







一、前言
现如今大数据越来越进入普通程序员的工作了,稍微大点的公司,很多都开始做大数据分析和使用了。作为一名java程序员,由今天起开始大数据的进阶之路,后续慢慢出一些文章,敬请期待…
PS: 网路上的大数据学习路线:
java->linux->shell->hadoop->hive->kafka->hbase->spark->fink
后续也会慢慢按照这个路线进行。本期先从Hadoop开始。
二、Hadoop的用途
举个简单的例子,假如你有一个程序,每天处理10M数据,10M数据很快解决了,但后面数据量一上来,处理10G甚至10T的内容,那你程序肯定受不了了,这个时候你想的是如何将这些数据分摊计算,短时间内处理这些大量数据,那Hadoop是你较好的选择,其实,
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布
式分析应用的开源框架,其核心部件是HDFS与MapReduce.(稍微理解下即可)
三、Hadoop能干什么
大数据存储:分布式存储
日志处理:擅长日志分析
ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
机器学习: 比如Apache Mahout项目
搜索引擎:Hadoop + lucene
实现数据挖掘:目前比较流行的广告推荐,个性化广告
推荐Hadoop是专为离线和大规模数据分析而设计的,
并不适合那种对几个记录随机读写的在线事务处理模式。
四、Hadoop Windows配置
4.1下载地址
最新版本 http://hadoop.apache.org/releases.html
历史版本:https://archive.apache.org/dist/hadoop/common/
本文使用2.8.3版本,推荐从历史版本去找 直达连接点击跳转。
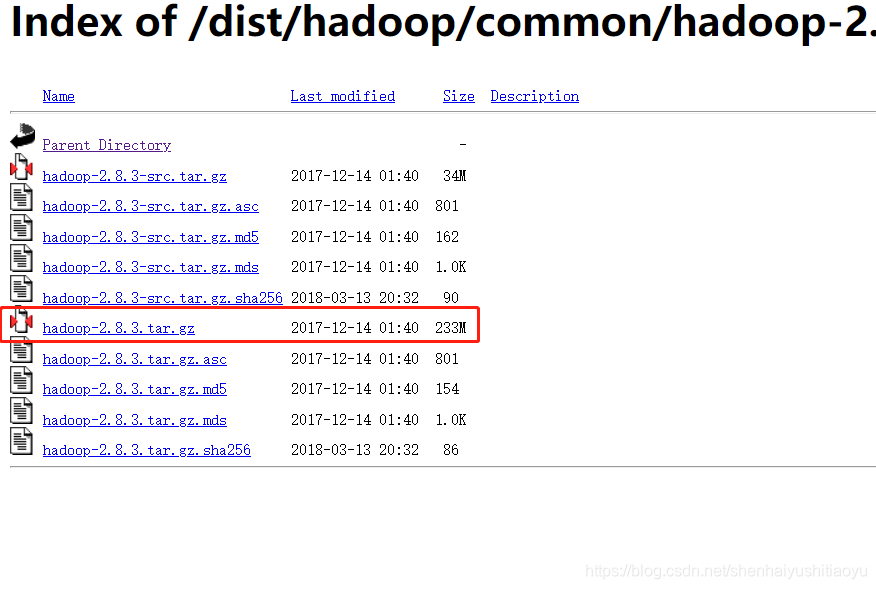
4.2 相关配置
下载好版本后,开始配置。
- 解压压缩包到某个目录,我这边的目录是
2.文件配置
A: java配置(由于Hadoop是java开发的,所以需要java运行环境,所以本机要有java jdk的配置,没有的百度下相关配置哈)
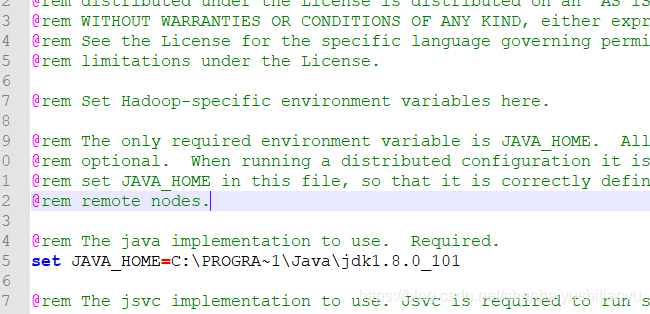
打开D:\develop\hadoop-2.8.3\etc\hadoop 找到 hadoop-env.cmd文件,编辑器打开该文件,配置好java地址
如:C:\Program Files\Java\jdk1.8.0_101 配PROGRA~1置时将 Program Files替换成
PROGRA~1 也就是
C:\PROGRA~1\Java\jdk1.8.0_101
B:
D:\develop\hadoop-2.8.3\etc\hadoop的其他配置:
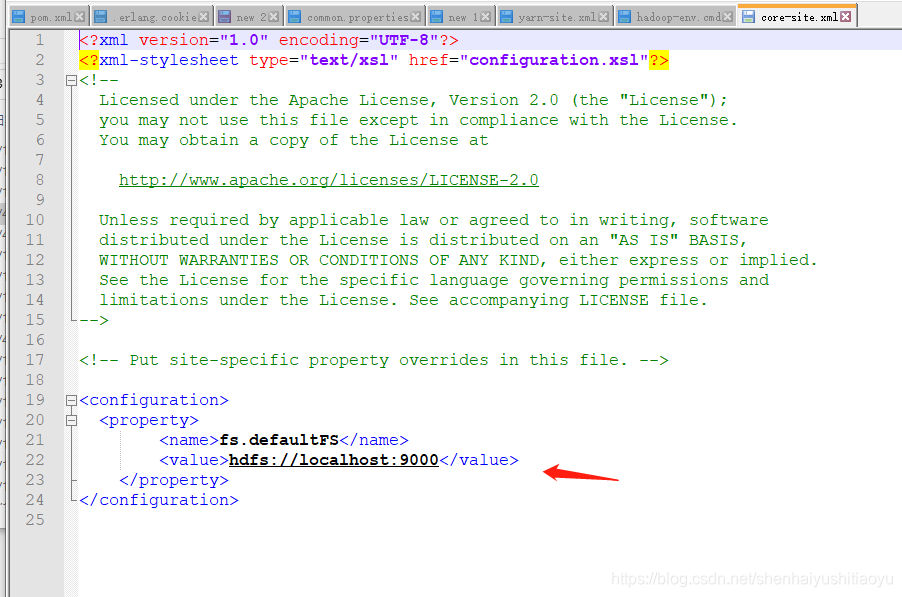
①core-site.xml(配置默认hdfs的访问端口)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
如图:
②hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data/dfs/datanode</value>
</property>
</configuration>
③将mapred-site.xml.template 名称修改为 mapred-site.xml 后再修改内容(设置mr使用的框架,这里使用yarn)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
④yarn-site.xml(这里yarn设置使用了mr混洗)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 环境变量配置。和java一样,很简单,如图所示:
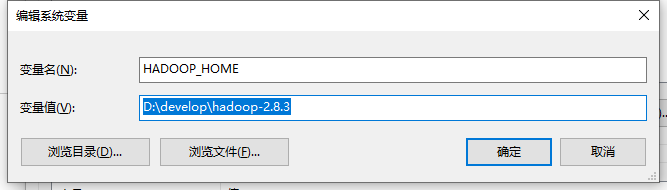
复制粘贴:HADOOP_HOME D:\develop\hadoop-2.8.3
path配置:
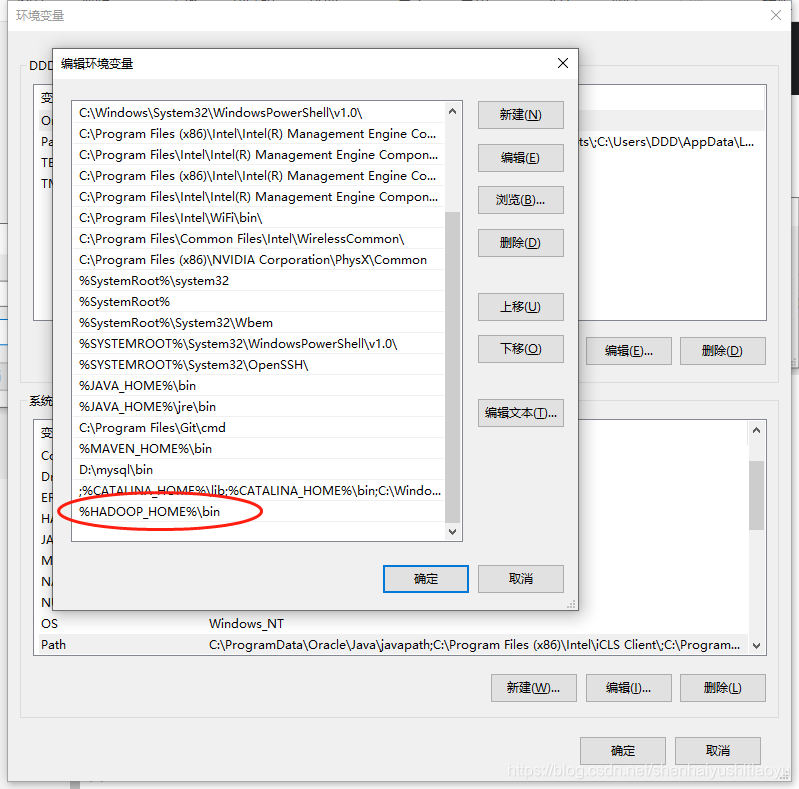
复制粘贴:%HADOOP_HOME%\bin
六、缺省文件下载
打开:https://github.com/steveloughran/winutils 下载zip.解压下载的文件,找到如下:
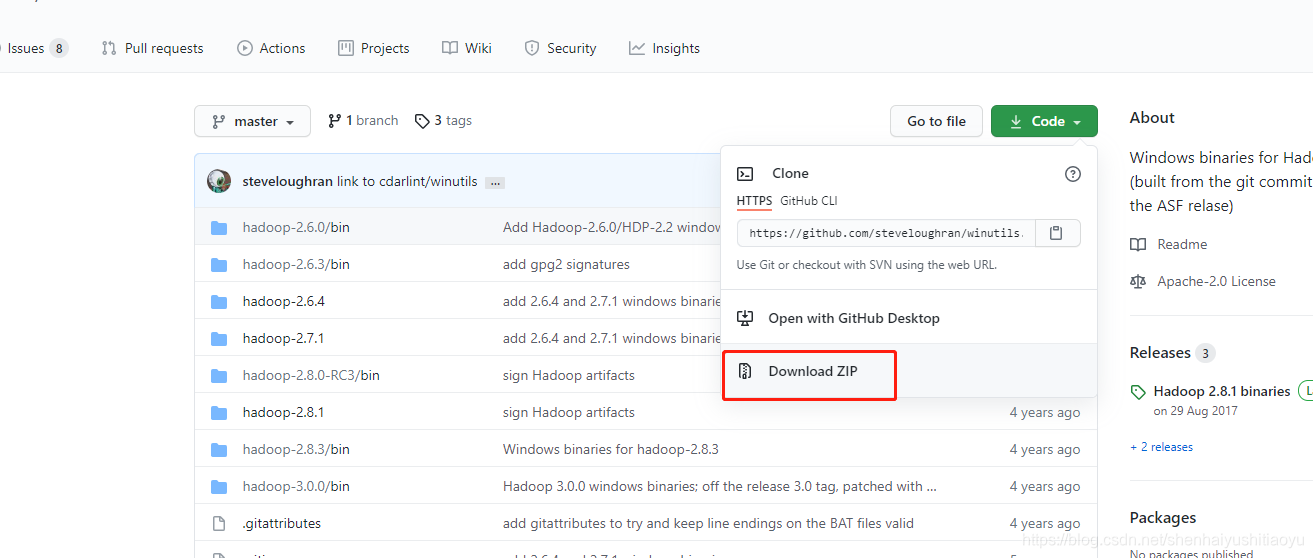
解压:
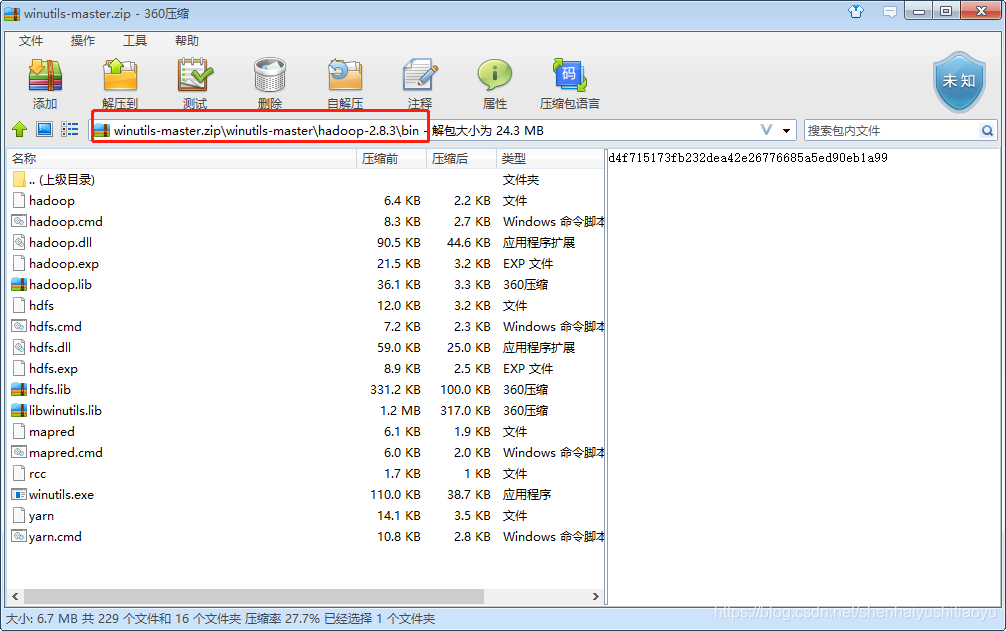
把整个bin的文件,复制到 D:\develop\hadoop-2.8.3\bin 中,替换即可。
因为Windows启动的时候会报 winutils.exe不存在,所以该方法只是把该文件补上而已。
七、启动Hadoop
进入D:\develop\hadoop-2.8.3\sbin 找到start-all.cmd 双击启动,随后会打开4个doc窗口,不报错即为启动成功(按照上面的方法一般是不会报错的,报错的话看下漏掉了什么即可)。
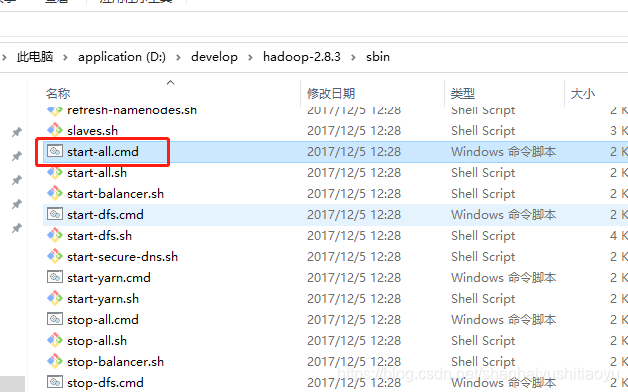
另
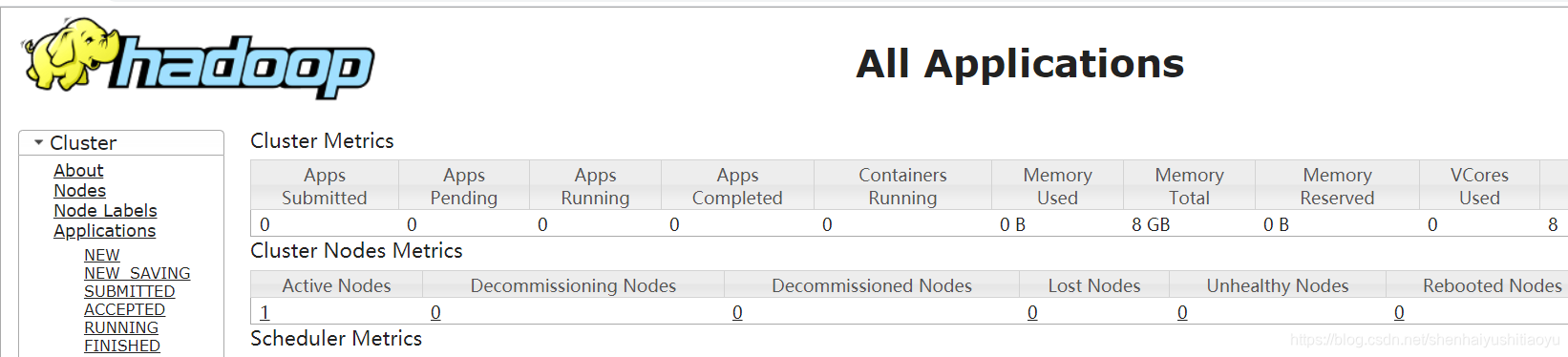
可以在浏览器地址栏中输入:http://localhost:8088查看集群状态。
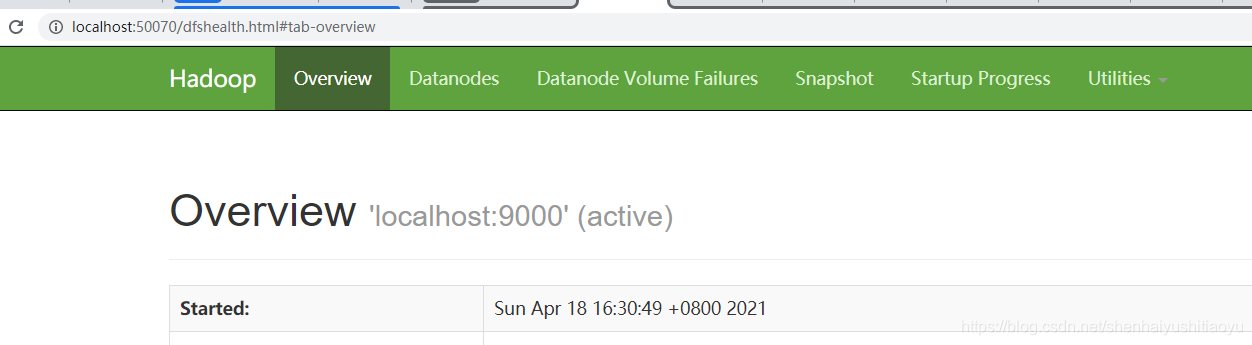
在浏览器地址栏中输入:http://localhost:50070查看Hadoop状态。
八、参考
九、扩展:
- 与Hadoop相关的一些项目(框架):
Ambari™:一种基于Web的工具,用于配置,管理和监视Apache Hadoop集群,其中包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了一个仪表板,用于查看集群健康状况(例如热图)以及以可视方式查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
Avro™:数据序列化系统。
Cassandra™:可扩展的多主数据库,没有单点故障。
Chukwa™:一种用于管理大型分布式系统的数据收集系统。
HBase™:可扩展的分布式数据库,支持大型表的结构化数据存储。
Hive™:一种数据仓库基础结构,可提供数据汇总和即席查询。
Mahout™:可扩展的机器学习和数据挖掘库。
Pig™:用于并行计算的高级数据流语言和执行框架。
Spark™:一种用于Hadoop数据的快速通用计算引擎。Spark提供了一个简单而富有表现力的编程模型,该模型支持广泛的应用程序,包括ETL,机器学习,流处理和图形计算。
Submarine:一个统一的AI平台,允许工程师和数据科学家在分布式集群中运行机器学习和深度学习工作负载。
Tez™:基于Hadoop YARN的通用数据流编程框架,它提供了强大而灵活的引擎来执行任意DAG任务,以处理批处理和交互用例的数据。Hadoop生态系统中的Hive™,Pig™和其他框架以及其他商业软件(例如ETL工具)都采用了Tez,以取代Hadoop™MapReduce作为基础执行引擎。
ZooKeeper™:面向分布式应用程序的高性能协调服务。
- Hadoop相关模块
Hadoop Common:支持其他Hadoop模块的通用实用程序。
Hadoop分布式文件系统(HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
Hadoop YARN:用于作业调度和群集资源管理的框架。
Hadoop MapReduce:基于YARN的系统,用于并行处理大数据集。
Hadoop Ozone: Hadoop的对象存储
Hadoop生态圈:
https://blog.csdn.net/qq_25062299/article/details/95592877














 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









