







 使用Python的sklearn数据包做数据分析经典案例泰坦尼克预测
使用Python的sklearn数据包做数据分析经典案例泰坦尼克预测
数据读取
分别读取两个csv文件中的数据合并到一个数组中
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
PassengerId = test['PassengerId']
all_data = pd.concat([train, test], ignore_index=True)
数据可视化分析
通过打印alldata数组,可以看到test和train合并之后的数组数据
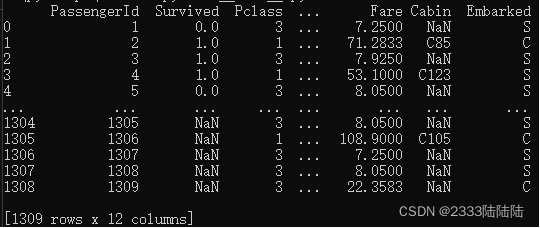
再通过discribe函数看出整体数据的特征及分布

由图可知数据集初步可分为11个特征和1个标签,且各特征值的总和、均值、标准差、最值、上下四分位点一目了然。
查看变量类型以及数量,分析得:
1.full数据集共1309行
2.浮点型变量有3个,整型变量4个,字符型5个
3.Survived列为标签,1代表获救,0代表遇难
4.Age\Cabin\Embarked\Fare\Name\Parch\PassengerId\Pclass\Sex\SibSip\Ticket11列为特征
5.Age\Cabin\Embarked\Fare数据有缺失
接下来将train中的数据可视化,分析几个特征和幸存之间的关系
可视化处理
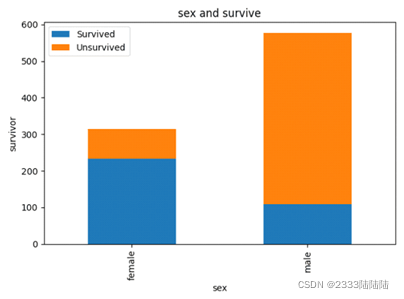
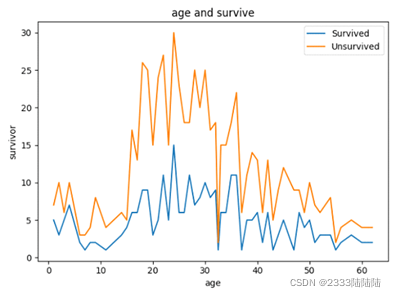
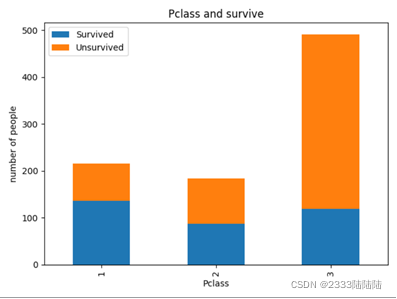
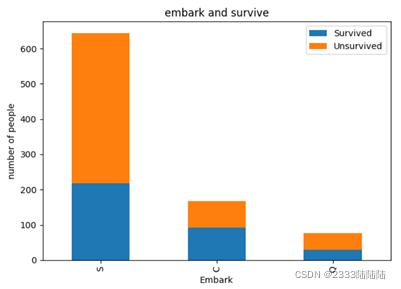
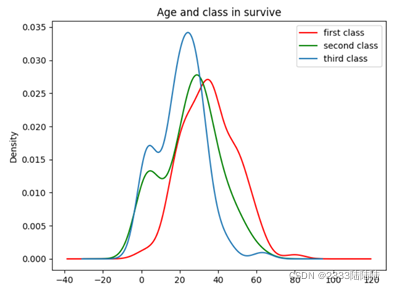
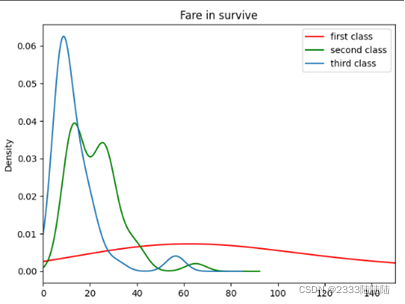
填充缺失数据
1.Age Feature:Age缺失量为263,缺失量较大,用Sex, Title, Pclass三个特征构建随机森林模型,填充年龄缺失值。特征提取并转化。
age_df = all_data[['Age', 'Pclass', 'Sex', 'Title']]
age_df = pd.get_dummies(age_df)
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
y = known_age[:, 0]
X = known_age[:, 1:]
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
predictedAges = rfr.predict(unknown_age[:, 1::])
all_data.loc[(all_data.Age.isnull()), 'Age'] = predictedAges
2.Embarked Feature:Embarked缺失量为2,缺失Embarked信息的乘客的Pclass均为1,且Fare均为80,因为Embarked为C且Pclass为1的乘客的Fare中位数为80,所以缺失值填充为C。
all_data['Embarked'] = all_data['Embarked'].fillna('C')
3.Fare Feature:Fare缺失量为1,缺失Fare信息的乘客的Embarked为S,Pclass为3,所以用Embarked为S,Pclass为3的乘客的Fare中位数填充。
fare=all_data[(all_data['Embarked'] == "S") & (all_data['Pclass'] == 3)].Fare.median()
all_data['Fare']=all_data['Fare'].fillna(fare)
特征选择
把姓氏相同的乘客划分为同一组,从人数大于一的组中分别提取出每组的妇女儿童和成年男性。
all_data['Surname']=all_data['Name'].apply(lambda x:x.split(',')[0].strip())
Surname_Count = dict(all_data['Surname'].value_counts())
all_data['FamilyGroup'] = all_data['Surname'].apply(lambda x:Surname_Count[x])
Female_Child_Group=all_data.loc[(all_data['FamilyGroup']>=2) & ((all_data['Age']<=12) | (all_data['Sex'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4235
4235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









