









一、单选题(每题2分,共20分)
1. -7的二进制补码表示为:
A. 01111000 B. 01111001 C. 11111000 D. 11111001
解析:正数的原码反码补码均相同,负数反码为除符号位外反转各个二进制位,补码为反码+1.
-7的原码:10000111
-7的反码:11111000
-7的补码:11111001
答案:D
2.以下四种介质中,带宽最大的是________。
A. 同轴电缆(coaxial) B. 双绞线(twisted pair) C. 光纤(twisted pair) D. 同步线(synchronous)
解析:双绞线也称为双扭线,是最古老但又最常用的传输媒体。把两根互相绝缘的铜导线并排放在一起,然后用规则的方法绞合起来(这样做是为了减少相邻的导线的电磁干扰)而构成双绞线。双绞线分为1类到5类,局域网中常用的为3类,4类和5类双绞线。 3类线用于语音传输及最高传输速率为 10Mbps的数据传输;4类线用于语音传输和最高传输速率为 16Mbps的数据传输;5类线用于语音传输和最高传输速率为 100Mbps的数据传输
同轴电缆由内导体铜质芯线,绝缘层,网状编制的外导体屏蔽层及保护塑料外层组成 ,内导体和外导体构成一组线对。由于外导体屏蔽层的作用,同轴电缆具有很好的抗干扰性。同轴电缆可以将 10Mb/S的基带数字信号传送1千米到 1.2千米,因此被广泛用于局域网中
光纤通信就是利用光导纤维传递光脉冲来进行通信,而光导纤维是光纤通信的媒体。光纤在任何时间都只能单向传输,因此,要实行双向通信,它必须成对出现,一个用于输入,一个用于输出,光纤两端接到光学接口上。光纤的传输系统比同轴电缆大的多,一般小同轴电缆的最大传输带宽为 20MHz左右,中同轴电缆的最大传输带宽为 60MHz左右。单根光导纤维的数据传输速率能达几Gbps,在不使用中继器的情况下,传输距离能达几十公里。
答案:C
3. 进程阻塞的原因不包括________。
A. 时间片切换 B. 等待I/O C. 进程sleep D. 等待解锁
解析:进程有3个状态:就绪态。执行态、阻塞态。三种状态的转换包含有:
就绪->执行,执行->就绪,执行->阻塞,阻塞->就绪
等待I/O、进程sleep、等待解锁等原因都会导致进程暂停。关于"时间片切换",当进程已经获得了除cpu外所有的资源,这时的状态就是就绪态,当分配到了时间片就成了执行态,当时间片用完之前一直未进入阻塞态的话,此后便继续进入就绪态。所以进程的就绪与阻塞是完全不同的。
答案:A
4. 设只含根节点的二叉树高度为1,现有一颗高度为h(h>1)的二叉树上只有出度为0和出度为2的结点,则此二叉树中所包含的结点数至少为________个。
A. 2^h-1 B. 2h-1 C. 2h D. 2h+1
解析:我们可以画一棵高度为2的树,显然只有3个结点,所以答案为2h-1
答案:B
5. 给定下列程序,那么执行printf("%d\n", foo(20, 13));的输出结果是________。
A. 3 B. 9 C. 27 D. 81
解析:foo(20, 13) = 3 * foo(14, 6) = 3 * 3 * foo(8, 3) = 3 * 3 * 3 * foo(2, 1) = 3 * 3 * 3 * 3 * foo(-4, 0) =3 * 3 * 3 * 3 * 1 = 81
答案:D
6. 对于以下说法,错误的是________。
A. Dijkstra算法用于求解图中两点间最短路径,其时间复杂度O(n^2)
B. Floyd-Warshall算法用于求解图中所有点对之间最短路径,其时间复杂度为O(n^3)
C. 找出n个数字的中位数至少需要O(n*logn)的时间
D. 基于比较的排序问题的时间复杂度下界是O(n*logn)
解析:AB正确,考察基本算法。C错误,最少是O(n)的时间,具体可参考这篇文章。D正确,基于比较的话,怎么样都至少需要O(n*logn)的时间。
答案:C
7. 给定一个m行n列的整数矩阵(如图),每行从左到右和每列从上到下都是有序的。判断一个整数k是否在矩阵中出现的最优算法,在最坏情况下的时间复杂度是________。
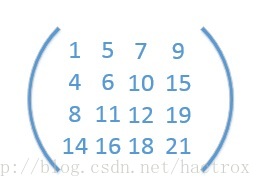
A. O(m*n) B. O(m+n) C. O(log(m*n)) D. O(log(m+n))
解析:我的理解是二分,先找到矩阵中间(中间一行和中间一列)的元素,然后就可以判断目标元素在坐上,右上,左下还是右下了,然后继续递归查找。
答案:C
8. 一个包里有5个黑球,10个红球和17个白球。每次可以从中取两个球出来,放置在外面。那么至少取________次以后,一定出现过取出一对颜色一样的球。
A. 16 B. 9 C. 4 D. 1
解析:首先我想C和D是可以直接排除的。因为题目说一定,拿1次或4次都不能保证其中两个颜色的球会消失。9次也不可能,比如说9次中每次都拿了一个红球和一个白球。知道了答案以后回过头来看看题目,5+10+17=32=2*16,全拿光的情况下一定会出现一对颜色相同的球,不知道题目想要考察些什么-.-
答案:A
9. 某地电信局要对业务号码进行梳理,需要检测开通的市话号码是否存在某一个是另一个的前缀的情况,以简化电话交换机的逻辑。例如:某用户号码是“11001100”,但与"110"报警电话产生前缀配对。已知市话号码最长8位,最短3位,并且所有3位的电话号码都以1开头。由于市话号码众多,长度也未必一直,高效的算法可以用O(n)的时间复杂度完成检测(n为开通市话号码个数,数量是千万级的)。那么,该算法最坏情况下需要耗费大约________内存空间。
A. 5GB B. 500MB C. 50MB D. 5MB
解析:千万级,也就是10,000,000。市话最长8为,也就是一个字节的空间,那么全部存下这些号码所耗费的空间为:1B*1000*1000*10 = 10MB(不必纠结1000还是1024,只要代表了千万级的数量就行了)。所以是两位数的级别。
答案:C
10. 骑士只说真话,骗子只说假话。下列场景中能确定一个骑士、一个骗子的有________。
A. 甲说:“我们中至少有一个人说真话”,乙什么也没说。
B. 甲说:"我们两个都是骗子",乙什么也没说。
C. 甲说:“我是个骗子或者乙是个骑士”,乙什么也没说。
D. 甲和乙都说:“我是个骑士”。
E. 甲说:“乙是个骑士”,乙说:“我们俩一个是骑士一个是骗子”。
解析:我觉得这道题有个很明显的坑,千万不要用甲乙一个是骗子一个是骑士来代入问题。因为他们两人都可能是骗子或都有可能是骑士。所以题目才会问能不能确定一个为骑士一个为骗子,而不是问"哪个是骑士哪个是骗子"。我们可以按照"甲如果是骗子,甲如果是骑士"的思路来代入每一个情景,就比较好判断了。
答案:B
11. 某服务请求经负载均衡设备分配到集群A、B、C、D进行处理响应的概率分别是10%、20%、30%和40%。已知测试集群所得的稳定性指标分别是90%、95%、99%和99.9%。现在该服务器请求处理失败,且已排除稳定性以外的问题,那么最有可能在处理该服务请求的集群是________。
A. A B. B C. C D. D
解析:选中该集群,并且处理失败了的概率为:10%*10、%20%*5%、30%*1%、40%*0.1%。A与B的概率最高。
答案:A、B
12. 以下________状态为TCP连接关闭过程中的出现的状态。
A. LISTEN B. TIME-WAIT C. LAST-ACK D. SYN-RECEIVED
解析:
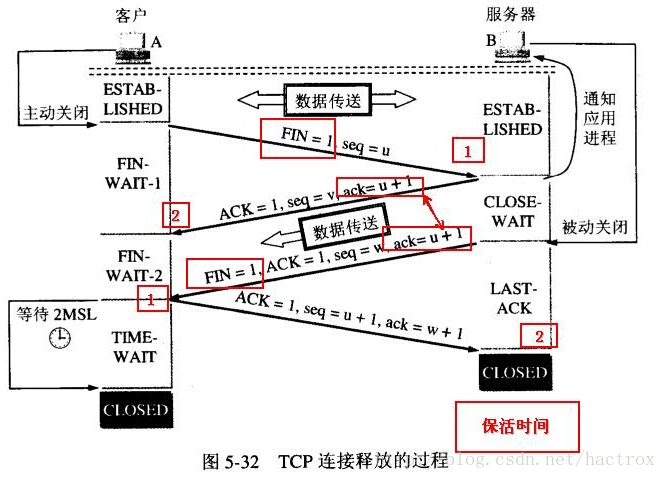
答案:B、C
13. 甲乙两人捡到一个价值10元的购物卡。协商后打算通过这样的拍卖规则来确定归属:两人单独出价(可以出0元),出价高者得到购物卡同时将与出价相同数量的前给对方。如果两人出价相同,则通过掷硬币来决定购物卡的归属。例如:甲和乙都出价1元,他们通过掷硬币来决定购物卡的归属。此时,得到购物卡的人赚9元,另一人赚1元。两人都同意用手头的现金来进行出价。甲和乙都知道甲有6元、乙有8元,两人都期望自己尽可能多赚。那么________。
A. 乙最终赚的比甲多 B. 甲最终赚的比乙多 C. 甲乙两人中可能有一人会有损失 D. 甲乙两人赚的一样多
解析:思路有点乱,最终猜是D结果选错了。一个网上的解析:假设甲出6元,如果乙出的比6少则甲赔,乙出的比6多则乙赔。
答案:C
14. 如果在一个排序算法的执行过程中,没有一对元素被比较过两次或以上,则称该排序算法为节俭排序算法,以下算法中是节俭排序算法的有________。
A. 插入排序 B. 选择排序 C. 堆排序 D. 归并排序
答案:A、D
三、填空与问答(每题8分,共40分)
15. 请补全下面的快速排序代码:
答案:
array[start++] = array[end];
array[end--] = array[start];
array[start] = value;
start
array+start+1, len-start-1
16. 图示是一个网络流从s到t的某时刻快照。此时t处一共接收到10+13+16=39单位流量。每条横线上的数字表示当前流量和管道的容量。那么,该网络最大的流量是多少?当着个网络流量最大时,哪几条边是满负荷的(边用两边顶点标识,s3表示从s到3的边,图上的流量和容量表示为10/10)。

解析:最基本的求最大流。可以手动计算,答案为41。可以用最大流模板验证正确性:设s为1,t为8,那么中间结点的实际编号为上图编号+1. 数据如下:
一种方案为:

17. 某公司有这么一个规定:只要有一个员工过生日,当天所有员工全部放假一天。但在其余时候,所有员工都没有假期,必须正常上班。假设一年有365天,每个员工的生日都概率均等地分布在这365天里。那么,这个公司需要雇用多少员工,才能让公司一年内所有员工的总工作时间期望值最大?
解析:哎我没算对。。以下是来自Matrix67大神的解释:
你的第一感觉或许是,公司应该雇用 100 多人,或者 200 多人吧。答案或许会让你大吃一惊:公司应该雇用 365 个人。注意,雇用 365 个人并不意味着全体员工全年的总工作时间为 0 ,因为 365 个人的生日都是随机的,恰好每天都有一个人过生日的概率极小极小。下面我们就来证明,这个问题的最优解就是 365 人。
由于期望值满足线性关系(即对于随机变量 X 和 Y 有 E(X) + E(Y) = E(X+Y) ),因此我们只需要让每一天员工总工作时间的期望值最大就可以了。假设公司里有 n 个人,那么在特定的一天里,没有人过生日的概率是 (364/365)n 。因此,这一天的期望总工作时间就是 n · (364/365)n 个工作日。为了考察函数 n · (364/365)n 的增减性,我们来看一下 ((n+1) · (364/365)n+1) / (n · (364/365)n) 的值,它等于 (364 · (n+1)) / (365 · n) 。如果分子比分母小,解得 n > 364 。可见,要到 n = 365 以后,函数才是递减的。
答案:365
18. 给定一个排好升序的数组A[1]、A[2]、……、A[n],其元素的值都两两不相等。请设计一高效的算法找出中间所有A[i] = i的下标。并分析其复杂度。(不分析复杂度不得分)
解析:首先分析一下这个数组,假设其中某个位置的A[i] = i,那么可以肯定的值,之前的A[x] > x,之后的A[x] < x。还有一个显而易见的性质就是中间的A[i]=i一定是连续存在的,不可能跨区域存在,因为这个数组是升序的。
我给出的方法是二分查找,具体的做法是:我们假设一个新数组B,其元素是A[i] - i的值,这样的话,B[i] = 0的时候A[i] = i,而且把B数组划分成了三个部分,左边的小于零的区域,中间的等于零的区域,右边的大于零的区域。
我第一次的想法是:二分搜索这个想象中的新数组,找到值为零的下标,但是这个下标不一定是最左边的满足条件的下标,所以我们还需要写一个while来往左移动这个下标,直到找到最左边的符合条件的下标,如下代码(假设已经通过二分查找找到了符合条件的一个下标idx):
这样的话其时间复杂度就是O(logn) + O(n),还是属于On)的范畴。
后来我想到,为什么只去随机命中一个目标下标呢!如果二分查找这个数据的边界的话,就能直接得到最左边符合条件的下标了!其实二分查找不仅仅适用于对一个元素的搜索,也可以用于两个、三个特定相对位置元素的搜索。每次查找的时候,假设当前位置是mid,那么只要判断当前A[mid] - mid是否小于零,以及后一个元素A[mid+1] - (mid+1) == 0就行了。
OK! 由于程序是原生的二分查找,所以时间复杂度为O(logn),没有占用额外的空间。并且不需要区分正整数还是负整数,数据类型也可以改成double没问题。
19. 某怪物被海水冲上一个孤岛。醒来时他发现自己处于险境。周围有N条鳄鱼都虎视眈眈的盯着他。每条鳄鱼看上去都饿得足以把他吞下去。不过,事情也未必真的那么糟糕。鳄鱼吞下他是要花费体力的。这些鳄鱼现在的体力都相当,由于猎食需要花费体力,所以吞下怪物的鳄鱼会由于体力下降而可能被周围的某条鳄鱼吞了。类似的,吞鳄鱼的这条鳄鱼也可能被其他鳄鱼吞了。因此,虽然有食物可猎,但他们自己并不想成为其他鳄鱼的猎食对象。正所谓,螳螂捕蝉,黄雀在后。所以鳄鱼们在确保自己生命安全的情况下才会发动进攻。那么,怪物到底安全么?为什么?
解析:当鳄鱼为偶数的时候,鳄鱼们两两相互制约,只要谁先吃了怪物,那这条鳄鱼就会被吃掉,所以这个时候怪物是安全的。当鳄鱼为奇数的时候,当第一条鳄鱼吃掉了怪物而变得虚弱时,剩下的鳄鱼们为偶数,两两相互制约,谁也不能吃这个吃了怪物的鳄鱼,所以第一个动手的是安全的,既然这样谁都想第一个动手,所以这个时候怪物就完蛋了。
20. 当你在浏览器输入一个网址,如http://www.taobao.com,按回车之后发生了什么?请从技术的角度描述,如浏览器、网络(UDP、TCP、HTTP等),以及服务器等各种参与对象上由此引发的一系列活动,请尽可能的涉及到所有的关键技术点。
解析:首先你输入了一个网址并按下了回车,这个时候浏览器会根据这个URL去查找其对应的IP,具体过程如下:
首先是查找浏览器缓存,浏览器会保存一段时间你之前访问过的一些网址的DNS信息,不同浏览器保存的时常不等。
如果没有找到对应的记录,这个时候浏览器会尝试调用系统缓存来继续查找这个网址的对应DNS信息。
如果还是没找到对应的IP,那么接着会发送一个请求到路由器上,然后路由器在自己的路由器缓存上查找记录,路由器一般也存有DNS信息。
如果还是没有,这个请求就会被发送到ISP(注:Internet Service Provider,互联网服务提供商,就是那些拉网线到你家里的运营商,中国电信中国移动什么的),ISP也会有相应的ISP DNS服务器,一听中国电信就知道这个DNS服务器的规模肯定不会小,所以基本上都能在这里找得到。题外话:会跑到这里进行查询是因为你没有改动过"网络中心"的"ipv4"的DNS地址,万恶的电信联通可以改动了这个DNS服务器,换句话说他们可以让你的浏览器跳转到他们设定的页面上,这也就是人尽皆知的DNS和HTTP劫持,ISP们还美名曰“免费推送服务”。强烈鄙视这种霸王行为。我们也可以自行修改DNS服务器来防止DNS被ISP污染。
如果还是没有的话, 你的ISP的DNS服务器会将请求发向根域名服务器进行搜索。根域名服务器就是面向全球的顶级DNS服务器,共有13台逻辑上的服务器,从A到M命名,真正的实体服务器则有几百台,分布于全球各大洲。所以这些服务器有真正完整的DNS数据库。如果到了这里还是找不到域名的对应信息,那只能说明一个问题:这个域名本来就不存在,它没有在网上正式注册过。或者卖域名的把它回收掉了(通常是因为欠费)。
这也就是为什么打开一个新页面会有点慢,因为本地没什么缓存,要这样递归地查询下去。
多说一句,例如"mp3.baidu.com",域名先是解析出这是个.com的域名,然后跑到管理.com域名的服务器上进行进一步查询,然后是.baidu,最后是mp3,
所以域名结构为:三级域名.二级域名.一级域名。
浏览器终于得到了IP以后,浏览器接着给这个IP的服务器发送了一个http请求,方式为get,例如访问nbut.cn
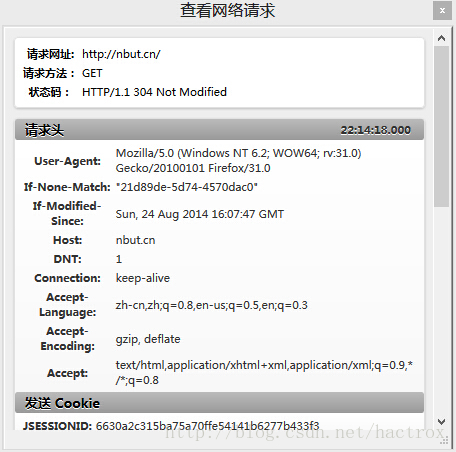
这个get请求包含了主机(host)、用户代理(User-Agent),用户代理就是自己的浏览器,它是你的"代理人",Connection(连接属性)中的keep-alive表示浏览器告诉对方服务器在传输完现在请求的内容后不要断开连接,不断开的话下次继续连接速度就很快了。其他的顾名思义就行了。还有一个重点是Cookies,Cookies保存了用户的登陆信息,在每次向服务器发送请求的时候会重复发送给服务器。Corome上的F12与Firefox上的firebug(快捷键shift+F5)均可查看这些信息。
发送完请求接下来就是等待回应了,如下图:
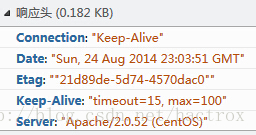
当然了,服务器收到浏览器的请求以后(其实是WEB服务器接收到了这个请求,WEB服务器有iis、apache等),它会解析这个请求(读请求头),然后生成一个响应头和具体响应内容。接着服务器会传回来一个响应头和一个响应,响应头告诉了浏览器一些必要的信息,例如重要的Status Code,2开头如200表示一切正常,3开头表示重定向,4开头,如404,呵呵。响应就是具体的页面编码,就是那个<html>......</html>,浏览器先读了关于这个响应的说明书(响应头),然后开始解析这个响应并在页面上显示出来。在下一次CF的时候(不是穿越火线,是http://codeforces.com/),由于经常难以承受几千人的同时访问,所以CF页面经常会出现崩溃页面,到时候可以点开火狐的firebug或是Chrome的F12看看状态,不过这时候一般都急着看题和提交代码,似乎根本就没心情理会这个状态吧-.-。
如果是个静态页面,那么基本上到这一步就没了,但是如今的网站几乎没有静态的了吧,基本全是动态的。所以这时候事情还没完,根据我们的经验,浏览器打开一个网址的时候会慢慢加载这个页面,一部分一部分的显示,直到完全显示,最后标签栏上的圈圈就不转了。

这是因为,主页(index)页面框架传送过来以后,浏览器还要继续向服务器发送请求,请求的内容是主页里面包含的一些资源,如图片,视频,css样式等等。这些"非静态"的东西要一点点地请求过来,所以标签栏转啊转,内容刷啊刷,最后全部请求并加载好了就终于好了。

需要说明的是,对于静态的页面内容,浏览器通常会进行缓存,而对于动态的内容,浏览器通常不会进行缓存。缓存的内容通常也不会保存很久,因为难保网站不会被改动。
-.-大概就是这样一个过程了,本人的能力与理解有限,可能说的不是很好,也可能遗漏了一些地方,欢迎补充与指正~















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









