







 本文深入探讨Linux内核如何在内存紧张时决定回收匿名页(anon)和文件页(file)的比例。除了熟知的swappiness参数外,内核还考虑了IO成本、refault概率和pageout数量等因素。源码分析揭示了workingset_refault计算逻辑的变化,以更精确地平衡回收成本和性能影响。
本文深入探讨Linux内核如何在内存紧张时决定回收匿名页(anon)和文件页(file)的比例。除了熟知的swappiness参数外,内核还考虑了IO成本、refault概率和pageout数量等因素。源码分析揭示了workingset_refault计算逻辑的变化,以更精确地平衡回收成本和性能影响。
概述
Linux内核为了区分冷热内存,将page以链表的形式保存,主要分为5个链表,除去evictable,我们主要关注另外四个链表:active file/inactive file,active anon和inactive anon链表,可以看到这主要分为两类,file和anon page,内存紧张的时候,内核开始从inactive tail定量回收page,那么这里面就有个很重要的选择:inactive file和inactive anon lru链表的回收比例到底怎么确定?稍微了解mm的肯定都知道内核有个回收倾向可以设置:swappiness,值越大代表更多的回收anon内存,相反,更倾向于回收非anon内存,但是内核控制两者回收比例仅仅是swappiness控制这么简单吗?在阅读v6.1内核发现,随着内核的不断发展和优化,两者回收比例不断的迭代,逐步考虑到更多的情况,本文将以v6.1源码,逐步揭开内核对于两种page回收比例控制的神秘面纱。
比例计算的核心源码
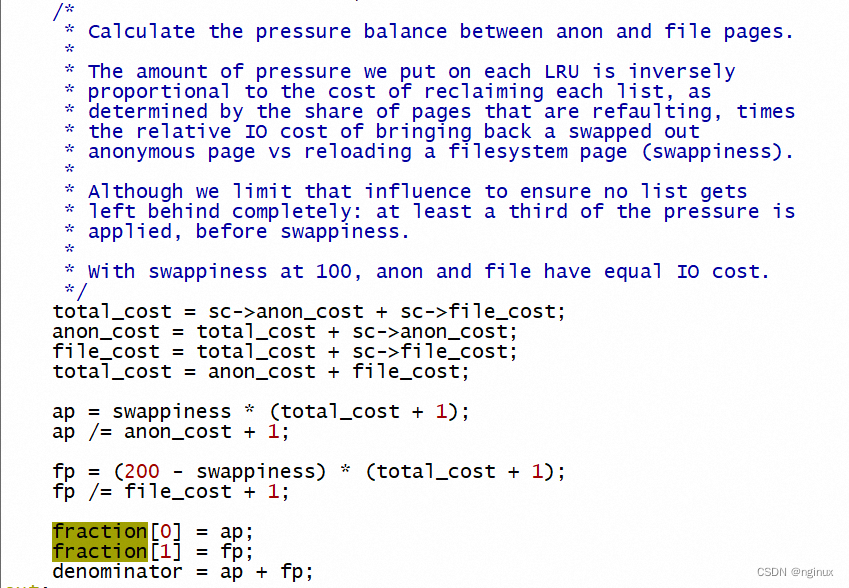
ap和fp分别表示 anon和file扫描回收的比重,其计算主要是涉及几个重要的元素:swappiness,file_cost和anon_cost。为了更好的理解这几个控制变量的意义,我们需要从内核回收两种页面的涉及思想上来考虑。
1. 回收file-backed page和anon page的IO成本不同,故引入swappiness。
比如内核在引入zram内存压缩技术之前,回收anon page的成本比较高,因为需要将内存通过IO写入磁盘,而file-backed文件页有可能遇到clean page不需要IO回写,而比如嵌入式往往都存在zram内存压缩技术,anon匿名内存得回收成本可能比file-backed page要低得,因为内存操作性能比IO性能更好,所以swappiness这个控制选项从另外一个角度理解:代表两种类型得IO成本。
swappiness的具体函数参见内核文档:

翻译:swappiness用于粗略得表示swap或者file-back page回收得IO成本,取值范围是0-200,如果是100代表内核得mm子系统认为内存回收两种page得IO成本是相当得。内核默认将该值设置60,这种情况内核认为swap的IO成本更高,但是对于存在内存swap的(比如zram或者zswap技术),超过100的值是值得考虑的,因为这种情况下swap是内存操作,性能更好,IO成本更低。
2. 内存回收要考虑refault概率和两种类型page pageout的数量
refault次数:
内核引入workingset算法后,可以精准的评估出来两种page的refault次数;如果refault次数越多,认为file-cost或者anon-cost数值越大(意味者要减少回收比例,否则频繁发生了refault影响性能)。
pageout数量:
内核也要避免某一种类型的page在疯狂的进行回收,尽量做到均衡,内核实现的时候pageout的page数量也作为一种参考变量,如果某一种类型的页面回收的过多也需要进行一定程度的抑制。
源码解析
源码分析部分我们主要关注file-cost和anon-cost数值的计算逻辑,根据上面分析refault次数和pageout次数都会影响cost数值的计算,下面我们从源码实现上验证一下相关逻辑。
refault因素影响:
/**
* workingset_refault - Evaluate the refault of a previously evicted folio.
* @folio: The freshly allocated replacement folio.
* @shadow: Shadow entry of the evicted folio.
*
* Calculates and evaluates the refault distance of the previously
* evicted folio in the context of the node and the memcg whose memory
* pressure caused the eviction.
*/
void workingset_refault(struct folio *folio, void *shadow)
{
bool file = folio_is_file_lru(folio);
struct mem_cgroup *eviction_memcg;
struct lruvec *eviction_lruvec;
unsigned long refault_distance;
unsigned long workingset_size;
struct pglist_data *pgdat;
struct mem_cgroup *memcg;
unsigned long eviction;
struct lruvec *lruvec;
unsigned long refault;
bool workingset;
int memcgid;
long nr;
if (lru_gen_enabled()) {
lru_gen_refault(folio, shadow);
return;
}
unpack_shadow(shadow, &memcgid, &pgdat, &eviction, &workingset);
eviction <<= bucket_order;
rcu_read_lock();
/*
* Look up the memcg associated with the stored ID. It might
* have been deleted since the folio's eviction.
*
* Note that in rare events the ID could have been recycled
* for a new cgroup that refaults a shared folio. This is
* impossible to tell from the available data. However, this
* should be a rare and limited disturbance, and activations
* are always speculative anyway. Ultimately, it's the aging
* algorithm's job to shake out the minimum access frequency
* for the active cache.
*
* XXX: On !CONFIG_MEMCG, this will always return NULL; it
* would be better if the root_mem_cgroup existed in all
* configurations instead.
*/
eviction_memcg = mem_cgroup_from_id(memcgid);
if (!mem_cgroup_disabled() && !eviction_memcg)
goto out;
eviction_lruvec = mem_cgroup_lruvec(eviction_memcg, pgdat);
refault = atomic_long_read(&eviction_lruvec->nonresident_age);
/*
* Calculate the refault distance
*
* The unsigned subtraction here gives an accurate distance
* across nonresident_age overflows in most cases. There is a
* special case: usually, shadow entries have a short lifetime
* and are either refaulted or reclaimed along with the inode
* before they get too old. But it is not impossible for the
* nonresident_age to lap a shadow entry in the field, which
* can then result in a false small refault distance, leading
* to a false activation should this old entry actually
* refault again. However, earlier kernels used to deactivate
* unconditionally with *every* reclaim invocation for the
* longest time, so the occasional inappropriate activation
* leading to pressure on the active list is not a problem.
*/
refault_distance = (refault - eviction) & EVICTION_MASK;
/*
* The activation decision for this folio is made at the level
* where the eviction occurred, as that is where the LRU order
* during folio reclaim is being determined.
*
* However, the cgroup that will own the folio is the one that
* is actually experiencing the refault event.
*/
nr = folio_nr_pages(folio);
memcg = folio_memcg(folio);
lruvec = mem_cgroup_lruvec(memcg, pgdat);
mod_lruvec_state(lruvec, WORKINGSET_REFAULT_BASE + file, nr);
mem_cgroup_flush_stats_delayed();
/*
* Compare the distance to the existing workingset size. We
* don't activate pages that couldn't stay resident even if
* all the memory was available to the workingset. Whether
* workingset competition needs to consider anon or not depends
* on having swap.
*/
workingset_size = lruvec_page_state(eviction_lruvec, NR_ACTIVE_FILE);
if (!file) {
workingset_size += lruvec_page_state(eviction_lruvec,
NR_INACTIVE_FILE);
}
if (mem_cgroup_get_nr_swap_pages(memcg) > 0) {
workingset_size += lruvec_page_state(eviction_lruvec,
NR_ACTIVE_ANON);
if (file) {
workingset_size += lruvec_page_state(eviction_lruvec,
NR_INACTIVE_ANON);
}
}
if (refault_distance > workingset_size)
goto out;
folio_set_active(folio);
workingset_age_nonresident(lruvec, nr);
mod_lruvec_state(lruvec, WORKINGSET_ACTIVATE_BASE + file, nr);
/* Folio was active prior to eviction */
if (workingset) {
folio_set_workingset(folio);
/* XXX: Move to lru_cache_add() when it supports new vs putback */
lru_note_cost_folio(folio);
mod_lruvec_state(lruvec, WORKINGSET_RESTORE_BASE + file, nr);
}
out:
rcu_read_unlock();
}workingset_refault有两个重要的点:
1.workingset_size计算逻辑
内核刚引入workingset算法的时候,workingset_size计算逻辑很简单,只要计算相应类型page的Active page数量就可以了,而v6.1源码的计算逻辑更为复杂,也更为科学,总结起来:workingset size等于:Sum of all LRU size except inactive list of page's type。
anon page:
workingset_size = NR_ACTIVE_FILE + NR_INACTIVE_FILE + NR_ACTIVE_ANON
file-backed page:
workingset_size = NR_ACTIVE_FILE + NR_ACTIVE_ANON + NR_INACTIVE_ANON
内核为什么要修改这个逻辑呢?可以参见如下系列patch:
Re: [PATCH 05/14] mm: workingset: let cache workingset challenge anon - Johannes Weiner
尤其这个系列的patch的05号修改对应workingset_size计算逻辑的优化,核心的思想是说虽然内核将lru链表分割成file和anon,但是计算workingset size的时候要综合起来看这两个部分,不能割裂的看,因为系统回收内存的时候是file和anon综合扫描回收的,具体原因原作者回复的特别清晰:
This is intentional, because there IS a connection: they both take up
space in RAM, and they both cost IO to bring back once reclaimed.
When file is refaulting, it means we need to make more space for
cache. That space can come from stale active file pages. But what if
active cache is all hot, and meanwhile there are cold anon pages that
we could swap out once and then serve everything from RAM?
When file is refaulting, we should find the coldest data that is
taking up RAM and kick it out. It doesn't matter whether it's file or
anon: the goal is to free up RAM with the least amount of IO risk.
Remember that the file/anon split, and the inactive/active split, are
there to optimize reclaim. It doesn't mean that these memory pools are
independent from each other.
The file list is split in two because of use-once cache. The anon and
file lists are split because of different IO patterns, because we may
not have swap etc. But once we are out of use-once cache, have swap
space available, and have corrected for the different cost of IO,
there needs to be a relative order between all pages in the system to
find the optimal candidates to reclaim.有个人说file和anon的refault distance计算是按内核的逻辑这两个是没关系,新patch打破了这个固有观念。作者回复了上面一段:
这是有意为之,因为这两个是有联系的:他们都占用RAM内存,回收的时候也都有IO成本。当file发生refault时候,意味者需要给cache更多的生存空间(避免被回收导致refault的空间),这个空间可以来自于老旧的active file pages(也就是说将该cache page放入active file lru链表保护下),但是如果如果active file page都是hot频繁访问的,与此同时,存在cold anon pages可以swap out应该怎么样呢?
当文件发生refault的时候,我们要做的是找到coldest的page然后回收掉,不需要关心这个是file,还是anon page:目标就是以最小的IO成本释放内存而已。
记住:file/anon的区分,inactive/active的区分都是为了方便内存回收,并不意味者这些内存是互相独立无关的。
总结:作者的意思是说,计算workingset size的时候,比如file-backed page来说,不仅仅只考虑本file acitve lru,也要综合考虑anon page的情况,比如作者说的情况,假设active file lru都是hot的,而anon 中存在大量cold page,这个时候os会选择回收anon page的,这对于file page就是一种保护了,作者的patch更新后更激进的将page放入active 进行保护。
对于patch更新后有个人提出了疑问说某种情况会导致发生内存颠簸:
> My suspicion is started by this counter example.
>
> Environment:
> anon: 500 MB (so hot) / 500 MB (so hot)
> file: 50 MB (hot) / 50 MB (cold)
>
> Think about the situation that there is periodical access to other file (100 MB)
> with low frequency (refault distance is 500 MB)
>
> Without your change, this periodical access doesn't make thrashing for cached
> active file page since refault distance of periodical access is larger
> than the size of
> the active file list. However, with your change, it causes thrashing
> on the file list.上面意思是说由于新的patch综合考虑了file/anon计算working size,那么对于上面的case新的patch引入后(没有更新前不会)低频访问的100M file产生的page就会被加入active file lru链表当中,这样的话可能会导致hot的file被挤到inactive file lru当中,然后导致这50M active hot page cache逐渐被挤到inactive file lru中被系统回收,导致颠簸,而没有引入新patch,由于不满足refault distance > 50M的条件,低频访问的page都不会被放入active file lru,所以没有问题。。。
作者回复:不管是否引入新patch其实都不会引入颠簸(本身这100M低频访问的颠簸是再说难免的),对于那50M hot file不会引起颠簸是因为这些内存是hot的,那意味者page_check_references会将page扔回active file lru的,所以不会被回收引起颠簸,GOOD Reply!!!
2.lru_note_cost_folio逻辑
这个函数就是用来累加不同类型(file/anon)回收的成本,调用时机有如下几种:
//根据pageout对应类型page(anon/file)统计swap-out或者write-page回写数量,这种
//情况就是统计下swap或者writepage的数量,避免过度swapout或者过度writepage,要均衡一下
shrink_inactive_list
--->lru_note_cost
//如果发现page生命周期范围内是active过的,那么发生缺页的时候就统计一次缺页成本
//内核认为active过的页面(PG_workingset的含义,就是生命周期中有存在active 链表中)被回收
//发生refault才具备参考意义
workingset_refault
--->lru_note_cost_folio
参考文章
[PATCH 10/14] mm: only count actual rotations as LRU reclaim cost - Johannes Weiner


















 9854
9854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









