







遇到的问题
我们es中保存了商户所有的商品信息,在一个下拉框中需要能多维度的定位到商品信息(如输入商品名+规格等等),因为涉及字段较多,所以我们还为每个字段单独设置了权重,且在使用should + multi_match 时指定了minimum_should_match(最小的匹配数量),以此来避免出现无关数据。
测试发现我们输入与第一项匹配值与预想有一定差距,比如下图:
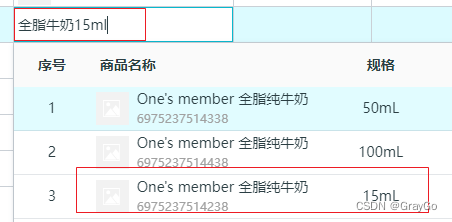
我们输入了全脂牛奶15ml,可是预想的15ml排到了第三行,一个50ml排到了第一行。我们在不停调整权重后也不能解决。
问题查询思路
没办法我们只能将第一行数据和第三行数据的评分细则拿出来,
post /索引名/_search/_explain/数据id
获取到两个数据的具体评分数据
在这里我们看到一个有意思的问题,在计算相同字段的相同数据时,居然评分还不一致,比如:商品名字段中的“全脂”
第一行数据:
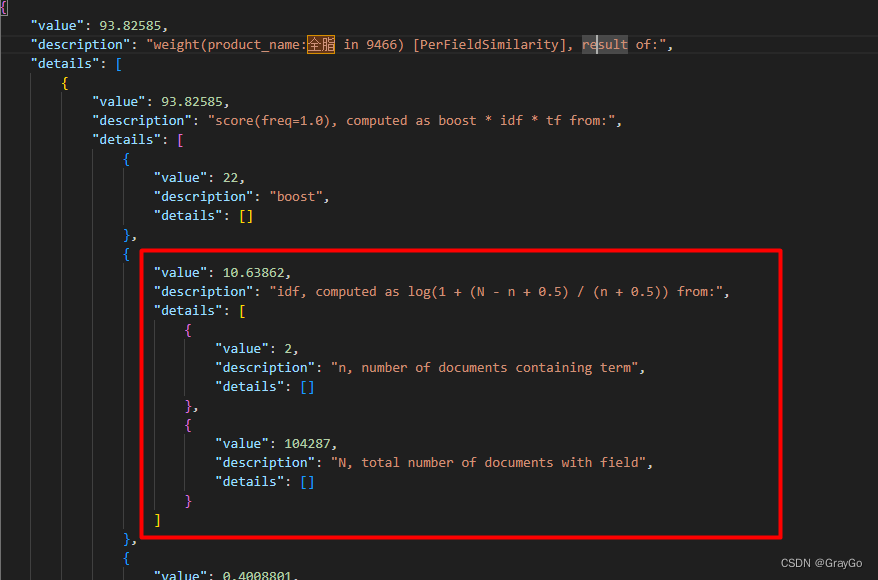
目标行数据
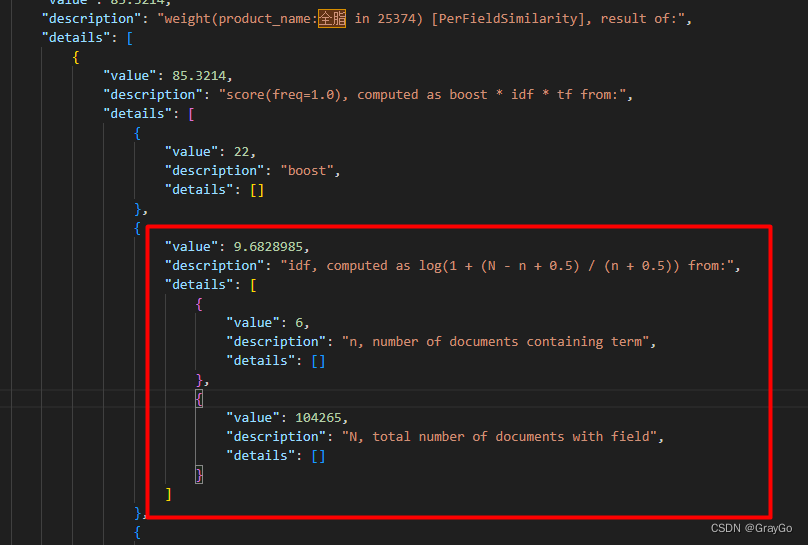
不是啊,咱两都叫“全脂”你的全脂为啥还尊贵点???
看了下这里在计算IDF,n是包含关键词的文档数。
简单介绍下es的(TF/IDF模型)评分机制:
-
TF:TF(Term Frequency),即词频,表示词条在文本中出现的频率。考虑一篇文档得分的首要方式,是查看一个词条在当前文档(注意IDF统计的范围是所有文档)中出现的次数,比如某篇文章围绕ES的打分展开的,那么文章中肯定会多次出现相关字眼,当查询时,我们认为该篇文档更符合,所以这篇文档的得分会更高。TF的值通常会被归一化,一般是词频除以文章总词数,以防止它偏向长的文件(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。
-
IDF:IDF(Inverse Document Frequency),即逆文档频率,反应了一个词在所有文档中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。
简单来说就是:一个词语在某一篇文档中出现次数越多,同时在所有文档中出现次数越少,那么该文档越能与其它文章区分开来,评分就会越高。
那就更奇怪了相同关键词,在同一个es中,出现次数还能不一样???
查了半天终于发现了端倪,我们在创建es索引的时候指定了数据分片,数据可能被分到了不同的分片中!!!
POST /索引名/_search?preference=_shards:分片号(1-N)
目标行在1分片中,里面文本“全脂”较多
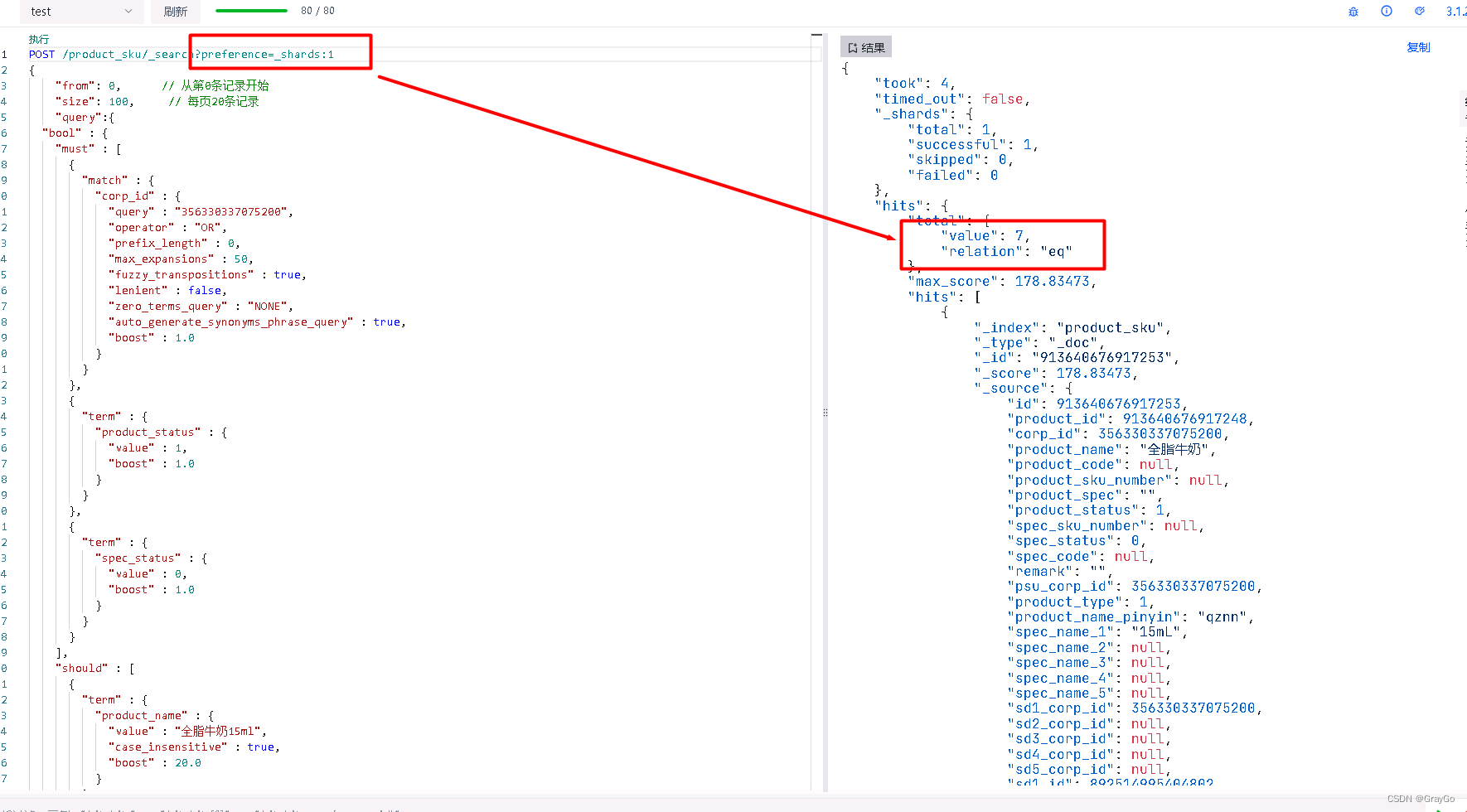
第一行数据在分片2中,里面文本“全脂”较少
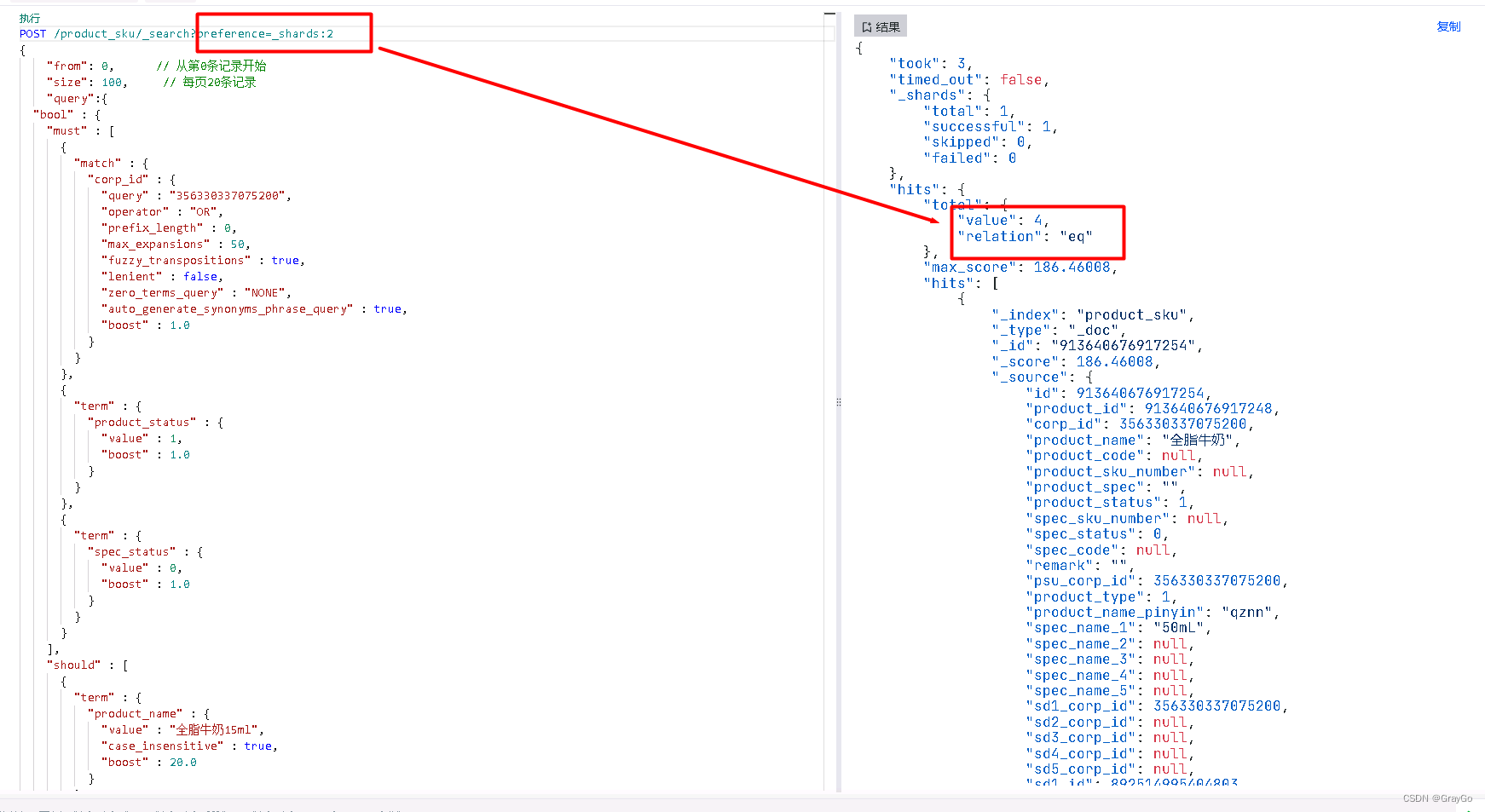
所以在计算idf(逆文档频率)时第一行数据集分数更高.
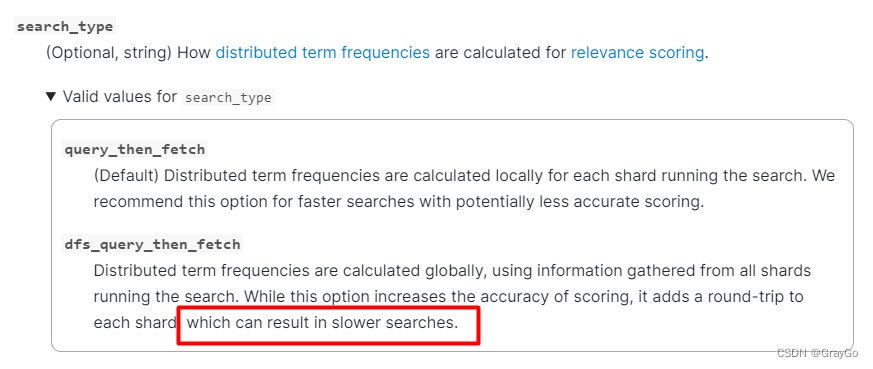
知道问题后,那就简单了,那有没有分片聚集查询呢?有,但官方不建议,我们做分片就是为了数据分散提升查询效率,聚集后会导致查询效率变慢。
官网说明:search_type说明
那我们试试吧
POST /索引名/_search?search_type=dfs_query_then_fetch
分数排序确实变了,但…变了后还不是预期模样
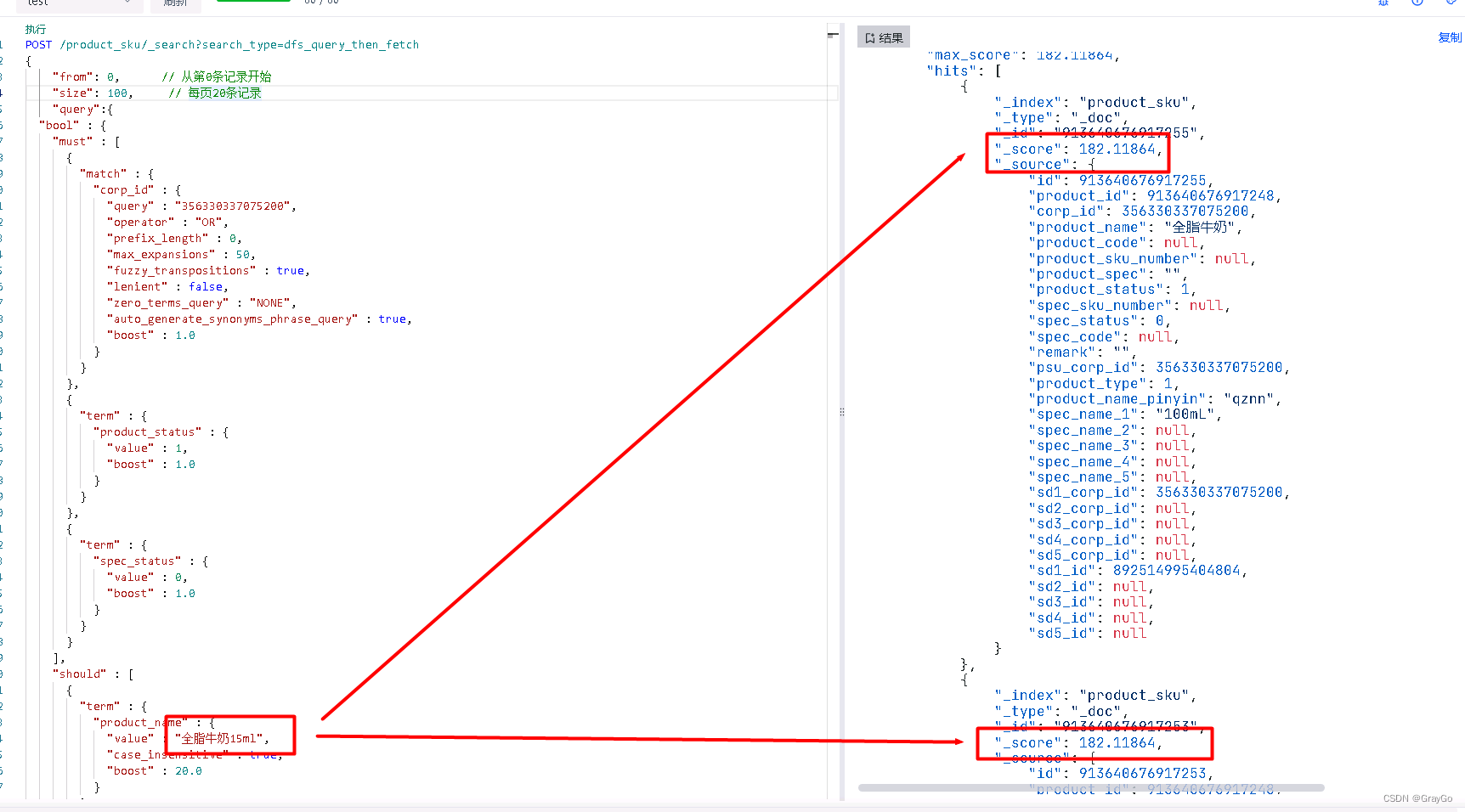
现在分数一致了,但我们想要的到了第二行。那么在分数一致时是如何排序的呢?问了问万能的gpt

如何解决
既然修改权重,相同分数等无法解决,我们就只能按照业务来自定义评分规则
这里推荐几篇大佬的参考文档
ElasticSearch自定义评分
Elasticsearch自定义评分的N种方法















 1742
1742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









