大数据
首先大家应该知道目前的环境处于一个数据时代,大数据也是一个不陌生的内容了。那么数据是什么,数据怎么分类,你真的清楚嘛?数据就像MySQL内存的数据。
数据目前被分为3类:
结构化数据: 有严格约束。(有源数据)
半结构化数据: 如HTML,XML,JSON等等文档
非结构化数据: 日志数据。(没有源数据)
那么数据的关键两个步骤那就是 高效存储 和 高效分析处理。怎么 高效存储和高效分析 就是大数据的技术关键。
hadoop的前身。也就是google公司提出了相关的解决方法。
2003年:google公司以论文的方式提出了 Google File System。一个面向大规模数据密集型应用的,可伸缩的分布式文件系统。他的关键词是数据存储,和集群存储。 但是它也存在一些小问题,那就是不能随机访问,更不能随机写。
而gfs就是hadoop中hdfs的前身。
2004年:google发表了另外一篇论文。如何实现Simplified Data Processing。也就是出现了MapReduce。也就是将一个任务分析拆分为一个个的任务单元。并且并行处理。再将处理后的数据再次收集,二次处理。
而hadoop直接引用了Mapreduce。
2006年:google公开了BigTable的论文。它支持键值对的存储格式。是个典型的NoSQL。是一个稀疏的,分布式的,持久化存储的多维度排序的Map。Bigtable的设计目的就是快速可靠的处理PB级的数据。并且可以部署到上千台机器上。
而bigtable就是HBase的前身。
而google的这些论文结果就被社区达人开发出了现在的hadoop。
hadoop介绍
hadoop诞生不久,就被全球各大需要处理大量数据的公司所青睐。现在的hadoop可谓是大红大紫,是个特别火热的开源项目。
说到hadoop就必须知道几个名词,HDFS,Map,Reduce,Namenode,Datanode,Jobtracker,Tasktraker ,SecondaryNameNode。
HDFS
首先HDFS是一个分布式文件系统。它是mapreduce处理的前提。它和现有的分布式文件系统有很多的相似之处。
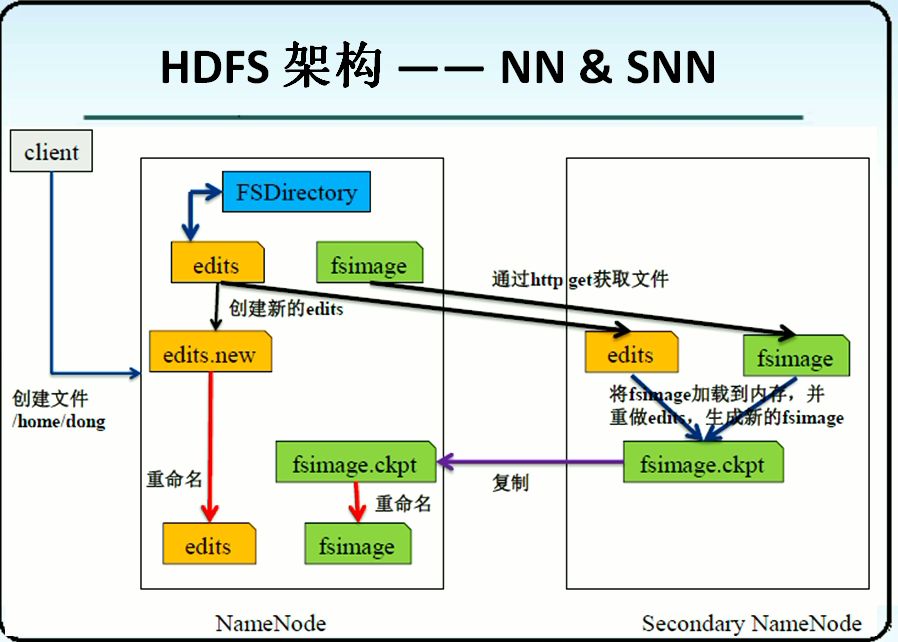
它也需要一个源数据节点,和N个数据节点。源数据节点即使NameNode。而数据节点就是DataNode。当然,为了高可用一下。还有SecondaryNameNode。
NameNode:是Master节点。所有的数据访问必须先经过一下它,它相当于是书的目录,记录着数据的映射。处理客户端的读写请求,配置副本策略,管理HDFS的名称空间。
SecondaryNameNode:分担NameNode的工作量。是NameNode的冷备份。合并fsimage和fsedits然后再发送给namenode。
DataNode:存数据的。负责存储client发来的数据块Block。执行数据块的读写等操作。
fsimage:源数据镜像文件(文件系统的目录树)
edits:源数据的操作日志(针对文件系统做出的修改记录)
注:namenode内存中存储的是fsimage+edits。SecondaryNameNode默认定时1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
为了更好的提供高可用。那么又引入了zookeeper。大家把数据发送给zookeeper。而主的挂了,从向zookeeper申请去拿所有的数据。从服务器立即顶替上去。
而为了防止data数据失效。所有的数据在一个datanode存一份的基础上,再在其他datanode备份x份。
所以HDFS是又很高的高可用性。Datanode不停向Namenode报告自己的数据存储信息。以备namenode可以调度。若某一datanode老不报告,namenode就认为节点挂了,即重新链式补充够足够的备份。
MapReduce
说到MapReduce。那么就需要知道jobtraker和tasktracker了。当然map过程和reduce过程也很重要。既然HDFS提供了平台,那么就需要程序去在这个平台上去处理数据了。那,这就是mapreduce的工作了。
Jobtracker:从集群中获取tasktracker的心跳。维护有关集群当前能力的信息并负责调度,分配以及用户指定作业的进度。也是用户提交作业的入口。同样,jobtracker扮演着HDFS中namenode的角色。那么也可以依赖zookeeper去实现高可用。
tasktracker:负责执行jobtraker发送过来的作业。任务追踪。
不过最新的hadoop。这些都改了,出现了yarn,提供了新的管理思路。
Map和Reduce就是hadoop处理程序的核心了。Mapreduce不仅仅是开发API,还是运行框架。也是相关的运行环境。
那么什么是map和reduce呢。在python的高阶函数中有两个方法分别叫做map方法和reduce方法。其实都是一个道理。
在python中。map是python内置的高阶函数。它接收一个函数fun和一个list。并通过把函数依次作用于list的每一个元素上。得到一个新的list返回。
同样,reduce也是python的内置的高阶函数。传入的函数必须接收两个参数(三个也可以),reduce对list的每个元素反复调用fun方法迭代下去,并返回最终的结果值。
而MapReduce的大致结构图如下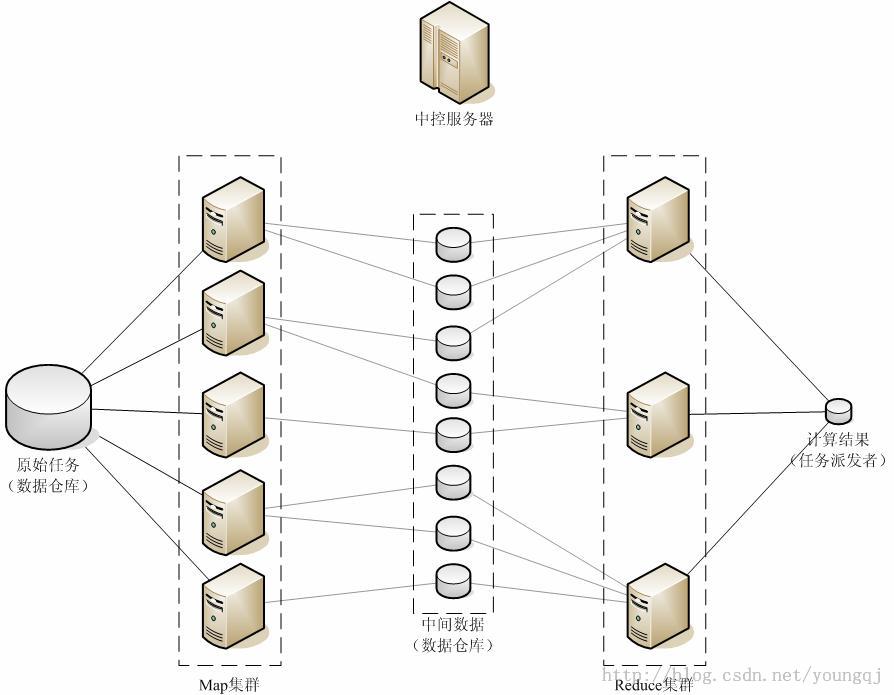
Map: 接收一个函数为参数,将其应用于列表中的其他所有元素。从而生成一个结果列表。
其中原始的数据如何被抽取成K,V。map的过程和reduce过程如何运行,都需要程序员去设定。任务被派发给哪些map,哪些reduce都是程序员可以定义。
Reduce:接收reduce集群提交上来的结果,然后再合并起来。
shuffling过程中。处理结果发给哪个reduce再处理都是由partitioner所定义,而partitioner是由程序员去写。partitioner决策哪个key发给哪个reduce。还有一个combiner过程。比如第一行,Bear有2个,那么可以再shuffling时直接就折叠了。将折叠结果直接发送给reduce。那么reduce的任务量就小多了。而combiner又是需要程序员去自己写。
下图就是非常清晰的mapreduce过程了。
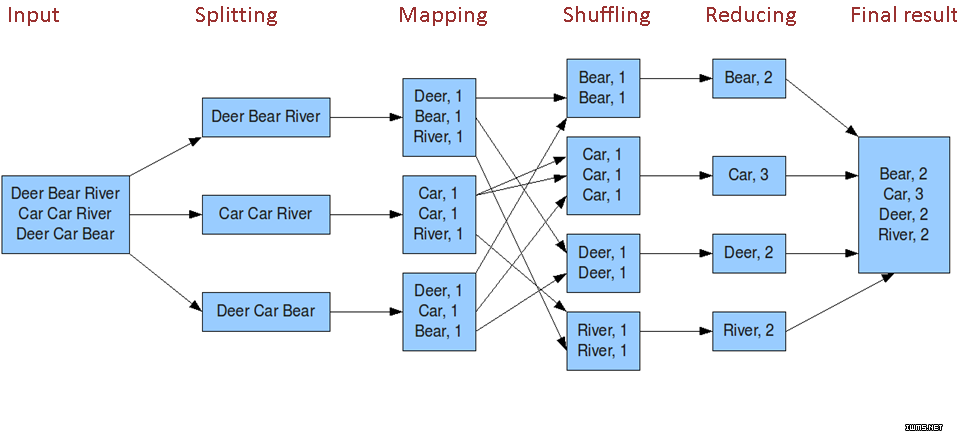
但是hadoop在发展过程中发生了重大的变化。前几天hadoop3都已经出来。并且都可以支持多个namenode。
Hadoop2.0
在hadoop的发展过程中,hadoop2.0 横空出世。结构出现了重大的变化,Yarn出现了!!!
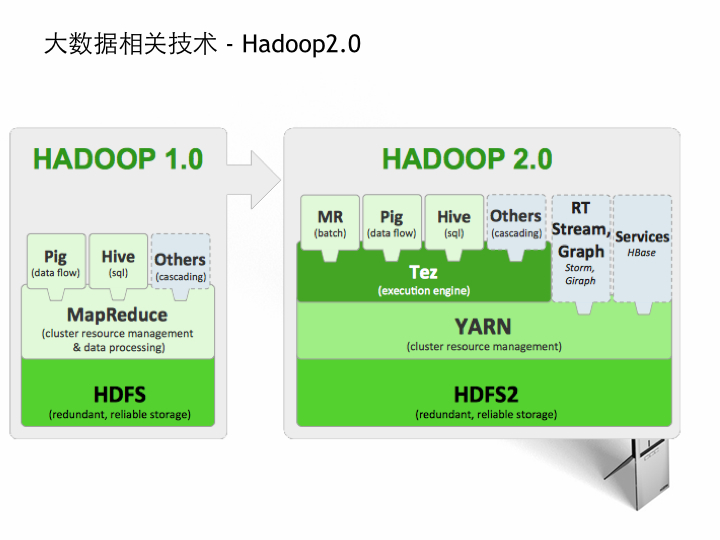
原本hadoop1.0中的Mapreduce被切割成了两个部分。一个部分为YARN,一部分仍然为Mapreduce。
在hadoop1中的Mapreduce既是集群资源管理器,又是处理程序。
在hadoop2中YARN负责集群资源管理器。Mapreduce成了处理程序,MR成了批处理程序。PIG,Hive和MR(Mapreduce)都在Tez上执行。Tez是一个执行引擎。RT是个实时流式图处理,HBase也直接运行在YARN上了。
当然,MR,PIG,HIVE也可以不跑在YARN上。而直接运行在YARN上。除此之外还有内存计算的SPARK,高性能计算的HPC SMPI
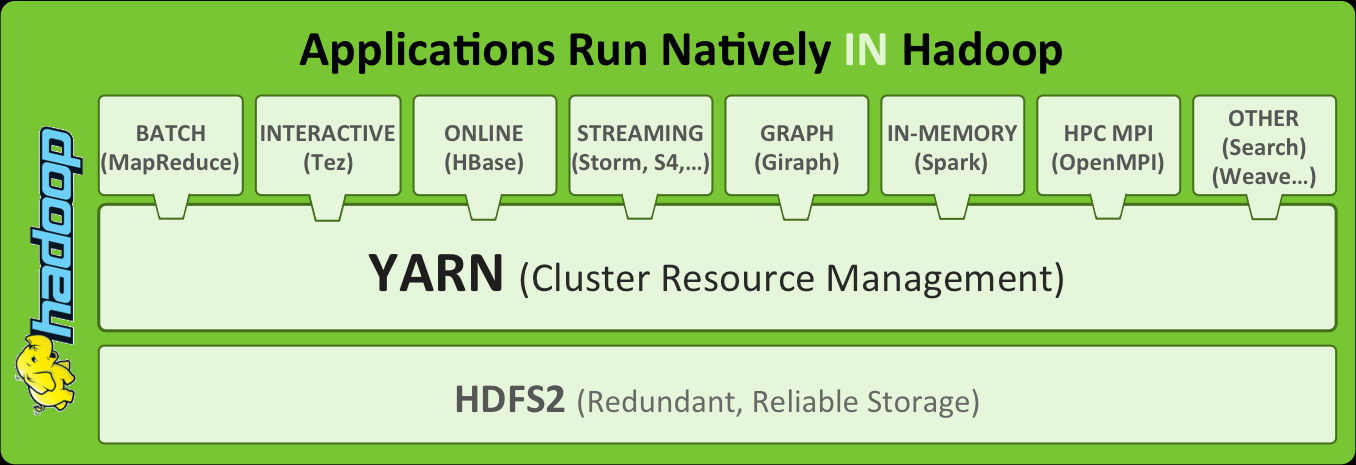
hadoop2.0的运行过程。
RM需要了解整个集群的工作状态,Application Master负责决定启动哪些容器(Container)去运行mapreduce。若哪个container出问题了,都会由container去管理。
将程序运行和全局资源分配分开。一个任务来了,ResourceManager启动一个NodeManager上的ApplicationMaster。之后就由ApplicationMaster来管理那些Container去做。

但是有个问题,hadoop是由Java语言所研发的,那么想要使用hadoop则必须会使用java语言编写jar包。这极大的打击了各位的学习兴趣。那么就有人去研发一些程序去调用MapreduceAPI。这就引出了Hive和Pig
Hive就是通过HQL(类似MySQL的SQL)去直接调用mapreduce。而Pig就是类似脚本的语言。去调用MapreduceAPI。但是又出现了新语言。但是这个就相对而言简单多了。























 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









