmd可以避免解压末尾的退出提示tar: Error exit delayed from previous errors.)
4 安装必要插件winutils-master
由于hadoop原本是运行在Linux上的,如需要运行在Windows上,需要下载Winutils-master https://github.com/cdarlint/winutils (建议到github下载,不要使用程序员提供的中转跳转到gitlab。点击code按钮选择download zip即可)
5 替换
解压winutils-master.zip,选择相应版本,将其bin文件夹替换hadoop-2.7.7\bin 文件夹
(注:上述3,4,5三个步骤可合并到一个步骤里,即直接下载已经替换过的安装包。新手建议使用合并方案,这篇文章提供的百度网盘压缩包是已经替换过的: https://blog.csdn.net/qq_40919128/article/details/125777002)
6 配置环境变量:
将hadoop-2.7.7文件夹剪切复制到合适位置(如直接放在c盘根目录下)再根据这个位置配置hadoop的系统变量和环境变量。建议将sbin目录也加到path中,这样可以不再需要在sbin目录下才能运行hadoop命令:
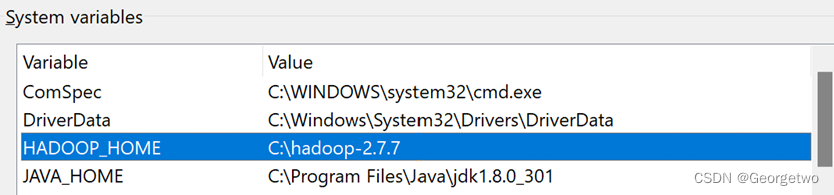

7 运行hadoop version查看是否安装好
如出现JAVA_HOME is incorrectly set. Please update hadoop-env.cmd 大概率是因为JAVA_HOME路径有空格,可以修改该文件配置(具体可查看网上资料),本人选择重装Java,不使用默认路径Program Files。
8 移动hadoop.dll文件
将C:\hadoop-2.7.7\bin\hadoop.dll剪切复制到C:\hadoop-2.7.7\sbin以及C:\Windows\System32这两个目录下(不知道这样做的的作用,有文章提到,故从大多数)
9 按如下路径创建文件夹,接下来修改配置文件时要用
C:\hadoop-2.7.7\data\dfs\datanode
C:\hadoop-2.7.7\data\dfs\namenode
10 修改如下四个文件
有的版本在conf\这个目录下,2.7.7版本在etc\目录下
有可能也需要修改hadoop-env.cmd,兹不赘述。
10.1) core-site.xml 其中的localhost可用0.0.0.0或127.0.0.1替换,端口50050要注意不被占用,可使用其它端口号(检查端口号使用情况命令:netstat -ano |findstr “post_number”)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:50050</value>
</property>
</configuration>
10.2)hdfs-site.xml 有些版本在路径前加上file:/ ,本人安装hadoop-2.7.7没有这样做,也可成功
<configuration>
<property>
<name>dfs.replication</name>
<!-- value 1,because it is single hadoop -->
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- Create the directory before use it -->
<value>/C:/hadoop-2.7.7/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!-- Create the directory before use it -->
<value>/C:/hadoop-2.7.7/data/dfs/datanode</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
10.3)mapred-site.xml (如果是mapred-site.xml.template则把.template后缀去掉)同样,端口号可改
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:50051</value>
</property>
</configuration>
10.4)yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
附:2.7.7版本的配置文件官网文档入口,可从中获得更多配置说明: https://hadoop.apache.org/docs/r2.7.7/
11 初始化namenode
运行 hdfs namenode -format
如果多次格式化,需要看一看data、tmp和logs目录,每次格式化时最好把他们删掉,避免出现一些ClusterId之类的问题,如出现此类问题,可以从头再来一遍。
自白:由于我删掉了配置的tmp文件,重新初始化后C:\hadoop-2.7.7\tmp\hadoop-15276\dfs\data\current目录下面不再有version文件记录datanode的clusterid, 导致后面一系列问题。
12 启动hadoop,运行start-all.cmd报错
RuntimeException: Error while running command to get file permissions : ExitCodeException exitCode=-1073741515
参考 https://blog.csdn.net/qq_45503559/article/details/102965422 ,这可能是Hadoop中bin目录下的winutils.exe缺少依赖msvcr100.dll造成,可以直接下载该文件再粘贴到C:\Windows\System32即可。但是网上关于这个组件的下载资源不好找,可使用下列链接直接下载
vcredist_x64.exe ,然后点击运行,即可在该目录下找到msvcr100.dll
https://www.microsoft.com/en-us/download/details.aspx?id=26999 (亲测有效)
https://learn.microsoft.com/zh-CN/cpp/windows/latest-supported-vc-redist?view=msvc-170#visual-studio-2015-2017-2019-and-2022 (备用)
下载后直接运行vcredist_x64.exe可修复 msvcr100.dll缺失问题
安装完毕再次运行start-all.cmd,登录50070Web UI下面什么也没有(有的文章截图中该Web UI有文件上传、删除按钮,但是本人安装后并没有发现对应按钮,可能是版本或者问题,希望有读者指出原因)

注:使用一段时间后,如果有MapReduce作业,会在根目录下生成一个tmp文件夹:
HDFS下/tmp目录的作用:
HDFS下的/tmp目录主要用作mapreduce操作期间的临时存储,如staging、个人目录、hdfs、root目录。 MapReduce工作产生的中间临时数据等将保存在该目录下。MapReduce作业执行完成后,这些文件将自动清除。
如果删除此临时文件,则可能会影响当前正在运行的mapreduce作业
引自:https://blog.csdn.net/liuwei0376/article/details/120739973
附:常用命令 :
启动/关闭hadoop: (sbin目录下)start-all.cmd / stop-all.cmd
查看安全模式: hdfs dfsadmin -safemode get
查看文件夹:hadoop fs -ls / (没有文件夹时返回Error: Could not find or load main class fs)
创建文件夹: hadoop fs -mkdir /zzt
删除文件夹:hadoop fs -rm -r -skipTrash /zzt (-r,recursive,表示递归删除子目录,在文件夹非空时需要加上此参数)
上传文件到指定目录: hadoop fs -put C:\Users\15276\Desktop\cpi.csv /zzt
下载文件到本地:hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./














 2660
2660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









