






今天介绍的是一篇来自CMU的 针对多任务自检查微调大模型来检测安全漏洞 的一篇文章

摘要
软件安全漏洞使攻击者能够通过恶意行为破坏软件运行。近年来,基于Transformer的语言模型显著推动了漏洞检测技术的发展,其性能已超越基于静态分析的深度学习模型。然而,仅基于代码标记(code tokens)训练的语言模型既无法捕捉漏洞类型的解释信息,也无法获取代码的数据流结构信息,而这两者对漏洞检测都至关重要。为此,我们提出一种创新方法:通过将多任务序列到序列的大型语言模型(LLM)与基于图神经网络(GNN)编码的程序控制流图(Control Flow Graph)相结合,实现序列到分类的漏洞检测。受思维链提示(chain-of-thought prompting)和LLM自我指导(self-instruction)的启发,我们提出了MSIVD(多任务自指导漏洞检测微调)方法。实验表明,MSIVD在BigVul数据集上的F1分数达到0.92,在PreciseBugs数据集上达到0.48,性能优于当前最优的LLM漏洞检测基线模型(LineVul)。通过联合训练LLM与GNN,并结合漏洞代码及其解释性指标,MSIVD为提升基于LLM的漏洞检测泛化能力提供了新方向。基于实验结果,我们进一步指出:由于当前LLM可能已接触或记忆了既有数据集的评估样本,构建新型标注安全漏洞数据集势在必行。
1 引言
软件安全漏洞使攻击者能够破坏程序并引发异常行为,例如泄露敏感用户信息或实施数据勒索。由软件漏洞引发的普遍性威胁已对个人和企业造成深远影响[1]。
这一现状推动了自动化漏洞检测技术的长期研究。近期研究通过整合静态分析信息(如基于程序抽象语法树提取的特征[2]、数据流分析[3]或数据依赖分析[4,5])训练深度学习模型进行漏洞检测。引入此类程序上下文信息可提升漏洞检测准确率[3,5,6]。然而,基于静态分析的深度学习模型虽实现了较高精度,却以可扩展性为代价——受限于可处理的程序/代码块规模及时间开销。例如,IVDetect[6]需长达9天的训练时间。此外,现有漏洞检测训练数据集的规模较小,也必然制约模型性能。
大型语言模型(LLM)的最新进展显著降低了漏洞检测模型的训练时间与数据需求。LineVul[7]通过利用代码预训练LLM的语义先验知识,以远低于IVDetect的训练时间(仅需数小时)实现了最先进的漏洞检测效能。事实上,基于LLM的漏洞检测工具[7,8]推动了LLM与静态分析技术的融合,这类方法在现有文献中报告了最高的漏洞检测率[3]。然而,其效能仍受限于LLM对**代码标记(code tokens)**的依赖性。尽管代码预训练LLM的最新进展增强了对代码语义的理解能力[9],但当代码标记数量超出模型上下文窗口大小时[10],LLM仍难以检测大规模代码库中的漏洞。将大型程序切割为小型代码片段虽可缓解此问题[7,10],但会因丢弃数据而进一步损失本已有限的标注数据。
在数据需求旺盛的机器学习场景中,本就有限的标注数据集进一步丢失信息会带来严峻挑战。此外,我们发现现有漏洞数据集[11,12]中往往包含未被充分挖掘的宝贵信息,例如漏洞原理解释、精准定位信息及修复建议等。这些信息不仅揭示了漏洞存在的根本原因,还指明了潜在的攻击路径。尽管这些数据集按机器学习标准仍属小规模,但其信息丰富性远超仅包含漏洞代码修改的常规数据。
本文提出一种多任务自指导大型语言模型(LLM),通过融合数据流驱动的图神经网络(GNN)实现多维度漏洞信息学习。多任务学习使模型能够同步获取共享知识与模式,通常可提升泛化能力与检测精度[13]。我们的方法基于两大洞见:(1) 联合微调代码与漏洞解释信息相较于单一代码微调更有利于性能提升;(2) 多数安全漏洞涉及特定且微妙的信息流特征,但仅通过代码或文本解释训练语言模型难以捕捉潜在漏洞程序中数值与数据传播的关键关联,因此程序图结构表征至关重要。
受思维链推理(chain-of-thought)与自指导(self-instruct)方法启发[14,15],我们将标注漏洞数据转换为多轮对话格式用于微调自指导多任务模型。为进一步整合程序分析信息,我们在微调后的LLM基础上添加轻量级图神经网络(GNN)层,以控制流图(CFG)嵌入编码程序结构。首先在经典数据集BigVul上验证模型,实证表明我们的方法在F1分数上超越现有最优LLM基线(LineVul)0.17,优于静态分析深度学习模型。
然而,实验同时揭示现代LLM在传统漏洞数据集上存在显著的评估数据泄露问题。为此,我们基于PreciseBugsCollector[12]构建新型漏洞数据集,通过严格筛选确保评估集仅包含预训练LLM知识截止日期(2023年1月)后发布的代码及其标注漏洞,并在第5章探讨LLM评估数据污染的潜在影响。
本文的核心贡献如下:
• 多任务自指导安全漏洞检测微调方法:提出融合漏洞检测、解释与修复的多任务训练框架,结合GNN漏洞适配器实现最优检测效能。
• 新型数据集:利用PreciseBugsCollector[12]构建标注漏洞数据集并转换为自指导对话格式,通过时间过滤规避LLM数据污染风险。
• 实证评估:在BigVul与PreciseBugs数据集上验证MSIVD的优越性,证明微调阶段的多轮自指导对模型效果至关重要。
• 工具开源:完整数据集、工具与模型检查点已开源。¹
在数据需求旺盛的机器学习场景中,本就有限的标注数据集进一步丢失信息会带来严峻挑战。此外,我们发现现有漏洞数据集[11,12]中往往包含未被充分挖掘的宝贵信息(如漏洞原理解释、精准定位信息及修复建议等)。重要的是,这些信息不仅揭示了漏洞存在的根本原因,还指明了潜在的攻击路径。尽管这些数据集按机器学习标准仍属小规模,但其信息丰富性远超仅包含漏洞代码修改的常规数据。
本文提出一种多任务自指导大型语言模型(LLM),通过融合数据流驱动的图神经网络(GNN)实现多维度漏洞信息学习。多任务学习使模型能够同步获取共享知识与模式,通常可提升泛化能力与检测精度[13]。我们的方法基于两大洞见:
- 联合微调代码与漏洞解释信息相较于单一代码微调更有利于性能提升;
- 多数安全漏洞涉及特定且微妙的信息流特征,但仅通过代码或文本解释训练语言模型难以捕捉潜在漏洞程序中数值与数据传播的关键关联,因此程序图结构表征至关重要。
受思维链推理(chain-of-thought)与自指导(self-instruct)方法启发[14,15],我们将标注漏洞数据转换为多轮对话格式用于微调自指导多任务模型。为进一步整合程序分析信息,我们在微调后的LLM基础上添加轻量级图神经网络(GNN)层,以控制流图(CFG)嵌入编码程序结构。首先在经典数据集BigVul上验证模型,实证表明我们的方法在F1分数上超越现有最优LLM基线(LineVul)0.17,优于静态分析深度学习模型。
2 示例解析

图1通过示例阐释本文方法的核心洞见²。该代码片段提取自开源项目MeterSphere⁴中的CWE-770漏洞³。CWE-770漏洞指程序未对资源(包括资源数量或使用时长)进行充分限制的情形。若缺乏配额管理、资源限制或其他防护机制,攻击者可通过高频请求耗尽资源,导致性能下降或拒绝服务(DoS)。
图1a展示了检查密码的checkPassword方法,其功能是验证用户提供的用户名与密码字符串是否有效。从表面看,代码能对非法输入正确抛出异常,看似具备适当的安全检查。但图1b的CVE漏洞描述指出:恶意用户提交超长密码可耗尽服务器CPU与内存资源,引发DoS攻击。
该漏洞的识别在解释性信息的辅助下显著简化。标注数据集中提供的CWE类型、严重性等级与攻击复杂度等信息,使得即使非专业读者也能结合漏洞原理解释快速定位问题。
我们假设,经过代码预训练的大型语言模型(LLM)能够从漏洞代码片段关联的解释性信息中获益。 如图1所示(案例来自PreciseBugs[12]),这类包含丰富上下文信息的样本需通过人工标注漏洞数据集或复杂数据清洗获取,导致可用于微调的标注数据规模受限。传统方法中,基于小规模标注数据对参数量超70亿的大型语言模型进行指令微调并不可行[16],更优策略是直接提取预训练LLM的注意力状态(即模型对输入元素的上下文编码信息),再通过非注意力机制训练实现漏洞检测[3,7,10]。
近期LLM微调技术的突破(如轻量化参数高效微调[17]、量化适配器层微调[10,18])使得小数据场景下的训练成为可能[19]。 我们认为,结合LLM微调前沿技术与漏洞解释性数据增强,可系统性提升语言模型对漏洞机理的全局理解。
代码规模与上下文窗口的挑战
示例中,checkPassword方法(350行)由loginLocalMode方法(90行)调用,90-375行代码共含5179个词元(token),远超主流开源LLM的2048或4096词元上下文窗口限制。若loginLocalMode或checkPassword在其他代码段中被复用,相关数据流信息的上下文窗口将进一步扩大。
解决方案:数据流分析与GNN建模
此类跨上下文信息流可通过程序控制流图(CFG)的数据流分析提取,并借助图神经网络(GNN,参考DeepDFA[3])建模。我们在漏洞检测训练中,同步微调GNN与LLM适配器权重,实现代码语义与数据流特征的双重学习。
3 方法框架
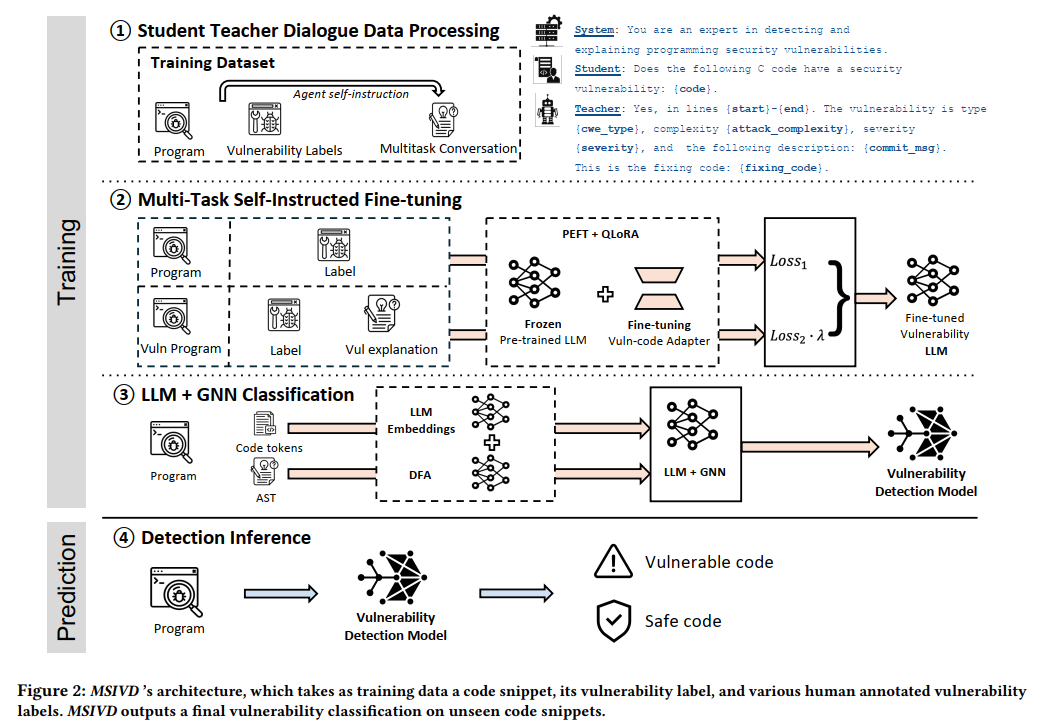
图2展示了MSIVD的四阶段实现流程,前三阶段为训练过程:
○1 自指导对话式数据处理
从标注数据集中提取漏洞类型、描述、代码位置等特征,构建适用于微调的多任务对话数据集(详见3.1节)。
○2 多任务微调
采用多任务学习策略微调LLM,核心学习目标为:
- 漏洞检测:识别代码中是否存在安全漏洞
- 漏洞解释:生成描述漏洞特征的自然语言解释(详见3.2节)
○3 LLM+GNN联合训练
基于程序控制流图(CFG)提取信息流数据,联合训练LLM与图神经网络(GNN)(详见3.3节)
○4 漏洞检测阶段
将待检测程序输入训练完成的MSIVD模型,预测其是否包含漏洞(详见3.4节)
3.1 师生对话数据处理
模型训练数据包含代码片段、漏洞标签、CWE类型、漏洞描述(如攻击者如何利用漏洞)及修复代码位置。受思维链推理(chain-of-thought)启发[14],我们将漏洞代码与标注信息转化为师生多轮对话格式。插入中间推理步骤可增强LLM复杂逻辑推理能力[14]。
对话结构设计
• 系统指令:声明教师角色为“安全漏洞检测与解释专家”
• 多轮问答:基于Self-Instruct[15]与Dialogue-policy-planned[20]方法构建师生思维链
• 单样本格式:每段完整对话构成一条训练数据
对话内容示例
如图3所示,师生围绕目标代码漏洞展开三轮对话:
- 第一轮:讨论漏洞存在性(如“代码是否存在缓冲区溢出风险?”)
- 第二轮:解释漏洞成因(如“第XX行未验证输入长度导致堆溢出”)
- 第三轮:定位修复行(如“需在第YY行添加长度校验逻辑”)
图1展示了对话中插入的code_snippet(代码片段)、cve_type(漏洞类型)、complexity(攻击复杂度)等变量(详见第2章案例)。
非漏洞样本构建
从数据集中采样开发者修复后的代码,关联负样本标签,并构建单轮对话(教师声明“该代码无安全漏洞”)。
3.2 多任务自指导微调
我们基于MFTCoder[21]的方法,通过多任务训练同步利用自指导对话数据集实现多目标优化。具体流程如下:
多轮对话代理机制
• 部署双代理架构:教师代理(生成漏洞解释)与学生代理(提出问题)
• 如图3所示,首轮对话聚焦代码漏洞存在性判定。训练过程中,LLM持续生成教师代理响应,并与标注答案对比计算损失
参数高效微调技术
采用4-bit量化低秩自适应(QLoRA)[18]提升微调效率,其核心技术包括:
- NF4高精度量化:将预训练模型权重压缩至4-bit
- 轻量适配器训练:基于低秩自适应(LoRA)[22]更新少量适配器参数
- 矩阵秩分解:如图4所示,向Transformer各层插入可训练低秩矩阵(秩𝑟 ≪ 原始维度𝑑)
LoRA前向传播公式
设原始权重矩阵为𝑊₀ ∈ ℝ^{𝑑×𝑑},LoRA修改前向过程为:
𝑊₀ + Δ𝑊 = 𝑊₀ + 𝐵𝐴 (其中𝐴 ∈ ℝ^{𝑟×𝑑}, 𝐵 ∈ ℝ^{𝑑×𝑟})
初始化时,𝐴采用高斯分布,𝐵初始化为零矩阵,故Δ𝑊 = 𝐵𝐴初始值为零
多任务加权损失函数
采用MFCoder[21]提出的加权损失计算策略:
L(𝜃) = min_𝜃 (1/𝑁) ∑_{𝑖=1}^𝑁 [ (∑_{𝑗=1}^{𝑀𝑖} ∑_{𝑘=1}^{𝑇𝑖𝑗} -log(𝑝_𝜃(𝑡_{𝑖𝑗𝑘})) ) / (∑_{𝑗=1}^{𝑀𝑖} 𝑇𝑖𝑗) ) ]
其中:
• 𝑁:任务总数
• 𝑀𝑖:第𝑖个任务的样本数
• 𝑇𝑖𝑗:第𝑖任务第𝑗样本的有效词元数
• 𝑡_{𝑖𝑗𝑘}:第𝑖任务第𝑗样本的第𝑘个词元
该公式对𝑁个任务的损失进行平均加权,确保多任务收敛稳定性
3.4 检测推理
对于待检测程序,MSIVD调用训练完成的漏洞检测模型预测代码片段是否存在安全风险(vulnerable/safe)。由于模型已通过对话格式的指令微调学习漏洞解释能力,其可进一步输出漏洞的CWE类型及成因说明。本文重点评估漏洞检测准确率,其解释质量评估将留待后续研究。
4 实验设置
本章阐述实验设置,包括数据集(4.1节)、指标与基线模型(4.2节)及模型配置(4.3节)。
4.1 数据集
4.1.1 经典漏洞数据集
现有漏洞检测模型[3,6,7,25]多基于Devign[2]或BigVul[11]数据集评估。二者均包含真实C/C++项目漏洞,但BigVul提供代码片段(单函数形式)、漏洞标签及CWE解释,而Devign仅含代码与标签。此外,BigVul规模更大(169,772条 vs Devign的14,653条),但存在标签不平衡问题(94%非漏洞标签,6%漏洞标签)。
数据集预处理
遵循LineVul[7]与DeepDFA[3]方法,从BigVul中排除1,564条样本(占比0.8%),包括:
- 不完整函数(如以
);结尾或缺少}) - 未修改代码的误标漏洞
- 修复行超70%的代码(本质性变更导致漏洞特征失效)
- 少于5行的函数
数据划分
按8:1:1划分训练集、验证集与测试集。
4.1.2 新型漏洞数据集
BigVul漏洞样本均采集自2023年1月(主流LLM预训练知识截止日期)之前。为降低数据泄露风险,我们使用PreciseBugCollector[12]工具构建新型数据集,其通过NVD(美国国家漏洞数据库)API采集人工标注的已验证漏洞,包含:
• 重大漏洞案例:如心脏滴血(CVE-2014-01605)、幽灵漏洞(CVE-2017-5753/CVE-2017-57156)、Log4Shell(CVE-2021-442287)
• 丰富元数据:漏洞描述、CWE类型、严重性等级、修复补丁等
我们从NVD全量数据库217,403条漏洞中筛选出含GitHub修复提交链接且标记为"补丁"的9,759条有效漏洞。通过提取对应GitHub提交的修复代码,将其分割为47,302个文件级变更⁹。
多语言噪声过滤
尽管PreciseBugs涵盖C/C++、Python、Java等多语言漏洞,但实验表明多语言数据会引入显著训练噪声。这与文献[26]结论一致:多语言漏洞微调会显著弱化单语言模型性能。因此,我们仅保留C/C++代码(与BigVul语言对齐),最终构建含2,543条漏洞的数据集,并通过单文件变更分割为12,970个代码片段样本。
数据集特性设计
• 不平衡分布:80%非漏洞样本 + 20%漏洞样本(模拟真实场景代码分布)
• 时间分割策略:
• 训练集:2023年1月前漏洞样本
• 验证/测试集:仅包含2023年1月后新增漏洞(规避LLM数据泄露)
对原始数据集的改进
- 代码片段化处理:将样本分割为单文件片段以适应LLM上下文窗口
- 对话格式转换:按3.1节方法处理为师生对话格式
- 数据泄露防护:基于PreciseBugCollector重采集2023-2024年最新漏洞,确保评估数据时效性
4.1.3 数据集分析
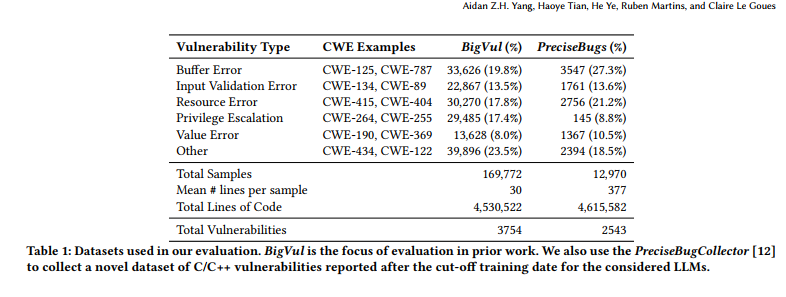
表1展示了数据集的特性对比。遵循BigVul及既有研究惯例,我们以样本(sample)为单位进行分析(一个漏洞通常包含多个样本,即标注函数或上下文窗口大小的代码段)。BigVul样本量(169,772)远超本文构建的C/C++ PreciseBugs数据集(12,970),但需注意:
• BigVul样本:单函数形式,平均30行代码
• PreciseBugs样本:程序窗口形式(可能跨函数),平均356行代码
就总代码行数与漏洞数量而言,PreciseBugs与BigVul规模相当。
漏洞类型标注
基于标注的CWE类型,我们采用Steenhoek等人[27]的分类方案标注主漏洞类型,包括:
- 缓冲区溢出(buffer overflow)
- 输入验证错误(input validation error)
- 资源错误(resource error)
- 权限提升(privilege escalation)
- 数值错误(value error)
表1显示,PreciseBugs与BigVul的漏洞类型分布高度相似,佐证了数据集的可比性。
4.2 评估指标与基线模型
我们通过二元分类(存在/不存在漏洞)评估模型性能,采用以下指标:
• F1值:𝐹1 = \frac{2 \cdot TP}{2 \cdot TP + FP + FN}
• 精确率(Precision): 𝑃 = T P T P + F P 𝑃 = \frac{TP}{TP + FP} P=TP+FPTP
• 召回率(Recall): 𝑅 = T P T P + F N 𝑅 = \frac{TP}{TP + FN} R=TP+FNTP
其中,TP(真阳性)、FP(假阳性)、TN(真阴性)、FN(假阴性)定义与既有漏洞检测研究一致[3,4,6,7]。
基线模型对比
我们将MSIVD与以下四类基线模型对比:
-
非LLM深度学习模型
• VulDeePecker[4]:基于代码属性图的漏洞检测• SySeVR[28]:符号执行驱动的语义分析
• Draper[29]:跨项目迁移学习模型
• IVDetect[6]:数据依赖增强的深度学习
• DeepDFA[3]:图神经网络驱动的数据流分析
-
LLM基线模型
• CodeBERT[30]:代码预训练语言模型• CodeT5[28]:序列到序列代码理解模型
• CodeLlama[31]:开源代码生成LLM
• LineVul[7]:基于LLM的序列分类模型(复现时统一使用CodeLlama-13B作为预训练模型)
-
LLM+GNN联合模型
• 基于DeepDFA复现包,将其GNN嵌入与微调LLM(如HuggingFace¹⁰预训练模型)结合 -
随机基线
• 以50%概率随机预测漏洞存在性(用于不平衡数据集的基准参考)
评估限制说明
• 非LLM基线模型(如IVDetect)仅在BigVul数据集评测(因其依赖静态分析结果,无法适配新型数据集)
• LLM基线模型同时在BigVul与PreciseBugs数据集评测,以验证其在未知漏洞上的泛化能力
4.3 模型配置
我们为MSIVD训练两个模型:
-
序列到序列微调模型
• 基于预训练LLM(CodeLlama-13B-Instruct¹²)进行多任务自指导微调• 输出包含漏洞检测结果及解释性文本
-
序列到分类联合模型
• 在DeepDFA的GNN架构基础上构建,输出二元分类标签(存在漏洞/安全)• 输入为第一个模型的冻结隐藏状态(freeze hidden states)
模型变体说明
• MSIVD:完整模型(含LLM + GNN)
• MSIVD−:仅含LLM的简化版(通过单线性层直接输出分类结果)
预训练模型选择
• 采用CodeLlama-13B-Instruct(130亿参数指令微调版)
• 受限计算资源与显存,未选择更大规模模型(如70B)
超参数配置
表2展示了模型超参数:
• LLM-GNN联合维度:4096(LLM) + 256(GNN) = 4352
• 总层数:8(LLM输出层) + 3(GNN层) = 11
• 批量大小:4(适配单块RTX 8000 GPU显存限制)
5 实验结果
本节通过以下三个研究问题(RQ)评估MSIVD性能:
RQ1:MSIVD在经典数据集上的漏洞检测效果如何?
在BigVul数据集上与基线模型对比(详见5.1节)。
RQ2:MSIVD对未知漏洞的泛化能力如何?
在新型数据集PreciseBugs上验证模型泛化性(详见5.2节)。
RQ3:MSIVD各组件对性能的贡献度如何?
通过消融实验分析多任务微调、GNN等组件的影响(详见5.3节)。
实验环境
• CPU:Intel Xeon 6248R @3.00GHz
• GPU:2×Nvidia Quadro RTX 8000
• 系统:Debian GNU/Linux 1
5.1 RQ1:MSIVD在经典数据集上的漏洞检测效果如何?
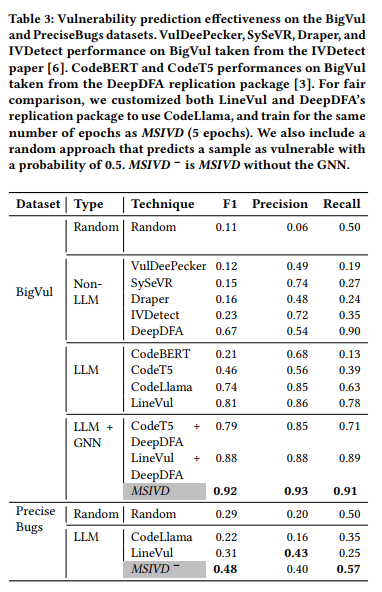
表3展示了MSIVD在BigVul数据集上的性能对比。关键发现如下:
-
非LLM基线的性能上限
• DeepDFA(基于GNN数据流分析)以F1值0.67领先其他非LLM模型,其高召回率(0.9)表明能捕获90%的漏洞样本。 -
LLM基线的优势
• 除CodeBERT外,所有LLM模型(CodeT5、CodeLlama)均超越基于程序分析的深度学习工具。• LineVul(基于CodeLlama-13B)达到F1值0.81,仅凭代码标记即超越所有程序分析模型。
-
LLM+GNN的协同效应
• 旧版LLM(如CodeT5)结合静态分析(DeepDFA)后F1值从0.46提升至0.79,增益显著。• 先进LLM(如CodeLlama)的静态分析增益有限(LineVul+DeepDFA vs LineVul),表明其自身代码语义理解已趋完善。
-
MSIVD的领先性能
• F1值0.92(精确率0.93,召回率0.91),全面优于所有基线。• 多任务解释性微调为预训练LLM提供额外检测精度增益,但主要性能提升仍源于LLM本身的强大能力。
结论
BigVul数据集上的性能突破主要归功于底层LLM的语义理解能力,而MSIVD通过融合漏洞解释与图结构分析实现了当前最优的漏洞检测效能。

















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









