







文章的创新点:新颖的相似度测量方法,不再使用一个边的标签定义一个权重而是对简单path experts的一个组合。 这个方法在8组和生物有关的实验集中有更好的正确率(相比于RWR random Walk with Restart)
关键词:random walk ,filtering and recommending
文章的测试目标任务:推荐任务 具体包括基因、收入、参考、专家查找。
在传统基于关键字排序来进行文件恢复,这其实是一个相似查询任务,其中查询节点是term node ,查询的结果的种类是“document”。
任务介绍
杂志推荐:寻找一个最合适的杂志来发表论文。 term是论文的名字和相关的实体,答案的种类是杂志,所以答案是一个关于生物杂志的排名。
参考推荐 寻找和一篇新论文相关参考文献的推荐。query是这篇论文的名称和相关的实体,现在的年份。答案的类型是论文,希望获得的答案是有关于论文的排序。
专家查询 对于相关的领域找到对应的专家。
数据集
RWR-based proximity measure
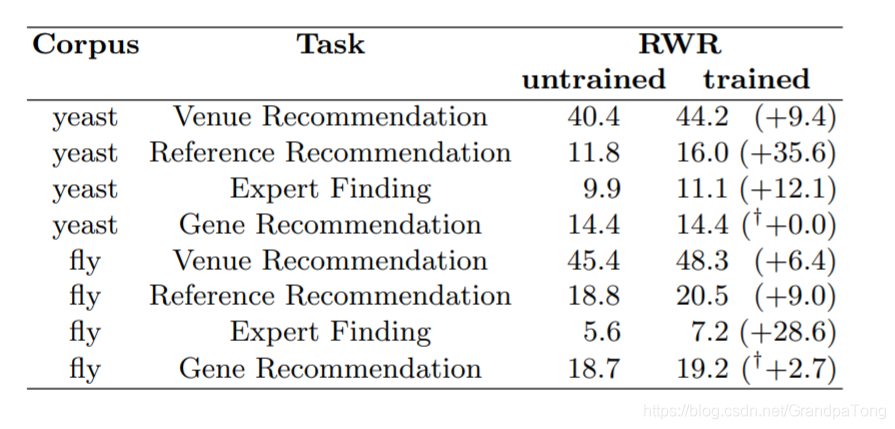
基线结果
未训练的RWR模型(所有边的权重设置为1.0)
经过训练的RWR模型
The Path Ranking Algorithm
单权重的局限性的例子:对于参考推荐,查询节点是时间,这里有有两种方法来得到结果,1.寻找在这个时间发表的文章2.查询在该时间发表的文章最常引用的文章。 第二个的启发性更强。
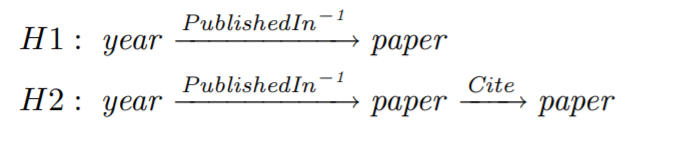
启发函数的定义
和定义相关的一些符号
range(R)
dom(R)
对于关系路径P=R1…Rl 和查询实体Eq
∈
\in
∈ dom (\P),我可以定义一个分布函数。
如果P是空的路径: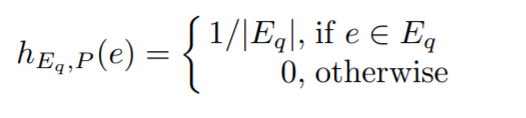
如果P不是空的路径:
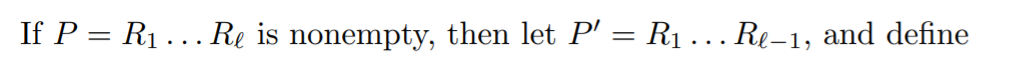
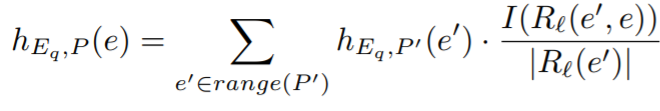
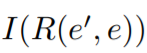
这是一个指针函数,如果R(e’,e),则为1,否则为0.e’表示不在dom中的。
下面解释为什么H2要比H1更好。
Eq是标题单词的集合,和基因-蛋白质实体,y是年份,e1在分布函数hEq,publishedIn-1,e2在分布函数hEqPublishedIn-1.Cite
在这片论文中只进行l=4以内的推理,推理的长度最大为4
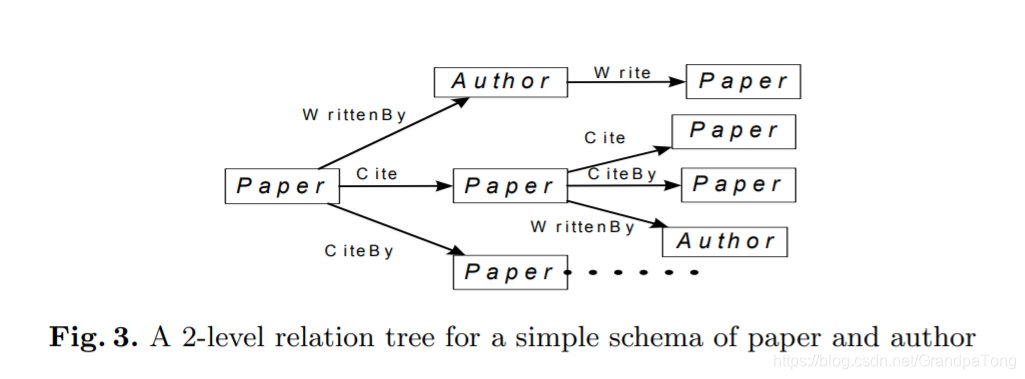
这个图所展示的是一个推理长度为2的前缀树。
另外因为有易操作,我们可以限制以下推理连不进行考虑,用来减少一些我们不关心的结果。

对于以上我们建立的得分函数为:
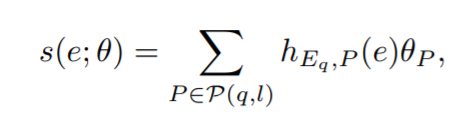
$$是不同路径的权重
参数的估计
对于参数的确定方法有以下几种
1.穷举法 exhaustive local search
2.反向传播 线性收敛
3.二阶优化函数 例如 BLMVM
4.二级优化函数 L-BFGS
L-BFGS用来求解log函数
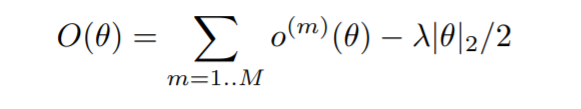
这里使用的目标函数是二项式似然函数。它具有易于优化的特点。
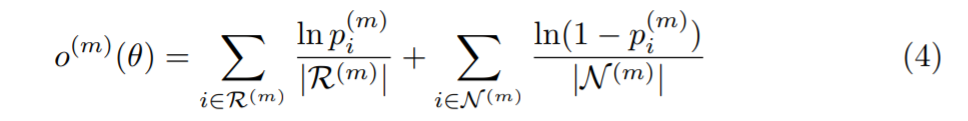
R是相关实体的索引集合。N是没有关系的实体索引集合。为了平衡训练不均衡的正样本和负样本的数量。我们可以利用log函数的优势。
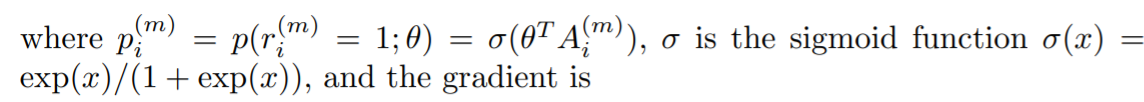
A表示的是特征矩阵。将pi带入之后对
θ
\theta
θ求导数我们可以得到
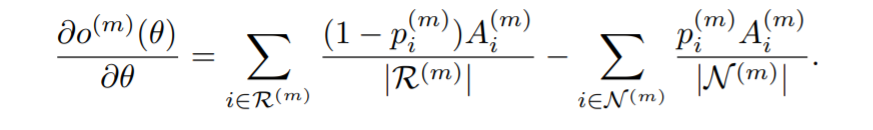
一般和主体有关系的正样本的数量是远远少于负样本的数量的。为了解决这个问题,首先我们对所有的负样本利用PRA模型求解(不进行训练)。排序之后选择第k(k+1)/2位置处的选为负样本。原因是不相关的样本被弱排序函数排序后,排序高的样本比排序第的样本更重要,具体的原因可以参考 Aslam et al.’s work。
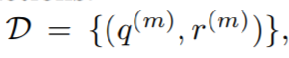
为训练集,r=1 表示e和q有关系
r=0,表示e和q没有关系。















 7879
7879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









