






文章目录
基本概念
1、变分自编码器属于无监督学习
2、变分自编码器的主要作用是可以生成数据
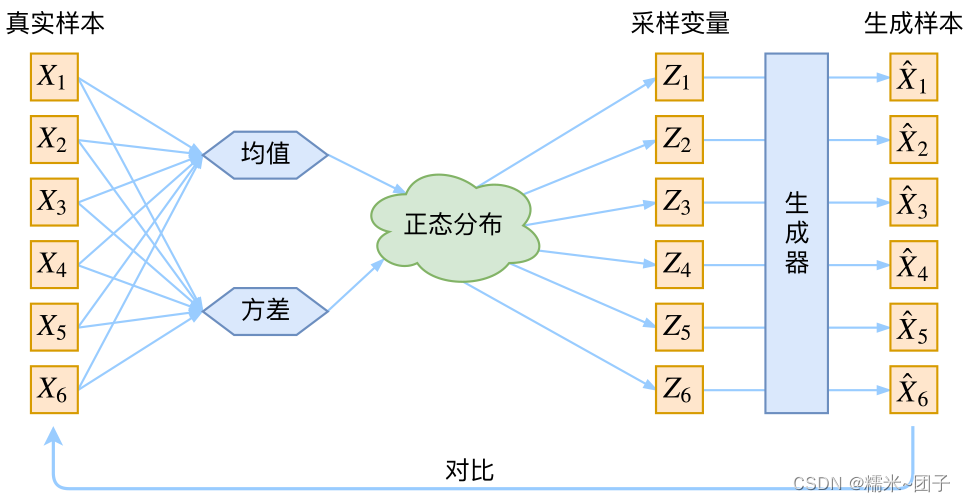
3、VAE的网络结构:
Tensorflow实现
VAE实现 MNIST 手写数字识别
1、库导入:
import os
import tensorflow as tf
from tensorflow import keras
from PIL import Image
from matplotlib import pyplot as plt
from tensorflow.keras import Sequential, layers
import numpy as np
2、数据集加载:
# 数据集加载,自编码器不需要标签因为是无监督学习
(x_train, _), (x_test, _) = keras.datasets.fashion_mnist.load_data()
x_train, x_test = x_train.astype(np.float32) / 255., x_test.astype(np.float32) / 255.
train_db = tf.data.Dataset.from_tensor_slices(x_train)
train_db = train_db.shuffle(batchsz * 5).batch(batchsz)
test_db = tf.data.Dataset.from_tensor_slices(x_test)
test_db = test_db.batch(batchsz)
3、模型搭建:
3.1 网络模块
# 编码网络
self.vae_encoder = layers.Dense(self.units)
# 均值网络
self.vae_mean = layers.Dense(self.z_dim) # get mean prediction
# 方差网络(均值和方差是一一对应的,所以维度相同)
self.vae_variance = layers.Dense(self.z_dim) # get variance prediction
# 解码网络
self.vae_decoder = layers.Dense(self.units)
# 输出网络
self.vae_out = layers.Dense(784)
3.2 encoder传播
def encoder(self, x):
h = tf.nn.relu(self.vae_encoder(x))
#计算均值
mu = self.vae_mean(h)
#计算方差
log_var = self.vae_variance(h)
return mu, log_var
3.3 decoder传播
def decoder(self, z):
out = tf.nn.relu(self.vae_decoder(z))
out = self.vae_out(out)
return out
3.4 参数重设定
def reparameterize(self, mu, log_var):
eps = tf.random.normal(log_var.shape)
std = tf.exp(log_var) # 去掉log, 得到方差;
std = std**0.5 # 开根号,得到标准差;
z = mu + std * eps
return z
3.5 主网络结构
def call(self, inputs):
mu, log_var = self.encoder(inputs)
# reparameterizaion trick:最核心的部分
z = self.reparameterize(mu, log_var)
# decoder 进行还原
x_hat = self.decoder(z)
# Variational auto-encoder除了前向传播不同之外,还有一个额外的约束;
# 这个约束使得你的mu, var更接近正太分布;所以我们把mu, log_var返回;
return x_hat, mu, log_var
3.6 模型实例化
model = VAE(z_dim,units=128)
model.build(input_shape=(128, 784))
optimizer = keras.optimizers.Adam(lr=lr)
3.7 loss函数
# 把每个像素点当成一个二分类的问题;
rec_loss = tf.losses.binary_crossentropy(x, x_hat, from_logits=True)
rec_loss = tf.reduce_mean(rec_loss)
3.8 计算KL散度
KL散度公式:
D
k
l
(
N
(
μ
,
σ
2
)
∣
∣
N
(
0
,
1
)
)
=
1
2
(
−
l
o
g
σ
2
+
μ
2
+
σ
2
−
1
)
D_{kl}(N(\mu,\sigma^2)||N(0,1))=\frac{1}{2}(-log\sigma^2+\mu^2+\sigma^2-1)
Dkl(N(μ,σ2)∣∣N(0,1))=21(−logσ2+μ2+σ2−1)
kl_div = -0.5 * (log_var + 1 -mu**2 - tf.exp(log_var))
kl_div = tf.reduce_mean(kl_div) / batchsz
loss = rec_loss + 1. * kl_div
完整代码
import os
import tensorflow as tf
from tensorflow import keras
from PIL import Image
from matplotlib import pyplot as plt
from tensorflow.keras import Sequential, layers
import numpy as np
tf.random.set_seed(2322)
np.random.seed(23422)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
# 把num张图片保存到一张
def save_images(img, name,num):
new_im = Image.new('L', (28*num, 28*num))
index = 0
for i in range(0, 28*num, 28):
for j in range(0, 28*num, 28):
im = img[index]
im = Image.fromarray(im, mode='L')
new_im.paste(im, (i, j))
index += 1
new_im.save(name)
# 定义超参数
batchsz = 256
lr = 1e-4
# 数据集加载,自编码器不需要标签因为是无监督学习
(x_train, _), (x_test, _) = keras.datasets.fashion_mnist.load_data()
x_train, x_test = x_train.astype(np.float32) / 255., x_test.astype(np.float32) / 255.
train_db = tf.data.Dataset.from_tensor_slices(x_train)
train_db = train_db.shuffle(batchsz * 5).batch(batchsz)
test_db = tf.data.Dataset.from_tensor_slices(x_test)
test_db = test_db.batch(batchsz)
# 搭建模型
z_dim = 10
class VAE(keras.Model):
def __init__(self,z_dim,units=256):
super(VAE, self).__init__()
self.z_dim = z_dim
self.units = units
# 编码网络
self.vae_encoder = layers.Dense(self.units)
# 均值网络
self.vae_mean = layers.Dense(self.z_dim) # get mean prediction
# 方差网络(均值和方差是一一对应的,所以维度相同)
self.vae_variance = layers.Dense(self.z_dim) # get variance prediction
# 解码网络
self.vae_decoder = layers.Dense(self.units)
# 输出网络
self.vae_out = layers.Dense(784)
# encoder传播的过程
def encoder(self, x):
h = tf.nn.relu(self.vae_encoder(x))
#计算均值
mu = self.vae_mean(h)
#计算方差
log_var = self.vae_variance(h)
return mu, log_var
# decoder传播的过程
def decoder(self, z):
out = tf.nn.relu(self.vae_decoder(z))
out = self.vae_out(out)
return out
def reparameterize(self, mu, log_var):
eps = tf.random.normal(log_var.shape)
std = tf.exp(log_var) # 去掉log, 得到方差;
std = std**0.5 # 开根号,得到标准差;
z = mu + std * eps
return z
def call(self, inputs):
mu, log_var = self.encoder(inputs)
# reparameterizaion trick:最核心的部分
z = self.reparameterize(mu, log_var)
# decoder 进行还原
x_hat = self.decoder(z)
# Variational auto-encoder除了前向传播不同之外,还有一个额外的约束;
# 这个约束使得你的mu, var更接近正太分布;所以我们把mu, log_var返回;
return x_hat, mu, log_var
model = VAE(z_dim,units=128)
model.build(input_shape=(128, 784))
optimizer = keras.optimizers.Adam(lr=lr)
epochs = 30
for epoch in range(epochs):
for step, x in enumerate(train_db):
x = tf.reshape(x, [-1, 784])
with tf.GradientTape() as tape:
# shape
x_hat, mu, log_var = model(x)
# 把每个像素点当成一个二分类的问题;
rec_loss = tf.losses.binary_crossentropy(x, x_hat, from_logits=True)
rec_loss = tf.reduce_mean(rec_loss)
# compute kl divergence (mu, var) ~ N(0, 1): 我们得到的均值方差和正太分布的;
# 链接参考: https://stats.stackexchange.com/questions/7440/kl-divergence-between-two-univariate-gaussians
kl_div = -0.5 * (log_var + 1 -mu**2 - tf.exp(log_var))
kl_div = tf.reduce_mean(kl_div) / batchsz
loss = rec_loss + 1. * kl_div
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 ==0:
print('\repoch: %3d, step:%4d, kl_div: %5f, rec_loss:%9f' %(epoch, step, float(kl_div), float(rec_loss)),end="")
num_pic = 9
# evaluation 1: 从正太分布直接sample;
z = tf.random.normal((batchsz, z_dim)) # 从正太分布中sample这个尺寸的
logits = model.decoder(z) # 通过这个得到decoder
x_hat = tf.sigmoid(logits)
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() * 255.
logits = x_hat.astype(np.uint8) # 标准的图片格式;
save_images(logits, 'd:\\vae_images\\sampled_epoch%d.png' %epoch,num_pic) # 直接sample出的正太分布;
# evaluation 2: 正常的传播过程;
x = next(iter(test_db))
x = tf.reshape(x, [-1, 784])
x_hat_logits, _, _ = model(x) # 前向传播返回的还有mu, log_var
x_hat = tf.sigmoid(x_hat_logits)
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() * 255.
x_hat = x_hat.astype(np.uint8) # 标准的图片格式;
# print(x_hat.shape)
save_images(x_hat, 'd:\\vae_images\\rec_epoch%d.png' %epoch,num_pic)
参考:
Tensorflow实现变分自编码器
马氏距离+协方差矩阵+KL散度的理解
Tensorflow 深度学习入门与实战 (课时139-141)














 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









