






↑ 点击蓝字 关注极市平台

作者丨科技猛兽
来源丨极市平台
审核丨邓富城
极市导读
本文为详细解读Vision Transformer的第三篇,主要解读了两篇关于Transformer在识别任务上的演进的文章:DeiT与VT。它们的共同特点是避免使用巨大的非公开数据集,只使用ImageNet训练Transformer。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
考虑到每篇文章字数的限制,每一篇文章将按照目录的编排包含二至三个小节,而且这个系列会随着Vision Transformer的发展而长期更新。
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(一)
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二)
本文目录
7 Transformer+Distillation:DeiT:高效图像Transformer
(来自Facebook AI)
7.1 DeiT原理分析
7.2 DeiT代码解读8 Transformer Visual Recognition:Visual Transformers:基于Token的图像表示和处理
(来自UC Berkeley)
8.1 Visual Transformers原理分析
8.1 Visual Transformers代码解读
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
7 Transformer+Distillation:DeiT:高效图像Transformer
论文名称:Training data-efficient image transformers & distillation through attention
论文地址:
Training data-efficient image transformers & distillation through attention
https://arxiv.org/abs/2012.12877
7.1 DeiT原理分析:
CNN已经成为了image recognition任务的主要设计范式,CNN成功的主要因素之一是可以获得一个大型的训练集,即Imagenet。受NLP中基于self-attention模型的成功,人们对利用CNN内的注意力机制的架构越来越感兴趣。最近,一些研究人员提出了混合架构,即将Transformer结构和CNN结合完成视觉任务。
经典模型 ViT 的缺点和局限性
使用Transformer结构完成视觉任务的典型的例子比如说 ViT (相关的讲解可以参考[Vision Transformer 超详细解读 (二)])。Transformer的输入是一个序列 (Sequence),那么现在我们有的是一堆图片,如何转成序列呢?ViT所采用的思路是把图像分块 (patches),然后把每一块视为一个向量 (vector),所有的向量并在一起就成为了一个序列 (Sequence),ViT使用的数据集包括了一个巨大的包含了300 million images的JFT-300,这个数据集是私有的,即外部研究者无法复现实验。而且在ViT的实验中作者明确地提到:
" that transformers do not generalize well when trained on insufficient amounts of data. "
意思是当不使用JFT-300这样子的巨大的数据集时,效果是不如CNN模型的,也就反映出Transformer结构若想取得理想的性能和泛化能力就需要这样大的数据集。但是普通的研究者一没有如此extensive的计算资源,而没有如此巨大的数据集,所以无法复现对应的实验结果,这也是这篇文章 (DeiT) 的motivation。简而言之,作者通过所提出的训练方案。只在 Imagenet 上进行训练,就产生了一个有竞争力的无卷积 transformers,而且在单台计算机上训练它的时间不到 3 天。DeiT (86M参数)在 ImageNet 上实现了 83.1% 的 top-1 精度。
Data-efficient image Transformers (DeiT) 的优势
DeiT只需要8块GPUs训练2-3天 (53 hours train,20 hours finetune)。
数据集只使用 ImageNet。
不包含任何卷积 (Convolution)。
DeiT的性能可以用下图1表示:

为什么DeiT能在大幅减少 1. 训练所需的数据集 和 2. 训练时长 的情况下依旧能够取得很不错的性能呢?我们可以把这个原因归结为DeiT的训练策略。上图是用ImageNet训练并在ImageNet测试的性能结果。ViT在小数据集上的性能不如使用CNN网络EfficientNet,但是跟ViT结构相同,仅仅是使用更好的训练策略的DeiT比ViT的性能已经有了很大的提升,在此基础上,再加上蒸馏 (distillation) 操作,性能超过了EfficientNet。
Visual transformer
简单复习下 Multi-head Self Attention layers (MSA): 如下图2所示,首先我们有一个 Query 矩阵 和一个 Key 矩阵 ,把二者矩阵乘在一起并进行归一化以后得到 attention 矩阵,它再与Value矩阵 得到最终的输出。如果是多个头 (Multi-head)的attention的话 (假设有 个头),就把得到的这 个输出结果concat在一起得到一个 的序列 (Sequence),最后经过linear transformation得到 的输出结果。

Transformer block for images: Multi-head Self Attention layers 之后往往会跟上一个 Feed-Forward Network (FFN) ,它一般是由2个linear layer构成,第1个linear layer把维度从 维变换到 维,第2个linear layer把维度从 维再变换到 维。
此时的Transformer block是不考虑位置信息的,即一幅图片只要内容不变,patches的顺序发生变化,结果不受影响。基于此ViT加入了位置编码 (Positional Encoding),这些编码在第一个block之前被添加到input token中,代表位置信息。
The class token: 与 input token 并在一起输入 Transformer block 的一个向量,最后的输出结果用来预测类别。这样一来,Transformer相当于一共处理了 个维度为 的token,并且只有最后一个token的输出用来预测类别。这种体系结构迫使patch token和class token之间传播信息。
Fixing the positional encoding across resolutions: 之前已有相关研究表明,建议使用较低的训练分辨率,并以较高的分辨率微调网络。这加快了训练速度,并提高了现行数据增强方案的准确性。当增加输入图像的分辨率时,我们保持 patch size,因此 patch 的数量 发生了变化。由于Transformer结构的原因,当 发生变化时,模型的权重不需要做出任何变化也可以以同样的方式计算出Query,Key和Value的值,所以Visual transformer适用于任何长度的sequence。但是位置编码不行,位置编码的长度是 ,当 发生变化时,意味着位置编码也要做出相应的变化,ViT 在改变分辨率时对位置编码进行插值。
DeiT具体方法
假设我们有一个性能很好的分类器 (它可以是CNN,也可以是Transformer,后面会有实验验证哪个效果更好) 作为teacher model。我们可以通过图3和4对比下DeiT与原版ViT的结构差异:通过引入了一个distillation token,然后在self-attention layers中跟class token,patch token不断交互。它跟左下角的class token很像,唯一的区别在于,class token的目标是跟真实的label一致,而distillation token是要跟teacher model预测的label一致。


从头开始捋一遍DeiT的思路:如图5所示。 之前的ViT的输出是一个softmax,它代表着预测结果属于各个类别的概率的分布。ViT的做法是直接将这个softmax与GT label取 。
而在DeiT中,除了这个 以外,还要:
1. 先加上一个蒸馏损失:
蒸馏分两种,一种是软蒸馏(soft distillation),另一种是硬蒸馏(hard distillation)。先讲讲软蒸馏,如下式所示,右半部分, 和 分别是student model和teacher model的输出, 表示 散度, 表示softmax函数, 和 是超参数。
硬蒸馏如下式所示, 表示交叉熵。
简而言之,蒸馏的含义就是:学生网络的输出 与真实标签取 ,接着如果是硬蒸馏,就再与教师网络的标签取 。如果是软蒸馏,就再与教师网络的softmax输出结果取 。
值得注意的是,硬标签也可以通过标签平滑技术 (Label smoothing) 转换成软标签,其中真值对应的标签被认为具有 的概率,剩余的 由剩余的类别共享。 是一个超参数,这里取0.1。
2. 再加上一个distillation token: 它和ViT中的class token一起加入Transformer中,和class token一样通过self-attention与其它的embedding交互作用,并且在最后一层之后由网络输出。
问:distillation token对应的这个输出的目标函数是什么?
答:就是蒸馏损失 (下图hard distillation loss 或者 soft distillation loss)。
distillation token 允许我们的模型从教师网络的输出中学习,就像在常规的蒸馏中一样,同时也作为一种对class token的补充。

作者发现一个有趣的现象,class token和distillation token是朝着不同的方向收敛的,对各个layer的这两个token计算余弦相似度,平均值只有0.06,不过随着网络会越来越大,在最后一层是0.93,也就是相似但不相同。这是预料之中的,因为他们的目标是生产相似但不相同的目标。
作者做了个实验来验证这个确实distillation token有给模型add something。就是简单地增加一个class token来代替distillation token,然后发现,即使对这两个class token进行独立的随机初始化,它们最终会收敛到同一个向量 (余弦相似度为0.999),且性能没有明显提升。
在测试时,我们有class token的输出向量,有distillation token的输出向量,它们经过linear层都可以转化成预测结果,那么最终的预测结果怎么定呢?可以简单地把二者的softmax结果相加来得到预测结果。
Experiments:
实验参数的设置:
如下图6所示为不同大小的DeiT结构的超参数设置,最大的结构是DeiT-B,与ViT-B的结构是相同的,唯一不同的是embedding的hidden dimension和head数量。作者保持了每个head的隐变量维度为64,throughput是一个衡量DeiT模型处理图片速度的变量,代表每秒能够处理图片的数目。

实验1:哪种Teacher model更合适?
作者首先观察到使用CNN作为teacher比transformer作为teacher的性能更优。图7对比了teacher网络使用DeiT-B和几个CNN模型RegNetY时,得到的student网络的预训练性能以及finetune之后的性能。其中, 代表使用分辨率为 384×384 的图像finetune得到的模型,最后的那个小蒸馏符号 alembic sign代表蒸馏以后得到的模型。

实验2:哪种蒸馏策略更合适?
下图8是不同蒸馏策略的性能对比。图7的label代表有监督学习,前3行分别是不使用蒸馏,使用soft蒸馏和使用hard蒸馏的性能对比。

前3行就对应着图9,不使用distillation token进行训练, 只是相当于在原来ViT的基础上给损失函数加上了蒸馏部分,结果如图8所示。

对于Transformer来讲,硬蒸馏的性能明显优于软蒸馏,即使只使用前文讲到的class token,不使用distill token,硬蒸馏达到83.0%,而软蒸馏的精度为81.8%。
图10为使用图5所示的训练方式训练得到的DeiT模型,使用3种方法测试,结果如图8后3行所示。
第1:只使用class token;第2:只使用distillation token;第3:class token和distillation token都使用;
从结果中可以发现:
作者所提出的训练策略能够进一步提升性能 (第3到第4行),意味着这2个token 提供了对分类有用的补充信息。
拿着训练好的模型,只使用distillation token进行测试,性能是要强于只使用class token进行测试的。


作者观察到,以更高的分辨率进行微调有助于减少方法之间的差异。这可能是因为在微调时,作者不使用教师信息。随着微调,class token和distillation token之间的相关性略有增加。
除此之外,蒸馏模型在accuracy和throughput之间的trade-off甚至优于teacher模型,这也反映了蒸馏的有趣之处。
实验3:Transformer真的学到了CNN的归纳假设吗?
作者也很难说,但是作者分析了一下蒸馏前的DeiT,CNN teacher和蒸馏后的DeiT之间决策的不一致性。如图11所示,6行6列。行列交叉值为行列这2个设置之间决策的不一致性。用distillation token分类的DeiT与CNN的不一致性比用class token的更小,不出意外地,两个都用的DeiT居中。通过第2行可知,蒸馏后的DeiT与CNN的不一致性比蒸馏前的DeiT更小。

实验4:性能对比
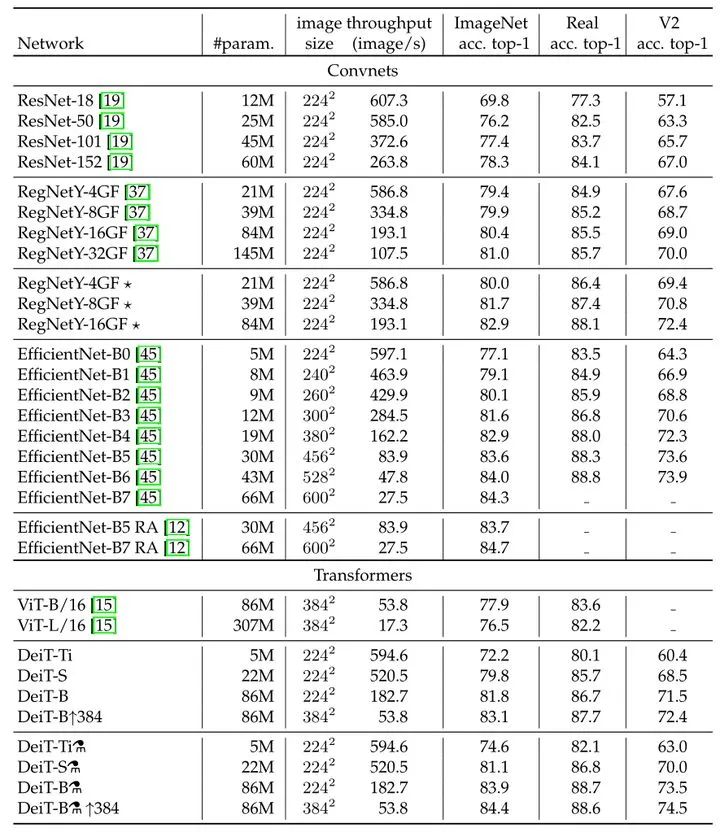
如上图12所示为不同模型性能的数值比较。可以发现在参数量相当的情况下,卷积网络的速度更慢,这是因为大的矩阵乘法比小卷积提供了更多的优化机会。
EffcientNet-B4和DeiT-B alembic sign的速度相似,在3个数据集的性能也比较接近。
实验5:迁移学习性能如何?
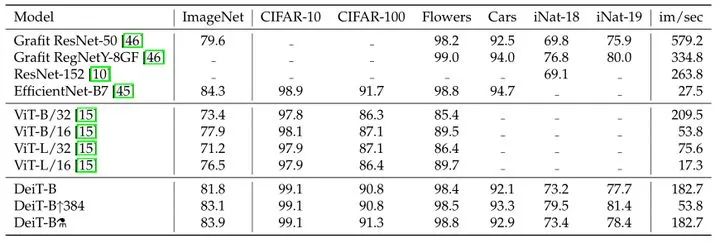
如图13所示为不同任务的数据集,图14为DeiT迁移到不同任务的性能,即不同模型迁移学习的能力对比,对比的所有模型均使用ImageNet作为预训练,包括一些CNN模型。

实验6:一些对比实验
最后作者做了一些关于数据增强方法和优化器的对比实验,如图15所示。Transformer的训练需要大量的数据,想要在不太大的数据集上取得好性能,就需要大量的数据增强,以实现data-efficient training。几乎所有评测过的数据增强的方法都能提升性能。对于优化器来说,AdamW比SGD性能更好。此外,作者发现Transformer对优化器的超参数很敏感,试了多组 和 。stochastic depth有利于收敛。 和 都能提高性能。 表示参数平滑后的模型,对性能提升只是略有帮助。

7.2 DeiT代码解读:
DeiT代码使用方法 :
作者提供了关于DeiT的所有的预训练模型,以DeiT-base distilled 384 (1000 epochs, acc1 = 85.2%, acc5 = 97.2%, #params = 88M)为例,可以通过下面这个链接下载:
https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_384-d0272ac0.pthdl.fbaipublicfiles.com
所有的预训练模型也可以通过torch hub直接进行加载。
DeiT代码大量借助了Ross Wightman大佬(https://github.com/rwightman)写的timm库的实现。
首先要安装timm库:
# DeiT is built on top of timm version 0.3.2, so need to install it first!pip install timm==0.3.2
# Download ImageNet category names for nicer display!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
2. 导入必要的库:
from PIL import Imageimport requestsimport matplotlib.pyplot as plt%config InlineBackend.figure_format = 'retina'
import torchimport timmimport torchvisionimport torchvision.transforms as T
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
torch.set_grad_enabled(False);
# Read the ImageNet categorieswith open("imagenet_classes.txt", "r") as f: imagenet_categories = [s.strip() for s in f.readlines()]
3. 图像预处理:
# create the data transform that DeiT expectstransform = T.Compose([ T.Resize(256, interpolation=3), T.CenterCrop(224), T.ToTensor(), T.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),])
4. 下面将展示如何从torchhub加载预训练的模型并对其进行前向推理过程。 在这里将使用DeiT-base,但是你也可以使用作者提供的任何其他模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)model.eval()
一共可以选择的模型,即deit_base_patch16_224可以替换为:
deit_base_distilled_patch16_224
deit_base_distilled_patch16_384
deit_base_patch16_224
deit_base_patch16_384
deit_small_distilled_patch16_224
deit_small_patch16_224
deit_tiny_distilled_patch16_224
deit_tiny_patch16_224
5. 从URL中检索图像并将其作为PIL图像返回:
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
im = Image.open(requests.get(url, stream=True).raw)
im
6. 应用DeiT模型进行前向推理过程,得到具有最高的置信度的5个类。
# transform the original image and add a batch dimension
img = transform(im).unsqueeze(0)
# compute the predictions
out = model(img)
# and convert them into probabilities
scores = torch.nn.functional.softmax(out, dim=-1)[0]
# finally get the index of the prediction with highest score
topk_scores, topk_label = torch.topk(scores, k=5, dim=-1)
for i in range(5):
pred_name = imagenet_categories[topk_label[i]]
print(f"Prediction index {i}: {pred_name:<25}, score: {topk_scores[i].item():.3f}")
结果:
Prediction index 0: tabby , score: 0.567Prediction index 1: tiger cat , score: 0.134Prediction index 2: remote control , score: 0.085Prediction index 3: Egyptian cat , score: 0.030Prediction index 4: cellular telephone , score: 0.006
以上就是使用DeiT预训练模型进行小测试的过程,下面是完整的模型训练和评估方法。
7. 数据准备:
到官网下载ImageNet数据集,解压后得到下面这样的格式:
可参考下面的链接:博皓:ImageNet数据集下载与处理(https://zhuanlan.zhihu.com/p/42696535)
/path/to/imagenet/ train/ class1/ img1.jpeg class2/ img2.jpeg val/ class1/ img3.jpeg class/2 img4.jpeg
就是train一个文件夹,val一个文件夹,里面按照类别存。
8. Evaluation:
这里使用单张GPU验证一个预训练模型 (以deit_base_patch16_224为例):
python main.py --eval --resume https://dl.fbaipublicfiles.com/deit/deit_base_patch16_224-b5f2ef4d.pth --data-path /path/to/imagenet
结果:
* Acc@1 81.846 Acc@5 95.594 loss 0.820
再以Deit-small为例:
python main.py --eval --resume https://dl.fbaipublicfiles.com/deit/deit_small_patch16_224-cd65a155.pth --model deit_small_patch16_224 --data-path /path/to/imagenet
结果:
* Acc@1 79.854 Acc@5 94.968 loss 0.881
再以Deit-tiny为例:
python main.py --eval --resume https://dl.fbaipublicfiles.com/deit/deit_tiny_patch16_224-a1311bcf.pth --model deit_tiny_patch16_224 --data-path /path/to/imagenet
结果:
* Acc@1 72.202 Acc@5 91.124 loss 1.219
再以deit_base_distilled_patch16_384为例:
python main.py --eval --model deit_base_distilled_patch16_384 --input-size 384 --resume https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_384-d0272ac0.pth
结果:
* Acc@1 85.224 Acc@5 97.186 loss 0.636
9. Training:
在4 gpus的单个节点上在ImageNet上对DeiT-small和Diet-tiny训练300 epoches:
DeiT-small:
python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py --model deit_small_patch16_224 --batch-size 256 --data-path /path/to/imagenet --output_dir /path/to/save
DeiT-tiny:
python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py --model deit_tiny_patch16_224 --batch-size 256 --data-path /path/to/imagenet --output_dir /path/to/save
10. Multinode training:
通过Slurm and [submitit](https://github.com/facebookincubator/submitit)进行多节点训练:
pip install submitit
在ImageNet上训练DeiT-base model,2个节点,8个gpus,300个epoches:
python run_with_submitit.py --model deit_base_patch16_224 --data-path /path/to/imagenet
训练模型:DeiT-base
教师模型:RegNetY-160
2个节点,8个gpus (32GB),300个epoches
蒸馏类型:hard distillation
python run_with_submitit.py --model deit_base_distilled_patch16_224 --distillation-type hard --teacher-model regnety_160 --teacher-path https://dl.fbaipublicfiles.com/deit/regnety_160-a5fe301d.pth --use_volta32
训练模型:DeiT-base
预训练模型分辨率:224 resolution images
finetune分辨率:384 resolution images
教师模型:RegNetY-160
2个节点,8个gpus (32GB),30个epoches
蒸馏类型:hard distillation
python run_with_submitit.py --model deit_base_patch16_384 --batch-size 32 --finetune https://dl.fbaipublicfiles.com/deit/deit_base_patch16_224-b5f2ef4d.pth --input-size 384 --use_volta32 --nodes 2 --lr 5e-6 --weight-decay 1e-8 --epochs 30 --min-lr 5e-6
DeiT代码解读:
导入包以及全部模型列表:
import torchimport torch.nn as nnfrom functools import partial
from timm.models.vision_transformer import VisionTransformer, _cfgfrom timm.models.registry import register_modelfrom timm.models.layers import trunc_normal_
__all__ = [ 'deit_tiny_patch16_224', 'deit_small_patch16_224', 'deit_base_patch16_224', 'deit_tiny_distilled_patch16_224', 'deit_small_distilled_patch16_224', 'deit_base_distilled_patch16_224', 'deit_base_patch16_384', 'deit_base_distilled_patch16_384',]
这里面引入了一个很有用的类VisionTransformer。
from timm.models.vision_transformer import VisionTransformer, _cfg
那么这个VisionTransformer类的源代码是什么?
可以从下面这个链接中找到:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
forward_features函数返回2个token对应的输出:
def forward_features(self, x):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add the dist_token
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
dist_token = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, dist_token, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0], x[:, 1]
前向传播函数:
Training状态时,流程如上图5所示,要返回2个输出 x 和 x_dist。
Inference状态时,流程如上图10所示,要返回2个输出 x 和 x_dist的均值。
def forward(self, x): x, x_dist = self.forward_features(x) x = self.head(x) x_dist = self.head_dist(x_dist) if self.training: return x, x_dist else: # during inference, return the average of both classifier predictions return (x + x_dist) / 2
模型定义的形式是:
@register_modeldef deit_tiny_patch16_224(pretrained=False, **kwargs): model = VisionTransformer( patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_tiny_patch16_224-a1311bcf.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model
如果想再定义一个模型,比如说:deit_small_patch16_224,就可以直接:
@register_modeldef deit_small_patch16_224(pretrained=False, **kwargs): model = VisionTransformer( patch_size=16, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs) model.default_cfg = _cfg() if pretrained: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_small_patch16_224-cd65a155.pth", map_location="cpu", check_hash=True ) model.load_state_dict(checkpoint["model"]) return model
注册器的代码部分如下:
_module_to_models = defaultdict(set) # dict of sets to check membership of model in module_model_to_module = {} # mapping of model names to module names_model_entrypoints = {} # mapping of model names to entrypoint fns_model_has_pretrained = set() # set of model names that have pretrained weight url present
def register_model(fn): # lookup containing module mod = sys.modules[fn.__module__] module_name_split = fn.__module__.split('.') module_name = module_name_split[-1] if len(module_name_split) else ''
# add model to __all__ in module model_name = fn.__name__ if hasattr(mod, '__all__'): mod.__all__.append(model_name) else: mod.__all__ = [model_name]
# add entries to registry dict/sets _model_entrypoints[model_name] = fn _model_to_module[model_name] = module_name _module_to_models[module_name].add(model_name) has_pretrained = False # check if model has a pretrained url to allow filtering on this if hasattr(mod, 'default_cfgs') and model_name in mod.default_cfgs: # this will catch all models that have entrypoint matching cfg key, but miss any aliasing # entrypoints or non-matching combos has_pretrained = 'url' in mod.default_cfgs[model_name] and 'http' in mod.default_cfgs[model_name]['url'] if has_pretrained: _model_has_pretrained.add(model_name) return fn
可以发现,通过register_model的注册器机制,给_module_to_models,_model_to_module,_model_entrypoints,_model_has_pretrained这几个字典自动存入新的模型,这一过程无需手动进行。
这里借助了内置函数__module__、__name__。
损失函数定义:
class DistillationLoss(torch.nn.Module):
"""
This module wraps a standard criterion and adds an extra knowledge distillation loss by
taking a teacher model prediction and using it as additional supervision.
"""
def __init__(self, base_criterion: torch.nn.Module, teacher_model: torch.nn.Module,
distillation_type: str, alpha: float, tau: float):
super().__init__()
self.base_criterion = base_criterion
self.teacher_model = teacher_model
assert distillation_type in ['none', 'soft', 'hard']
self.distillation_type = distillation_type
self.alpha = alpha
self.tau = tau
def forward(self, inputs, outputs, labels):
"""
Args:
inputs: The original inputs that are feed to the teacher model
outputs: the outputs of the model to be trained. It is expected to be
either a Tensor, or a Tuple[Tensor, Tensor], with the original output
in the first position and the distillation predictions as the second output
labels: the labels for the base criterion
"""
outputs_kd = None
if not isinstance(outputs, torch.Tensor):
# assume that the model outputs a tuple of [outputs, outputs_kd]
# outputs: original output
# outputs_kd: distillation predictions
outputs, outputs_kd = outputs
base_loss = self.base_criterion(outputs, labels)
if self.distillation_type == 'none':
return base_loss
if outputs_kd is None:
raise ValueError("When knowledge distillation is enabled, the model is "
"expected to return a Tuple[Tensor, Tensor] with the output of the "
"class_token and the dist_token")
# don't backprop throught the teacher
with torch.no_grad():
teacher_outputs = self.teacher_model(inputs)
if self.distillation_type == 'soft':
T = self.tau
# taken from https://github.com/peterliht/knowledge-distillation-pytorch/blob/master/model/net.py#L100
# with slight modifications
distillation_loss = F.kl_div(
F.log_softmax(outputs_kd / T, dim=1),
F.log_softmax(teacher_outputs / T, dim=1),
reduction='sum',
log_target=True
) * (T * T) / outputs_kd.numel()
elif self.distillation_type == 'hard':
distillation_loss = F.cross_entropy(outputs_kd, teacher_outputs.argmax(dim=1))
loss = base_loss * (1 - self.alpha) + distillation_loss * self.alpha
return loss
在hard distillation模式下:使用F.cross_entropy计算cross entropy loss。
在soft distillation模式下:使用F.kl_div计算KL散度。
记录训练日志:
作者使用的是自定义的MetricLogger类,里面的变量meters是一个字典,记录各种数据对应的值。
class MetricLogger(object): def __init__(self, delimiter="\t"): self.meters = defaultdict(SmoothedValue) self.delimiter = delimiter
通过add_meter函数添加记录新的变量:
def add_meter(self, name, meter): self.meters[name] = meter
通过update函数更新meters: def update(self, **kwargs): for k, v in kwargs.items(): if isinstance(v, torch.Tensor): v = v.item() assert isinstance(v, (float, int)) self.meters[k].update(v)
训练一个epoch以及evaluate代码:
def train_one_epoch(model: torch.nn.Module, criterion: DistillationLoss, data_loader: Iterable, optimizer: torch.optim.Optimizer, device: torch.device, epoch: int, loss_scaler, max_norm: float = 0, model_ema: Optional[ModelEma] = None, mixup_fn: Optional[Mixup] = None, set_training_mode=True): model.train(set_training_mode) metric_logger = utils.MetricLogger(delimiter=" ") metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}')) header = 'Epoch: [{}]'.format(epoch) print_freq = 10
for samples, targets in metric_logger.log_every(data_loader, print_freq, header): samples = samples.to(device, non_blocking=True) targets = targets.to(device, non_blocking=True)
if mixup_fn is not None: samples, targets = mixup_fn(samples, targets)
with torch.cuda.amp.autocast(): outputs = model(samples) loss = criterion(samples, outputs, targets)
loss_value = loss.item()
if not math.isfinite(loss_value): print("Loss is {}, stopping training".format(loss_value)) sys.exit(1)
optimizer.zero_grad()
# this attribute is added by timm on one optimizer (adahessian) is_second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order loss_scaler(loss, optimizer, clip_grad=max_norm, parameters=model.parameters(), create_graph=is_second_order)
torch.cuda.synchronize() if model_ema is not None: model_ema.update(model)
metric_logger.update(loss=loss_value) metric_logger.update(lr=optimizer.param_groups[0]["lr"]) # gather the stats from all processes metric_logger.synchronize_between_processes() print("Averaged stats:", metric_logger) return {k: meter.global_avg for k, meter in metric_logger.meters.items()}
@torch.no_grad()def evaluate(data_loader, model, device): criterion = torch.nn.CrossEntropyLoss()
metric_logger = utils.MetricLogger(delimiter=" ") header = 'Test:'
# switch to evaluation mode model.eval()
for images, target in metric_logger.log_every(data_loader, 10, header): images = images.to(device, non_blocking=True) target = target.to(device, non_blocking=True)
# compute output with torch.cuda.amp.autocast(): output = model(images) loss = criterion(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
batch_size = images.shape[0] metric_logger.update(loss=loss.item()) metric_logger.meters['acc1'].update(acc1.item(), n=batch_size) metric_logger.meters['acc5'].update(acc5.item(), n=batch_size) # gather the stats from all processes metric_logger.synchronize_between_processes() print('* Acc@1 {top1.global_avg:.3f} Acc@5 {top5.global_avg:.3f} loss {losses.global_avg:.3f}' .format(top1=metric_logger.acc1, top5=metric_logger.acc5, losses=metric_logger.loss))
return {k: meter.global_avg for k, meter in metric_logger.meters.items()}
损失函数:传入的就是DistillationLoss类。
模型:model传入对应的DeiT模型。
把预训练模型的位置编码插值,只对position tokens部分进行插值,extra tokens不变。
# interpolate position embedding
pos_embed_checkpoint = checkpoint_model['pos_embed']
embedding_size = pos_embed_checkpoint.shape[-1]
num_patches = model.patch_embed.num_patches
num_extra_tokens = model.pos_embed.shape[-2] - num_patches
# height (== width) for the checkpoint position embedding
orig_size = int((pos_embed_checkpoint.shape[-2] - num_extra_tokens) ** 0.5)
# height (== width) for the new position embedding
new_size = int(num_patches ** 0.5)
# class_token and dist_token are kept unchanged
extra_tokens = pos_embed_checkpoint[:, :num_extra_tokens]
# only the position tokens are interpolated
pos_tokens = pos_embed_checkpoint[:, num_extra_tokens:]
pos_tokens = pos_tokens.reshape(-1, orig_size, orig_size, embedding_size).permute(0, 3, 1, 2)
pos_tokens = torch.nn.functional.interpolate(
pos_tokens, size=(new_size, new_size), mode='bicubic', align_corners=False)
pos_tokens = pos_tokens.permute(0, 2, 3, 1).flatten(1, 2)
new_pos_embed = torch.cat((extra_tokens, pos_tokens), dim=1)
checkpoint_model['pos_embed'] = new_pos_embed
创建并加载teacher model:
teacher_model = create_model()函数来自timm库的实现。
torch.hub.load_state_dict_from_url得到teacher model权重。
teacher_model.load_state_dict(checkpoint['model'])加载teacher model权重。
teacher_model = None if args.distillation_type != 'none': assert args.teacher_path, 'need to specify teacher-path when using distillation' print(f"Creating teacher model: {args.teacher_model}") teacher_model = create_model( args.teacher_model, pretrained=False, num_classes=args.nb_classes, global_pool='avg', ) if args.teacher_path.startswith('https'): checkpoint = torch.hub.load_state_dict_from_url( args.teacher_path, map_location='cpu', check_hash=True) else: checkpoint = torch.load(args.teacher_path, map_location='cpu') teacher_model.load_state_dict(checkpoint['model']) teacher_model.to(device) teacher_model.eval()
参数的更新:
loss_scaler(loss, optimizer, clip_grad=max_norm,
parameters=model.parameters(), create_graph=is_second_order)
loss_scaler的定义是:
loss_scaler = NativeScaler()
这里的NativeScaler类也是在timm库中定义的,如下面代码所示:
这个类在使用时需要传入loss, optimizer, clip_grad, parameters, create_graph这5个参数。
class NativeScaler: state_dict_key = "amp_scaler"
def __init__(self): self._scaler = torch.cuda.amp.GradScaler()
def __call__(self, loss, optimizer, clip_grad=None, parameters=None, create_graph=False): self._scaler.scale(loss).backward(create_graph=create_graph) if clip_grad is not None: assert parameters is not None self._scaler.unscale_(optimizer) # unscale the gradients of optimizer's assigned params in-place torch.nn.utils.clip_grad_norm_(parameters, clip_grad) self._scaler.step(optimizer) self._scaler.update()
def state_dict(self): return self._scaler.state_dict()
def load_state_dict(self, state_dict): self._scaler.load_state_dict(state_dict)
8 Transformer Visual Recognition:Visual Transformers:基于Token的图像表示和处理
论文名称:Visual Transformers: Token-based Image Representation and Processing for Computer Vision
论文地址:
https://arxiv.org/abs/2006.03677arxiv.org
8.1 Visual Transformers原理分析:
本文的动机是什么?
问:CNN和Vision Transformer的不同点在哪里?
答:
1) 传统CNN公平地对待图片的每个像素。
传统CNN在进行计算机视觉任务时,会把图片视为均匀排列的像素阵列 (uniformly- arranged pixel arrays),使用卷积操作来处理一些高度局部化的特征 (highly-localized features)。但是,传统卷积操作对于一张图片的不同pixel,是以相同的重要性对待的 (treat all image pixels equally),不论这个像素的内容是什么,也不论它是否重要。但是,这样做的确存在问题:图像分类模型应该优先考虑前景对象而不是背景。分割模型应该优先考虑行人,而不是不成比例的大片天空、道路、植被等。所以作者认为,传统CNN把图片建模为像素阵列,处理时不考虑像素的内容,也不考虑不同像素之间重要性的差异。
2) 并非所有图片都拥有全部概念。
所有自然图像中都存在角点 (corner) 和边缘 (edge) 等低级特征,因此对所有图像应用低级卷积滤波器是合适的。但是,特定图像中存在耳朵形状等高级特征,因此对所有图像应用高级过滤器在计算上效率低下。
3) 卷积很难将空间上遥远的概念联系起来。
每个卷积滤波器都被限制在一个小的区域内工作,但是语义概念之间的长期交互是至关重要的。为了联系空间距离概念 ( spatially-distant concepts),以前的方法增加了卷积核大小 (kernel size),增加了模型深度 (depth),或者采用了新的操作,如dilated convolutions, global pooling, and non-local attention layers。然而,通过在像素卷积范式中工作,这些方法充其量缓解了问题,通过增加模型和计算复杂性来补偿卷积的弱点。
在本文中作者提出了另一种处理图片的方法Visual Transformers,即:
1) 把图片建模为语义视觉符号 (semantic visual tokens)。
2) 使用Transformer来建模tokens之间的关系。
这样一来,Visual Transformers (VT)把问题定义在了语义符号空间 (semantic token space)中,目的是在图像中表示和处理高级概念 (high-level concepts)。在token空间中建模高级概念之间的联系 (models concept interactions in the token-space)。而且,图片的不同部分,因其内容不同重要性也不同。注意,这与我们之前一直提的在像素空间 (pixel-space)中处理信息的Transformer (如ViT,DeiT,IPT等等)完全不同,因为计算量的相差了多个数量级。
作者使用空间注意力机制将特征图转换成一组紧凑的语义符号 (semantic tokens)。再把这些tokens输入一个Transformer,利用Transformer特殊的功能来捕捉tokens之间的联系。
这样一来,VT可以:
1) 关注那些相对重要区域,而不是像CNN那样平等地对待所有的像素。
2) 将语义概念编码在视觉符号 (visual tokens)中,而不是对所有图像中的所有概念进行建模。
3) 使用Transformer来建模tokens之间的关系。
VT模型在分类任务 (Model Base: ResNet, Dataset: ImageNet,减少了6.9倍计算量,涨点4.6-7 Accuracy) 以及语义分割任务 (Model Base: FPN,Dataset: LIP and COCO-stuff,减少了6.4倍计算量,涨点0.35 mIoU) 上都取得了很好的性能。

对于一张给定图片,首先通过卷积操作得到其low-level的特征,把这些得到的feature map输入给VT。首先通过一个tokenizer,把这些特征图的pixels转化为 visual tokens。每个 token 代表图片中的一个语义概念 (semantic concept)。得到这些 token 以后,再将它们通过Transformer,那么Transformer输出的也应当是一堆 visual tokens。那么最后,这些 visual tokens要么直接应用于图像分类任务,要么通过 Projector 投影回特征图进行语义分割任务。
所以接下来将依次介绍:
Tokenizer
Transformer
Projector
在此之前,需要先搞清楚以下 2 个问题:
问:这篇工作的特殊之处在哪里?
答: 之前的工作都是对图片 (或特征图)直接使用Transformer:先把图片分块,做序列化,再把这些序列拼成一个张量,对张量做Transformer。而这个工作是先把图片 (或特征图)通过一个叫做tokenizer的东西转化为 visual tokens,再对这些 visual tokens做Transformer。那么理所应当得到的也是一些 visual tokens,这个时候只需要视情况选择是否将它重新映射回图片 (或特征图)即可。
问:为什么要先使用卷积,再变成 visual tokens,再使用Transformer处理这些 visual tokens呢?
答: 这样做的目的是为了结合卷积和Transformer的优点。我们知道在网络的浅层,我们需要的特征一般都是一些低级的特征(比如说一些边,角等等),这些特征应该使用卷积操作得到。
在网络的深层,我们需要处理的特征一般是高级的语义特征,这时作者使用VT (Visual Transformer 处理 visual tokens 的 Transformer 模型)来建模这些高级的语义特征。
在网络末端,作者直接使用visual tokens来进行图像识别的任务,并使用投影后的特征图来进行像素级的预测任务 (分割)。
Tokenizer:
Filter-based Tokenizer
我们假设 ,最终要得到的visual token 。Filter-based Tokenizer的第1步是对 进行1 × 1卷积 ,再对这 组向量 (每组 个) 都进行 操作 (注意这里 的分母应该是 个)。这么做的目的是把每个像素 都映射到 个semantic group中的一个。这步操作结束以后得到的张量是 。再把它转置以后与 进行矩阵乘法最终得到 。Filter-based Tokenizer的表达式和示意图如下:

经过这样的一次变换, 变成了 , 许多高级的语义概念是稀疏的,每个概念可能只出现在图像的一小部分里面。因此,固定的学习权重集可能会浪费计算时间,因为它会同时对所有高级概念进行建模。所以Tokenizer把学习的内容从整张图片的 的像素变成了 个语义token,节约了参数量。
因为这种Tokenizer是使用了1 × 1卷积 来进行抽取visual tokens的,所以也被称为Filter-based Tokenizer。
Recurrent Tokenizer
为了弥补Filter-based Tokenizer的局限性,作者又设计了Recurrent Tokenizer,就是使用上一层的token 来指导这一层的token 的生成。首先我们使用 与矩阵 相乘得到矩阵 ,再把它当做上面的 1 × 1卷积与 作用得到这一层的token 。Recurrent Tokenizer的表达式和示意图如下:

Transformer:
得到了 visual tokens 之后,接下来使用Transformer对它进行建模。
:计算
:计算
$\text{softmax}{L} \left((\mathbf{T}{in}\mathbf{K}) (\mathbf{T}{in}\mathbf{Q})^T\right) \text{Attention}$
表达式是:
注意式 (8.3)与标准Transformer的attention式子不同,式 (8.3)直接把 当做了 ,而且 与 相乘的结果只是作为残差。式 (8.4)是标准Transformer的Add & Norm过程,区别只是这里的 操作都是Pointwise Convolution (1 × 1卷积)。
Projector:
对于一些需要像素级别预测的视觉任务,比如分割等,需要得到pixel-level details。显然,只有 visual tokens 提供的信息是不够的。所以作者再通过Projector把Transformer输出的 visual tokens 反变换称为Feature map。
式中, 分别是输入和输出特征图。这种key-query product 的方式决定了如何将编码在visual tokens 中的有用的信息投影到特征图中。Projector对张量的操作如下图19所示。在得到 $\mathbf{X}{out} \mathbf{X}{in} \mathbf{T}$ 只是为了得到残差。


如何在自己的视觉模型中使用VT?
分类模型:
我们可以把VT看作是一种插件,可以添加在我们自己的模型里面,比如ResNet-{18, 34, 50, 101},我们可以把它们变成visual-transformer-ResNets (VT-ResNets)-{18, 34, 50, 101}。
具体怎么变呢?把ResNet网络的最后一个stage的所有的卷积层变成VT module。ResNet网络的结构如下图20所示。比如ResNet-18最后一个stage有2个basic block,ResNet-101最后一个stage有3个bottleneck block,等等。我们要把它们变成VT module。在这个过程中,有3个超参数需要设置:
channel size of the output feature map
channel size of visual token
number of visual tokens
ResNet-{18, 34} 的stage 4结束后得到的feature map是14×14×256,ResNet-{50,101} 的stage 4结束后得到的feature map是14×14×1024,在实验中作者使用了16个visual token,且其channel数都设为1024。所以最后Transformer也会输出得到16个visual tokens,即 。注意这里 的是图17,18中的黑体字母C,代表visual token的channel size。
分割模型:
将panoptic feature pyramid networks (FPN)视为baseline,如下图21左图所示。

只需要把FPN中的卷积 (图21左图中间的黑色箭头)替换成VT module即可。在实做中作者使用了8个visual tokens,且其channel数都设为1024。然后,输出的visual tokens被投影回原始特征图,用于执行分割任务。与最初的FPN相比,VT-FPN的计算成本要小得多,因为作者只对极少数量的visual tokens而不是所有像素进行操作。
Experiments:
实验1:将ResNet改造为VT-ResNet,性能有什么变化?
下图22为ImageNet (1.3 million training set, 50 thousand validation set) 的实验结果。模型对比了ResNet-{18, 34}。第1个VT module使用Filter-based Tokenizer,后面的所有VT module都使用Recurrent Tokenizer。可以发现:当我们把最后一个stage的卷积操作给替换成VT之后,计算量都有所下降,而且准确度都有所提升。

实验2:探索不同类型的Tokenizer对性能的影响。
在上文我们提到Tokenizer的作用就是把一个 的特征图给变成一个 的token。那么这个Tokenizer的种类可以有多个,作者尝试了3种,分别是:
Pooling-based tokenizer
Clustering-based tokenizer
Filter-based tokenizer
第3种Filter-based tokenizer如上文介绍。
第1种Pooling-based tokenizer就是直接下采样,把 spatial dimensions从 降低到 。
第2种Clustering-based tokenizer就是先把 通过K-Means 聚类,得到一个 ,相当于Filter-based tokenizer里的 。再通过它得到visual tokens,写成公式就是:
结果如图23所示,后两种Tokenizer的性能比第1种强一些。

下图24为探索Recurrent tokenizer的性能, 实验表明,使用Recurrent tokenizer可以获得更高的准确率。

下图25为探索visual tokens数量对精确度的影响。

作者测试了不同数量的visual tokens,结果发现准确性几乎没有提高。这与作者的假设相一致,即16个visual tokens已经可以捕获各种各样的概念,即不再需要额外的visual tokens。
下图26为探索Projector对最终结果的影响,结果发现:即使是对于分类任务,将visual tokens通过Projector映射回特征图的性能会更好。这可能是因为feature maps仍然编码重要的空间信息。

实验3:Visual Transformer for Semantic Segmentation
数据集: COCO-stuff dataset (118K training images, 5K validation images) 和LIP dataset。
模型: VT-FPN,backbone:ResNet-{50, 101}。
2个数据集的结果如下图27所示,我们发现,当把FPN替换成VT-FPN之后,mIoU获得了轻度的提升,而且所需的计算量有所下降。


实验4:可视化Visual Tokens
根据本文的假设,从图片中抽取的 visual token 对应于图像中不同的高级语义,为此,作者可视化了式 (8.1)中的 ,它相当于attention,由filter-based tokenizers输出。从图28中我们发现,红色表示较高的attention值,蓝色表示较低的attention值。在没有任何监督的情况下, visual token 自动聚焦在图像中与不同语义概念相对应的不同区域,如羊、地、衣服、木头。

8.2 Visual Transformers代码解读:
代码来自非官方版本:
https://github.com/arthasmil/visualtransformers
初始化权值:
def _weights_init(m):
classname = m.__class__.__name__
#print(classname)
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight)
定义一个任意功能的神经网络层,它在实例化时需要传入一个function F,使得这个神经网络层的功能就是F。
class LambdaLayer(nn.Module):
def __init__(self, lambd):
super(LambdaLayer, self).__init__()
self.lambd = lambd
def forward(self, x):
return self.lambd(x)
定义一个任意功能的残差神经网络层,它在实例化时需要传入一个function fn,使得这个神经网络层的功能就是fn。
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
定义LayerNormalize层:
class LayerNormalize(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
定义 ResNet 的 Basic block:
class BasicBlock(nn.Module): expansion = 1
def __init__(self, in_planes, planes, stride=1, option='A'): super(BasicBlock, self).__init__() self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential() if stride != 1 or in_planes != planes: if option == 'A': """ For CIFAR10 ResNet paper uses option A. """ self.shortcut = LambdaLayer(lambda x: F.pad(x[:, :, ::2, ::2], (0, 0, 0, 0, planes//4, planes//4), "constant", 0)) elif option == 'B': self.shortcut = nn.Sequential( nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.expansion * planes) )
def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.bn2(self.conv2(out)) out += self.shortcut(x) out = F.relu(out) #print(out.size()) return out
这里的F.pad是pytorch内置的tensor扩充函数,便于对数据集图像或中间层特征进行维度扩充,下面是pytorch官方给出的函数定义。
torch.nn.functional.pad(input, pad, mode='constant', value=0)
函数变量说明:
input
需要扩充的tensor,可以是图像数据,抑或是特征矩阵数据。pad
扩充维度,用于预先定义出某维度上的扩充参数。mode
扩充方法,'constant', 'reflect' or 'replicate'三种模式,分别表示常量,反射,复制。value
扩充时指定补充值,但是value只在mode='constant’有效,即使用value填充在扩充出的新维度位置,而在’reflect’和’replicate’模式下,value不可赋值。
所以lambda x: F.pad(x[:, :, ::2, ::2], (0, 0, 0, 0, planes//4, planes//4), "constant", 0)就是在channel维度上填充planes//2,HW维度上减半。
MLP Layer:
class MLP_Block(nn.Module): def __init__(self, dim, hidden_dim, dropout = 0.1): super().__init__() self.nn1 = nn.Linear(dim, hidden_dim) torch.nn.init.xavier_uniform_(self.nn1.weight) torch.nn.init.normal_(self.nn1.bias, std = 1e-6) self.af1 = nn.GELU() self.do1 = nn.Dropout(dropout) self.nn2 = nn.Linear(hidden_dim, dim) torch.nn.init.xavier_uniform_(self.nn2.weight) torch.nn.init.normal_(self.nn2.bias, std = 1e-6) self.do2 = nn.Dropout(dropout) def forward(self, x): x = self.nn1(x) x = self.af1(x) x = self.do1(x) x = self.nn2(x) x = self.do2(x) return x
Attention Layer:
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dropout = 0.1):
super().__init__()
self.heads = heads
self.scale = dim ** -0.5 # 1/sqrt(dim)
self.to_qkv = nn.Linear(dim, dim * 3, bias = True) # Wq,Wk,Wv for each vector, thats why *3
torch.nn.init.xavier_uniform_(self.to_qkv.weight)
torch.nn.init.zeros_(self.to_qkv.bias)
self.nn1 = nn.Linear(dim, dim)
torch.nn.init.xavier_uniform_(self.nn1.weight)
torch.nn.init.zeros_(self.nn1.bias)
self.do1 = nn.Dropout(dropout)
def forward(self, x, mask = None):
b, n, _, h = *x.shape, self.heads # *(1,2,3) → 1,2,3: 解释器将自动进行解包然后传递给多个单变量参数(参数个数要对应相等).
qkv = self.to_qkv(x) #gets q = Q = Wq matmul x1, k = Wk mm x2, v = Wv mm x3
q, k, v = rearrange(qkv, 'b n (qkv h d) -> qkv b h n d', qkv = 3, h = h) # split into multi head attentions, 在最后1维提个3, 提个heads出来.
dots = torch.einsum('bhid, bhjd->bhij', q, k) * self.scale
if mask is not None:
mask = F.pad(mask.flatten(1), (1, 0), value = True)
assert mask.shape[-1] == dots.shape[-1], 'mask has incorrect dimensions'
mask = mask[:, None, :] * mask[:, :, None]
dots.masked_fill_(~mask, float('-inf'))
del mask
attn = dots.softmax(dim=-1) #follow the softmax,q,d,v equation in the paper
out = torch.einsum('bhij,bhjd->bhid', attn, v) #product of v times whatever inside softmax
out = rearrange(out, 'b h n d -> b n (h d)') #concat heads into one matrix, ready for next encoder block
out = self.nn1(out)
out = self.do1(out)
return out
定义Transformer (标准的结构,每个Block先Attention Layer+ Add&Norm,再FFN(MLP Layer) + Add&Norm):
class Transformer(nn.Module): def __init__(self, dim, depth, heads, mlp_dim, dropout): super().__init__() self.layers = nn.ModuleList([]) for _ in range(depth): self.layers.append(nn.ModuleList([ Residual(LayerNormalize(dim, Attention(dim, heads = heads, dropout = dropout))), Residual(LayerNormalize(dim, MLP_Block(dim, mlp_dim, dropout = dropout))) ])) def forward(self, x, mask = None): for attention, mlp in self.layers: x = attention(x, mask = mask) # go to attention x = mlp(x) #go to MLP_Block return x
定义整体的VT-ResNet模型:Tokennizer + Transformer:
class ViTResNet(nn.Module): def __init__(self, block, num_blocks, num_classes=10, dim = 128, num_tokens = 8, mlp_dim = 256, heads = 8, depth = 6, emb_dropout = 0.1, dropout= 0.1): super(ViTResNet, self).__init__() self.in_planes = 16 self.L = num_tokens self.cT = dim self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(16) self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1) self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2) self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2) #8x8 feature maps (64 in total) self.apply(_weights_init) # Tokenization self.token_wA = nn.Parameter(torch.empty(BATCH_SIZE_TRAIN,self.L, 64),requires_grad = True) #Tokenization parameters torch.nn.init.xavier_uniform_(self.token_wA) self.token_wV = nn.Parameter(torch.empty(BATCH_SIZE_TRAIN,64,self.cT),requires_grad = True) #Tokenization parameters torch.nn.init.xavier_uniform_(self.token_wV) self.pos_embedding = nn.Parameter(torch.empty(1, (num_tokens + 1), dim)) torch.nn.init.normal_(self.pos_embedding, std = .02) # initialized based on the paper
#self.patch_conv= nn.Conv2d(64,dim, self.patch_size, stride = self.patch_size)
self.cls_token = nn.Parameter(torch.zeros(1, 1, dim)) #initialized based on the paper self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, mlp_dim, dropout)
self.to_cls_token = nn.Identity()
self.nn1 = nn.Linear(dim, num_classes) # if finetuning, just use a linear layer without further hidden layers (paper) torch.nn.init.xavier_uniform_(self.nn1.weight) torch.nn.init.normal_(self.nn1.bias, std = 1e-6)
def _make_layer(self, block, planes, num_blocks, stride): strides = [stride] + [1]*(num_blocks-1) layers = [] for stride in strides: layers.append(block(self.in_planes, planes, stride)) self.in_planes = planes * block.expansion
return nn.Sequential(*layers) def forward(self, img, mask = None): x = F.relu(self.bn1(self.conv1(img))) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = rearrange(x, 'b c h w -> b (h w) c') # 64 vectors each with 64 points. These are the sequences or word vecotrs like in NLP
#Tokenization
# x:(b, hw, 64) # wa:(b, 64, L) # wv:(b, 64, cT) wa = rearrange(self.token_wA, 'b h w -> b w h') #Transpose A= torch.einsum('bij,bjk->bik', x, wa) A = rearrange(A, 'b h w -> b w h') #Transpose
# A:(b, L, hw) A = A.softmax(dim=-1)
# VV:(b, hw, cT) VV= torch.einsum('bij,bjk->bik', x, self.token_wV)
# T:(b, L, cT = 128) T = torch.einsum('bij,bjk->bik', A, VV) #print(T.size())
# cls_tokens:(b, 1, 128) cls_tokens = self.cls_token.expand(img.shape[0], -1, -1)
# x:(b, L+1, cT = 128) x = torch.cat((cls_tokens, T), dim=1) x += self.pos_embedding x = self.dropout(x)
# x:(b, L+1, cT = 128) x = self.transformer(x, mask) #main game
# x:(b, cT = 128) x = self.to_cls_token(x[:, 0])
x = self.nn1(x) return x
构建Dataset和Dataloader:
BATCH_SIZE_TRAIN = 100
BATCH_SIZE_TEST = 100
DL_PATH = "C:\Pytorch\Spyder\CIFAR10_data" # Use your own path
# CIFAR10: 60000 32x32 color images in 10 classes, with 6000 images per class
transform = torchvision.transforms.Compose(
[torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomRotation(10, resample=PIL.Image.BILINEAR),
torchvision.transforms.RandomAffine(8, translate=(.15,.15)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
train_dataset = torchvision.datasets.CIFAR10(DL_PATH, train=True,
download=True, transform=transform)
test_dataset = torchvision.datasets.CIFAR10(DL_PATH, train=False,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE_TRAIN,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=BATCH_SIZE_TEST,
shuffle=False)
训练和验证:
def train(model, optimizer, data_loader, loss_history): total_samples = len(data_loader.dataset) model.train()
for i, (data, target) in enumerate(data_loader): optimizer.zero_grad() output = F.log_softmax(model(data), dim=1) loss = F.nll_loss(output, target) loss.backward() optimizer.step()
if i % 100 == 0: print('[' + '{:5}'.format(i * len(data)) + '/' + '{:5}'.format(total_samples) + ' (' + '{:3.0f}'.format(100 * i / len(data_loader)) + '%)] Loss: ' + '{:6.4f}'.format(loss.item())) loss_history.append(loss.item()) def evaluate(model, data_loader, loss_history): model.eval() total_samples = len(data_loader.dataset) correct_samples = 0 total_loss = 0
with torch.no_grad(): for data, target in data_loader: output = F.log_softmax(model(data), dim=1) loss = F.nll_loss(output, target, reduction='sum') _, pred = torch.max(output, dim=1) total_loss += loss.item() correct_samples += pred.eq(target).sum()
avg_loss = total_loss / total_samples loss_history.append(avg_loss) print('\nAverage test loss: ' + '{:.4f}'.format(avg_loss) + ' Accuracy:' + '{:5}'.format(correct_samples) + '/' + '{:5}'.format(total_samples) + ' (' + '{:4.2f}'.format(100.0 * correct_samples / total_samples) + '%)\n')
N_EPOCHS = 150
model = ViTResNet(BasicBlock, [3, 3, 3])optimizer = torch.optim.Adam(model.parameters(), lr=0.003)
#optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate,momentum=.9,weight_decay=1e-4)#lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer=optimizer, milestones=[35,48],gamma = 0.1)
train_loss_history, test_loss_history = [], []for epoch in range(1, N_EPOCHS + 1): print('Epoch:', epoch) start_time = time.time() train(model, optimizer, train_loader, train_loss_history) print('Execution time:', '{:5.2f}'.format(time.time() - start_time), 'seconds') evaluate(model, test_loader, test_loss_history)
print('Execution time')
PATH = ".\ViTRes.pt" # Use your own pathtorch.save(model.state_dict(), PATH)
总结:
本文介绍的2篇文章都是Transformer在识别任务上的演进,它们的共同特点是避免使用巨大的非公开数据集,只使用ImageNet训练Transformer。DeiT的方法是通过作者提出的distillation token;而VT的做法是通过把任务搞到token域中进行,即先把图片变成一个个包含着高级语义概念的visual token,再对它们使用Transformer建模关系。这2篇文章所提出的策略都可以作为读者节约数据集的行之有效的方法。
推荐阅读
用Pytorch轻松实现28个视觉Transformer,开源库 timm 了解一下!(附代码解读)

搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二)

搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了


# 极市原创作者激励计划 #
极市平台深耕CV开发者领域近5年,拥有一大批优质CV开发者受众,覆盖微信、知乎、B站、微博等多个渠道。通过极市平台,您的文章的观点和看法能分享至更多CV开发者,既能体现文章的价值,又能让文章在视觉圈内得到更大程度上的推广。
对于优质内容开发者,极市可推荐至国内优秀出版社合作出书,同时为开发者引荐行业大牛,组织个人分享交流会,推荐名企就业机会,打造个人品牌 IP。
投稿须知:
1.作者保证投稿作品为自己的原创作品。
2.极市平台尊重原作者署名权,并支付相应稿费。文章发布后,版权仍属于原作者。
3.原作者可以将文章发在其他平台的个人账号,但需要在文章顶部标明首发于极市平台
投稿方式:
添加小编微信Fengcall(微信号:fengcall19),备注:姓名-投稿

△长按添加极市平台小编
△点击卡片关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ 














 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









