






先看API文档的介绍

总结下Set集合的特点:
1、元素不可重复
2、是无序的
3、Set接口中的方法和Collection一致
根据特点,我们直接开始介绍它的实现类HashSet和TreeSet
HashSet实现类:
可以先做测试,验证Set是否无序,是否不可重复。
重新定义个测试类HashSetTest,代码如下:
public class HashSetTest {
@SuppressWarnings("unchecked")
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("a");
hashSet.add("a");
hashSet.add("b");
hashSet.add("c");
hashSet.add("d");
hashSet.add("e");
System.out.println(hashSet);
}
}测试结果:
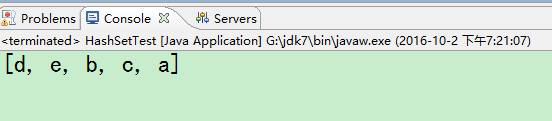
发现确实是元素无序且不重复的,然后继续做测试,这一次还用Student实体类做测试。
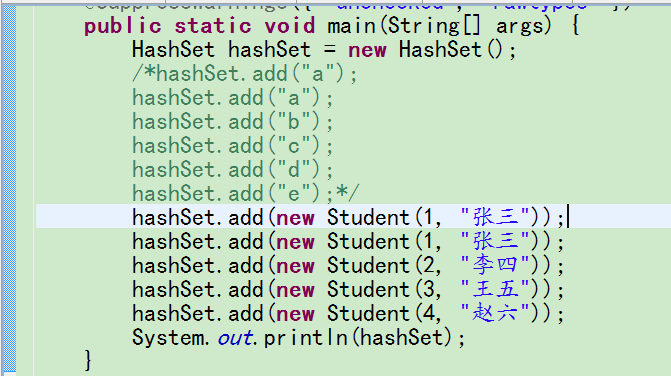
测试结果:

可以看出元素是无序的,但是有两个张三,这显然不是我们想要的结果,根据之前ArrayList判断元素相同的机制,我们是应该可以推测出HashSet对象没有判断Student内容是否相同,这时就需要理解HashSet是如何判断元素相同的。
从HashSet可以看出这个集合应该与哈希表(HashTable)有关,而HashSet判断元素是否相同有两步骤:
1、判断两元素的哈希值(hashCode方法)
2、通过equals判断
Student 之前重写过equals()方法了,但是却没有起作用,说明Student在第一个判断哈希值时是不一样的,所以HashSet认为这是两个不同的元素,那这个哈希值是如何判断的?
我们得知道所有对象都有hashCode()方法。
而HashSet对于Student对象哈希值判断默认是对象的引用地址,
所以即使两个对象内容一样,但是引用地址不同,
HashSet依然把它们当作两个不同对象存入。
这就是上图出现两个张三的原因。既然知道原因是因为判断了Student对象引用地址的哈希值,那我们就需要重写Student类的hashCode()方法,让它根据Student对象属性来判断哈希值。
具体代码如下:
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + sId;
return result;
}至于第二个判断equals()方法之前ArrayList例子已经重写过,无需重写,至此重新做个测试,
测试结果:

发现测试结果是符合要求,但是我们现在若是多了一个需求:要求是存取元素有序。那该如何?
有两种方法:一种是HashSet的子类LinkedHashSet,LinkedHashSet:具有可预知迭代顺序的Set接口的哈希表和链表实现。这边不多做介绍,有兴趣的可以自行查看相关资料。
另一种就是需要学习的TreeSet集合。老规矩先看API文档的介绍。

总结下特点:
1、底层靠TreeMap实现
2、两种元素排序方法:一种元素自身具备比较功能。
另一种让集合自身拥有比较功能,通过Comparator比较器实现。(掌握)
3、内部数据结构是二叉树(了解)
4、是不同步的
概念中出现了自然顺序和Comparator接口,可能刚接触的人比较陌生,那么我们先来了解自然顺序,API文档中同样存在定义:

可知若是想让元素具备比较功能,元素必须是类的自然排序,而自然排序需要元素实现Comparable接口,重写compareTo方法。接下来做个测试,定义一个TreeSetTest,具体代码如下:
package com.java.set;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add("a");
treeSet.add("b");
treeSet.add("c");
treeSet.add("d");
treeSet.add("e");
System.out.println(treeSet);
Iterator it = treeSet.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}测试结果如下:
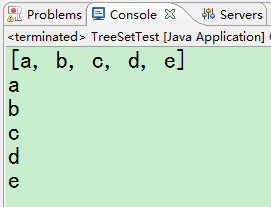
可以看出若是字符串本身具备自然排序,然后我们把元素换成Student对象看会出现什么现象。

结果如下:
Exception in thread "main" java.lang.ClassCastException: com.java.entity.Student cannot be cast to java.lang.Comparable
at java.util.TreeMap.compare(TreeMap.java:1188)
at java.util.TreeMap.put(TreeMap.java:531)
at java.util.TreeSet.add(TreeSet.java:255)
at com.java.set.TreeSetTest.main(TreeSetTest.java:16)因为Student对象不具备自然排序,没有实现comparable接口,所有报了类型无法转换的错误。
现在Student类实现Comparable接口,具体重写compareTo()方法。具体代码如下:
public int compareTo(Object obj) {
Student student = (Student)obj;
//根据sId进行排序
int temp = this.sId - student.sId;
//若是sId相同则根据name进行排序
return temp == 0 ? this.name.compareTo(student.name) : temp;
}然后在做测试:
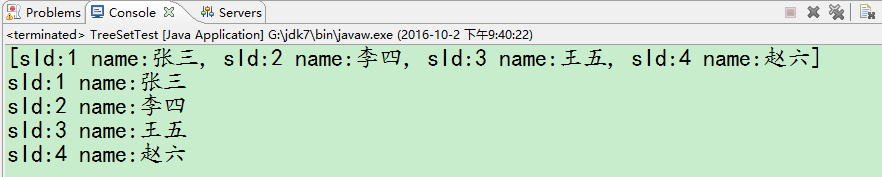
结果是有序的。
接下来介绍Comparator比较器。
如果不按照对象中具备的自然顺序排序,
或是对象不具备自然顺序可以使用TreeSet集合第二种排序方法:
让集合自身具备比较功能。
具体思路:首先需要先建立一个比较器,
定义一个类实现Comparator接口,
重写compare方法。
将该对象作为参数传递给TreeSet构造函数。
现在我们定义一个比较器ComparatorByName,该比较器通过姓名排序。
具体代码如下:
package com.java.comparator;
import java.util.Comparator;
import com.java.entity.Student;
public class ComparatorByName implements Comparator{
@Override
public int compare(Object obj1, Object obj2) {
Student student1 = (Student)obj1;
Student student2 = (Student)obj2;
int temp = student1.getName().compareTo(student2.getName());
return temp == 0 ? student1.getsId() - student2.getsId() : temp;
}
}测试代码如下:

测试结果如下:
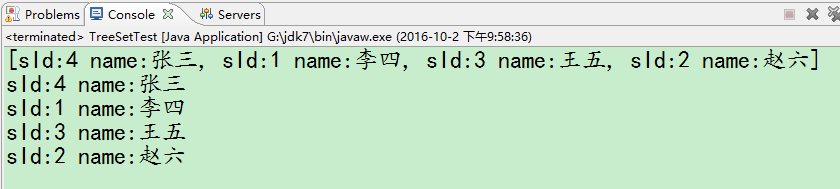
至此Set集合内容结束。接下开始介绍Map集合。















 1937
1937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









