







摘要
二进制与源代码匹配(尤其是函数级匹配)在计算机安全领域至关重要。给定二进制代码时,定位其对应源代码可提升逆向工程的准确性与效率;给定源代码时,检索关联的二进制代码则有助于确认已知漏洞。然而,由于源代码与二进制代码之间存在显著差异,相关研究仍较为有限。已有方法通常提取代码字面量(如字符串、整数等),再结合匈牙利算法等传统匹配策略实现代码关联,但这些方法在函数级场景中存在明显局限:其忽视了代码潜在的语义特征,且多数代码缺乏充足的字面量。此外,这些方法依赖专家经验进行特征识别与特征工程,过程耗时且成本高昂。
本文提出了一种端到端跨模态检索网络(CodeCMR),用于二进制与源代码匹配,在提升精度的同时减少了对专家经验的依赖。具体实现中:
• 源代码特征提取:采用深度金字塔卷积神经网络(DPCNN);
• 二进制代码特征提取:基于图神经网络(GNN);
• 代码字面量建模:通过神经网络捕捉字符串、整数等字面量特征;
• 负采样优化:设计“范数加权采样”策略提升训练效率。
实验表明,该模型在两个数据集上均显著优于现有方法。
1 引言
二进制与源代码匹配是计算机安全领域的核心任务。现有研究多聚焦于二进制到源代码的匹配,涵盖代码克隆检测[1]、开源代码复用识别[2-4]及逆向工程[5-6]等场景;而源代码到二进制的匹配同样具有重要价值——通过已知源代码判定其对应二进制是否存在于目标文件中,可为漏洞风险预警提供关键支持。然而,由于源代码与二进制代码之间存在显著差异,相关匹配任务极具挑战性。
传统方法通常提取代码字面量(如字符串、整数、if/else分支数[2]、递归调用[5]等),再结合匈牙利算法[7]等传统匹配策略计算代码相似性。但这些方法存在两大问题:其一,仅依赖代码字面量导致精度受限,忽略了蕴含更丰富信息的潜在语义特征;其二,需依赖专家经验进行特征选择与特征工程,过程耗时且成本高昂。
本文研究聚焦于函数级代码匹配。相比已有库级任务[1-6],函数级输入的字符串与整数更稀疏,要求模型具备更高的特征提取精度。为便于理解,图1展示了一组函数级源码-二进制代码对。尽管两者包含相同字符串,但此类特征粒度粗糙(因字符串数量稀少且不同函数可能共享相同字符串);整数集合虽有一定区分性,但二进制代码中的地址偏移会破坏其等价性,且相同整数可能跨函数出现。因此,需提取更多特征以提升匹配精度。
从图1可见,源码与二进制代码间存在丰富的潜在语义关联。例如,源码中的函数调用可与二进制控制流图(CFG)左下区块匹配(图中通过颜色标注对应代码)。此类关联类似于跨模态任务(如图文描述),即不同格式数据间仍存在语义一致性。若能有效提取语义特征,匹配精度将显著提升。
基于上述观察,本文提出一种端到端跨模态检索框架,将二进制-源代码匹配建模为跨模态检索任务(模态分别为源码与二进制代码)。近年来,跨模态检索已在图文[8-9]、音图[10]、文音[11-12]等场景广泛应用,其通用框架通常包含:
• 模态专用编码器:分别提取不同模态的特征向量;
• 负采样与损失函数设计:针对任务特性优化训练过程。例如,食谱-图像任务[8]采用分层LSTM[13]与ResNet[14]提取特征,并结合对抗损失、三元组损失与难样本挖掘提升性能。
本文框架具体实现如下:
• 源码特征提取:采用深度金字塔卷积神经网络(DPCNN)[15],可直接处理字符级源码序列,相比基于抽象语法树(AST)的方法更高效鲁棒;
• 二进制特征提取:设计图神经网络(GNN)模型,通过端到端HBMP模型[17]生成节点嵌入,再结合GGNN[32]与Set2Set[33]计算二进制语义嵌入;
• 字面量建模:构建LSTM模型提取整数特征,分层LSTM模型提取字符串特征;
• 训练优化:提出“范数加权采样”策略,加速训练并提升精度。
本文贡献如下:
- 任务定义:首次将函数级二进制-源码匹配问题归类为跨模态检索任务,并提出系统性解决方案;
- 模型创新:
• 源码侧:字符级DPCNN模型避免AST解析开销,兼顾效率与性能;
• 二进制侧:端到端GNN模型替代预训练方法,提升精度与效率; - 特征增强:设计字面量(字符串/整数)提取模型,并创新负采样策略;
- 实验验证:在两组数据集上验证模型优越性,其中10,000样本数据集上Recall@1/Recall@10达90.2%/98.3%,满足实际应用需求。
2 相关工作
2.1 二进制与源代码匹配
二进制与源代码匹配是计算机安全领域的关键任务。现有研究多聚焦于二进制到源代码的匹配,通过提取源码与二进制代码的字面量实现关联。例如:
• BinPro[5]:提取匹配特征与预测特征,结合匈牙利算法实现代码匹配;
• B2SFinder[2]:利用七类可追踪特征,设计加权特征匹配算法;
• RESource[3]:借鉴Re-Google思想,基于开发者社区仓库的字符串字面量与触发式查询进行匹配;
• Binary Analysis Tool (BAT)[1]:通过解包扫描与叶节点扫描提取信息,提出数据压缩方法计算相似度得分;
• OSSPolice[4]:以字符串字面量与导出函数为特征,通过软件相似性比对检测开源代码复用;
• Codebin[6]:定义控制流图(CFG)复杂度计算方法,并从函数调用与CFG中提取特征。
与上述库级匹配方法不同,本文专注于函数级匹配。由于函数规模远小于库,二进制与源码中的字面量(如字符串、整数)显著减少,且无法依赖函数调用链或符号表。因此,需设计更细粒度的特征提取方法与更精准的匹配模型。
2.2 代码表示学习
代码表示学习是支撑匹配任务的基础研究,主要分为两类:
• 源代码表示:
• SourcererCC[18]:以词法标记序列为输入特征;
• ASTNN[19]:将抽象语法树(AST)拆分为语句子树,编码为向量后通过双向RNN生成表示。
• 二进制代码表示:
• 传统方法依赖图匹配算法[20];
• Gemini[21]:提出基于图神经网络(GNN)的二进制嵌入方法;
• Yu等人(2020):采用BERT预训练[42]从节点嵌入中学习语义特征;
• Zuo等人(2018):提出神经机器翻译方法建模语义关系。
2.3 跨模态检索
跨模态检索旨在从不同模态数据中关联相关实例[8]。通用方法包括:
- 模态专用编码器:将跨模态输入映射为嵌入向量;
- 损失函数设计:通过相似性学习与损失优化实现关联。
核心挑战在于构建跨模态的公共语义空间[23]。现有研究主要分为三类:
• 度量学习:通过距离度量学习跨模态相似性[24-25];
• 对抗训练:利用对抗网络关联跨模态嵌入[8-9,26-28];
• 相关性分析:
• CCA[29]:采用典型相关性分析建模图文相似性;
• DCCA[30]:通过深度网络学习非线性变换,增强模态间线性关联。
此外,对齐策略(如局部对齐[31]与全局对齐[30])也被广泛用于优化跨模态映射。
3 方法设计
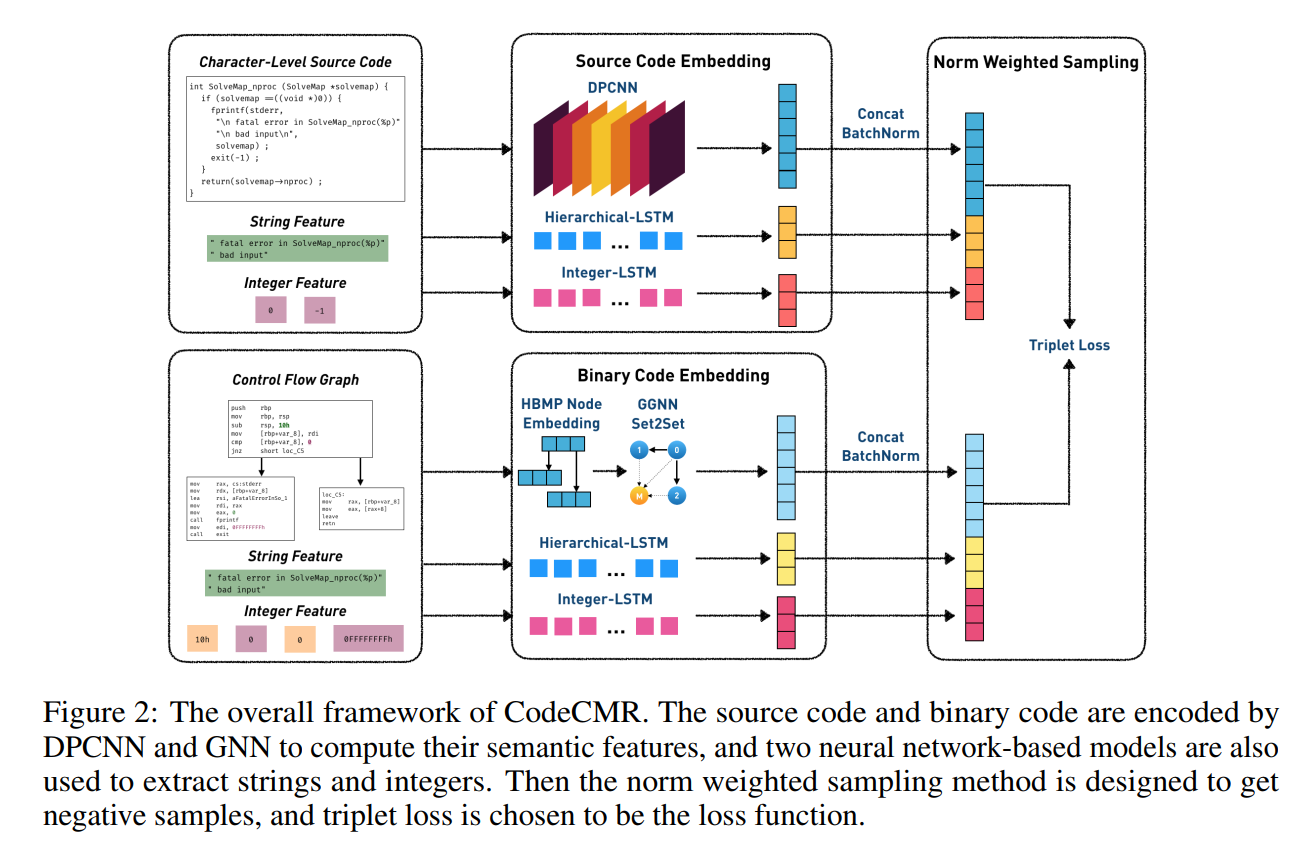
3.1 总体框架
图2展示了本文方法的整体框架。源码与二进制代码均包含三类输入:语义输入(字符级源码/控制流图)、字符串输入与整数输入。各输入通过独立编码器处理:
• 源码语义编码:采用深度金字塔卷积神经网络(DPCNN)[15]结合全局平均池化提取特征;
• 二进制语义编码:基于图神经网络(GNN)设计,通过HBMP节点嵌入生成初始表示,结合GGNN[32]消息传递与Set2Set[33]图池化计算图嵌入;
• 字面量编码:分别构建神经网络模型提取字符串与整数特征。
三类特征经拼接(Concatenate)与批量归一化(Batch Normalization)[34]对齐后,通过范数加权采样策略优化负样本选择概率,最终利用三元组损失(Triplet Loss)[35]约束正负样本距离:
目标:确保锚点(源码/二进制)与正样本(对应二进制/源码)的距离 ( D(A, P) ) 小于其与负样本 ( D(A, N) ),且通过间隔(Margin)分离正负对。
Loss = max ( D ( A , P ) − D ( A , N ) + margin , 0 ) (1) \text{Loss} = \max(D(A, P) - D(A, N) + \text{margin}, 0) \tag{1} Loss=max(D(A,P)−D(A,N)+margin,0)(1)
该框架具备高度扩展性:
- 预训练增强:可将提取的特征作为预训练权重,支持代码克隆检测等下游任务;
- 多任务扩展:添加对抗损失(Adversarial Loss)可增强跨模态嵌入对齐,或用于二进制到源码的生成式任务;
- 生成式应用:代码表示可作为生成模型(如代码反编译)的初始嵌入。
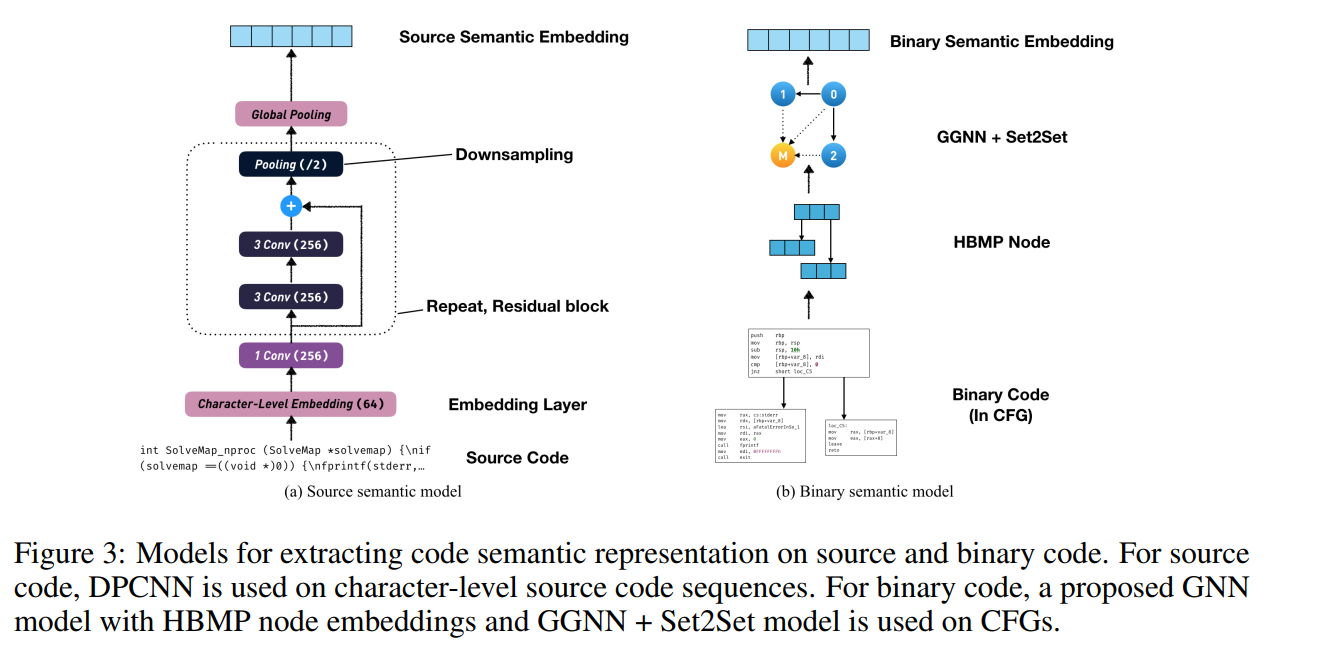
3.2 代码语义特征提取
代码语义表示提取模型架构如图3所示。**图3(左)**为源码的DPCNN模型结构,具体流程如下:
- 预处理与嵌入:
• 源码被预处理为字符级长序列,输入嵌入层生成字符嵌入向量;
• 嵌入层权重通过训练学习,关键改进包括:
◦ 用kernel size=1的卷积层替代区域嵌入(Region Embedding)[36],统一嵌入层与残差层的维度;
◦ 参考ALBERT[37],将嵌入层维度设为小于残差层,以减少参数量。 - 特征提取:
• 嵌入向量输入多个重复的DPCNN模块;
• 每个模块含两个残差卷积层与一个下采样池化层(末层除外);
• 卷积层共享特征维度,提升存储与计算效率[15]。 - 全局表征:
• 最终通过全局平均池化生成语义表示。
**图3(右)**展示二进制代码的语义特征提取流程:
- 节点嵌入生成:
• 控制流图(CFG)节点转换为令牌嵌入向量;
• HBMP模型[17]:通过三层LSTM生成块级表示(各层初始隐态继承前层输出)。 - 图结构建模:
• GGNN[32]:迭代传递相邻节点消息,建模图结构依赖;
• Set2Set[33]:基于集合的顺序无关图池化,生成最终CFG表示。
• 关键特性:Set2Set与DPCNN的全局平均池化均保持顺序无关性,确保节点/字符顺序变化不影响结果。
模型选择依据:
• 本文选用**DPCNN(源码)与HBMP+GGNN+Set2Set(二进制)**组合,因其无需额外解析开销且鲁棒性强。
• 例如,若采用ASTNN[19]处理源码,需将代码解析为抽象语法树(AST),但实验表明:
• 解析耗时:AST解析过程显著增加时间成本;
• 解析失败率:使用gcc解析方法[19]时,仅10%的代码可成功解析;
• 专家依赖:即使更换解析工具,仍需大量专家经验调试,实际应用受限。
3.3 代码字面量特征
除语义特征外,代码字面量(如整数)亦可提供有效信息。如图1所示,源码与二进制代码中的整数虽存在相似性,但由于二进制中可能包含地址偏移等额外数值,二者并不完全一致。此外,以下场景需额外考虑:
• 整数语义变换:例如源码中的 i <= 5 可能被编译为 i < 6,x * 16 可能优化为 x << 4;
• 平台差异:整数在不同平台(如32位/64位)上可能发生位宽扩展或截断。
为此,本文提出基于LSTM的整数特征模型(integer-LSTM),其设计要点如下:
-
输入特征:
• 整数词元(Token):通过嵌入层生成向量表示;
• 整数值(Number):作用于输入门与输出门,控制信息流动。 -
模型结构:
• 门控机制:整数值经对数变换后参与门控计算(公式2-6),若当前整数对预测无贡献,模型可将输入门或输出门置零;
• 特征融合:将词元嵌入与对数整数值拼接为联合输入,增强模型信息量;
• 池化层:对所有隐状态进行平均池化,保留输出门的信息贡献。
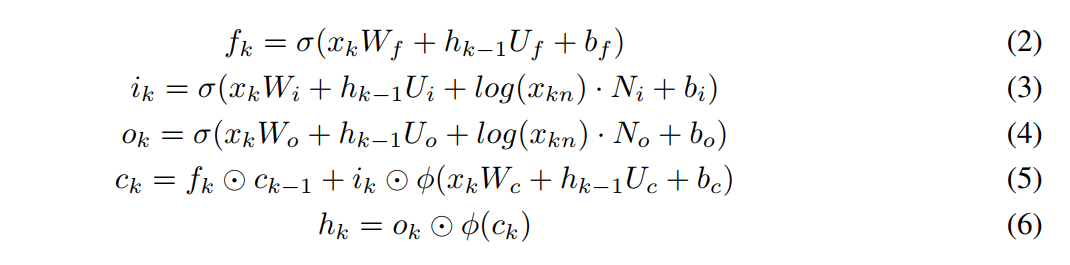
3.4 字符串特征建模
对于字符串特征,本文设计了一种分层LSTM模型。尽管源码与二进制代码中的字符串集合通常一致(如图1中均包含 "fatal error in SolveMap_nproc(%p)" 与 "bad input"),但传统模型仅能生成相同的集合嵌入,而本模型通过以下机制实现细粒度相似性度量:
-
字符串级嵌入:
• 每个字符串通过独立的LSTM模型转换为嵌入向量;
• 例如,图1中的两个字符串分别生成嵌入 ( e_1 ) 和 ( e_2 )。 -
集合级聚合:
• 对字符串嵌入进行求和池化(Sum Pooling),生成集合级嵌入:
[
E_{\text{set}} = e_1 + e_2
]
• 优势:相似字符串(如语义相近但词序不同的变体)在嵌入空间中距离更近,从而提升匹配精度。
模型价值:
• 语义敏感性:即使字符串集合相同,本模型可为语义相似的字符串对分配更高相似度得分;
• 抗噪声能力:避免因字符串微小差异(如拼写错误、格式调整)导致误判。
3.4 范数加权采样
在融合源码与二进制代码的三类特征嵌入后,通过拼接(Concatenate)与批量归一化(Batch Normalization)生成对齐嵌入。为约束正样本相似度高于负样本,本文采用三元组损失(Triplet Loss)。然而,三元组损失存在负采样难题:不同负样本会导致训练效果显著差异[35]。Schroff等人(2015)指出硬样本(Hard Examples)易导致早期训练陷入局部最优,故提出半硬采样(Semi-Hard Sampling),但该方法可能陷入收敛停滞[38]。Wu等人(2017)提出距离加权采样(Distance Weighted Sampling),其公式为:
[
w_{\text{log}k} = -(n-2)d_k - \frac{n-3}{2}\left(1 - \frac{1}{4}d_k^2\right) \tag{7}
]
[
[w_1; w_2; \dots; w_i] = \text{softmax}([w{\text{log}1}; w{\text{log}2}; \dots; w{\text{log}_i}]) \tag{8}
]
其中 ( n ) 为嵌入维度,( d_k ) 为第 ( k ) 个样本的距离。该策略通过距离权重分配采样概率 ( w_k ),相比均匀采样、硬采样等方法,能从更广范围选择负样本[38]。
本文提出范数加权采样(Norm Weighted Sampling),在距离加权采样基础上引入缩放因子 ( s ) 调控概率分布:
[
[w_1; w_2; \dots; w_i] = \text{softmax}([w_{\text{log}1} \cdot s; w{\text{log}2} \cdot s; \dots; w{\text{log}_i} \cdot s]) \tag{9}
]
其思想与NormFace[39]相似:通过归一化后添加缩放因子可调整softmax分数,加速收敛。例如,给定式(7)计算结果序列 ([-0.74, -1.00, -0.95, -0.40, 0.00]),不同 ( s ) 值的采样概率对比如下:
• ( s = 1 )(等同距离加权采样):([0.16, 0.12, 0.13, 0.23, 0.36])
• ( s = 2 ):([0.12, 0.07, 0.08, 0.23, 0.50])
• ( s = 0.5 ):([0.18, 0.16, 0.17, 0.22, 0.27])
可见,( s ) 可缩放最大概率值的幅度(如 ( s = 2 ) 时最高概率从0.36增至0.50),同时保持概率排序不变。实际应用中,可通过调整 ( s ) 适配不同任务与数据集需求,其作用类似于负温度参数(Beta)。
4 实验评估
4.1 数据集与实现细节
本文在二进制-源代码匹配任务上评估模型性能。源码通过不同编译器(gcc/clang)、平台(x64/ARM)与优化选项(O0/O3)编译为控制流图(CFG),构建以下两类数据集:
• gcc-x64-O0:训练集30,000对,验证集与测试集各10,000对;
• clang-arm-O3:训练集30,000对,验证集与测试集各10,000对。
二进制代码特征通过IDA Pro工具提取,评估指标为Recall@1与Recall@10(即正确匹配对在10,000个测试对中的相似度排名为Top1/Top10)。数据集详情参见:https://github.com/binaryai。
训练参数:
• 通用设置:学习率0.001,批次大小32,三元组间隔(Margin)0.5,优化器Adam;
• 源码处理:字符序列长度4,096,嵌入层维度64,卷积层维度128,残差块重复次数7;
• 二进制处理:节点嵌入与图嵌入维度均为128,GGNN消息传递与Set2Set迭代次数均为5;
• 字面量建模:字符串与整数的嵌入层及LSTM隐层维度均为64。
4.2 对比方法
-
传统方法:
• BinPro[5] 与 B2SFinder[2]:基于多特征提取与匈牙利算法[7]计算匹配得分。 -
源码语义特征对比:
• DPCNN(本文):字符级源码特征提取;
• LSTM 与 TextCNN[41]:自然语言处理常用方法。 -
二进制语义特征对比:
• 端到端模型(本文):训练时动态生成块嵌入;
• 预训练方法:BERT[42]、Word2vec[43];
• 手工特征[21]:基于人工设计特征。 -
代码字面量对比:
• integer-LSTM(本文):融合整数值与词元特征;
• 传统LSTM:仅输入整数词元;
• 匈牙利算法:基于字符串与整数的传统匹配。 -
负采样策略对比:
• 范数加权采样(本文):引入缩放因子 ( s );
• 距离加权采样[38] 与 随机采样。
4.3 实验结果
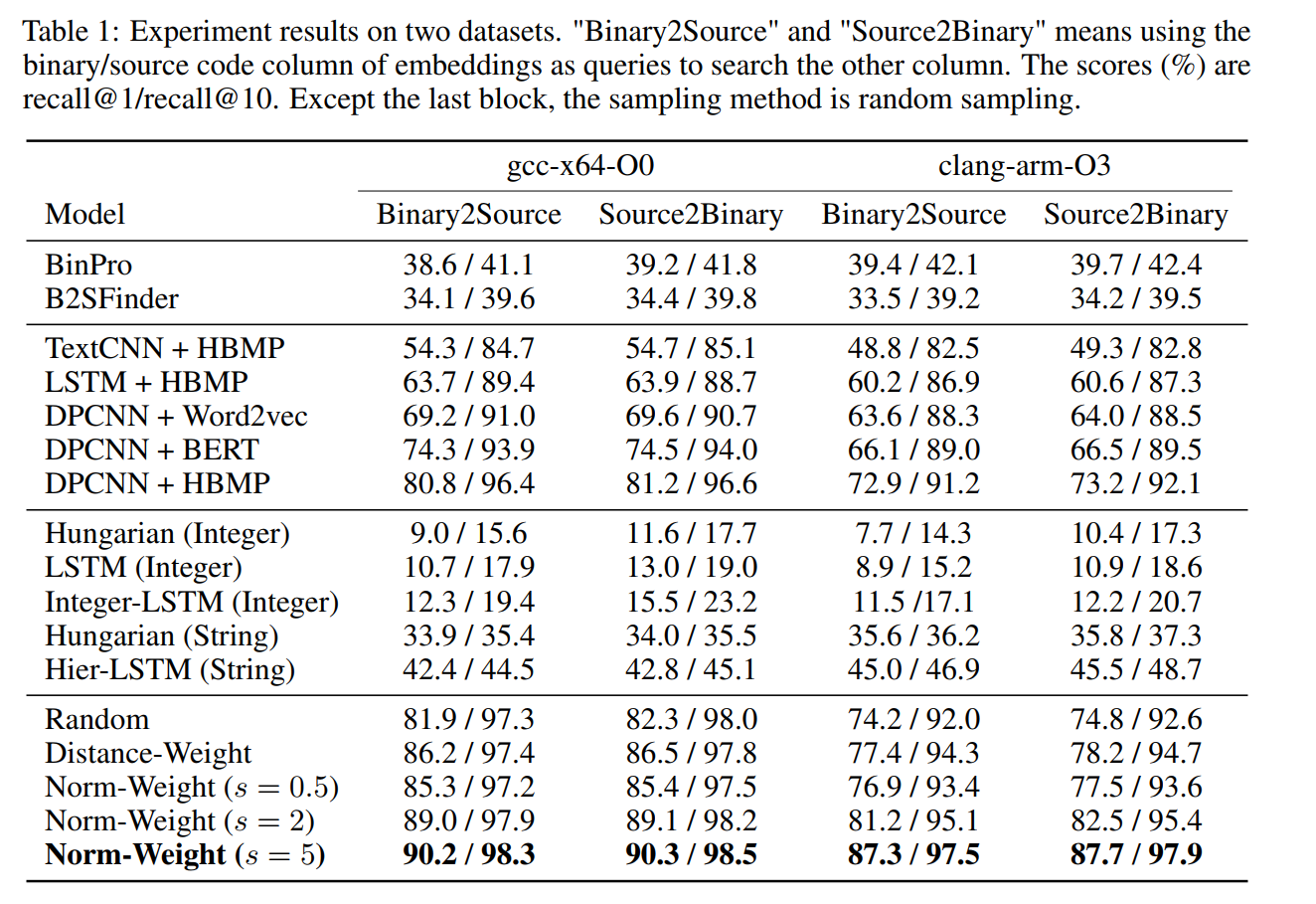
表1展示了各模型性能对比:
• 传统方法(BinPro、B2SFinder等)Recall@1仅为38.6%;
• 纯语义特征模型显著优于纯字面量模型,证明源码与二进制间的潜在语义特征是匹配关键;
• 本文模型(DPCNN+HBMP+字面量模型+范数加权采样)Recall@1/Recall@10达90.2%/98.3%,较传统方法提升显著。
核心结论:
- 语义特征对函数级代码匹配的贡献远超字面量特征;
- 端到端模型(无需预训练或手工特征)在精度与效率上均优于现有方法;
- 范数加权采样通过调节 ( s ) 值优化负样本分布,进一步提升模型性能。
核心结论分析:
-
代码语义模型性能:
• DPCNN+HBMP组合模型在代码语义特征提取中表现最优,表明端到端深度模型(DPCNN对比TextCNN/LSTM,HBMP对比BERT/Word2Vec)具备更强的信息提取能力。 -
代码字面量模型价值:
• integer-LSTM模型因融合整数值特征,性能优于传统LSTM;
• 深度学习方法在字面量特征提取上显著超越传统方法(如匈牙利算法)。 -
范数加权采样效果:
• s=5时最优:Recall@1较随机采样提升约8%,验证损失更低且召回率更高;
• s值影响:增大s(如s=5)通过筛选更有效的三元组提升训练效果,但过大(s=8/10)会导致性能轻微下降;
• 训练曲线洞察:
◦ 随机采样因选择低效三元组导致训练损失虚低但验证损失高;
◦ 范数加权采样(尤其大s值)因选择高效三元组,训练损失真实反映模型优化方向,验证性能更优。
实验启示:
• 模型设计:端到端架构+细粒度特征提取是提升二进制-源码匹配的关键;
• 负采样策略:动态调节s值可适配不同任务需求,平衡训练效率与精度。
5 讨论
如第3.1节所述,本文提出的框架具备高度可扩展性。实践中,我们尝试了以下改进方法并取得良好效果:
5.1 代码编码器扩展
• 源码编码器:ASTNN[19]、Tree-LSTM[47]等基于抽象语法树(AST)的模型可替代DPCNN,但需额外解析开销;
• 二进制编码器:除图神经网络(GNN)外,Transformer[48]等NLP模型亦值得探索;
• 字面量编码器:其他基于RNN的模型[49-50]可适配不同场景。
本文选用字符级DPCNN的关键优势在于其鲁棒性——无需依赖专家经验设计源码解析器。
5.2 损失函数与采样策略优化
• 损失函数:AM-softmax[51]、Arcface[52]、Multi-similarity损失[53]、Circle损失[44]等度量学习方法可进一步提升性能;
• 采样策略:跨批次记忆(Cross-batch memory)[45]能有效利用历史样本信息。
5.3 对抗学习与跨模态方法
• 对抗训练:引入WGAN-GP[54]通过极小极大优化关联跨模态嵌入,但需精细调参;
• 跨模态检索方法:现有技术[55-56]可适配本任务,但需权衡模型复杂度与收益。
5.4 预训练方法探索
• 单模态预训练:BERT[42]等NLP预训练方法因静态嵌入限制,表现不及端到端训练;
• 跨语言预训练:跨语言模型[46]可融合跨模态信息,但需权衡计算成本与精度提升。
6 结论
本文针对函数级二进制-源代码匹配任务提出一种端到端跨模态检索框架,核心贡献包括:
- 任务定义:首次将函数级匹配问题建模为跨模态检索任务;
- 模型设计:
• 源码侧:字符级DPCNN避免AST解析开销;
• 二进制侧:端到端GNN模型替代预训练方法;
• 字面量侧:提出integer-LSTM与分层LSTM模型; - 训练优化:范数加权采样策略显著提升性能。
实验表明,模型在两组数据集上Recall@1/Recall@10达90.2%/98.3%,较传统方法提升显著,满足实际应用需求。
更广泛影响
• 积极影响:助力安全研究人员快速定位漏洞特征(如通过源码-二进制关联实现漏洞签名检索与逆向工程支持);
• 潜在风险:恶意攻击者可能滥用该技术实施定向攻击。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









