







一、Linux环境部署
- 工具准备(虚拟机、操作系统、远程工具)
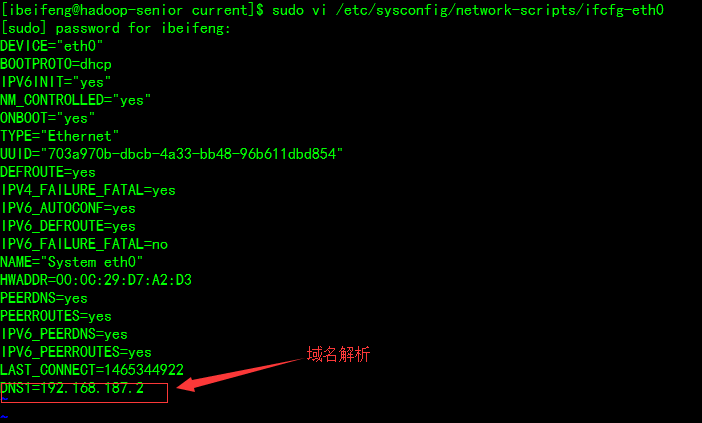
- 修改IP:NAT模式设置固定IP
主机名:vi /etc/sysconfig/network
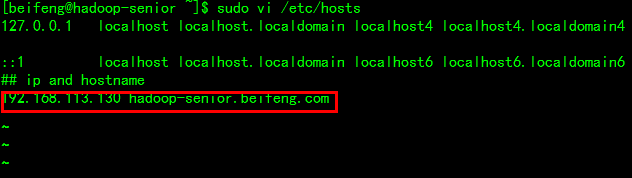
映射: vi /etc/hosts
- 创建普通用户
useradd xxx
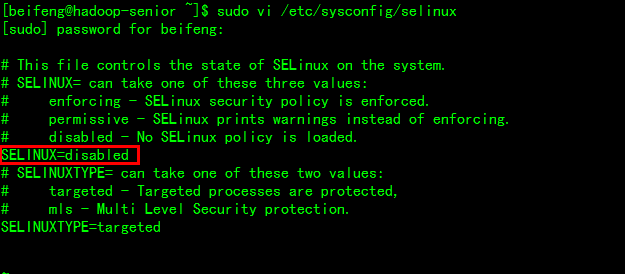
passwd xxx - 关闭防火墙
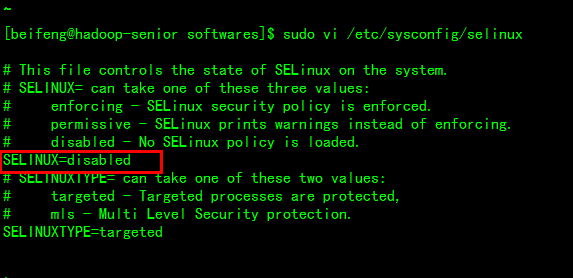
# vi /etc/sysconfig/selinux
改为disabled禁用,然后重启系统生效
- 卸载自带open JDK
\# rpm -qa | grep java
\# rpm -e –nodeps java-1.6.0-openjdk-1.6.0.0-1.50.1.11.5.el6_3.x86_64
tzdata-java-2012j-1.el6.noarch
java-1.7.0-openjdk-1.7.0.9-2.3.4.1.el6_3.x86_64
6、配置sudo权限
# vi sudo
用户名 ALL=(root)NOPASSWD:ALL
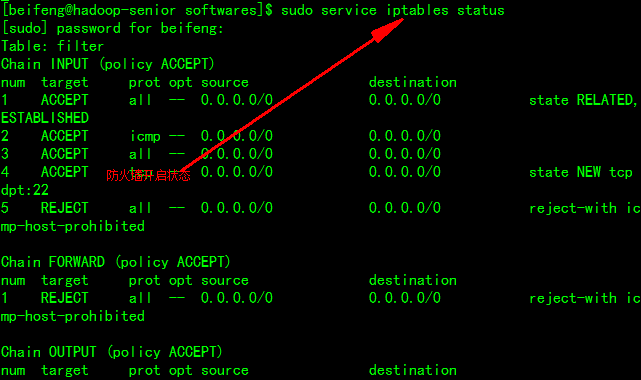
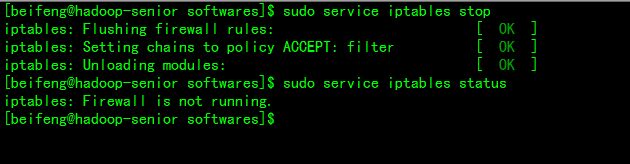
7、查看防火墙状态并关闭
$ sudo service iptables status 查看状态
$ sudo service iptables stop 关闭防火墙
禁用防火墙



二、Hadoop三种模式
本地模式
适用在开发使用
Hadoop默认的配置就叫本地模式
伪分布式模式
适用于开发人员测试程序执行
分布式
Hadoop守护进程运行在一个集群上
三、伪分布式的环境搭建
- 从官网下载Hadoop安装包
- 对Linux目录结构规划
- 解压JDK到指定目录
$ tar -zxf jdk-7u67-linux-x64.tar.gz -C /opt/modlues/ - 配置环境变量
$ sudo vi /etc/profile
环境变量设置内容
##JAVA_HOME
export JAVA_HOME=/opt/modlues/jdk1.7.0_67
export PATH= PATH: JAVA_HOME/bin
切换root用户让文件生效
\$$ su - root
\# source /etc/profile
查看JDK是否安装配置成功
\$java -version - 解压Hadoop安装包
$ tar -zxf hadoop-2.5.0.tar.gz -C /opt/modlues/
Hadoop安装目录下的doc目录为英文说明文档
节省空间的话可以考虑删除
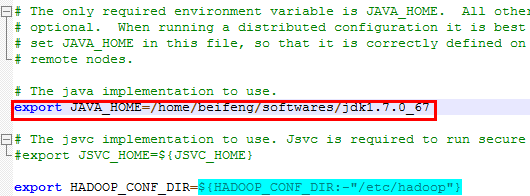
lib/native代表本地库 - 配置hadoop-env.sh文件
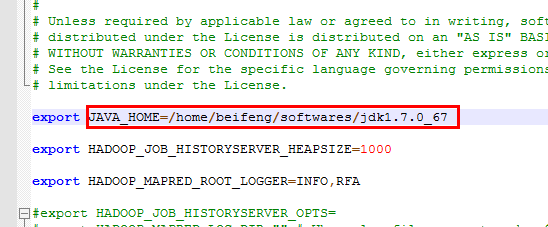
export JAVA_HOME=/opt/modlues/jdk1.7.0_67
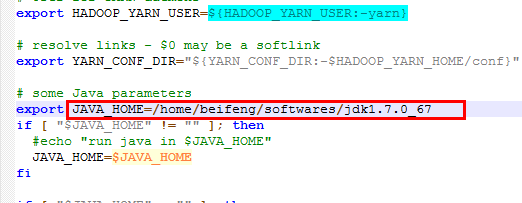
配置yarn-env.sh文件
export JAVA_HOME=/opt/modlues/jdk1.7.0_67
配置mapred-env.sh文件
export JAVA_HOME=/opt/modlues/jdk1.7.0_67
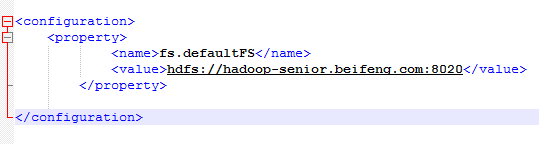
配置core-site.xml文件
作用:
fs.defaultFS表示默认要配置的文件系统,value字段指定具体的namenode所在机器,填写主机名即可,端口改为:8020
配置主节点NameNode的位置和交互端口
fs.defaultFS
hdfs://hadoop-senior01.ibeifeng.com:8020
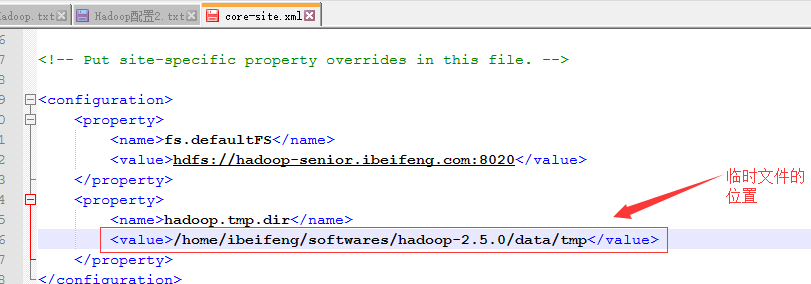
指定临时目录的位置,先要在Linux系统中创建存放的目录
配置slaves文件
作用:
datanode机器所在位置
hadoop-senior01.ibeifeng.com直接加上主机名即可
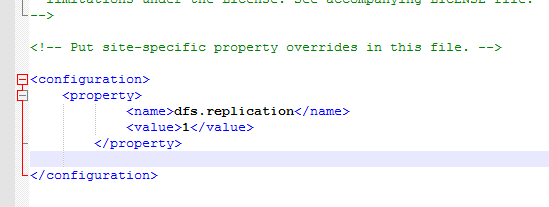
- 配置hdfs-site.xml文件
副本数等于所有datanode的总和
dfs.replication
1
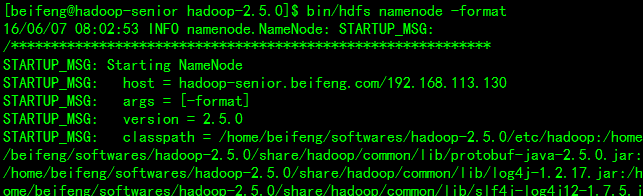
- 格式化NameNode
bin/hdfs对于元数据进行初始化,否则无法读取到信息
格式化命令:bin/hdfs namenode -format
- 启动HDFS服务进程
命令:
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
查看进程状态命令:
$ jps
格式化的对象:/tmp/xxx/dfs/name/current下的fsimage文件 - 如何查看日志文件
进入hadoop安装目录下的logs目录,查看.log结尾的日志文件
注意:出错或者进程没有启动,要学会查看日志文件内容。















 44万+
44万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









