







Redission延迟任务的方式和坑点
我又来梳理知识负债来了,对下一个公司要求有点高,还没上岸,也没什么心情出去旅游,我一直相信上岸也是需要缘分的,天时地利人和
祝大家五一快乐吧
这篇是总结式博客,不墨迹,上干货
延迟任务其实有好几种方式,时间轮转,Timer,@Scheduler,RabbitMQ死信队列,RocketMQ这些,今天先说这个,redission中也有个延迟队列的实现,估计很多人不知道,不过没关系,就算知道也不太好用,但也想说一说,毕竟考虑用过
原理
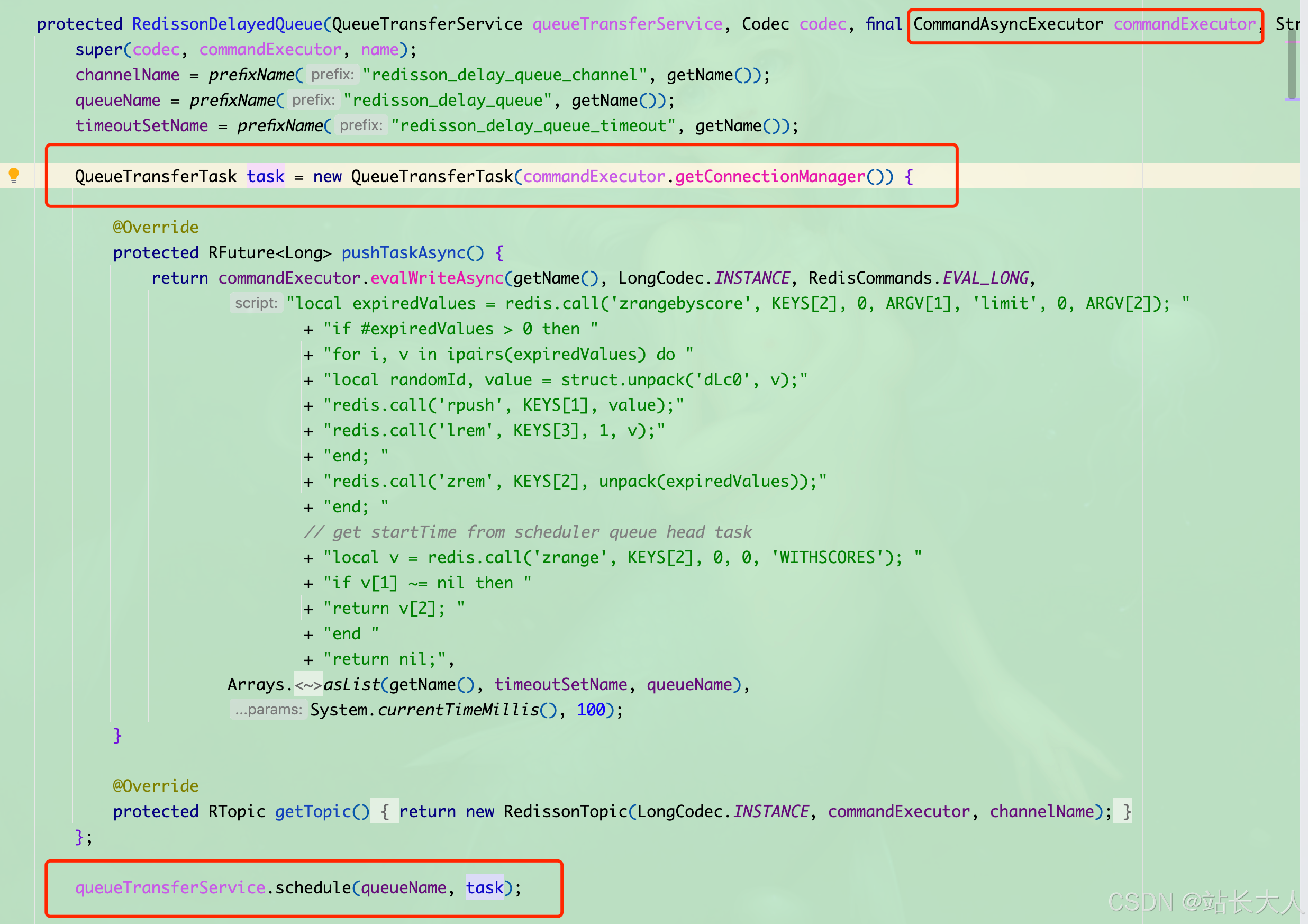
使用RBlockingQueue和RDelayedQueue组合,底层依赖Redis的ZSET结构存储延迟任务,
独立线程轮询(默认间隔1s)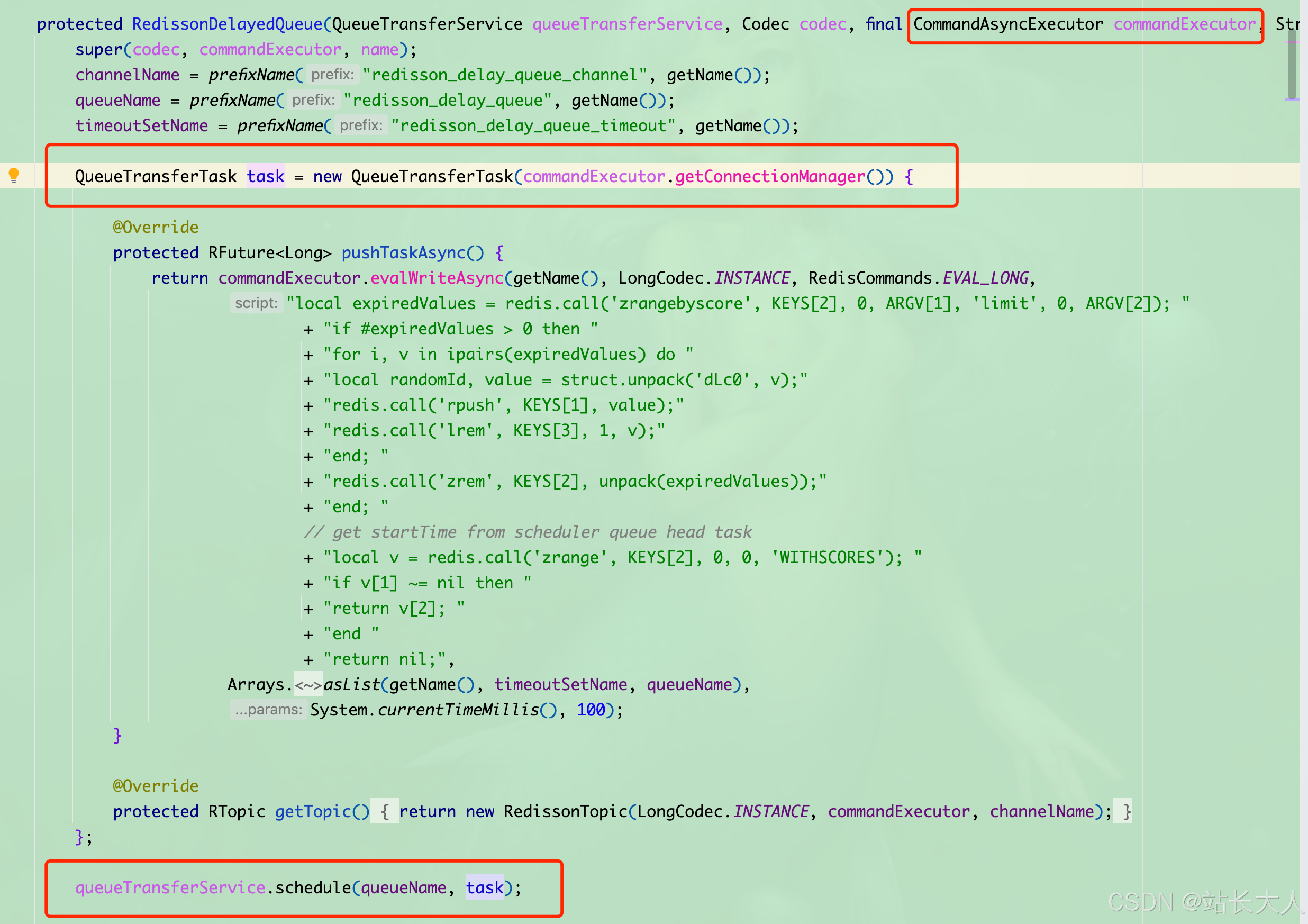
ZSET 中到期的消息,通过事件驱动将消息转移到阻塞队列,由消费者立即处理
延迟队列核心原理:阻塞队列take+独立线程轮询ZSET
这也是delayedQueue.offer() 和 blockingQueue.take() 的协作机制
当调用 delayedQueue.offer(message, delay, unit) 时,消息会暂时存储在 Redisson 的 延迟队列中间存储区(Redis 的 ZSET 结构),直到延迟时间到期后才会被自动移动到目标阻塞队列(RBlockingQueue)中。因此,blockingQueue.take() 只能在延迟时间结束后获取到消息,而 RTopic 的发布是立即触发的
分布式take阻塞机制
Redis底层行为:使用BLPOP命令实现,多个客户端监听同一队列时,Redis按连接到达顺序分配消息,每条消息仅被一个客户端取出,无重复消费(理想情况下同一消费者组是负载均衡消费的),无全局竞争开销
性能瓶颈:ZSET的ZRANGE操作在数据量大时会产生性能衰减
使用场景
- 延迟时间随机,可能超过两个小时,定时任务做不了,RocketMQ也做不了
- 订单量百万以下,数据规模中小型
config配置赋一下
public Config createProdConfig() {
Config config = new Config();
// 1. 序列化方式
config.setCodec(new JsonJacksonCodec());
// 3. 集群模式配置(示例)
ClusterServersConfig clusterConfig = config.useClusterServers()
.addNodeAddress("redis://node1:6379", "redis://node2:6380")
.setScanInterval(3000)
.setSlaveConnectionMinimumIdleSize(16)
.setSlaveConnectionPoolSize(64)
.setMasterConnectionPoolSize(32)
.setIdleConnectionTimeout(30000)
.setConnectTimeout(5000)
.setTimeout(2000)
.setRetryAttempts(3)
.setRetryInterval(1500);
// 4. SSL配置(按需)
if (useSSL) {
clusterConfig.setSslEnableEndpointIdentification(true)
.setSslProvider(SslProvider.JDK);
}
// 5. 内存保护
config.setReferenceEnabled(false);
//看门狗时间
config.setLockWatchdogTimeout(30000);
return config;
}
其中有序列化的方式,有三种方式,如下
| 特性 | JsonJacksonCodec | MsgPackJacksonCodec | JsonSmileCodec |
|---|---|---|---|
| 序列化格式 | 标准JSON文本 | MessagePack二进制 | Smile(JSON兼容的二进制格式) |
| 数据体积 | 较大(含结构标识符) | 最小(压缩率比JSON高30%-50%) | 中等(比JSON小20%-30%) |
| 处理速度 | 中等(需文本解析) | 最快(二进制直接解码) | 快(二进制流处理) |
| 可读性 | 高(人类可读) | 低(需专用工具查看) | 低(二进制但保留JSON结构) |
| 跨语言兼容性 | 全语言支持 | 主流语言支持 | 需Jackson库支持 |
| 应用场景 | 需要人工查数据中小数据量与其他非java系统交互 | IOT设备通信高频日志存储(降低磁盘占用)微服务10K+QPS的高吞吐场景 | Hadoop等大数据处理中间格式Java集群内部通信需要兼容JSON工具链的二进制场景 |
集群模式不同连接池设置的方式也不同
单点模式
config.useSingleServer()
.setAddress("redis://" + host + ":6379")
.setPassword(password)
.setSubscriptionConnectionPoolSize(64) //订阅连接池
.setConnectTimeout(5000) //连接建立超时
.setRetryAttempts(3) //命令重试次数
.setRetryInterval(1500) //命令重试间隔
.setConnectionPoolSize(128) //优化连接池大小 默认64
.setTimeout(2000) //操作超时时间
.setIdleConnectionTimeout(30_000);//优化连接超时时间
集群模式
config.useClusterServers()
.addNodeAddress("redis://" + host + ":6379")
.setScanInterval(2000) // 集群节点扫描间隔(ms)
.setSlaveConnectionPoolSize(128) // 从节点连接池
.setMasterConnectionPoolSize(64)
.setCheckSlotsCoverage(false); // 禁用槽校验(性能优化)
哨兵模式
config.useSentinelServers()
.setScanInterval(2000)
.setMasterName("mymaster")
.addSentinelAddress("redis://sentinel1:26379")
.setFailedAttempts(3); // 节点失败切换阈值
主从模式
config.useMasterSlaveServers()
.setMasterAddress("redis://master:6379")
.addSlaveAddress("redis://slave1:6379", "redis://slave2:6379")
.setReadMode(ReadMode.SLAVE); // 读操作路由到从节点
高级调优项
SSL/TLS安全连接
config.useSingleServer()
.setSslEnableEndpointIdentification(true)
.setSslProvider(SslProvider.OPENSSL) // 性能更好
.setSslTruststorePassword("password")
.setSslTruststore(new File("/path/to/truststore.jks").toURI());
离线模式优化
config.setUseScriptCache(true); // 缓存Lua脚本(默认true)
config.setScriptsExecutor(new ForkJoinPool(32)); // Lua执行线程池
响应式编程支持
config.useSingleServer()
.setSubscriptionConnectionMinimumIdleSize(12) // 响应式连接预留
.setSubscriptionConnectionPoolSize(24);
核心代码
下面分享下核心代码,其中包括重试机制,独立线程(当然了用你自己独立线程池哈),异常处理机制,死信队列,发现自己要处理的东西还蛮多的
import com.mtgg.laoxiang.common.constant.CommonConstant;
import com.mtgg.laoxiang.service.bean.DelayMessageContext;
import lombok.extern.slf4j.Slf4j;
import org.redisson.api.RBlockingQueue;
import org.redisson.api.RDelayedQueue;
import org.redisson.api.RQueue;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.util.concurrent.TimeUnit;
@Slf4j
@Component
public class DelayQueueConsumerV0 {
private RBlockingQueue<DelayMessageContext> blockingQueue;
private RDelayedQueue<DelayMessageContext> delayedQueue;
@Autowired
private RedissonClient redissonClient;
// 使用 @PostConstruct 确保 RedissonClient 已注入
@PostConstruct
public void init() {
initDelayQueue();
}
private void initDelayQueue() {
log.info("init delay queue……………………");
// 创建阻塞队列和延迟队列
this.blockingQueue = redissonClient.getBlockingQueue(CommonConstant.DELAY_QUEUE_NAME);
this.delayedQueue = redissonClient.getDelayedQueue(blockingQueue);
// 启动独立线程监听消息,用线程池创建即可
new Thread(() -> {
//判断中断标志,若已中断则中断线程
while (!Thread.currentThread().isInterrupted()) {
try {
log.info("阻塞获取消息1……………………");
DelayMessageContext context = blockingQueue.take(); // 阻塞获取消息
handleMessage(context);
} catch (InterruptedException e) {
log.error("init delay queue error", e);
Thread.currentThread().interrupt();
}
}
}).start();
}
public void handleMessage(DelayMessageContext context) {
try {
// 业务处理逻辑,拿到消息可以根据id去数据库获取完整数据处理,避免大参数在上下文中传递
log.info("获取到消息-处理消息: " + context);
} catch (Exception e) {
log.error("handleMessage error", e);
handlerRetry(context, e);
}
}
private void handlerRetry(DelayMessageContext context, Exception e) {
String messageId = "businessType:" + context.getId();
//原子操作
long currentRetryCount = redissonClient.getAtomicLong("retry:" + messageId).incrementAndGet();
log.info("消息处理失败,当前重试次数+1后:id:{}, retryCount:{} ", context.getId(), currentRetryCount);
if (currentRetryCount > CommonConstant.MAX_RETRY_COUNT){
//超过最大重试次数,进入死信队列
sendToDlq(context);
return;
}
//计算下一次重试延迟时间(用指数避退,每次延迟不一样)
long delayTime = (long) (CommonConstant.INITIAL_DELAY_SECONDS
* Math.pow(CommonConstant.BACKOFF_MULTIPLIER, currentRetryCount));
log.info("消息处理失败,准备重试,当前重试次数: " + currentRetryCount + ", 重试延迟时间: " + delayTime + "秒");
//重新放入延迟队列
delayedQueue.offer(context, delayTime, TimeUnit.SECONDS);
log.info("消息重新放入延迟队列:id:{}", context.getId());
}
private void sendToDlq(DelayMessageContext context){
RQueue<Object> dlq = redissonClient.getQueue(CommonConstant.DLQ_PREFIX + CommonConstant.DELAY_QUEUE_NAME);
dlq.add(context);
log.info("消息进入死信队列:id:{}", context.getId());
}
@PreDestroy
public void destroy() {
log.info("销毁队列释放资源……………………");
if (delayedQueue != null) {
delayedQueue.destroy();
}
if (redissonClient != null && !redissonClient.isShutdown()) {
redissonClient.shutdown();
}
}
}
这里我们用RAtomicLong,其实可以使用RMap的addAndGetAsync,因为RMap的底层是个hash,一个key解决了所有次数问题,内存占用低节省空间,聚合查询方便
当然,如果是初期少量的计数器<100可用AtomicLong;大于100最好用Hash,像失败重试这种场景应该不会很多,可以使用AtomicLong
相关问题
为什么不好用?
- take拿到数据Redis就已经移除了,会存在数据丢失风险,后面细说
- 重试机制等都得自己做
- 每个实例只要调用getDelayedQueue()方法就会启动一个轮询线程轮询Redis-ZSET
take阻塞监听的缺陷
-
获取到消息就会被移除,存在丢失风险
-
性能瓶颈:高并发场景如果大量节点占用连接资源会影响吞吐量
-
一个服务一个take,不会有大量节点,也可以避免大量节点,用分片解决吞吐量问题,充分利用单机cpu
-
故障恢复延迟,消费者宕机后,它未处理的消息需要等待TCP连接超时(默认数分钟)才能被其他客户端获取,业务会延迟
take取出会移除当前元素,如果宕机了怎么办?
- 取出元素可以发送到MQ中,依赖MQ强大的消息重试,保证数据最终一致性
- 若取出后还未来的及发送到MQ就宕机,依赖5-10分钟一次的定时任务,检测已到时间还未执行的记录,发送MQ继续执行
重复消费-服务集群是否需要做幂等?
答案是需要。原则性来说具备原子性不用做幂等
原子性:Redisson 的 RBlockingQueue.take() 方法基于 Redis 的 BRPOP 命令实现,消息仅会被一个消费者获取,天然具备互斥性
但是如果已取出-处理中服务宕机,或者网络闪断导致连接超时-Redis认为当前节点断开可能给其他节点获取,导致重复消费
高可用问题-内部轮询线程中断可能消息丢失或无法延迟消费
原因:可能服务宕机、持久化失败、网络问题等等,或take获取后直接宕机消息丢失
目标:
- 高可用:任意消费者实例宕机,其他实例立即接管其任务
- 消息可靠:消息处理失败后自动重试,不丢失
- 负载均衡:根据消费者处理能力动态分配任务
方案对比:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 简单集群竞争消费 | 实现简单 | 消息可能重复消费、无故障转移、负载不均 |
| 分片+分布式锁 | 高可用、负载均衡 | 实现较复杂,需管理锁生命周期 |
| 消费者组(Kafka风格) | 完善的负载均衡和重试机制 | Redis 原生不支持,需借助 Streams 等高级数据结构 |
解决方案:
- 可数据库定时任务扫描执行延迟任务兜底,缺点是无法及时发布
- 当前线程异常终止:需异常拦截处理 + 重试机制保证线程存活
- 消息可能丢失:结合ACK确认+死信队列实现可靠消费或重新投递
- 配置持久化策略:AOF+ fcync everysec,平衡性能与安全
- 取出直接发到MQ中
吞吐量问题
可用分片消费设计,提高横向扩展处理能力,提高吞吐量的,可以按hash规则定义多个队列分别处理,适用于消息处理耗时比较高,需要并行加速消耗队列中的积压
什么时候启动独立线程轮询ZSET?
redissonClient.getDelayedQueue,在程序调用这行代码时会启动一个独立的延迟调度线程
Redisson多节点部署,延迟队列是否有问题?
有问题,微服务配置Redisson,多节点部署就会启动多个独立线程轮询Redis-ZSET
这时有可能会都检测到消息到期转移到BlockingQueue中,导致重复消费
- 竞争调度,重复消费使用分布式锁控制,或者幂等
- 多个轮询队列对Redis也会有一定的压力
- 控制只有一个实例启动时调用redissonClient.getDelayedQueue启动调度任务,其他实例不调用
- 但会有一个问题,如果实例挂了调度任务也会挂,可以定时任务动态设置备用节点,定期检测启用;进而引发一个问题:这样其他节点就不能再发送延迟消息,因为发送延迟消息就要调用getDelayedQueue(),调用就会启动独立线程轮询,就比较尴尬
有时候就是这样,我们要做的就是打造自己的船,等风来~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











