






大家好,我是对白。
在我们做一个项目或业务之前,需要了解为什么要做它,比如为什么要做文本分类?项目开发需要,还是文本类数据值得挖掘。
1、介绍
目前讨论文本分类几乎都是基于深度学习的方法,本质上还是一个建模的过程,包括数据准备-预处理-模型选择-模型调优-模型上线这样的一套流程。在本地进行文本分类开发我们需要关注的两个主要的问题:数据处理和模型选择,这两者是相互依赖的。
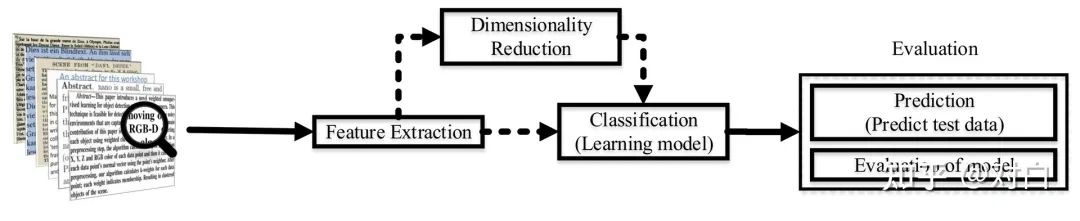
图1 文本分类的步骤
文本分类可以根据文本的大小可以分为如下几种:
文本级别: 对整篇文章进行分类
段落级别: 对单独的段落分类
句子级别: 对句子进行分类
子句级别: 对句子的一部分进行识别(命名体识别不就是这个吗)
介绍图所示也分为三个部分,特征提取、分类模型、评估指标。
2、特征提取(Representation)
介绍文本数据清洗的几种方法和两种特征提取方法,Embedding和Weighted Words。
2.1 数据清洗
在自然语言处理(NLP)中,大多数文本和文档都包含许多冗余的单词,例如StopWords,Miss-Mermilings,Slangs等。在许多算法中,如统计和概率学习方法,噪声和不必要的特征可以对整体性能产生负面影响。
Tokenization
中文有的翻译称之为分词,将句子切成小块称之为token。
python中
from nltk.tokenize import word_tokenizetext = "After sleeping for four hours, he decided to sleep for another four"tokens = word_tokenize(text)print(tokens)# result['After', 'sleeping', 'for', 'four', 'hours', ',', 'he', 'decided', 'to', 'sleep', 'for', 'another', 'four']# 中文文本text = "我在华为工作"print(" ".join([s for s in jieba.cut(text)]))# results我 在 华为 工作Stop words
中文翻译:停用词。通过社交媒体(如Twitter,Facebook等)的文本和文档分类通常受到文本语料中的嘈杂性质(缩写,不规则形式)的影响。简而言之,过滤掉一些词。
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = "This is a sample sentence, showing off the stop words filtration."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
print(word_tokens)
print(filtered_sentence)
# results
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing', 'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop', 'words','filtration', '.']使用stopwords也是很简单,分词做一个字典或者集合进行筛选即可,这里不再赘述。
Capitalization
中文名字:资本化?句子可以包含大写和小写字母的混合。多个句子构成文本文档。为了减少问题空间,最常见的方法是将一切降低到小写。这将在同一空间的文档中带来所有单词,但它通常会改变某些词的含义,例如“美国”到“我们”,第一个代表美国和第二个是代名词。要解决此问题,可以应用俚语和缩写转换器。什么叫缩写转换器?盲猜应该就是一个hashmap。
text = "The United States of America (USA) or America, is a federal republic composed of 50 states"
print(text)
print(text.lower())
# results
'The United States of America (USA) or America, is a federal republic composed of 50 states'
'the united states of america (usa) or america, is a federal republic composed of 50 states'Slangs and Abbreviations
谚语和缩写。在进行常规的文本分类的时候,希望将谚语翻译,缩写变为全称是的数据分布保持一致。当然,不一定非得对此进行处理,如果针对缩写和谚语的数据集和模型构建那则不需要考虑此问题。
Noise Removal
噪音消除。其实就是使用正则表达式过滤掉一些错误或者无关紧要的字符,使得数据尽可能对齐。
英文常用的手段
def text_cleaner(text):
rules = [
{r'>\s+': u'>'}, # remove spaces after a tag opens or closes
{r'\s+': u' '}, # replace consecutive spaces
{r'\s*<br\s*/?>\s*': u'\n'}, # newline after a <br>
{r'</(div)\s*>\s*': u'\n'}, # newline after </p> and </div> and <h1/>...
{r'</(p|h\d)\s*>\s*': u'\n\n'}, # newline after </p> and </div> and <h1/>...
{r'<head>.*<\s*(/head|body)[^>]*>': u''}, # remove <head> to </head>
{r'<a\s+href="([^"]+)"[^>]*>.*</a>': r'\1'}, # show links instead of texts
{r'[ \t]*<[^<]*?/?>': u''}, # remove remaining tags
{r'^\s+': u''} # remove spaces at the beginning
]
for rule in rules:
for (k, v) in rule.items():
regex = re.compile(k)
text = regex.sub(v, text)
text = text.rstrip()
return text.lower()处理中文的时候我们可能需要删除一些无用的英文字符,或者无效的数字。
Spelling Correction
语法错误自动纠正。
英文案例比较简单
from autocorrect import Speller
slr = Speller()
print(slr.autocorrect_word('caaaar'))
print(slr.autocorrect_word(u'mussage'))
print(slr.autocorrect_word(u'survice'))
print(slr.autocorrect_word(u'hte'))
# results
"aaaaaa"
"message"
"service"
"the"中文的自动纠错
import pycorrector
corrected_sent, detail = pycorrector.correct('少先队员因该为老人让坐')
print(corrected_sent, detail)
# results
少先队员应该为老人让座 [['因该', '应该', 4, 6], ['坐', '座', 10, 11]]修正后在分词,目前也有基于深度学习的文本纠正。
2.2 Weighted Words
term-frequency~(TF)
基于出现的频率做单词到数字的映射。
出现的次数。
出现次数的对数。或者使用布尔值表示?
如果使用一个等长的向量,其中的位置表示为单词的频率信息,这样做容易导致的问题是什么?出现频率高的单词决定了单词的表示。
加权字表示,TF-IDF在文档中术语重量的数学表示:
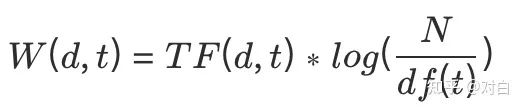
其中n是文档的数量,df(t)是包含语料库中术语t的文档的数量。
可以通过 如下方式实现。
from sklearn.feature_extraction.text import TfidfVectorizer2.3 Embedding
使用较低维度的向量表示文本中的单词。
机器学习中的编码思路。
方法一:one-hot
存在的问题:
1. 效率低下,一个独热编码向量十分稀疏(这意味着大多数索引为零);
2. 数据中的单词集合越大,编码后的向量长度越长3. 任意两个词正交,无法较好的度量词之间的相关性;
方法二:int
存在的问题:
1. 整数编码是任意的(它不会捕获单词之间的任何关系);2. 对于要解释的模型而言,整数编码颇具挑战。例如,线性分类器针对每个特征学习一个权重。由于任何两个单词的相似性与其编码的相似性之间都没有关系,因此这种特征权重组合没有意义;
Embedding 层
不同的框架下的Embedding层的作用是什么?需要注意的两点
解决one-hot编码无法提取词之间的相关性的问题,方法是通过训练一个权重矩阵(矩阵的大小为(m,n)m表示训练数据中的单词集合的大小,n通常称之为词向量的大小,即压缩后的维度大小。矩阵中的参数通过目标任务反向传播进行学习。
在前向传播不采用one-hot编码后的矩阵进行输入,采用int编码进行查表操作来代替矩阵相乘来加速。
Word2Vec
Embedding层虽然可以学习到词的低维度表示,但是在数据样本比较小的情况下,仅仅通过目标任务学习巨大的Embedding矩阵往往效果不是理想。
联想到,图片分类中的image数据的预训练权重,在文本分类中也希望通过巨大预料数据提前得到单词的预训练权重,然后在小的数据集上进行迁移学习以提升模型的精度。Word2Vec是在此想法下的产物,与文本分类预训练有几点不同。
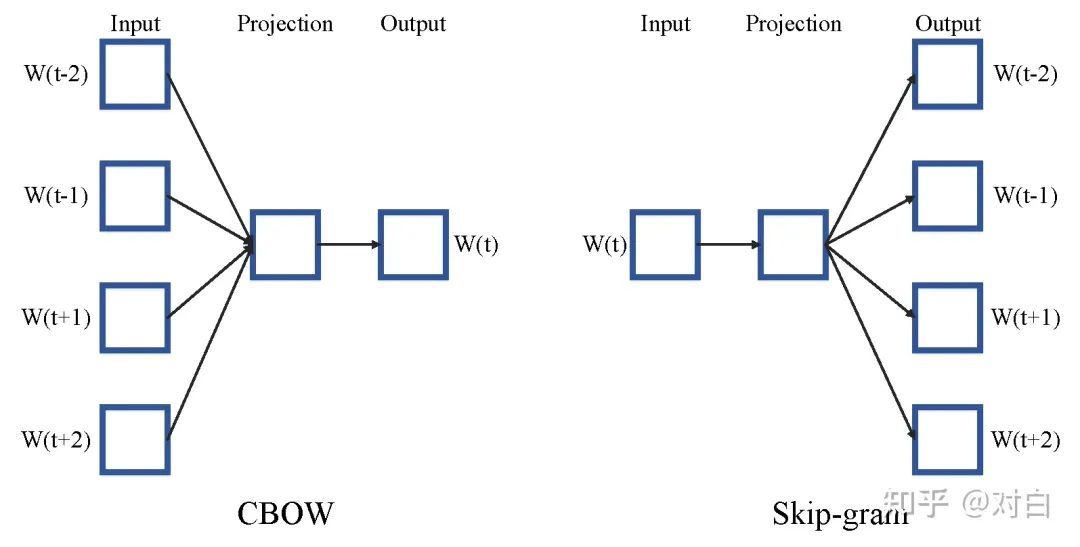
以Skip-gram为例简单介绍:
The wide road shimmered in the hot sun.句子中的每个单词的上下文词被窗口打下指定,样例如下。对于窗口长度n,考虑上下文,意味着每个单词对应的窗口长度为2*n+1。
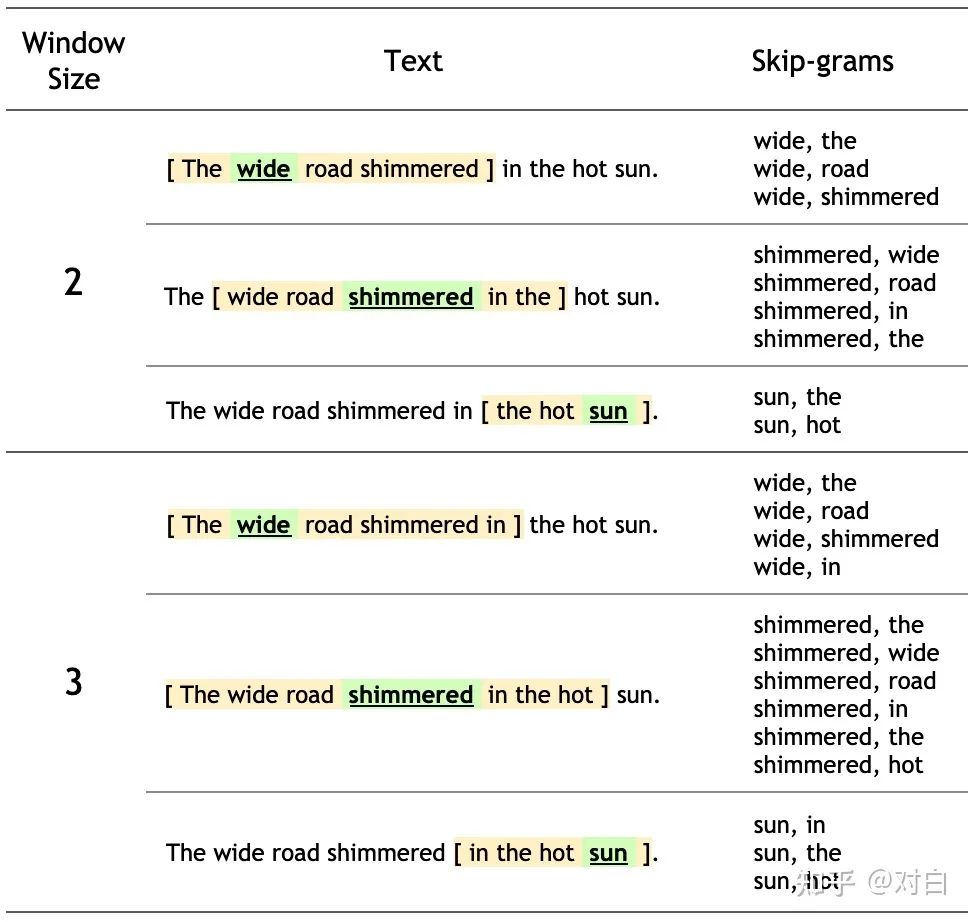
词编码在Embedding中写过,首先使用one-hot编码然后喂入网络,在word2vec中也使一样的。不过这里的目标是给定一个词的one-hot编码,学习的是skip-gram pair,因此网络定义如下:
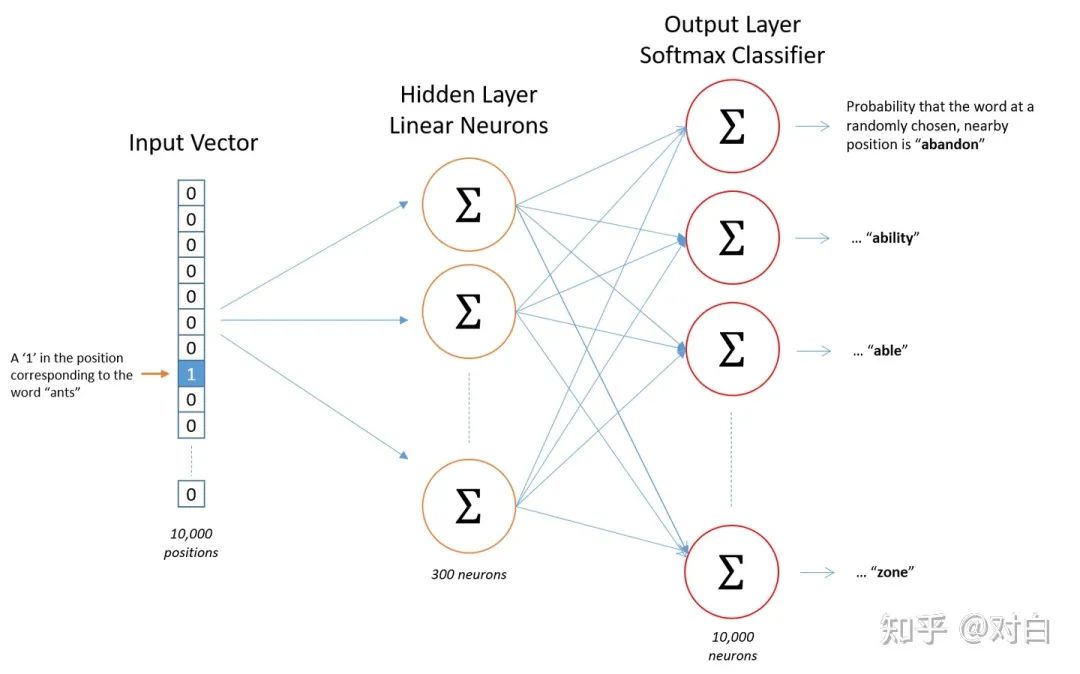
如上图所示:隐层没有使用任何激活函数,但是输出层使用了sotfmax。基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,10000表示词本中单词的个数,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
FastText
FastText和Word2Vec之间有什么联系和区别。
相同点,学习得到低维度词向量表示。
不同点,FastText使用了subwords这种更细粒度的特征。
FastText的结构如下,可以直接应用于文本分类任务,隐藏层使用求和使得模型十分高效。
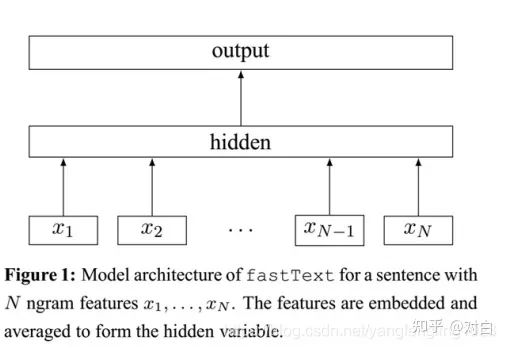
GloVe
全局向量表示,使用词频信息+上下文信息的一种词向量表示。官方网站:https://nlp.stanford.edu/projects/glove/
三步走:
根据语料库(corpus)构建一个共现矩阵(Co-ocurrence Matrix)X,矩阵中的每一个元素Xij代表单词i和上下文单词j在特定大小的上下文窗口(context window)内共同出现的次数。一般而言,这个次数的最小单位是1,但是GloVe不这么认为:它根据两个单词在上下文窗口的距离d,提出了一个衰减函数(decreasing weighting):decay=1/d用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小。
构建词向量(Word Vector)和共现矩阵(Co-ocurrence Matrix)之间的近似关系,论文的作者提出以下的公式可以近似地表达两者之间的关系:
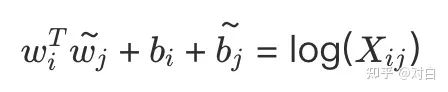
其中,wiT和wj~是我们最终要求解的词向量;bi和bj~分别是两个词向量的偏置。
损失函数
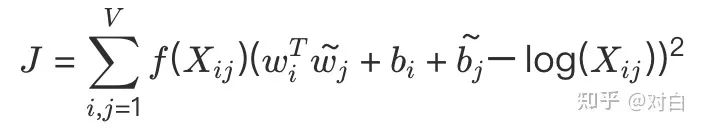
这个loss function的基本形式就是最简单的mean square loss,只不过在此基础上加了一个权重函数f(Xij),那么这个函数起了什么作用,为什么要添加这个函数呢?我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的(frequent co-occurrences),那么我们希望:
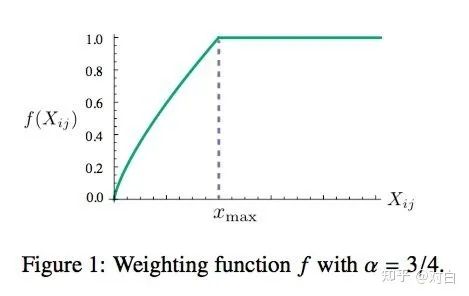
1.这些单词的权重要大于那些很少在一起出现的单词(rare co-occurrences),所以这个函数要是非递减函数(non-decreasing);
2.但我们也不希望这个权重过大(overweighted),当到达一定程度之后应该不再增加;
3.如果两个单词没有在一起出现,也就是Xij=0,那么他们应该不参与到loss function的计算当中去,也就是f(x)要满足f(0)=0
满足以上两个条件的函数有很多,作者采用了如下形式的分段函数,(xmax=100,α=0.75):
Contextualized Word Representations
预训练是否存在其他的表征方式,word2vec这种表示方法的缺点是什么?
缺乏语义信息
中文的预训练模型:https://github.com/HIT-SCIR/ELMoForManyLangs
上下文词表示,ELMO是一个深刻的语境化词表示,可以处理(1)单词的复杂特征(例如,语法和语义)(2)这些用途在语言上下文(即,模型多义)上的不同方式变化。这些单词vectors是学习的深度双向语言模型(BILM)的内部状态的函数,该函数在大型文本语料库上预先训练。
ELMo representations are:
Contextual: 每个单词的表示取决于它使用的整个上下文。
Deep: 每个单词的表示组合了深度预先训练的神经网络的所有层。
Character based: Elmo表示是基于纯字符级别的,允许网络使用形态线索学习不属于词表中的单词表示。
2.3 不同特征提取的优缺点
一、Weighted Words:
优点:
容易计算
使用此方法容易计算两个文档的相似度
提取文档具有代表性的基础指标
未知单词也可以工作
缺点:
不能捕捉位置关系
不能捕捉语义信息
高频单词容易影响结果(例如 is,as)
二、TF-IDF:
优点:
容易计算
使用此方法容易计算两个文档的相似度
提取文档具有代表性的基础指标
高频单词影响较小
缺点:
不能捕捉位置关系
不能捕捉语义信息
三、Word2Vec:
优点:
捕捉位置关系
捕捉语义信息
缺点:
无法从文本中捕捉单词的意思,多义性无法支持
受词表限制
四、GloVe (Pre-Trained):
优点:
捕捉位置关系
捕捉语义信息
基于大语料训练
缺点:
无法从文本中捕捉单词的意思,多义性无法支持
内存消耗严重,需要存储近似矩阵
受词表限制
五、GloVe (Trained):
优点:
非常简单,捕捉线性关系优异(performs better than Word2vec)
对于高度频繁的单词对的重量较低,例如“am”,“is”等的单词将不会影响太大
缺点:
内存消耗严重,需要存储近似矩阵
需要大量的语料数据支持
受词表限制
无法从文本中捕捉单词的意思,多义性无法支持
六、FastText:
优点:
适用于少量的单词
在字符水平中用n-gram解决受词表限制的问题
缺点:
无法从文本中捕捉单词的意思,多义性无法支持
内存消耗严重
计算开销比GloVe 和 Word2Vec更大
七、Contextualized Word Representations:
优点:
动态的单词表示
缺点:
存储开销大
显著提高下游性能但是计算开销大
需要额外的word embedding
受词表限制
仅能服务于句子和文章级别
3、模型介绍
在做文本分类的过程中,模型的设计其实包括上述介绍的词向量的获得,尽可能希望得到如下的信息
词向量可以充分表征文本原来的意思
词向量可以表征语义信息
模型可以提取样本级别的整体特征表示,然后+Softmax便可以实现分类
3.1 基于静态词向量的网络
为啥使用静态词向量+LSTM前后文无法充分表征语义信息?个人揣测,使用静态词向量的网络通常是在小数据上基于给定任务训练,难以捕捉比较好的语义信息。
3.1.1 FastText
本质上应该属于Word2Vec+单层的网络+H-softmax。
3.1.2 TextCNN
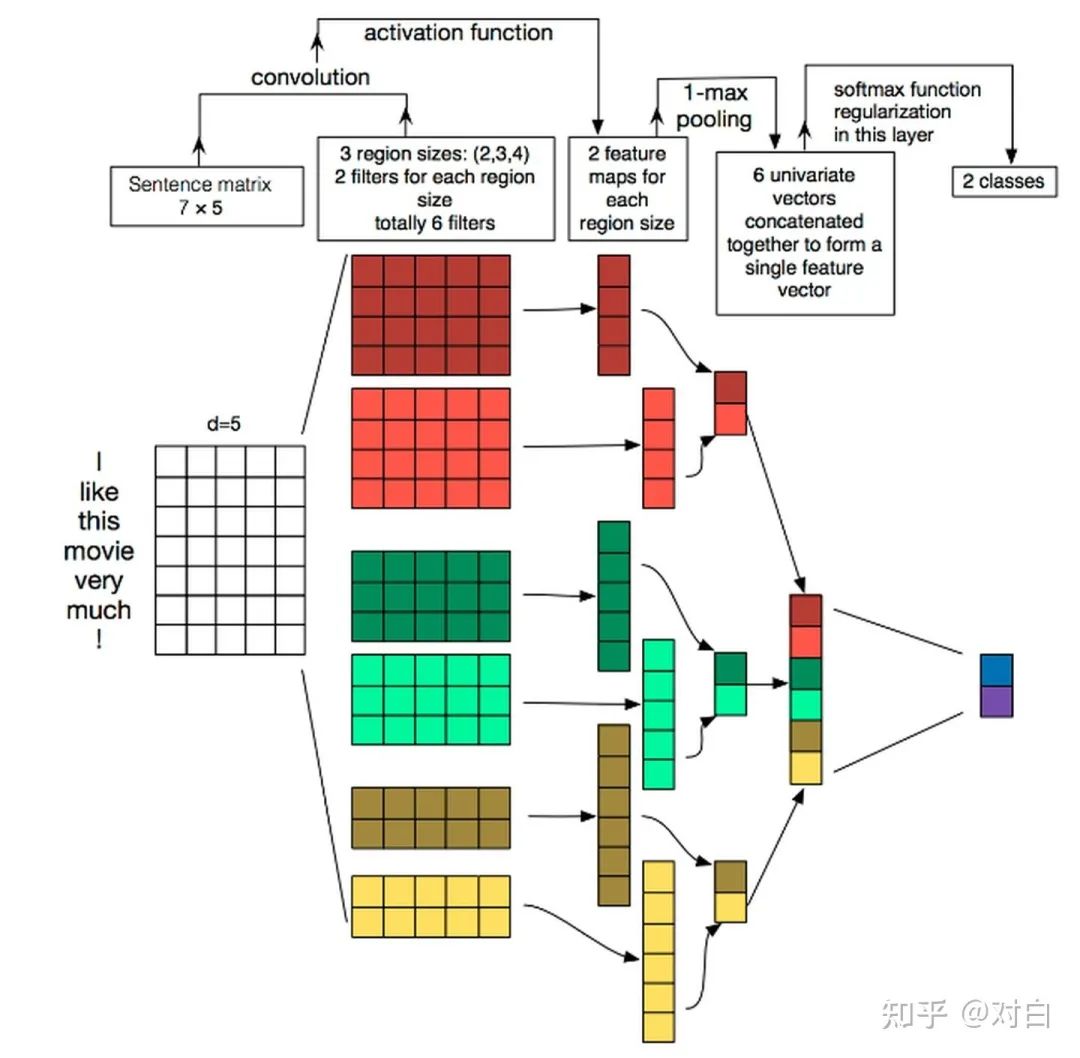
本质上使用Word2Vec+CNN
TextCNN详细过程:
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
FullConnection and Softmax:最后接一层全连接的softmax层,输出每个类别的概率。
3.1.3 TextRNN

3.2 基于动态词向量的网络
为什么使用动态此向量?
word级别到数值向量的映射不足以完全表征上下文的信息,我们希望基于上下文训练对应的词向量表示,即我们希望在句子级别或者更高的级别对文本进行编码。
就好比,我仅使用mlp对图像进行学习不如CNN可以提取空间信息更加有效的意思?
主要的模型有:
GPT、Bert、XLNet等,这部分的技术原理仍旧需要时间来仔细分析,但是我们最终的目的是如何在项目中有效使用,所以做一下简要的介绍。
3.2.1 Bert
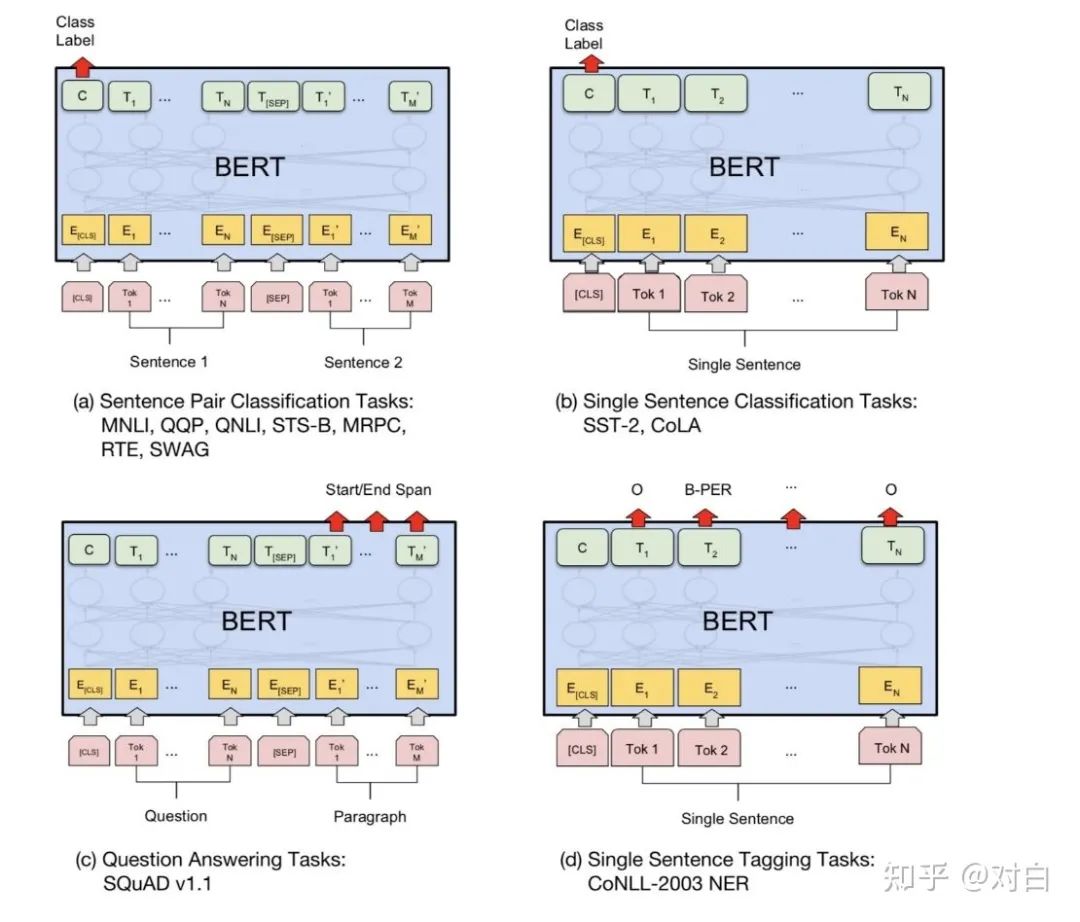
BERT是一种预训练语言表示的方法,他将NLP模型的建立分为了两个阶段:Pre-training和fine-tuning。Pre-training是为了在大量文本语料(维基百科)上训练了一个通用的“语言理解”模型,然后用这个模型去执行想做的NLP任务。Fine-training则是在具体的NLP任务上进行相应的微调学习。
Bert模型结构主要是采用了transformer的编码结构,其主要创新点在于其训练方式采用了1)它在训练双向语言模型时以减小的概率把少量的词替成了Mask或者另一个随机的词。感觉其目的在于使模型被迫增加对上下文的记忆。2)增加了一个预测下一句的loss,迫使模型学习到句子之间的关系。
输入表示:
论文的输入表示(input representation)能够在一个token序列中明确地表示单个文本句子或一对文本句子(例如, [Question, Answer])。对于给定token,其输入表示通过对相应的token、segment和position embeddings进行求和来构造。图2是输入表示的直观表示:
关键创新:预训练任务
任务1: Masked LM
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
任务2:下一句预测
在为了训练一个理解句子的模型关系,预先训练一个二进制化的下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。
通过采用以上两种预训练方式,使得模型能够具有语义表征性质,在fine-tuning阶段就可以搭连一个NN结构完成文本分类任务。
4、评估指标
ACC
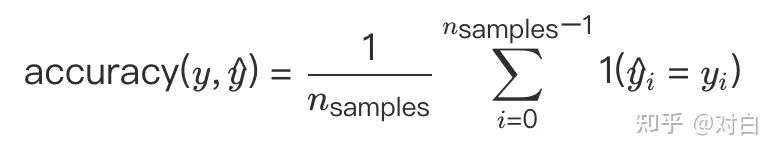
>>> import numpy as np
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0, 2, 1, 3]
>>> y_true = [0, 1, 2, 3]
>>> accuracy_score(y_true, y_pred)
0.5
>>> accuracy_score(y_true, y_pred, normalize=False)
2Top-K ACC

>>> import numpy as np
>>> from sklearn.metrics import top_k_accuracy_score
>>> y_true = np.array([0, 1, 2, 2])
>>> y_score = np.array([[0.5, 0.2, 0.2],
... [0.3, 0.4, 0.2],
... [0.2, 0.4, 0.3],
... [0.7, 0.2, 0.1]])
>>> top_k_accuracy_score(y_true, y_score, k=2)
0.75
>>> # Not normalizing gives the number of "correctly" classified samples
>>> top_k_accuracy_score(y_true, y_score, k=2, normalize=False)
3F1

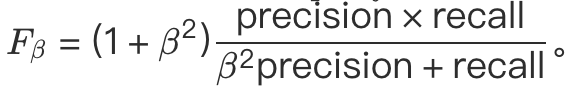
>>> from sklearn import metrics
>>> y_pred = [0, 1, 0, 0]
>>> y_true = [0, 1, 0, 1]
>>> metrics.precision_score(y_true, y_pred)
1.0
>>> metrics.recall_score(y_true, y_pred)
0.5
>>> metrics.f1_score(y_true, y_pred)
0.66...AUC
ROC曲线,是一个图解,它说明了二值分类器系统在其判别阈值变化时的性能。它是通过在不同的阈值设置下绘制阳性中的真阳性部分(TPR=真阳性率)与阴性中的假阳性部分(FPR=假阳性率)来创建的。TPR也称为敏感性,FPR是1减去特异性或真阴性率。
AUC是ROC曲线下的面积。
from sklearn.metrics import roc_auc_score技术交流群邀请函
已建立CV/NLP/推荐系统/多模态/内推求职等交流群!想要进交流群学习的同学,可以直接扫下方二维码进群。
加的时候备注一下:昵称+学校/公司。群里聚集了很多学术界和工业界大佬,欢迎一起交流算法心得,日常还可以唠嗑~

往期精彩回顾


你好,我是对白,清华计算机硕士毕业,现大厂算法工程师,拿过8家大厂算法岗SSP offer(含特殊计划),薪资40+W-80+W不等。
本科独立创业五年,两家公司创始人,拿过三百多万元融资(已到账),项目入选南京321高层次创业人才引进计划。创业做过无人机、机器人和互联网教育,保研清华后退居股东。
我每周至少更新三篇原创,分享人工智能前沿算法、创业心得和人生感悟。我正在努力实现人生中的第一个小目标,上方关注后可以加我微信交流。

您的“点赞/在看/分享”是我坚持的最大动力!
坚持不易,卖萌打滚求鼓励 (ฅ>ω<*ฅ)
分享
收藏
点赞
在看














 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









