








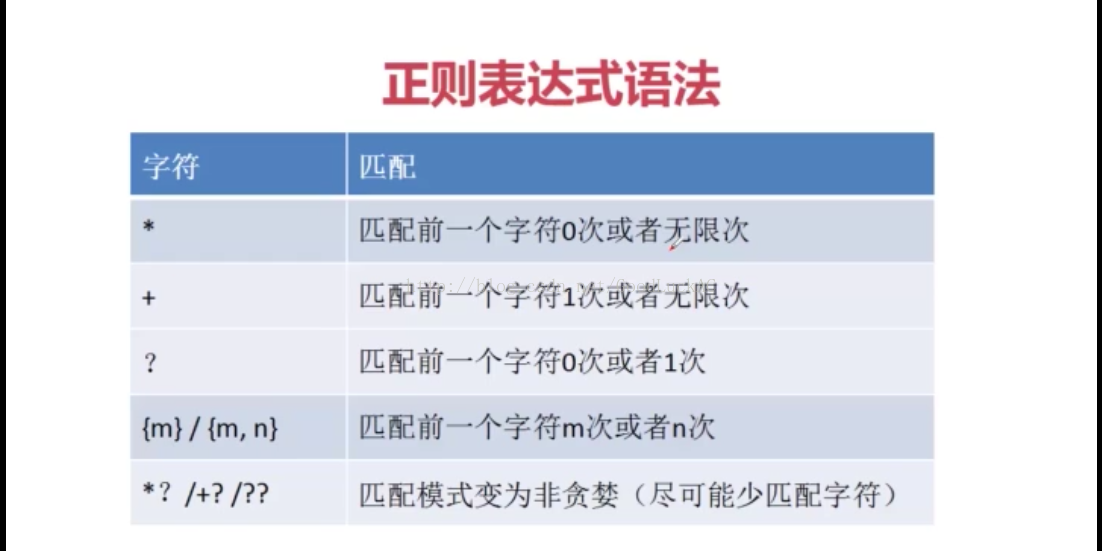
#'*'的作用就是匹配前一个字符0次或者是无限次
In [5]: ma=re.match(r'[A-Z][a-z]*','A')#匹配0次
In [6]: ma
Out[6]: <_sre.SRE_Match at 0xb61cbd08>
In [7]: ma.group()
Out[7]: 'A'
In [8]: ma=re.match(r'[A-Z][a-z]*','Asdkjljfsjdfoidjs')#'*'的作用就是匹配前一个字符无限次,无法匹配开头的数字
In [9]: ma
Out[9]: <_sre.SRE_Match at 0xb61cbd40>
In [10]: ma.group()
Out[10]: 'Asdkjljfsjdfoidjs'
In [11]: ma=re.match(r'[A-Z][a-z]*','Asdkjljfsjdfoidjs1')#可以匹配数字前的字符串
In [12]: ma.group()
Out[12]: 'Asdkjljfsjdfoidjs'
ma=re.match(r'[_A-Za-z]+','_HTll')#'+'的作用就是匹配前面的字符一次或者是无限次也就是说只要有加号出现至少是匹配字符串本身
In [13]: ma=re.match(r'[_A-Za-z]+','_')
In [14]: ma
Out[14]: <_sre.SRE_Match at 0xb6b86e20>
In [4]: ma=re.match(r'[_a-zA-Z]','')
In [5]: ma
In [6]: ma=re.match(r'[_a-zA-Z]',' ')
In [7]: ma
In [6]: ma
Out[6]: <_sre.SRE_Match at 0xb6b86b10>
In [7]: ma=re.match(r'[_A-Za-z]+','_Hll')
In [8]: ma
Out[8]: <_sre.SRE_Match at 0xb6b86c28>
In [9]: ma.group()
Out[9]: '_Hll'
In [10]: ma=re.match(r'[_A-Za-z]+','_')
In [11]: ma
Out[11]: <_sre.SRE_Match at 0xb6b86d08>
In [12]: ma.g
ma.group ma.groupdict ma.groups
In [12]: ma.group()
Out[12]: '_'
In [8]: ma=re.match(r'[1-9]?[0-9]','90')#?可以匹配前一个字符串一个或者0个,就是说可以匹配‘ ’或者任意一个数前面的字符串可以看作一个工具
In [9]: ma
Out[9]: <_sre.SRE_Match at 0xb6132d78>
In [10]: ma.group()
Out[10]: '90'
In [11]: ma=re.match(r'[1-9]?[0-9]','911')
In [12]: ma.group()
Out[12]: '91'
In [13]: ma=re.match(r'[1-9]?[0-9]','09')
In [14]: ma.group()
Out[14]: '0'
In [3]: ma=re.match(r'[\w]{6,10}@qq.com','2991483698@qq.com')#{}的意思就是[]出现的字符出现的次数6-10次
In [4]: ma
Out[4]: <_sre.SRE_Match at 0xb6194c98>
In [5]: ma.group()
Out[5]: '2991483698@qq.com'
In [6]: ma=re.match(r'[0-9][a-z]*?','1bz')#*?就是尽可能匹配不到字符串,所以按照*的语法规则,不会匹配任何值
In [7]: ma.group()
Out[7]: '1'
In [8]: ma=re.match(r'[0-9][a-z]+?','1bz')#+?就是尽可能匹配不到字符串,按照+号的的语法规则,至少匹配一个字符
In [9]: ma.group()
Out[9]: '1b'















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









