







 本文深入探讨了Google的Facenet框架在人脸识别中的应用,详细解析了其网络结构,包括L2正则化和embedding过程。重点介绍了Facenet如何通过triplet loss而非softmax损失函数来优化特征向量之间的距离,以实现更精确的人脸识别。同时提到了中心损失(center loss)作为补充,并提供了预训练模型的获取方式。
本文深入探讨了Google的Facenet框架在人脸识别中的应用,详细解析了其网络结构,包括L2正则化和embedding过程。重点介绍了Facenet如何通过triplet loss而非softmax损失函数来优化特征向量之间的距离,以实现更精确的人脸识别。同时提到了中心损失(center loss)作为补充,并提供了预训练模型的获取方式。
在第一部分中,分析了整个小项目的体系,重点讨论了用于人脸检测对齐的mtcnn网络的实现原理,并利用笔记本电脑自带的摄像头进行了测试。今天在这里要讨论的重点是人脸识别中的核心部分——facenet网络。
facenet是Google开源的人脸识别框架,它的作用是把输入的人脸图像映射为多维特征向量,相当于对不同的人脸进行了不同的编码,同一个人脸的图像生成的编码几乎一致,不同的人脸图像生成的编码差异非常大,并以此达到识别的目的。设计一个能够达到这样效果的映射的网络是一个很难的问题,我们下面就一步一步来看facenet是怎样解决这个问题的。
首先,facenet的结构是这样的:
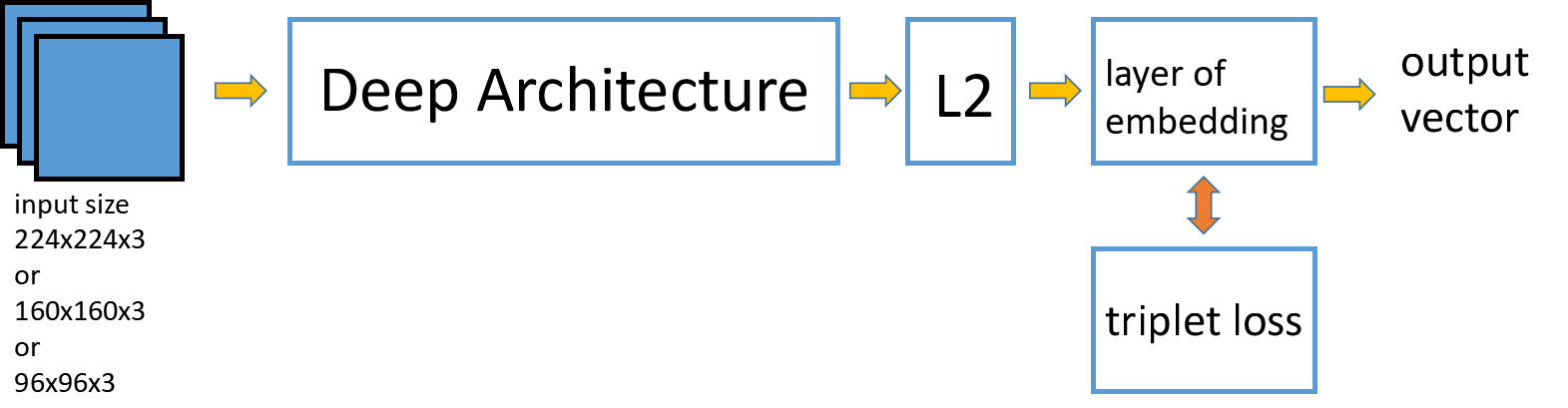
facenet网络的输入有多种不同的大小,中间部分是一个深度卷积神经网络,与其他普通CNN没有多大区别。facenet不一样的地方在于后面部分,它对深度卷积神经网络的输出做了一个L2正则化,然后再对输出进行了embedding,直接将embedding的映射结果作为特征向量输出。facenet并没有像其他一般的CNN用softmax作为损失函数,而是设计了一种新的损失——triplet loss。
在理想的情况下,特征向量之间的距离可以直接反映人脸的相似度,即:
- 对于同一个人的两张人脸图像,对应的向量之间的欧几里得距离比较小
- 对于不同人的两张图像,对应的向量之间的欧几里得距离比较大
假设人脸图像为x1和x2,对应的特征为f(x1)和f(x2)。当x1和x2对应的是同一个人脸时,其距离II f(x1)-f(x2) II应该很小,而当x1和x2对应的是不同的人脸时,其距离II f(x1)-f(x2) II应该很大。
然而事实并非如此。在一般CNN网络中,最后的输出经过softmax分类器,使用的是softmax损失。这个损失是不同类别间的损失。对于人脸来说,每一个人脸就是一个人。看起来似乎很合理,但是用softmax表示损失,以此区别出不同的人是不可行的。softmax本质上没有对每一类的向量表示之间的距离做出要求。用softmax分类的结果,可能同一个类中的向量,它的类间距比不同类中的向量间距还要大。对于这种情况,就要考虑设计新的损失函数解决问题。
下面重点看triplet loss的定义及原理
三元组损失(triplet loss)的原理:既然目标是特征之间的距离应当具备某些性质,那
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









