







OpenStack组件之Scheduler
Scheduler可译为调度器,由nova-scheduler服务实现,主要解决的是如何选择在哪个计算节点上启动实例的问题。它可以应用多种规则,如果考虑内存使用率、
cpu负载率、cpu构架(intel/amd)等多种因素,根据一定的算法,确定虚拟机实例能够运行在哪一台计算服务器上。Nova-scheduler服务会从队列中接收一个虚
拟机实例的请求,通过读取数据库的内容,从可用资源池中选择最合适的计算节点来创建新的虚拟机实例。
创建虚拟机实例时,用户会提出资源需求,如cpu.内存、磁盘各需要多少。Openstack将这些需求定
义在实例类型中,用户只需指定使用哪个实例类型
Nova调渡器的类型
- 随机调度器(chance scheduler) :从所有正常运行nova-compute服务的节点中随机选择。
- 过滤器调度器(filter scheduler):根据指定的过滤务件以及权重选择最佳的计算节点。Filter又称为筛选器
- 缓存调度器(caching scheduler):可看作随机调度器的一种特殊类型,在随机调度的基础上将主机资源信息缓存在本地内存中,然后通过后台的定时任务定时从数据库中获取最新的主机资源信息。
过滤器调度器的调度过程
主要分二个阶段
- 通过指定的过滤器选择满足条件的计算节点,比如内存使用率小于50%,可以使用多个过滤器依次进行过滤
- 对过滤之后的主机列表进行权重计算并排序,选择最优的计算节点来创建虚拟机实例
过滤器
- 当过滤调度器需要执行调度操作时,会让过滤器对计节点进行判断,返回True或False
letc/nova/nova.conf配置文件中
-
scheduler_available_filters选项用于配置可用过滤器
,默认是所有nova自带的过滤器都可以用于过滤作用Scheduler_available_filters = nova.scheduler.filters.all_filters -
另外还有一个选项scheduler_default_filters用于指定nova-scheduler服务真正使用的过滤器,默认值如下
Scheduler_default_filters = RetryFilters, AvailabilityZoneFilter, RamFilter,
ComputeFilter, ComputeCapabilitiesFilter,ImagePropertiesFilter,
ServerGroupAntiAffinityFilter, ServerGroupAffinityFilter
过滤调度器将按照列表中的顺序依次过滤。
- RetryFilter(再审过滤器)
主要作用是过滤掉之前已经调度过的节点。如A、B、C都通过了过滤,A权重最大被选中执行操作,由于某种原因,操作在A上失败了。Nova-filter将重新执行过滤
操作,那么此时A就被会RetryFilter直接排除,以免再次失败
- AvailabilityZoneFilter(可用区域过滤器)
为提高容灾性并提供隔离服务,可以将计算节点划分到不同的可用区域中。Openstack默认有一个命名为nova的可用区域,所有的计算节点初始是放在nova区域
中的。用户可以根据需要创建自己的一个可用区域。创建实例时,需要指定将实例部署在哪个可用区域中。Nova-scheduler执行过滤操作时,会使用
AvailabilityZoneFilter不属于指定可用区域计算节点过滤掉
- RamFilter(内存过滤器)
根据可用内存来调度虚拟机创建,将不能满足实例类型内存需求的计算节点过滤掉,但为了提高系统资源利用率,Openstack在计算节点的可用内存时允许超过实
际内存大小,超过的程度是通过nova.conf配置文件中
ram_allocation_ratio参数来控制的,默认值是1.5。
Vi/etc/nova/nova.conf
Ram_allocation_ratio=1.5
- DiskFilter(硬盘调度器)
根据磁盘空间来调度虚拟机创建,将不能满足类型磁盘需求的计算节点过滤掉。磁盘同样允许超量,超量值可修改nova.conf中disk_allocation_ratio参数控制,默
认值是1.0
Viletc/nova/nova.confdisk_allocation_ratio=1.0
- CoreFilter(核心过滤器)
根据可用CPU核心来调度虚拟机创建,将不能满足实例类型vCPU需求的计算节点过滤掉。vCPU也允许超量,超量值是通过修改nova.conf中
cpu_allocation_ratio参数控制,默认值是16。
Vi letc/nova/nova.conf
cpu_allocation_ratio=16.0
- ComputeFilter(计算过滤器)
保证只有nova-compute服务正常工作的计算节点才能被nova-scheduler调度,它是必选的过滤器。
- ComputeFilter(计算过滤器)
保证只有nova-compute服务正常工作的计算节点才能被nova-scheduler调度,它是必选的过滤器。
ComputeCapablilitiesFilter(计算能力过滤器)根据计算节点的特性来过滤,如x86_64和ARM架构的不同节点,要将实例
- lmagePropertiesFilter(镜像属性过滤器)
根据所选镜像的属性来筛选匹配的计算节点。通过元数据来指定其属性。如希望镜像只运行在KVM的Hypervisor上,可以通过Hypervisor Type属性来指定。
- ServerGroupAntiAffinityFilter(服务器组反亲和性过滤器)
要求尽量将实例分散部署到不同的节点上。例如有3个实例s1、s2.s3.3个计算节点A、B、C。具体操作如下:
创建一个anti-affinit策略的服务器组
openstack server group create -policy anti-affinity group-1
创建三个实例,将它们放入group-1服务器组
openstack server create -flavor m1.tiny -image cirros -hint group=group-1 s1
openstack server create -flavor m1.tiny -image cirros -hint group=group-1 s2
openstack server create -flavor m1.tiny -image cirros -hint group=group-1 s3
- ServerGroupAffinityFilter(服务器组亲和性过滤器)
与反亲和性过滤器相反,此过滤器尽量将实例部署到同一个计算节点上
权重(weight)
nova-scheduler服务可以使用多个过滤器依次进行过滤过滤之后的节点再通过计算权茸选出能够部署实例的节点。
注意:
所有权重位于novalschedulerlweights目录下目前默认实现是RAMweighter,根据计算节点空闲的内存量计算权重值
,空闲越多,权重越大,实例将被部署到当前空闲内存最多的计算节点上
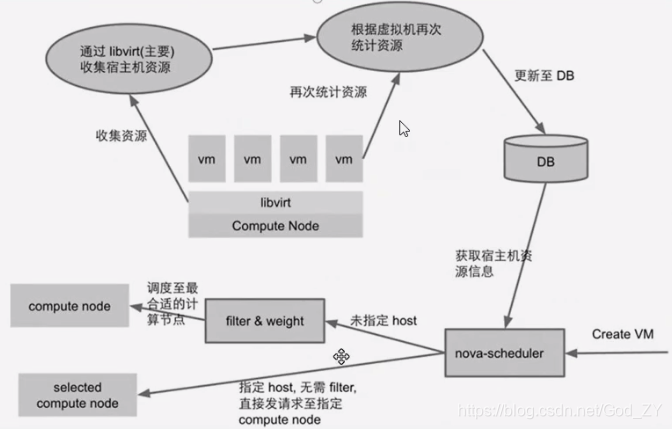
总结:
Scheduler调渡器通过DB数据库收集computenode节点信息状态,根据调度算法挑选出最合适运行的节点,缓存调渡器实时将节点的动态更新到调渡器中,避免
因为周期时间长导致Scheduler未同步节点实时信息而导致虚拟机创建失败。

















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









