







AI 时代学什么,怎么学 / 2024.9

要是没有线性代数,任何数学和初等教程都讲不下去。按照现行的国际标准,线性代数是通过公理化来表述的。它是第二代数学模型,其根源来自于欧几里得几何、解析几何以及线性方程组理论。如果不熟悉线性代数的概念,像线性性质、向量、线性空间、矩阵等等,要去学习自然科学,现在看来就和文盲差不多,甚至可能学习社会科学也是如此。
——L·戈丁《数学概观》
本文来自:《人工智能数学基础》陈华主编

线性代数不仅是人工智能的基础,而且是现代数学和以现代数学为主要分析方法的众多学科的基础。无论是图像处理还是量子力学,都离不开向量和矩阵的使用。线性代数中的向量和矩阵为人工智能提供了一种特征描述的组合方式,将具体事物抽象为数学对象,描述事物发展的静态和动态规律。线性代数的核心意义在于提供了一种看待世界的抽象视角:万事万物都可以被抽象成某些特征的组合,在预置规则定义的框架下,世界被以静态和动态的方式加以观察。
向量和矩阵
人工智能很多场景中的数据结构都采用了向量和矩阵。
向量和矩阵不只是理论上的分析工具,也是计算机工作的基础条件。人类能够感知连续变化的大千世界,可计算机只能处理离散取值的二进制信息,因此,来自模拟世界的信号必须在定义域和值域上同时进行数字化,才能被计算机存储和处理。从这个角度来看,线性代数是用虚拟数字世界表示真实物理世界的工具。
向量是人工智能中的一个关键数据结构。在计算机存储中,标量占据的是零维数组;向量占据的是n维数组。人工智能领域主要将向量理解为n维空间上的点。例如,三维空间中的一个向量可以表达为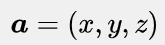 。一个数据集也可以很方便地表示为一个n维向量。
。一个数据集也可以很方便地表示为一个n维向量。
矩阵占据的是二维数组。矩阵可以看作向量的组合。在计算机视觉领域,矩阵可用来表示图像。图像的基本单位是像素,一幅图像是由固定行列数的像素组成的,如果每个像素都用数字表示,那么一幅图像就是一个矩阵。对于灰度图像来说,每个像素对应一个数字。
张量占据的是三维乃至更高维度的数组,如RGB图像和视频可用表示三原色的三个数字表示。
范数和内积
范数和内积是描述作为数学对象的向量时用到的特定的数学语言。范数是对单个向量大小的度量,描述的是向量自身的性质,其作用是将向量映射为一个非负的数值。通用的Lp范数定义如下:
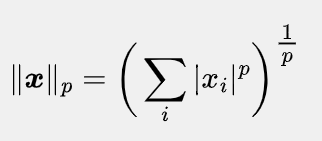
范数计算的是单个向量的尺度,而内积能够表示两个向量之间的相对位置,即表示向量之间的夹角。两个相同维数的向量内积的表达式为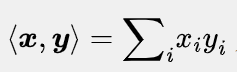 ,即对应元素相乘后求和。一种特殊的情况是内积为0,在二维空间中,这意味着两个向量的夹角为90°,即相互垂直。而在高维空间中,这种关系被称为正交(Orthogonality)。如果两个向量正交,则说明它们线性无关,相互独立,互不影响。
,即对应元素相乘后求和。一种特殊的情况是内积为0,在二维空间中,这意味着两个向量的夹角为90°,即相互垂直。而在高维空间中,这种关系被称为正交(Orthogonality)。如果两个向量正交,则说明它们线性无关,相互独立,互不影响。
在实际问题中,向量不仅表示某些数字的组合,更可能表示某些对象或某些行为的特征。范数和内积能够处理这些表示特征的数学模型,进而提取原始对象或原始行为中的隐含关系。
如果有一个集合,它的元素都是具有相同维数的向量(可以是有限个或无限个),并且定义了加法和数乘等结构化的运算,那么,这样的集合称为线性空间,而定义了内积运算的线性空间称为内积空间。在线性空间中,任意一个向量代表的都是n维空间中的一个点;反过来,空间中的任意点也可以唯一地用一个向量表示,两者相互等效。

在线性空间上的点和向量相互映射时,一个关键问题是参考系的选取。在现实生活中,只要给定经度、纬度和海拔高度,就可以唯一地确定地球上的一个位置,因此,经度值、纬度值、高度值构成的三维向量(x,y,z)就对应了三维物理空间中的一个点。但是,在高维空间中,坐标系的定义就没有这么直观了。要知道,人工神经网络处理的通常是数以万计的特征,对应的同样是数以万计的复杂空间,要描述这样的高维空间,就需要用到正交基的概念。
在内积空间中,一组两两正交的向量构成了这个空间的正交基。假如正交基中基向量的范数都是单位长度1,则这组正交基就是标准正交基。正交基的作用是给内积空间定义经纬度。一旦描述内积空间的正交基确定了,向量和点之间的对应关系也就随之确定了。值得注意的是,描述内积空间的正交基并不唯一。对于二维空间来说,平面直角坐标系和极坐标系就对应了两组不同的正交基,也代表了两种实用的描述方式。
线性变换
线性空间的一个重要特征是能够承载变化。当作为参考系的标准正交基确定后,空间中的点就可以用向量表示。当这个点从一个位置移动到另一个位置时,描述它的向量自然也会改变。点的变化对应着向量的线性变换,而描述对象变化或向量线性变换的数学语言正是矩阵。
在线性空间中,变化的实现有两种方式:一是点本身的变化,二是参考系的变化。在第一种方式中,使某个点发生变化的方法是用代表变化的矩阵乘以代表点的向量。如果保持点不变,而换一种观察的角度,那么也能得到不同的结果。在这种情况下,矩阵的作用就是对正交基进行变换。因此,对矩阵和向量的乘积就存在不同的解读Ax=y:这个表达式既可以理解为向量x经过矩阵A所描述的变换变成了向量y;也可以理解为一个对象在坐标系A的度量下得到的结果为向量x,在标准坐标系I 的度量下得到的结果为向量y。这表示矩阵不仅能够描述变化,也可以描述参考系本身。
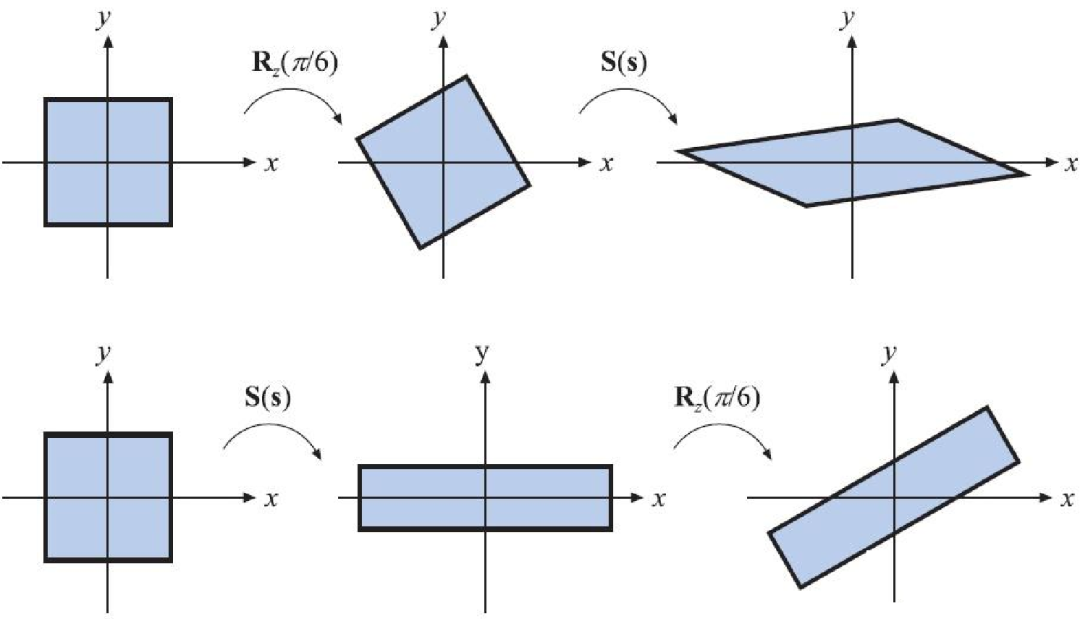
线性回归是描述变量关系常见的处理方法,是人工智能的基础算法。描述和解决线性回归问题的方法有很多,其旨在找到一组系数,使得输出的变量预测为最佳。
使用线性代数方法很容易得到最小二乘意义上的解。对于输入向量矩阵和输出向量,如果要找到一组最优的系数,使得预测误差最小,那么这个问题可以表示为求解如下线性方程组:
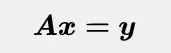
通常在线性回归问题中,矩阵A 是不可逆的,此时就需要用伪逆来求方程组在最小二乘意义下的最优解。将方程两边同时左乘A^T,就可以解出参数x:
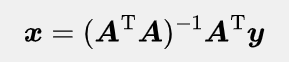
这称为正则方程,它可以在很多人工智能应用场景中用于快速求得最优解。
正如前文所述,矩阵代表了向量的变换,其效果通常是对原始向量同时施加方向变化和尺度变化。但对于一些特殊的向量,矩阵只能改变尺度而无法改变方向,也就是只有伸缩的效果而没有旋转的效果。对于给定的矩阵,这类特殊的向量即矩阵的特征向量,特征向量的尺度变化系数就是特征值。
矩阵特征值和特征向量的动态意义在于表示了变化的速度和方向。如果把矩阵所代表的变化看作奔跑的人,那么矩阵的特征值就代表了这个人奔跑的速度,特征向量就代表了这个人奔跑的方向。但是,矩阵可不是普通人,它是有多个分身的人,其不同分身以不同速度(特征值)在不同方向(特征向量)上奔跑,所有分身的运动叠加在一起才是矩阵的效果。求解给定矩阵的特征值和特征向量的过程叫作特征值分解,但能够进行特征值分解的矩阵必须是n维方阵。将特征值分解算法推广到所有矩阵,则可以得到更加通用的矩阵分解方法——奇异值分解。
奇异值分解(SVD)
奇异值分解是线性代数中的一种矩阵分解方法,在人工智能领域应用非常广泛,如用于特征选择、降噪、数据压缩、主成分分析(PCA)等方面。其表达式如下:A=UΣV’(V'即U^T)
矩阵经过奇异值分解后会得到一系列系数,抛弃其中某些较小的系数,对原矩阵重建,则重建后误差很小。可以认为较小的系数代表了原信号的粗略信息或低频信息,忽略这部分并不影响原信号的表达,而大的系数代表了原信号的重要信息或高频信息。这样,就可以根据这一特性进行特征选择、主成分提取和数据压缩等操作。
例如,下图中图(a)是原始图像,图(b)~图(d)是用SVD重构的图像,图(b)取了前10个特征,图(c)取了前20个特征,图(d)取了前40个特征。可以看到,图(b)反映了原始图像的基本信息,且随着特征数的提高,图像细节变得更清晰。

线性代数的基本原理在人工智能算法中处于核心地位,在人工智能的语义分析、推荐系统、卷积神经网络等方面有大量应用,是目前最前沿的深度学习算法原理的基础。
推荐阅读

《中国人工智能简史:从1979到1993》
作者:林军 岑峰 著
出版时间:2023.8
出版社:人民邮电出版社
作者团队深入采访了全国十余所主要高校、中科院多个研究所老中青三代人工智能研究者,重点介绍中国人工智能领域杰出的科学家,以及他们创造非凡成果的有趣故事。
本书梳理了自 1979 年至 1993 年中国人工智能领域初期十多年的发展历程,用轻松而真诚的笔触,讲述了为中国人工智能发展寻路的奠基者,并介绍了重要历史事件的来龙去脉,带领读者深入了解中国人工智能发展早期鲜为人知的历史。

[美] 斯图尔特·罗素(Stuart Russell)[美]彼得·诺维格(Peter Norvig) 著,
张博雅,陈坤,田超,顾卓尔,吴凡 ... 译,张志华 校
吴军、黄铁军作序推荐
揭示AI与chatgpt的奥秘,详解人工智能的发展与未来!
本书全面、深入地探讨了人工智能(AI)领域的理论和实践,以统一的风格将当今流行的人工智能思想和术语融合到引起广泛关注的应用中,真正做到理论和实践相结合。
本书可作为高等院校人工智能相关专业本科生、研究生教材,也是相关领域专业人员的一本参考书。

《概率导论(第2版·修订版)》
作者:[美] 迪米特里·伯特瑟卡斯,[美] 约翰·齐齐克利斯
译者:郑忠国 童行伟
从直观、自然的角度阐述概率;适合理工科学生入门,便于自学。
本书多年来在美国麻省理工学院、斯坦福大学、加州大学等名校被用作概率课程教材,经过课堂检验和众多师生的反馈得以不断完善,是一本在表述简洁和推理严密之间取得优美平衡的经典作品。

《普林斯顿概率论读本》
作者:[美] 史蒂文·J. 米勒(Steven J. Miller)
译者:李馨
普林斯顿读本三剑客之概率论,概率论教材,叙述深入浅出,提供课程视频和讲义,概率论学习图书。
对于学生来说,学习概率论及其众多应用、技术和方法似乎非常费力且令人生畏,而这正是本书的用武之地。这本通俗易懂的学习指南旨在用作概率论的独立教材或相关课程的补充材料,可帮助学生轻松地学习概率论知识并取得良好效果。
本书基于史蒂文·J. 米勒在布朗大学、曼荷莲学院和威廉姆斯学院教授的课程而作。米勒通过先修课程材料、各种难度的问题及证明对概率论这一数学领域进行了详细介绍。探索每个主题时,米勒首先引导学生运用直觉,然后才深入技术细节。本书涵盖的主题很广,并且对材料加以重复以强化知识。读完本书,学生不仅能掌握概率论,还能为将来学习其他课程打下基础。

《概率论沉思录》
作者:埃德温·汤普森·杰恩斯
译者:廖海仁
著名数学物理学家,圣路易斯华盛顿大学和斯坦福大学教授,统计力学和概率统计推断方面权谋埃德温·汤普森·杰恩斯,40年思想著作;
无数读者苦等15年的概率论神作,英文版豆瓣评分9.4高分;
概率论作为逻辑的延伸,是所有科学推断的基础。本书收集了概率统计的各种线索,将概率和统计推断融合在一起,用新的观点生动地描述了概率论在物理学、数学、经济学、化学和生物学等领域中的广泛应用,尤其是阐述了贝叶斯理论的丰富应用,弥补了传统概率论和统计学的不足,并揭开了众多悖论背后的玄机。
长按二维码—识别—关注















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









