






背景
MyTopling 是基于 ToplingDB 的 MySQL,分叉自 MyRocks,ToplingDB 则分叉自 RocksDB,兼容 RocksDB 接口,从而 MyTopling 可以复用 MyRocks 的大部分成果。
ToplingDB 早已开源,MyTopling 也会于近期开源,目前我们正处于紧张的内部开发中
ToplingDB 的一个重要功能是 分布式 Compact(文档),去年我们实现了 托管Todis 的 分布式 Compact 支持。同样是基于 ToplingDB,分布式 Compact 自然也是 MyTopling 的重要功能。
分布式 Compact 介绍
我们先看单个 MyTopling 实例的集群架构:
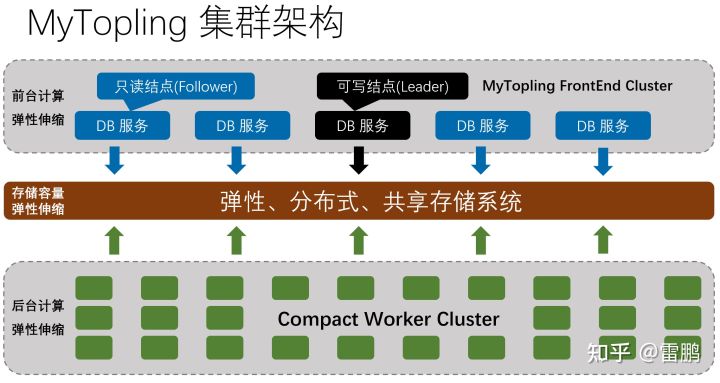
从图中可以看到,除了传统的多副本(传统主从 或 Raft)之外,MyTopling 还多了一个 Compact Worker Cluster,这个 Cluster 还有那么多结点,这不是要消耗更多的硬件资源吗?
但是,作为云原生 DB 提供商,我们是有很多个 MyTopling 实例的!重要的话要说三遍:是很多个,很多个,很多个:
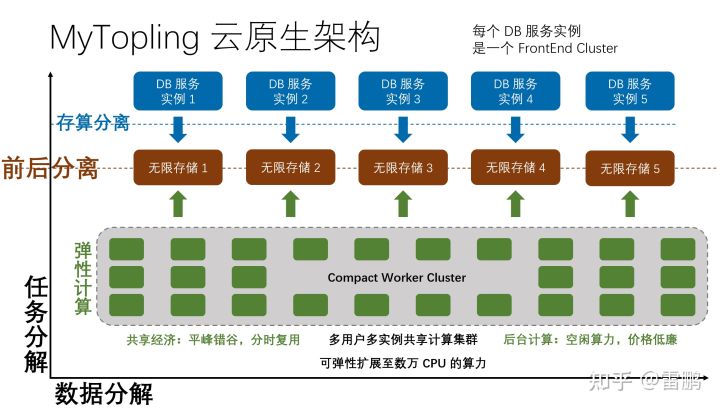
同一个 Compact 集群服务很多个 MyTopling DB 实例,这里面的关键点在于:
- 很多个 DB 实例,从统计上看,不同实例的流量峰值和低谷在时间上是交错的
- Compact 是后台计算,相比前台 Query,对延迟的要求要低得多
- 在 LSM 的写负载中,80% 甚至 90% 以上的计算,都是 Compact
这几个关键点跟分布式 Compact 有什么关系呢?
1. 很多个 DB 实例,从统计上看,不同实例的流量峰值和低谷在时间上是交错的
统计意义上,在任意时刻,不同 DB 实例的流量总和,不是它们最高值的累加,而是平均值的累加,从而在 Compact 集群中实现 平峰填谷的效果。
2. Compact 是后台计算,相比前台 Query,对延迟的要求要低得多
按照传统方案,为了 保证在线服务的延时,机器的负载不能太高(< 30%),更要命的是,Compact 消耗的计算也在这 30% 以内。这就需要为 DB 结点预置足够的硬件资源,而这些预置的资源是按照 峰值流量计算的,从而在大部分时间内,这些预置的资源都是 浪费的!
这里矛盾的地方在于:前台 Query 是低 延迟优先,后台 Compact 是 吞吐率优先。实现高吞吐率 既可以通过堆硬件来实现, 也可以通过提高硬件(CPU)利用率来实现;但是低延迟(特别是P99), 很难在高负载(CPU利用率)的工况下实现。所以在现实中只能两害相权取其轻。
因为 Compact 对延迟不敏感,所以我们把它转移到专用集群中,专用集群可以把 CPU 负载跑到很高(例如90%),从而大幅提升资源的利用率。
3. 在 LSM 的写负载中,80% 甚至 90% 以上的计算,都是 Compact
在这一点上,LSM 是天选之子,正因为 Compact 占比这么大,把它转移(Offload)出去,才能获取更大的收益。所以对这方面的探索是业界的一个重要方向,例如阿里云就尝试过把 Compact 转移到 FPGA。
与之相对的,BTree 就不行。
把 Compact 转移到专用集群,我们就不需要为 DB 结点预置过高的硬件资源,或者说,使用相同规格的 DB 结点,我们可以实现高得多的服务能力。结合存算分离,同一DB实例的多个结点共用同一份存储(存储也是多副本的),相比 Spanner Share Nothing 架构,既减小了存储成本,也减小了计算成本(只需要一次 Compact)。
另一方面,在 Compact 集群中,不光资源利用率得到了大幅提升,我们还可以利用云平台的空闲算力,例如阿里云的抢占式实例,AWS 的 Spot Instance,价格最低只有标准价格的一折,根据我们大量使用中的统计,均价大约是两折。
问题:MyTopling 分布式 Compact 特有的问题
从上面可以看到,在我们的分布式 Compact 架构上,MyTopling 实例与 Compact Worker(后面简称 Worker)是多对多的,用白话说就是同一个 Worker 可以服务来自多个不同的 MyTopling 实例的 Compact 任务,同一个 MyTopling 实例的多个 Compact 任务也会由多个不同的 Worker 执行。
这个架构在 MyTopling DB 结点这边没啥问题,但是在 Worker 端就有问题了,因为 Worker 是多线程架构。其实多线程架构本来没啥问题,在 Todis 中,它就工作得很好。
真正问题在于:MyTopling fork 自上游 MyRocks,而 MyRocks 使用了大量的全局变量(全局数据字典、统计信息等等),我们的分布式 Compact 直接复用了 MyRocks 的代码,这样就导致,当同一个 Worker 服务不同 MyTopling 实例的 Compact 任务时,全局变量就会冲突混淆!
要解决这个问题,我们要么修改代码,把全局变量都消除掉,要么在架构上支持这种 不太规范 的应用。经过仔细思考,我们选择了后者,原因在于:
- 把全局变量都消除掉,工作量太大,并且会导致与上游 MyRocks 的分裂,后期将难以合并上游代码,无法复用上游开源社区新的贡献
- 把全局变量都消除掉,只是针对 MyTopling,违背了软件复用的原则
- 在架构上支持全局变量,虽然难度较大,但是工作是一次性的,适用于任何上层 DB
从多线程到多进程
设计决策定下来了,接下来就是实现,这需要将多线程模型改成多进程模型。为了最小化工作量,我们使用了“微创手术”修改法,主要包括以下修改:
- 在 Worker 程序中,把执行 Compact 的代码,包在新 fork 出来的子进程中
- 实现中碰到一个小问题,子进程在执行 ::exit 时,陷入了死锁,最后直接通过 ::_exit 解决掉
- 关于 ::exit 和 ::_exit,备战面试的同学们需要仔细了解下
- 提示:exit 是 C 库函数,会执行 C++ 全局变量的析构,然后调用 _exit 来结束进程
- 提示:_exit 是系统调用,作用是释放进程占有的OS资源,然后结束进程
- 实现中碰到一个小问题,子进程在执行 ::exit 时,陷入了死锁,最后直接通过 ::_exit 解决掉
- 在 ToplingZipTable 中,分离出一个 ZipServer 进程,执行 Topling 压缩算法
- 在 Topling PA-Zip 算法中,数据的压缩在一个多线程 Pipeline 中执行,并且通过一些技巧来最大化 CPU L2/L3 的利用率,跟不使用 Pipeline 相比,性能可以提高 40% 以上
- 在多线程架构中,Compact 线程将每条原始 Value 提交到 Pipeline 的队列
- 在多进程架构中,Compact 线程将保存了所有原始 Value 的文件名(通过本地 Http 调用)提交给 ZipServer 进程,在 ZipServer 进程内部,执行原先多线程架构中的压缩计算,压缩结束后 Http 调用返回给客户端(Compact 线程)
- 在具体实现上,使用本地 127.0.0.1 http 服务,通过 json 传递元数据,通过文件传递大块数据,中等长度和较短的二进制数据,通过 process_vm_readv/writev 来传递。
- 为了最小化对外依赖,http server 我们继续使用(内嵌的)civetweb,http client 使用 libcurl,期间遭遇了一个 libcurl 的 Expect: 100-continue 问题,这充分说明,即便是象 libcurl 这样千锤百炼的基础组件,也得防范它们的“天坑”
- 在 Topling PA-Zip 算法中,数据的压缩在一个多线程 Pipeline 中执行,并且通过一些技巧来最大化 CPU L2/L3 的利用率,跟不使用 Pipeline 相比,性能可以提高 40% 以上
最后,我们得到了一个惊喜:在 MySQL 的分布式 Compact 开发完成之前,我们使用 Todis 来测试多进程模型(使用 wikipedia 数据),发现 Worker 的吞吐率竟然提升了 30%,在双路至强 E5-2682(共32核64线程)上,单 Worker 结点的 Compact 吞吐率达到 900MB/sec,而多线程模型中吞吐率不到 700MB/sec。我们猜测,可能是因为多进程中锁的冲突降低,同时因为资源隔离,操作系统也可以进行更好的调度!
还有一个值得庆幸的是:compact worker 中,我们直接使用了 RocksDB 的内部模块,通过读取 DB 提交过来的 Compact 元信息,构造一个 VersionSet,然后调用 CompactionJob …… 但是这样直接使用 RocksDB 的内部模块,触发了 RocksDB 的一个 Bug —— 有个引用计数偶尔会提前归零从而对象被提前释放,导致后续内存错误,进程崩溃,这个问题之前在 todis 的 分布式 Compact 中也偶尔出现,但概率很低,在 MyTopling 中出现的概率提高了很多,折腾了很久,也没有任何头绪,最后是暴力修改:
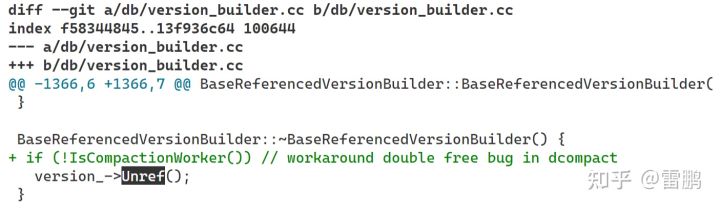
在 Compact Worker 中,干脆不调用这个 Unref,从而在 version_ 的 refcnt 错误地提前归零时,避免了后面的内存错误和 coredump,而在 version_ 的 refcnt 没有提前归零时,会导致这个 version 对象泄露。多进程的好处在此刻就体现出来了,泄露就泄露呗,反正进程退出时所有东西都释放了!
以前 todis 分布式 compact 也触发这个问题导致 coredump,好像问题很严重!其实根本不是啥大事,compact worker 本来就是无状态的,进程崩溃就自动重启,DB 这边发现 compact 失败就重试,系统工程的魅力在此得到了完美体现:通过合理的系统设计,用不可靠的组件,实现可靠的完整系统。















 124
124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









