




 本文提出了一种混合GZSL框架,结合了生成模型和嵌入模型,通过对比嵌入策略利用类监督和实例监督。文章讨论了语义嵌入的局限性,并提出了一种实例级和类级对比嵌入方法来改善GZSL中的性能,通过实验展示了该方法在缓解投影域偏移问题上的有效性。
本文提出了一种混合GZSL框架,结合了生成模型和嵌入模型,通过对比嵌入策略利用类监督和实例监督。文章讨论了语义嵌入的局限性,并提出了一种实例级和类级对比嵌入方法来改善GZSL中的性能,通过实验展示了该方法在缓解投影域偏移问题上的有效性。
文章目录
Preface
生成模型与嵌入模型集成,混合GZSL方法将生成模型产生的真实样本和合成样本映射到一个嵌入空间中,在那里我们执行最终的GZSL分类。
对比嵌入(CE-GZSL)=类监督+实例监督
基于语义嵌入的方法在GZSL中表现不佳,原因在于投影域偏移问题。
基于特征生成的方法有效缓解偏移问题,然而特征生成方法在原始特征空间中产生合成的视觉特征。我们推测,原始特征空间远离语义信息,因此缺乏区分能力,对于GZSL分类是次优的。
贡献:
- 提出基于嵌入模型和基于特征生成模型的混合GZSL框架
- 提出一种对比嵌入,它可以在混合GZSL框架中利用类监督和实例监督
GZSL的对比嵌入
Problem definition
可见类:
S
:
y
s
S:y_s
S:ys
不可见类:
U
:
y
u
U:y_u
U:yu
两者不相交
N
N
N个有标签样本进行训练:
D
t
r
=
{
(
x
1
,
y
1
)
,
.
.
.
,
(
x
N
,
y
N
)
}
D_{tr}=\{(x_1,y_1),...,(x_N,y_N)\}
Dtr={(x1,y1),...,(xN,yN)},
x
i
x_i
xi表示实例
y
i
y_i
yi 表示对应的可见类标签。
包含
M
M
M个无标签样本的测试集:
D
t
e
=
{
x
N
+
1
,
.
.
.
,
x
N
+
M
}
D_{te}=\{x_{N+1},...,x_{N+M}\}
Dte={xN+1,...,xN+M}
类级语义描述: A = { a 1 , . . . , a S , a S + 1 , . . . , a S + U } A=\{a_1,...,a_S,a_{S+1},...,a_{S+U}\} A={a1,...,aS,aS+1,...,aS+U}。我们可以从标记的实例 y y y 推断出实例 x x x 的语义描述符 a a a。
Hybrid GZSL
传统ZSL的语义嵌入旨在学习一个嵌入函数
E
E
E,该函数将一个视觉特征
x
x
x 映射到表示为
E
(
x
)
E (x)
E(x) 的语义描述符空间中,常用的语义嵌入方法依赖于一个结构化损失函数。
p
(
x
,
a
)
p(x,a)
p(x,a)是可见类的真实训练样本的经验分布,
a
′
≠
a
a'\neq a
a′=a是其他类随机选择的语义描述符,
△
>
0
\triangle >0
△>0是一个边际参数,使
E
E
E 更稳健。
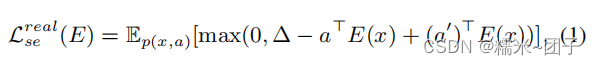
特征生成方法学习条件生成器网络
G
G
G,生成以高斯噪声
ϵ
N
(
0
,
I
)
\epsilon ~N(0,I)
ϵ N(0,I) 和语义描述符
a
a
a 为条件的样本
x
~
=
G
(
a
,
ϵ
)
\tilde{x}=G(a,\epsilon)
x~=G(a,ϵ)。
D
D
D(识别网络)与
G
G
G一起训练以区分实例
(
x
,
a
)
(x,a)
(x,a)和合成例
(
x
~
,
a
)
(\tilde{x},a)
(x~,a)。
特征发生器网络
G
G
G 和鉴别器网络
D
D
D 可以通过优化以下对抗性目标来学习
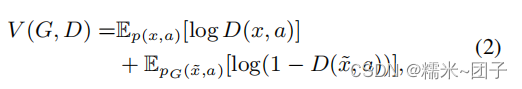
p
G
(
x
~
,
a
)
=
p
G
(
x
~
∣
a
)
p
(
a
)
p_G(\tilde{x},a)=p_G(\tilde{x}|a)p(a)
pG(x~,a)=pG(x~∣a)p(a)是合成特征和其对应的语义描述符的联合分布。
G
G
G 的损失函数可表示为:
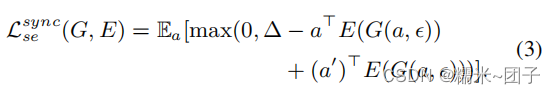
结合(1)(3),联合损失函数:
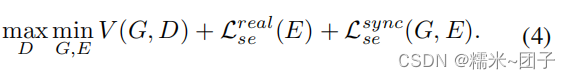
Contrastive Embedding
实例级对比嵌入
可视化样本
x
x
x 的嵌入表示为
h
=
E
(
x
)
h=E(x)
h=E(x)。对于每一个数据点
h
i
h_i
hi,建立
(
K
+
1
)
−
w
a
y
(K+1)-way
(K+1)−way 分类子问题来区分唯一的正样本
h
+
h^+
h+ 和
K
K
K 个负样本
{
h
1
−
,
.
.
.
,
h
K
−
}
\{h_1^-,...,h_K^-\}
{h1−,...,hK−}。其中,
h
+
h^+
h+ 与
h
i
h_i
hi 具备相同的类标签,
h
i
−
h_i^-
hi− 与
h
i
h_i
hi 的类标签不同。
添加一个非线性投影头
H
H
H:
z
i
=
H
(
h
i
)
=
H
(
E
(
x
i
)
)
z_i=H(h_i)=H(E(x_i))
zi=H(hi)=H(E(xi)),对
z
i
z_i
zi 进行
(
K
+
1
)
−
w
a
y
(K+1)-way
(K+1)−way 学习
h
i
h_i
hi,
(
K
+
1
)
−
w
a
y
(K+1)-way
(K+1)−way 交叉熵损失函数:
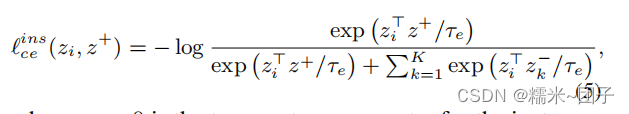
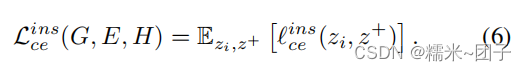
类级对比嵌入
学习了一个比较器网络
F
(
h
,
a
)
F(h,a)
F(h,a),它度量嵌入的
h
h
h 和语义描述符
a
a
a 之间的相关性得分。在
F
F
F 的帮助下,我们将嵌入空间中随机选择的点的类级对比嵌入损失作为一个
S
−
w
a
y
S-way
S−way 分类子问题。损失函数:
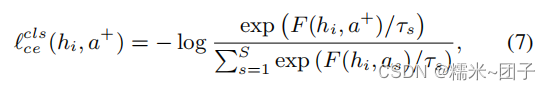
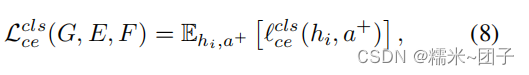
总体 Loss
(4)(6)(8):
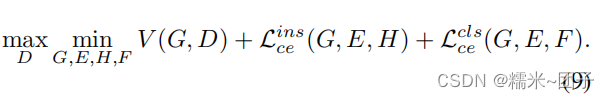
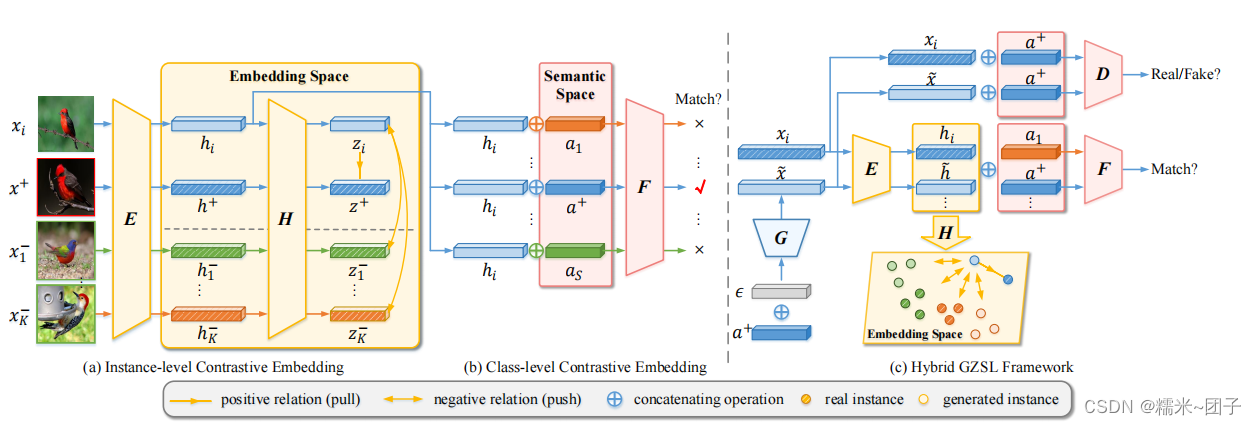
- 学习了一个嵌入函数 E E E ,它将视觉样本 x i x_i xi 映射到嵌入空间中,命名为 h i = E ( x i ) h_i=E(x_i) hi=E(xi)。
- 进一步学习了一个非线性投影 H H H 来更好地约束嵌入空间 z i = H ( h i ) z_i=H(h_i) zi=H(hi)。
- 引入了一个比较器网络 F F F,它来测量 h i h_i hi 和语义描述符 a i a_i ai之间的相关性得分。
- 通过实例级和类级的监督来学习嵌入函数。将对比嵌入模型与特征生成模型相结合。
- 在特征生成模型中,基于语义描述符 a a a 和高斯噪声 ϵ \epsilon ϵ 的特征生成器 G G G 生成视觉特征,鉴别器 D D D的目的是区分假视觉特征和真实视觉特征。
GZSL classification
- 首先通过组合特征生成器网络 G G G 和嵌入函数 E : h ~ j = E ( G ( a u , ϵ ) ) E:\tilde{h}_j=E(G(a_u,\epsilon)) E:h~j=E(G(au,ϵ))来生成嵌入空间中每个不可见类的特征,其中 u ≥ S + 1 u≥S + 1 u≥S+1, a u a_u au 是一个不可见类的语义描述符。
- 将 D t r D_{tr} Dtr中可见类的给定训练特征映射到相同的嵌入空间中: h i = E ( x i ) h_i =E(x_i) hi=E(xi)。
- 最后,我们利用嵌入空间中的真实样本和合成的看不见样本来训练softmax模型作为最终的GZSL分类器。
Experiment
F
F
F 是一个多层感知器(MLP),其中包含一个带有LeakyReLU激活的隐藏层。
F
F
F 以嵌入的
h
h
h 和语义描述符
a
a
a 的串联体作为输入,并输出它们之间的相关性估计。
生成器
G
G
G 和鉴别器
D
D
D 都包含一个4096个单元的隐藏层与LeakyReLU激活。

















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









