







目录
2.1 /nova/scheduler/filter_scheduler.py/FilterSchduler/_schedule():
2.2 /nova/scheduler/filter_scheduler.py/FilterSchduler/_get_sorted_hosts():
2.3 /nova/scheduler/host_manager.py/HostManager/get_filtered_hosts():
2.4 /nova/filters.py/BaseFilterHandler/get_filtered_objects():
一.nova-scheduler基本介绍
我们在创建云主机的时候,openstack肯定需要选择在哪个计算节点上面创建云主机,然而选择的标准就是用户定义的flavor,flavor包括磁盘大小,内存大小,vCPU个数以及metadata等等,openstack会根据这些参数选择一个合适的计算节点来创建云主机。
1.1 基本配置
openstack的调度器有很多类型,在此我们仅讨论filter_scheduler,在配置文件nova.conf文件中的调度器驱动scheduler_driver选项选择filter_scheduler即可(其他备选项为:caching_scheduler,chance_scheduler,fake_scheduler)。
在配置文件nova.conf中的scheduler_available_filters 和 scheduler_default_filters这两个参数用于配置openstack使用的filter。其中,scheduler_available_filters表示openstack中所有可用的filter,scheduler_default_filters表示实际使用到的过滤器。
1.2 调度过程
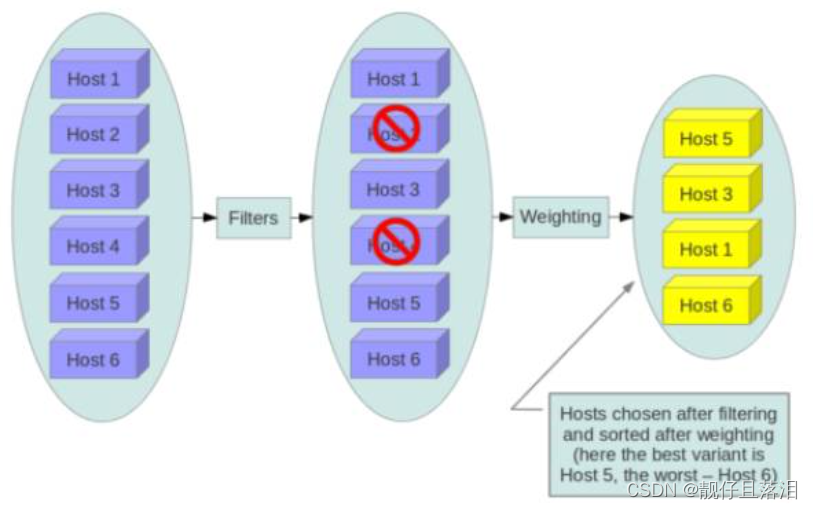
openstack的nova调度过程主要分为两步:
1. 利用多个filters结合具体flavor对计算节点进行层层过滤;
2. 利用weighting对通过filters层层过滤的计算节点进行权重的计算,最终选择权重最大的计算节点创建云主机。
二. nova-scheduler调度过程源码剖析
2.1 /nova/scheduler/filter_scheduler.py/FilterSchduler/_schedule():
首先,该函数内部会调用_get_all_host_states()函数来获得所有可用主机和节点以及对应的状态,其中_get_all_host_states()的一个传入参数provider_summaries是通过nova的Placement_API获得的所有可以提供创建云主机要求的计算节点的摘要(Placement_API会根据预期创建的主机所需资源去目前所有计算节点去搜索是否有可以满足要求的主机和节点,如果找不到则会报错:找不到有效主机);然后,获得需要创建的云主机的个数:num_instances;最后, 对于num_instances个云主机分别调用_get_sorted_hosts()过滤掉不满足要求的主机和节点,再返回找到的用于创建云主机的主机和节点。
def _schedule(self, context, spec_obj, instance_uuids,
alloc_reqs_by_rp_uuid, provider_summaries,
allocation_request_version=None, return_alternates=False):
elevated = context.elevated()
hosts = self._get_all_host_states(elevated, spec_obj,
provider_summaries)
num_instances = (len(instance_uuids) if instance_uuids
else spec_obj.num_instances)
......
for num in range(num_instances):
hosts = self._get_sorted_hosts(spec_obj, hosts, num)
if not hosts:
# NOTE(jaypipes): If we get here, that means not all instances
# in instance_uuids were able to be matched to a selected host.
# Any allocations will be cleaned up in the
# _ensure_sufficient_hosts() call.
break
instance_uuid = instance_uuids[num]
# Attempt to claim the resources against one or more resource
# providers, looping over the sorted list of possible hosts
# looking for an allocation_request that contains that host's
# resource provider UUID
claimed_host = None
for host in hosts:
cn_uuid = host.uuid
if cn_uuid not in alloc_reqs_by_rp_uuid:
msg = ("A host state with uuid = '%s' that did not have a "
"matching allocation_request was encountered while "
"scheduling. This host was skipped.")
LOG.debug(msg, cn_uuid)
continue
alloc_reqs = alloc_reqs_by_rp_uuid[cn_uuid]
# TODO(jaypipes): Loop through all allocation_requests instead
# of just trying the first one. For now, since we'll likely
# want to order the allocation_requests in the future based on
# information in the provider summaries, we'll just try to
# claim resources using the first allocation_request
alloc_req = alloc_reqs[0]
if utils.claim_resources(elevated, self.placement_client,
spec_obj, instance_uuid, alloc_req,
allocation_request_version=allocation_request_version):
claimed_host = host
break
if claimed_host is None:
# We weren't able to claim resources in the placement API
# for any of the sorted hosts identified. So, clean up any
# successfully-claimed resources for prior instances in
# this request and return an empty list which will cause
# select_destinations() to raise NoValidHost
LOG.debug("Unable to successfully claim against any host.")
break
claimed_instance_uuids.append(instance_uuid)
claimed_hosts.append(claimed_host)
# Now consume the resources so the filter/weights will change for
# the next instance.
self._consume_selected_host(claimed_host, spec_obj)
# Check if we were able to fulfill the request. If not, this call will
# raise a NoValidHost exception.
self._ensure_sufficient_hosts(context, claimed_hosts, num_instances,
claimed_instance_uuids)
# We have selected and claimed hosts for each instance. Now we need to
# find alternates for each host.
selections_to_return = self._get_alternate_hosts(
claimed_hosts, spec_obj, hosts, num, num_alts,
alloc_reqs_by_rp_uuid, allocation_request_version)
return selections_to_return 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7575
7575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









