







大数据开发-Hadoop分布式集群搭建
环境准备
- JDK1.8
- Hadoop3.X
- 三台服务器
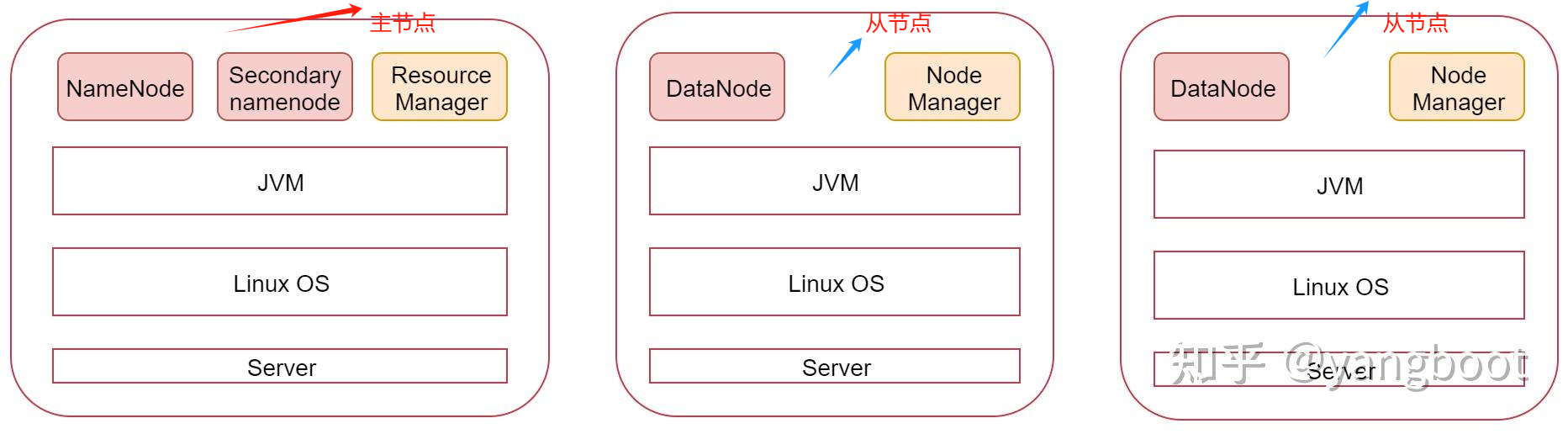
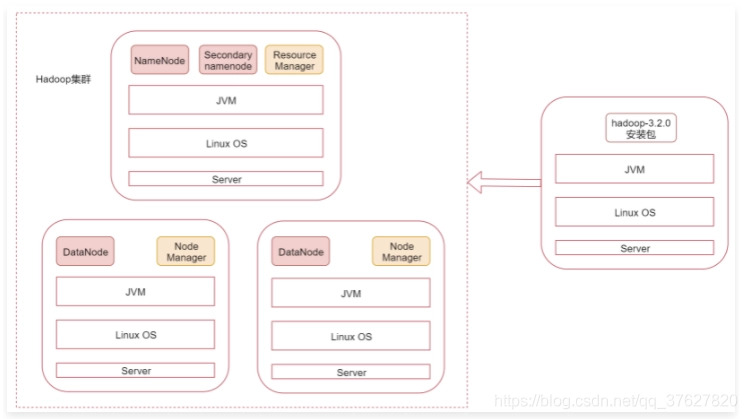
主节点需要启动namenode、secondary namenode、resource manager三个进程
从节点需要启动datanode、node manager两个进程,下面按照步骤进行搭建。
环境配置
# 三台服务器都要改 hosts文件
[root@hadoop01 ~]# vim /etc/hosts
[root@hadoop02 ~]# vim /etc/hosts
[root@hadoop03 ~]# vim /etc/hosts
# 添加如下信息,根据自己的服务器ip以及名称进行修改
192.168.52.100 hadoop01
192.168.52.101 hadoop02
192.168.52.102 hadoop03
# 同步服务器时间
[root@hadoop01 ~]# yum install ntpdate
[root@hadoop01 ~]# ntpdate -u ntp.sjtu.edu.cn
5 Mar 09:38:26 ntpdate[1746]: step time server 17.253.84.125 offset 1.068029 sec
[root@hadoop02 ~]# yum install ntpdate
[root@hadoop02 ~]# ntpdate -u ntp.sjtu.edu.cn
5 Mar 09:38:26 ntpdate[1746]: step time server 17.253.84.125 offset 1.068029 sec
[root@hadoop03 ~]# yum install ntpdate
[root@hadoop03 ~]# ntpdate -u ntp.sjtu.edu.cn
5 Mar 09:38:26 ntpdate[1746]: step time server 17.253.84.125 offset 1.068029 sec
# 定时同步
[root@hadoop01 ~]# vim /etc/crontab
[root@hadoop02 ~]# vim /etc/crontab
[root@hadoop03 ~]# vim /etc/crontab
# crontab中添加如下内容
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
主节点免密登陆从节点
# 将主节点的认证文件copy到其它两个从节点
[root@hadoop01 ~]# scp ~/.ssh/authorized_keys hadoop02:~/
The authenticity of host 'hadoop02 (192.168.52.101)' can't be established.
ECDSA key fingerprint is SHA256:sc01Vk7PIabS9viczEKdgVfwzIYVHA1xib77Q+8tczk.
ECDSA key fingerprint is MD5:ea:15:4e:5f:b0:83:4f:75:ed:1d:2f:02:c4:fa:04:3f.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop02,192.168.52.101' (ECDSA) to the list of known hosts.
root@hadoop02's password:
authorized_keys
[root@hadoop01 ~]# scp ~/.ssh/authorized_keys hadoop03:~/
The authenticity of host 'hadoop03 (192.168.52.102)' can't be established.
ECDSA key fingerprint is SHA256:sc01Vk7PIabS9viczEKdgVfwzIYVHA1xib77Q+8tczk.
ECDSA key fingerprint is MD5:ea:15:4e:5f:b0:83:4f:75:ed:1d:2f:02:c4:fa:04:3f.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop03,192.168.52.102' (ECDSA) to the list of known hosts.
authorized_keys
## 如果没有authorized_keys 可以通过以下生成
[root@hadoop01 ~]# ssh-keygen -t rsa
[root@hadoop01 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 在其它两个从节点执行
[root@hadoop02 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
[root@hadoop03 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
# 执行完成之后可以在主节点免密登陆其它两个从节点
[root@hadoop01 ~]# ssh hadoop02
Last login: Mon Mar 4 16:41:58 2024 from fe80::32d8:512f:316e:a311%ens33
到此为止,环境配置完毕!
Hadoop配置
# 解压
[root@hadoop01 soft]# tar -zxvf hadoop-3.2.0.tar.gz
#修改配置文件
[root@hadoop01 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/home/soft/jdk1.8
export HADOOP_LOG_DIR=/home/hadoop_repo/logs/hadoop
# core-site.xml
[root@hadoop01 hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop_repo/data</value>
</property>
</configuration>
[root@hadoop01 hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop01:50090</value>
</property>
</configuration>
# mapred-site.xml
[root@hadoop01 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# yarn-site.xml
[root@hadoop01 hadoop]# vim yarn-site.xml
<configuration>
<!--指定MR走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
<!--环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
</configuration>
# workers 指定从节点
[root@hadoop01 hadoop]# vim workers
hadoop02
hadoop03
Hadoop脚本修改
## start-dfs.sh
[root@hadoop01 sbin]# vim start-dfs.sh
# 文件起始位置添加:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
## stop-dfs.sh
[root@hadoop01 sbin]# vim stop-dfs.sh
# 文起始位置添加:
HDFS_DATA_NODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
## start-yarn.sh
[root@hadoop01 sbin]# vim start-yarn.sh
# 文起始位置添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
## stop-yarn.sh
[root@hadoop01 sbin]# vim stop-yarn.sh
# 文起始位置添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
从节点配置
# 将修改好的hadoop拷贝到其它两台机器上
[root@hadoop01 soft]# scp -rq hadoop-3.2.0 hadoop02:/home/soft/
[root@hadoop01 soft]# scp -rq hadoop-3.2.0 hadoop03:/home/soft/
## 格式化主节点
[root@hadoop01 hadoop-3.2.0]# bin/hdfs namenode -format
启动Hadoop集群
# 启动
[root@hadoop01 sbin]# start-all.sh
Starting namenodes on [hadoop01]
Last login: Tue Mar 5 11:11:55 CST 2024 from 192.168.52.1 on pts/0
Starting datanodes
Last login: Tue Mar 5 11:16:32 CST 2024 on pts/0
Starting secondary namenodes [hadoop01]
Last login: Tue Mar 5 11:16:35 CST 2024 on pts/0
Starting resourcemanager
Last login: Tue Mar 5 11:16:40 CST 2024 on pts/0
Starting nodemanagers
Last login: Tue Mar 5 11:16:47 CST 2024 on pts/0
You have new mail in /var/spool/mail/root
# 查看进程
[root@hadoop01 sbin]# jps # 主节点
1765 SecondaryNameNode
2007 ResourceManager
2329 Jps
1500 NameNode
[root@hadoop03 ~]# jps # 从节点
1361 NodeManager
1252 DataNode
1477 Jps
You have new mail in /var/spool/mail/root
[root@hadoop02 ~]# jps # 从节点
1513 Jps
1418 NodeManager
1308 DataNode
启动完成!
官方文档地址:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
Hadoop客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,所以我们需要在业务机器上安装Hadoop,这样就可以在业务机器上操作Hadoop集群了,这个机器就称为Hadoop的客户端节点。
在这个客户端节点只需要安装基本的java环境、hadoop环境就可以使用了(不要启动hadoop进程,不然就变成集群中的机器了)。
e.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
Hadoop客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,所以我们需要在业务机器上安装Hadoop,这样就可以在业务机器上操作Hadoop集群了,这个机器就称为Hadoop的客户端节点。
在这个客户端节点只需要安装基本的java环境、hadoop环境就可以使用了(不要启动hadoop进程,不然就变成集群中的机器了)。

















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











