









文中内容参考《redis设计与实现(第二版)》和redis源码,由于该书写的比较早,主要以源码(redis5.0.5)为主。
虽说是参考的源码的,但是主要内容仍然来自书籍。
笔记中的内容并不完整,redis有点儿多,先做一个简单的整理,如果工作中会用到的话再做一个完整的版本吧!
前面的相关数据结构部分可以看一下,后面的内容并没有很全面的整理,之后需要的话对源码进行一次完整的阅读。
1 redis数据结构与对象
1.1 动态字符串
1.1.1 数据结构定义
//deps/hiredis/sds.h
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
不同字段的含义:
len:占4个字节,已使用长度;alloc:占4个字节,申请到的长度;flags:占1个字节,低三位表示当前字符串的类型,高位并未使用;buf:数据域,是一个柔型数组。
并且字符串支持不同长度版本:sds8.sds16,sds32,sds64。

1.1.2 相关API
| 函数 | 功能 | 时间复杂度 |
|---|---|---|
| sdsnew | 创建一个包含给定 C 字符串的 SDS 。 | O(N) , N 为给定 C 字符串的长度。 |
| sdsempty | 创建一个不包含任何内容的空 SDS 。 | O(1) |
| sdsfree | 释放给定的 SDS 。 | O(1) |
| sdslen | 返回 SDS 的已使用空间字节数。 | 这个值可以通过读取 SDS 的 len 属性来直接获得, 复杂度为 O(1) 。 |
| sdsavail | 返回 SDS 的未使用空间字节数。 | 这个值可以通过读取 SDS 的 free 属性来直接获得, 复杂度为 O(1) 。 |
| sdsdup | 创建一个给定 SDS 的副本(copy)。 | O(N) , N 为给定 SDS 的长度。 |
| sdsclear | 清空 SDS 保存的字符串内容。 | 因为惰性空间释放策略,复杂度为 O(1) 。 |
| sdscat | 将给定 C 字符串拼接到 SDS 字符串的末尾。 | O(N) , N 为被拼接 C 字符串的长度。 |
| sdscatsds | 将给定 SDS 字符串拼接到另一个 SDS 字符串的末尾。 | O(N) , N 为被拼接 SDS 字符串的长度。 |
| sdscpy | 将给定的 C 字符串复制到 SDS 里面, 覆盖 SDS 原有的字符串。 | O(N) , N 为被复制 C 字符串的长度。 |
| sdsgrowzero | 用空字符将 SDS 扩展至给定长度。 | O(N) , N 为扩展新增的字节数。 |
| sdsrange | 保留 SDS 给定区间内的数据, 不在区间内的数据会被覆盖或清除。 | O(N) , N 为被保留数据的字节数。 |
| sdstrim | 接受一个 SDS 和一个 C 字符串作为参数, 从 SDS 左右两端分别移除所有在 C 字符串中出现过的字符。 | O(M*N) , M 为 SDS 的长度, N 为给定 C 字符串的长度。 |
| sdscmp | 对比两个 SDS 字符串是否相同。 | O(N) , N 为两个 SDS 中较短的那个 SDS 的长度。 |
1.1.3 实现原理
redis中的字符串实现的一个特点是为字符数组加上了左右边界。
1.1.3.1 空间预分配
这一点很想C++中的vector,如果用户需要n个字节的空间,则redis会分配大于n的空间(一般为2*n)进行预分配减少之后的空间分配操作,提升性能。
redis的内存分配策略为:
- 如果
sds的长度(len值)小于1mb,则得到的空间为2*len+1,即free=len,一个字符存储结尾字符'\0'; - 如果
sds的长度(len值)大于等于1mb,则得到的空间为len+1kb+1。
#define SDS_MAX_PREALLOC (1024*1024)
//...
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
1.1.3.2 free-on-write(惰性空间释放)
free-on-write这个词是我按照copy-on-write联想出来的,其基本原理也类似:即当用户释放内存空间时,系统并不会真正的释放空间而是标记记录,待到用户需要写这部分空间或者系统内存不足时再进行释放。这样的好处是如果用户之后还会对目标数据进行操作扩展就不需要进行额外的申请。
并未在源码中找到类似的机制,只有清空字符串时并未进行只是设置部分数据而已,严格意义上不能算作是redis针对字符串数据的一种机制。
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
}
1.1.3.3 二进制安全
因为通过,len和free确定了字符串的区间,而不是简单的使用'\0'进行标记,一定程度上保证了该数据不会出现缓冲区溢出。并且能够保存除了字符串之外的其他类型面向byte数据,如图像,二进制数据等等。
但是需要注意的是这并不是严格意义上的二进制安全,在stsupdatelenapi中使用了c函数库提供的strlen进行长度更新,整个redis这个函数基本没使用过,因此这个函数尽量不要使用。
void sdsupdatelen(sds s) {
size_t reallen = strlen(s);
sdssetlen(s, reallen);
}
1.1.3.4 其他技巧
在redis源码中可以看到访问sds都是使用如下方式:
typedef char *sds;
sds s;
//...
unsigned char flags = s[-1];
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
//...
原因很简单,整个结构体的头部大小是固定的:sizeof(int) * 2 + sizeof(char),如果知道了结构体中数据指针的地址很容易推断到结构体开头的地址。这样做的好处是可以方便使用,部分兼容语言的库函数。
结构体中的buf[]是一个柔性数组,并不占用结构体的大小,因此sizeof(struct sdshdr)实际上是sizeof(len)+sizeof(alloc)+sizeof(flags)。
结构中最后一个元素允许是未知大小的数组,这个数组就是柔性数组。但结构中的柔性数组前面必须至少一个其他成员,柔性数组成员允许结构中包含一个大小可变的数组。sizeof返回的这种结构大小不包括柔性数组的内存。包含柔数组成员的结构用malloc函数进行内存的动态分配,且分配的内存应该大于结构的大小以适应柔性数组的预期大小。
1.1.4 sds和C字符串的区别
| C字符串 | SDS |
|---|---|
| 可能出现缓冲区溢出 | 不会造成缓冲区溢出 |
| 只能存储文本数据 | 二进制安全,可以存储任意数据 |
| 可以使用<string.h>库函数 | 可以部分使用<string.h>库函数 |
1.2 链表
1.2.1 数据结构定义
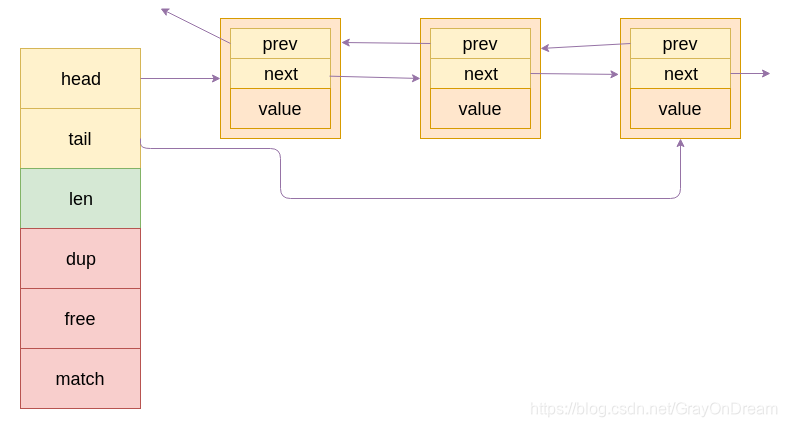
链表的结点定义:
typedef struct listNode {
struct listNode *prev; //上一个节点
struct listNode *next; //下一个节点
void *value; //数据域
} listNode;
链表的迭代器定义:
typedef struct listIter {
listNode *next; //下一个节点
int direction; //方向,AL_START_HEAD或者AL_START_TAIL
} listIter;
链表定义:
typedef struct list {
listNode *head; //链表的头指针
listNode *tail; //链表的尾指针
void *(*dup)(void *ptr); //复制节点的函数指针
void (*free)(void *ptr); //释放节点的函数指针
int (*match)(void *ptr, void *key); //节点值对比函数指针
unsigned int len; //链表的长度
} list;
从上面的结构体定义中可以看到,redis中的字典实现的基础数据结构是hash表。
1.2.2 相关API
| 函数 | 功能 | 时间复杂度 |
|---|---|---|
| listSetDupMethod | 将给定的函数设置为链表的节点值复制函数。 | O(1) 。 |
| listGetDupMethod | 返回链表当前正在使用的节点值复制函数。 | 复制函数可以通过链表的 dup 属性直接获得, O(1) |
| listSetFreeMethod | 将给定的函数设置为链表的节点值释放函数。 | O(1) 。 |
| listGetFree | 返回链表当前正在使用的节点值释放函数。 | 释放函数可以通过链表的 free 属性直接获得, O(1) |
| listSetMatchMethod | 将给定的函数设置为链表的节点值对比函数。 | O(1) |
| listGetMatchMethod | 返回链表当前正在使用的节点值对比函数。 | 对比函数可以通过链表的 match 属性直接获得,O |
| listLength | 返回链表的长度(包含了多少个节点)。 | 链表长度可以通过链表的 len 属性直接获得, O(1) 。 |
| listFirst | 返回链表的表头节点。 | 表头节点可以通过链表的 head 属性直接获得, O(1) 。 |
| listLast | 返回链表的表尾节点。 | 表尾节点可以通过链表的 tail 属性直接获得, O(1) 。 |
| listPrevNode | 返回给定节点的前置节点。 | 前置节点可以通过节点的 prev 属性直接获得, O(1) 。 |
| listNextNode | 返回给定节点的后置节点。 | 后置节点可以通过节点的 next 属性直接获得, O(1) 。 |
| listNodeValue | 返回给定节点目前正在保存的值。 | 节点值可以通过节点的 value 属性直接获得, O(1) 。 |
| listCreate | 创建一个不包含任何节点的新链表。 | O(1) |
| listAddNodeHead | 将一个包含给定值的新节点添加到给定链表的表头。 | O(1) |
| listAddNodeTail | 将一个包含给定值的新节点添加到给定链表的表尾。 | O(1) |
| listInsertNode | 将一个包含给定值的新节点添加到给定节点的之前或者之后。 | O(1) |
| listSearchKey | 查找并返回链表中包含给定值的节点。 | O(N) , N 为链表长度。 |
| listIndex | 返回链表在给定索引上的节点。 | O(N) , N 为链表长度。 |
| listDelNode | 从链表中删除给定节点。 | O(1) 。 |
| listRotate | 将链表的表尾节点弹出,然后将被弹出的节点插入到链表的表头, 成为新的表头节点。 | O(1) |
| listDup | 复制一个给定链表的副本。 | O(N) , N 为链表长度。 |
| listRelease | 释放给定链表,以及链表中的所有节点。 | O(N) , N 为链表长度。 |
1.2.3 实现原理
链表的实现比较直接,就是简单的双向链表,通过一个数据结构保存链表的头指针,尾指针,长度,操作函数指针等信息。
另外实现了一个链表的迭代器方便的链表的访问。
1.3 字典
字典的实现原理是哈希表。
1.3.1 数据结构定义
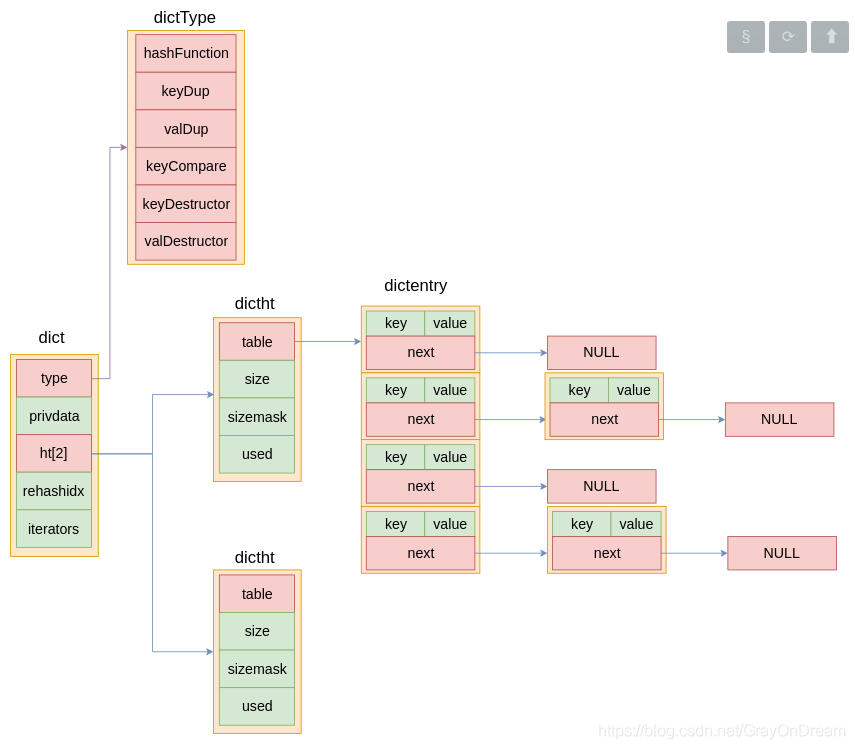
hash表定义:
typedef struct dictht {
dictEntry **table; //哈希表数组,dictEntry的指针数组
unsigned long size; //哈希表的大小
unsigned long sizemask; //总是等于size - 1,配合hash值计算对应值的插入位置
unsigned long used; //hash表中的节点数量
} dictht;
hash表节点定义:
typedef struct dictEntry {
void *key; //键
void *val; //值
struct dictEntry *next; //指向下一个hash表的节点
} dictEntry;
redis中的字典:
typedef struct dict {
dictType *type; //各种类型的操作函数
void *privdata; //私有数据
dictht ht[2]; //哈希表
int rehashidx; //用来记录rehash进度的变量
int iterators; /* number of iterators currently running */
} dict;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //hash函数
void *(*keyDup)(void *privdata, const void *key); //复制键函数
void *(*valDup)(void *privdata, const void *obj); //复制值函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //键的比较函数
void (*keyDestructor)(void *privdata, void *key); //销毁键函数
void (*valDestructor)(void *privdata, void *obj); //销毁值函数
} dictType;
1.3.2 相关API
| 函数 | 功能 | 时间复杂度 |
|---|---|---|
| dictCreate | 创建一个新的字典。 | O(1) |
| dictAdd | 将给定的键值对添加到字典里面。 | O(1) |
| dictReplace | 将给定的键值对添加到字典里面, 如果键已经存在于字典,那么用新值取代原有的值。 | O(1) |
| dictFetchValue | 返回给定键的值。 | O(1) |
| dictGetRandomKey | 从字典中随机返回一个键值对。 | O(1) |
| dictDelete | 从字典中删除给定键所对应的键值对。 | O(1) |
| dictRelease | 释放给定字典,以及字典中包含的所有键值对。 | O(N) , N 为字典包含的键值对数量。 |
1.3.3 实现原理
1.3.3.1 hash索引
redis字典计算hash索引的方式如下,即通过hash算法得到对应key的hash值然后和sizemask与操作就是最终的索引值:
idx = hash & d->ht[table].sizemask;
redis字典采用的hash算法是SipHash算法。
大部分非加密哈希算法的改良,都集中在让哈希速度更快更好上。SipHash 则是个异类,它的提出是为了解决一类安全问题:hash flooding。通过让输出随机化,SipHash 能够有效减缓 hash flooding 攻击。凭借这一点,它逐渐成为 Ruby、Python、Rust 等语言默认的 hash 表实现的一部分。
uint64_t siphash(const uint8_t *in, const size_t inlen, const uint8_t *k) {
#ifndef UNALIGNED_LE_CPU
uint64_t hash;
uint8_t *out = (uint8_t*) &hash;
#endif
uint64_t v0 = 0x736f6d6570736575ULL;
uint64_t v1 = 0x646f72616e646f6dULL;
uint64_t v2 = 0x6c7967656e657261ULL;
uint64_t v3 = 0x7465646279746573ULL;
uint64_t k0 = U8TO64_LE(k);
uint64_t k1 = U8TO64_LE(k + 8);
uint64_t m;
const uint8_t *end = in + inlen - (inlen % sizeof(uint64_t));
const int left = inlen & 7;
uint64_t b = ((uint64_t)inlen) << 56;
v3 ^= k1;
v2 ^= k0;
v1 ^= k1;
v0 ^= k0;
for (; in != end; in += 8) {
m = U8TO64_LE(in);
v3 ^= m;
SIPROUND;
v0 ^= m;
}
switch (left) {
case 7: b |= ((uint64_t)in[6]) << 48; /* fall-thru */
case 6: b |= ((uint64_t)in[5]) << 40; /* fall-thru */
case 5: b |= ((uint64_t)in[4]) << 32; /* fall-thru */
case 4: b |= ((uint64_t)in[3]) << 24; /* fall-thru */
case 3: b |= ((uint64_t)in[2]) << 16; /* fall-thru */
case 2: b |= ((uint64_t)in[1]) << 8; /* fall-thru */
case 1: b |= ((uint64_t)in[0]); break;
case 0: break;
}
v3 ^= b;
SIPROUND;
v0 ^= b;
v2 ^= 0xff;
SIPROUND;
SIPROUND;
b = v0 ^ v1 ^ v2 ^ v3;
#ifndef UNALIGNED_LE_CPU
U64TO8_LE(out, b);
return hash;
#else
return b;
#endif
}
uint64_t siphash_nocase(const uint8_t *in, const size_t inlen, const uint8_t *k)
{
#ifndef UNALIGNED_LE_CPU
uint64_t hash;
uint8_t *out = (uint8_t*) &hash;
#endif
uint64_t v0 = 0x736f6d6570736575ULL;
uint64_t v1 = 0x646f72616e646f6dULL;
uint64_t v2 = 0x6c7967656e657261ULL;
uint64_t v3 = 0x7465646279746573ULL;
uint64_t k0 = U8TO64_LE(k);
uint64_t k1 = U8TO64_LE(k + 8);
uint64_t m;
const uint8_t *end = in + inlen - (inlen % sizeof(uint64_t));
const int left = inlen & 7;
uint64_t b = ((uint64_t)inlen) << 56;
v3 ^= k1;
v2 ^= k0;
v1 ^= k1;
v0 ^= k0;
for (; in != end; in += 8) {
m = U8TO64_LE_NOCASE(in);
v3 ^= m;
SIPROUND;
v0 ^= m;
}
switch (left) {
case 7: b |= ((uint64_t)siptlw(in[6])) << 48; /* fall-thru */
case 6: b |= ((uint64_t)siptlw(in[5])) << 40; /* fall-thru */
case 5: b |= ((uint64_t)siptlw(in[4])) << 32; /* fall-thru */
case 4: b |= ((uint64_t)siptlw(in[3])) << 24; /* fall-thru */
case 3: b |= ((uint64_t)siptlw(in[2])) << 16; /* fall-thru */
case 2: b |= ((uint64_t)siptlw(in[1])) << 8; /* fall-thru */
case 1: b |= ((uint64_t)siptlw(in[0])); break;
case 0: break;
}
v3 ^= b;
SIPROUND;
v0 ^= b;
v2 ^= 0xff;
SIPROUND;
SIPROUND;
b = v0 ^ v1 ^ v2 ^ v3;
#ifndef UNALIGNED_LE_CPU
U64TO8_LE(out, b);
return hash;
#else
return b;
#endif
}
解决冲突:因为hash表,一定存在不同的key,得到相同的hash值的情况,redis字典解决冲突的方式是使用链地址法,每次将新插入的节点插入到对应索引位置的头部,可以保证插入操作为O(1)。
1.3.3.2 rehash
随着字典的不断使用,其中hash表的负载因子(used/size)会不断提升或者减小,导致hash表太过紧凑或者松散。redis提供rehash机制对hash表进行相应的扩展或者收缩。
redis哈希表rehash算法步骤:
- 字典中的
ht[1]是辅助进行rehash的表,进行rehash时,首先需要给ht[1]分配空间:- 如果执行的是扩展操作,
ht[1]的大小为第一个大于等于ht[0].used * 2的 2 n 2^n 2n; - 如果执行的是收缩操作,
ht[1]的大小为第一个大于等于ht[0].used的 2 n 2^n 2n;
- 如果执行的是扩展操作,
- 将保存在
ht[0]上的所有数据进行rehash(重新计算hash索引),保存到h[1]上; - 当
ht[0]上的数据都迁移到ht[1]上时,则释放ht[0],将ht[1]设置为ht[0],并创建一个空的表作为ht[1]。
另外需要注意的是redis判断rehash完成的依据是ht[0].used==0之后设置rehashidx==-1,rehashidx记录当前rehash到那个表节点。
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
rehash的时机:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 1 (
used/size); - 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5 (
used/size);
当条件1和条件2其中一个被满足时则开始进行rehash扩展。
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行, 服务器执行扩展操作所需的负载因子并不相同, 这是因为在执行 BGSAVE 命令或BGREWRITEAOF 命令的过程中, redis 需要创建当前服务器进程的子进程, 而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率, 所以在子进程存在期间, 服务器会提高执行扩展操作所需的负载因子, 从而尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存。
当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作。
渐进式rehash:
redis如果一次性的对所有数据进行rehash则可能出现服务短时间内无法使用的情况,因此redis采用的是渐进式的rehash,即每次只进行一部分rehash,并且使用rehashidx记录rehash的进度。
如下代码所示,每次只进行指定ms级的rehash,当超过预定时间则中断。
/* Rehash for an amount of time between ms milliseconds and ms+1 milliseconds */
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
1.4 跳跃表
跳跃表(skiplist)是一种有序数据结构, 它通过在每个节点中维持多个指向其他节点的指针, 从而达到快速访问节点的目的。
在大部分情况下, 跳跃表的效率可以和平衡树相媲美, 并且因为跳跃表的实现比平衡树要来得更为简单, 所以有不少程序都使用跳跃表来代替平衡树。redis使用跳跃表作为有序集合键的底层实现之一: 如果一个有序集合包含的元素数量比较多, 又或者有序集合中元素的成员(member)是比较长的字符串时, redis 就会使用跳跃表来作为有序集合键的底层实现。
redis 只在两个地方用到了跳跃表, 一个是实现有序集合键, 另一个是在集群节点中用作内部数据结构, 除此之外, 跳跃表在 redis 里面没有其他用途。
1.4.1 数据结构定义
跳跃表的节点:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
robj *obj; //节点所保存的成员对象
double score; //分值,节点按各自所保存的分值从小到大排列
struct zskiplistNode *backward; //指向当前节点中的前一个节点
struct zskiplistLevel {
struct zskiplistNode *forward; //当前层指向的下一个节点
unsigned int span; //当前层所指向节点和下一个节点之间的距离
} level[]; //层的数组,每个节点可能包含多个层
} zskiplistNode;
跳跃表管理控制节点:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //分别为跳跃表的头结点和尾节点
unsigned long length; //记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
int level; //记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
} zskiplist;
跳跃表简单的就理解成一个双向链表的升级版,和双向链表不同的地方便是,每个节点包含多个forward指针而已。
zset实现:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
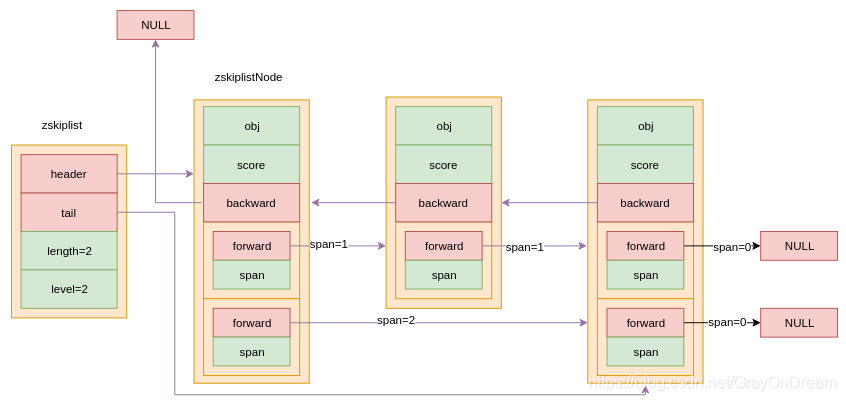
1.4.2 相关API
| 函数 | 功能 | 时间复杂度 |
|---|---|---|
| zslCreate | 创建一个新的跳跃表。 | O(1) |
| zslFree | 释放给定跳跃表,以及表中包含的所有节点。 | O(N) , N 为跳跃表的长度。 |
| zslInsert | 将包含给定成员和分值的新节点添加到跳跃表中。 | 平均 O(N) , N 为跳跃表长度。 |
| zslDelete | 删除跳跃表中包含给定成员和分值的节点。 | 平均 O(N) , N 为跳跃表长度。 |
| zslGetRank | 返回包含给定成员和分值的节点在跳跃表中的排位。 | 平均 O(N) , N 为跳跃表长度。 |
| zslGetElementByRank | 返回跳跃表在给定排位上的节点。 | 平均 O(N) , N 为跳跃表长度。 |
| zslIsInRange | 给定一个分值范围(range), 比如 0 到 15 , 20 到 28,诸如此类, 如果给定的分值范围包含在跳 | 跃表的分值范围之内, 那么返回 1 ,否则返回 0 。 |
| zslFirstInRange | 给定一个分值范围, 返回跳跃表中第一个符合这个范围的节点。 | 平均 O(N) 。 N 为跳跃表长度。 |
| zslLastInRange | 给定一个分值范围, 返回跳跃表中最后一个符合这个范围的节点。 | 平均 O(N) 。 N 为跳跃表长度。 |
| zslDeleteRangeByScore | 给定一个分值范围, 删除跳跃表中所有在这个范围之内的节点。 | O(N) , N 为被删除节点数 |
| zslDeleteRangeByRank | 给定一个排位范围, 删除跳跃表中所有在这个范围之内的节点。 | O(N) , N 为被删除节点数 |
1.4.3 其他
- 每个跳跃表节点的层高都是 1 至 32 之间的随机数;
- 在同一个跳跃表中, 多个节点可以包含相同的分值, 但每个节点的成员对象必须是唯一的;
- 跳跃表中的节点按照分值大小进行排序, 当分值相同时, 节点按照成员对象的大小进行排序。
1.5 整数集合
整数集合(intset)是 redis 用于保存整数值的集合抽象数据结构, 它可以保存类型为 int16_t 、 int32_t 或者 int64_t 的整数值, 并且保证集合中不会出现重复元素。整数集合是集合键的底层实现之一。
1.5.1 数据结构定义
typedef struct intset {
uint32_t encoding; //编码方式
uint32_t length; //集合包含元素的数量
int8_t contents[]; //保存元素的数组
} intset;
虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组, 但实际上 contents 数组并不保存任何 int8_t 类型的值 —— contents 数组的真正类型取决于 encoding 属性的值。
| 编码 | 类型 |
|---|---|
| INTSET_ENC_INT16 | int16_t |
| INTSET_ENC_INT32 | int32_t |
| INTSET_ENC_INT64 | int64_t |
1.5.2 相关API
| 函数 | 功能 | 时间复杂度 |
|---|---|---|
| intsetNew | 创建一个新的整数集合。 | O(1) |
| intsetAdd | 将给定元素添加到整数集合里面。 | O(N) |
| intsetRemove | 从整数集合中移除给定元素。 | O(N) |
| intsetFind | 检查给定值是否存在于集合。 | 因为底层数组有序,查找可以通过二分查找法来进行, 所以复杂度为 O(\log N) 。 |
| intsetRandom | 从整数集合中随机返回一个元素。 | O(1) |
| intsetGet | 取出底层数组在给定索引上的元素。 | O(1) |
| intsetLen | 返回整数集合包含的元素个数。 | O(1) |
| intsetBlobLen | 返回整数集合占用的内存字节数。 | O(1) |
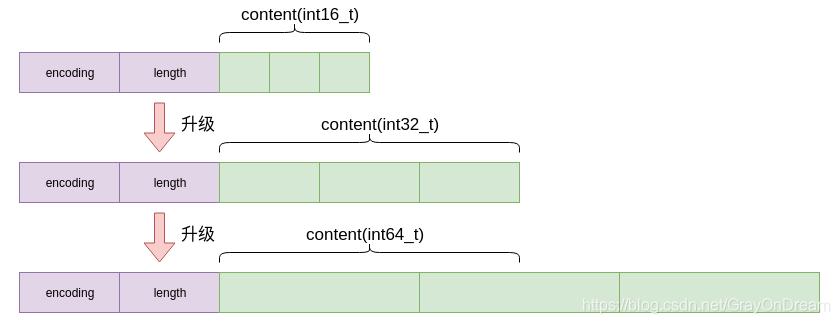
1.5.3 升级
升级:
每当我们要将一个新元素添加到整数集合里面, 并且新元素的类型比整数集合现有所有元素的类型都要长时, 整数集合需要先进行升级(upgrade), 然后才能将新元素添加到整数集合里面。
升级的基本三个步骤为:
- 根据新元素的类型, 扩展整数集合底层数组的空间大小, 并为新元素分配空间;
- 将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素放置到正确的位上, 而且在放置元素的过程中, 需要继续维持底层数组的有序性质不变;
- 将新元素添加到底层数组里面。
降级:整数集合不支持降级操作, 一旦对数组进行了升级, 编码就会一直保持升级后的状态。
升级的优点:
- 提升灵活性;
- 节约内存。
1.6 压缩列表
压缩列表是 redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry), 每个节点可以保存一个字节数组或者一个整数值。压缩列表是一种为节约内存而开发的顺序型数据结构。压缩列表被用作列表键和哈希键的底层实现之一。
1.6.1 数据结构定义
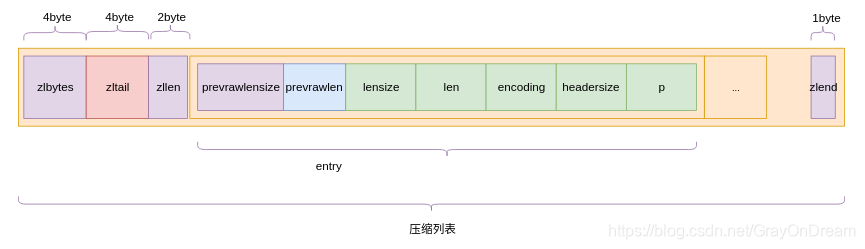
压缩列表中不同字段的含义:
zlbytes:占4字节,记录整个列表占用内存字节数;zltail:占4字节,记录 压缩列表尾节点距离起始位置地址偏移zllen:占2字节,记录压缩列表的节点数量;- 当
zllen<UINT16_MAX(65535),该值等于节点数; - 当
zllen==UINT16_MAX,需要遍历整个压缩列表才能得到节点数;
- 当
entry:列表节点,不固定;zlen:占1字节,使用0xff标记压缩列表的结尾。
/* Return total bytes a ziplist is composed of. */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
/* Return the offset of the last item inside the ziplist. */
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
/* Return the length of a ziplist, or UINT16_MAX if the length cannot be
* determined without scanning the whole ziplist. */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
/* The size of a ziplist header: two 32 bit integers for the total
* bytes count and last item offset. One 16 bit integer for the number
* of items field. */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
/* Size of the "end of ziplist" entry. Just one byte. */
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
/* Return the pointer to the first entry of a ziplist. */
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
/* Return the pointer to the last entry of a ziplist, using the
* last entry offset inside the ziplist header. */
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
/* Return the pointer to the last byte of a ziplist, which is, the
* end of ziplist FF entry. */
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;

压缩列表节点不同字段的含义:
prevrawlensize:占4字节,存储当前节点的前一个节点的长度字段占用字节长度,可能为1或者5;prevrawlen:占4个字节,前一个节点的长度;- 占用字节可以使1或者5字节:
- 当前一节点的长度小于254字节时,该属性占用1字节;
- 当前一字节的长度大于等于254字节时,该属性占用5字节,且第一个字节设置为
0xfe,后四个字节存储长度;
lensize:占4个字节,存储encoding字段的长度;len:占4个字节,表示当前节点数据内容的长度;headersize:占4个字节,prevrawlensize + lensize;encoding:占1个字节,表示数据类型,可选为ZIP_STR_,ZIP_INT_;- 字节数组编码,1、2或者5字节,值的最高位为
00、01或者10,去除最高位的两位为数据的长度; - 整数值,1字节,最高位为
11,去除最高位的两位为数据的长度;11000000:int16_t;11010000:int32_t;11100000:int64_t;11110000:24位有符号数;11111110:8位有符号数;
- 字节数组编码,1、2或者5字节,值的最高位为
p:数据域。
#define ZIP_STR_MASK 0xc0
#define ZIP_INT_MASK 0x30
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
#define ZIP_INT_16B (0xc0 | 0<<4)
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe
解压Entry:
void zipEntry(unsigned char *p, zlentry *e) {
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
e->headersize = e->prevrawlensize + e->lensize;
e->p = p;
}
/* Return the length of the previous element, and the number of bytes that
* are used in order to encode the previous element length.
* 'ptr' must point to the prevlen prefix of an entry (that encodes the
* length of the previous entry in order to navigate the elements backward).
* The length of the previous entry is stored in 'prevlen', the number of
* bytes needed to encode the previous entry length are stored in
* 'prevlensize'. */
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
(prevlen) = (ptr)[0]; \
} else if ((prevlensize) == 5) { \
assert(sizeof((prevlen)) == 4); \
memcpy(&(prevlen), ((char*)(ptr)) + 1, 4); \
memrev32ifbe(&prevlen); \
} \
} while(0);
/* Decode the entry encoding type and data length (string length for strings,
* number of bytes used for the integer for integer entries) encoded in 'ptr'.
* The 'encoding' variable will hold the entry encoding, the 'lensize'
* variable will hold the number of bytes required to encode the entry
* length, and the 'len' variable will hold the entry length. */
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
if ((encoding) < ZIP_STR_MASK) { \
if ((encoding) == ZIP_STR_06B) { \
(lensize) = 1; \
(len) = (ptr)[0] & 0x3f; \
} else if ((encoding) == ZIP_STR_14B) { \
(lensize) = 2; \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \
} else if ((encoding) == ZIP_STR_32B) { \
(lensize) = 5; \
(len) = ((ptr)[1] << 24) | \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
panic("Invalid string encoding 0x%02X", (encoding)); \
} \
} else { \
(lensize) = 1; \
(len) = zipIntSize(encoding); \
} \
} while(0);
1.6.2 相关API
| 函数 | 功能 | 时间复杂度 |
|---|---|---|
| ziplistNew | 创建一个新的压缩列表。 | O(1) |
| ziplistPush | 创建一个包含给定值的新节点, 并将这个新节点添加到压缩列表的表头或者表尾。 | 平均 O(N^2) 。 |
| ziplistInsert | 将包含给定值的新节点插入到给定节点之后。 | 平均 O(N^2) 。 |
| ziplistIndex | 返回压缩列表给定索引上的节点。 | O(N) |
| ziplistFind | 在压缩列表中查找并返回包含了给定值的节点。 | 因为节点的值可能是一个字节数 |
| ziplistNext | 返回给定节点的下一个节点。 | O(1) |
| ziplistPrev | 返回给定节点的前一个节点。 | O(1) |
| ziplistGet | 获取给定节点所保存的值。 | O(1) |
| ziplistDelete | 从压缩列表中删除给定的节点。 | 平均 O(N^2) 。 |
| ziplistDeleteRange | 删除压缩列表在给定索引上的连续多个节点。 | 平均 O(N^2) 。 |
| ziplistBlobLen | 返回压缩列表目前占用的内存字节数。 | O(1) |
| ziplistLen | 返回压缩列表目前包含的节点数量。 | 节点数量小于 65535 时 O(1) 。 |
1.6.3 连锁更新
之前说过,redis的中的prevrawlen保存的是上一个节点的长度,当节点长度不同时,该字段占用的字节数也不同,也就是说由于添加数据,删除数据导致之前的节点长度的变化也会到后续节点的长度。此时需要对多个节点的prevrawlen进行更新,即连锁更新。
因为连锁更新在最坏情况下需要对压缩列表执行 N 次空间重分配操作, 而每次空间重分配的最坏复杂度为 O(N^2) 。
要注意的是, 尽管连锁更新的复杂度较高, 但它真正造成性能问题的几率是很低的:
- 首先, 压缩列表里要恰好有多个连续的、长度介于 250 字节至 253 字节之间的节点, 连锁更新才有可能被引发, 在实际中, 这种情况并不多见;
- 其次, 即使出现连锁更新, 但只要被更新的节点数量不多, 就不会对性能造成任何影响: 比如说, 对三五个节点进行连锁更新是绝对不会影响性能的。
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize;
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
while (p[0] != ZIP_END) {
zipEntry(p, &cur);
rawlen = cur.headersize + cur.len;
rawlensize = zipStorePrevEntryLength(NULL,rawlen);
/* Abort if there is no next entry. */
if (p[rawlen] == ZIP_END) break;
zipEntry(p+rawlen, &next);
/* Abort when "prevlen" has not changed. */
if (next.prevrawlen == rawlen) break;
if (next.prevrawlensize < rawlensize) {
/* The "prevlen" field of "next" needs more bytes to hold
* the raw length of "cur". */
offset = p-zl;
extra = rawlensize-next.prevrawlensize;
zl = ziplistResize(zl,curlen+extra);
p = zl+offset;
/* Current pointer and offset for next element. */
np = p+rawlen;
noffset = np-zl;
/* Update tail offset when next element is not the tail element. */
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
/* Move the tail to the back. */
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
zipStorePrevEntryLength(np,rawlen);
/* Advance the cursor */
p += rawlen;
curlen += extra;
} else {
if (next.prevrawlensize > rawlensize) {
/* This would result in shrinking, which we want to avoid.
* So, set "rawlen" in the available bytes. */
zipStorePrevEntryLengthLarge(p+rawlen,rawlen);
} else {
zipStorePrevEntryLength(p+rawlen,rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
break;
}
}
return zl;
}
1.7 压缩字典
zipmap利用字符串实现了一个简单的hash_table结构,又通过固定的字节表示节省空间。zipmap和前面介绍的ziplist结构十分类似。
1.7.1 数据结构定义

各个字段的含义:
zmlen:占1个字节,表示当前键值对的数量;- 当
zmlen<254时,表示键值对数量; - 当
zmlen>=254时,只能通过遍历确定大小
- 当
- 键值对:
key_len:编码类似ziplist,可以是1个或者5个字节:- 1个字节,
key的长度小于254; - 5个字节,
key的长度大于等于254;
- 1个字节,
key:键;value_len:编码类似ziplist,可以是1个或者5个字节:- 1个字节,
value的长度小于254; - 5个字节,
value的长度大于等于254;
- 1个字节,
free:占1个字节,表示value后的空闲长度;value:值;
end:占用1个字节,借位字符,值为0xff。
1.7.2 相关API
| 函数 | 功能 | 时间复杂度 |
|---|---|---|
| zipmapNew | 创建空的zipmap | O(1) |
| zipmapLookupRaw | 查找目标键对应的value | O(n) |
| zipmapSet | 插入键值对,如果存在就更新 | O(n) |
| zipmapExists | 判断键是否存在 | O(n) |
1.8 快速链表
quicklist是redis3.2中引入的新结构,能够在时间效率和空间效率间实现较好的折中。quicklist是一个双向链表,链表中的每个节点都是一个ziplist结构,quicklist可以看成是将双向链表将若干个小型的ziplist组合在一起的数据结构。当ziplist节点个数较多的时候,quicklist退化成双向链表,一个极端的情况就是每个ziplist节点只有一个entry,即只有一个元素。当ziplist元素较少的时候,quicklist可以退化成ziplist,另一种极端的情况就是,整个quicklist中只有一个ziplist节点。
1.8.1 数据结构定义
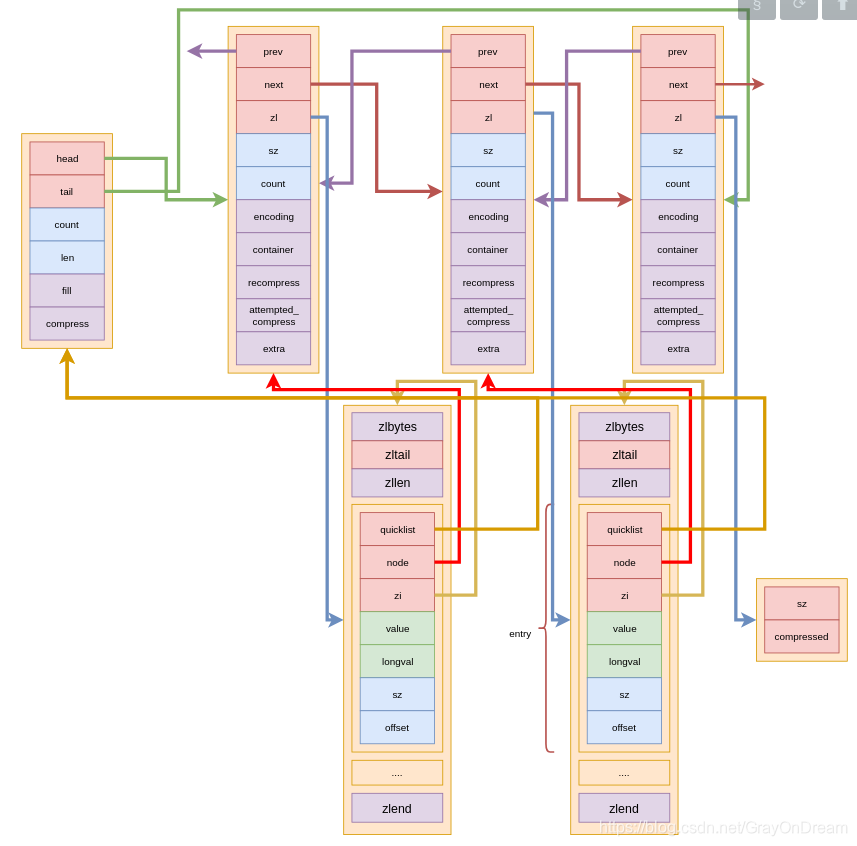
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
各个字段的含义:
head:占一个机器长度,指向头结点;tail:占一个机器长度,指向尾节点;count:占4个字节,压缩列表中的entry的数量;count:占4个字节,节点数量;fill:占16位,- 正数,表示每个ziplist最多包含的数据项数;
- 负数:
- -1,ziplist节点最大为4kb;
- -2,ziplist节点最大为8kb;
- -3,ziplist节点最大为16kb;
- -4,ziplist节点最大为32kb;
- -5,ziplist节点最大为64kb;
compress:占16位,快速列表末尾不进行压缩的节点数。
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
各个字段的含义:
prev:上一个节点的指针;next:下一个节点的指针zl:指向元素;sz:占4个字节,ziplist的大小count:占16bit,ziplist中的entry数量;encoding:占2bit,编码方式RAW:原生编码;LZF:LZF压缩编码;
container:占2bit,zl指向的容器类型:NONE:none;ZIPLIST:ziplist;
recompress:1bit,当前节点是否进过压缩;attempted_compress:1bit,测试时使用;extra:10bit,预留字段
LZF压缩格式:
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
不同字段的含义:
sz:当前字段的长度;compressed:压缩后的数据。
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
unsigned char *zi;
unsigned char *value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;
压缩列表中的元素结构,各个字段的含义:
quicklist:node:指向当前元素所在的node;zi:指向当前元素所在的ziplist;value:当前节点的字符串内容;longval:当前节点的数值内容;sz:节点大小;offset:大年节点相对于ziplist的偏移量,即当前节点是第几个entry
1.8.2 常用API
| 函数名称 | 功能 | 时间复杂度 |
|---|---|---|
| quicklistCreate | 创建默认quicklist | O(1) |
| quicklistNew | 创建自定义属性quicklist | O(1) |
| quicklistPushHead | 在头部插入数据 | O(m) |
| quicklistPushTail | 在尾部插入数据 | O(m) |
| quicklistPush | 在头部或者尾部插入数据 | O(m) |
| quicklistInsertAfter | 在某个元素后面插入数据 | O(m) |
| quicklistInsertBefore | 在某个元素前面插入数据 | O(m) |
| quicklistDelEntry | 删除某个元素 | O(m) |
| quicklistDelRange | 删除某个区间的所有元素 | O(1/m+ m) |
| quicklistPop | 弹出头部或者尾部元素 | O(m) |
| quicklistReplaceAtIndex | 替换某个元素 | O(m) |
| quicklistIndex | 获取某个位置的元素 | O(n+m) |
| quicklistGetIterator | 获取指向头部或尾部的迭代器 | O(1) |
| quicklistGetIteratorAtIdx | 获取特定位置的迭代器 | O(n+m) |
| quicklistNext | 获取迭代器下一个元素 | O(m) |
1.8.3 数据压缩
压缩:
quicklist每个节点的实际数据存储结构为ziplist,这种结构的主要优势在于节省内存空间。为了进一步降低ziplist占用空间,redis允许对ziplist再进行一次压缩,redis采用的压缩算法是LZF,压缩后数据可以分为多个片段,每个片段可以分为解释字段和数据字段:
- 解释字段:占用1~3个字节;
- 数据字段:可能不存在。
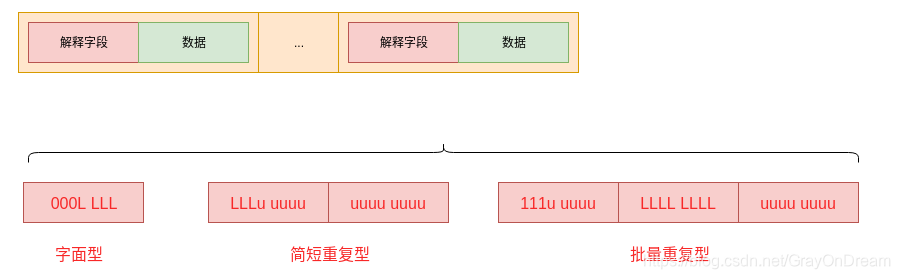
LZF数据压缩的基本思想是:数据与前面重复的,记录重复位置以及重复长度,否则直接记录原始数据内容。基本步骤如下:
- 遍历输入字符串,对当前字符及其后面2个字符进行散列运算;
- 如果在Hash表中找到曾出现的记录,则计算重复字节的长度以及位置,反之直接输出数据。
LZF压缩的数据格式有三种:
- 字面型:解释字段占用1个字节,数据字段的长度等于一个字节的低5位
LLLLL内容+1; - 简短重复型:解释字段占用2个字节,没有数据字段,数据内容与前面的数据重复,重复长度小于8。重复长度等于两个字节中第一个字节的高三位
LLL组成的字面值+2,重复开始偏移量等于第一个字节的低5位和第二个字节组成的数+1; - 批量重复型:解释字段占用3个字节,没有数据字段,数据与前面的内容重复。长度是第二个字节
LLLL LLLL组成的字面量+9,偏移量为所有u组成的字面量+1(有疑问:TODO:)
解压缩:
根据LZF压缩后的数据格式,我们可以较为容易地实现LZF的解压缩。值得注意的是,可能存在重复数据与当前位置重叠的情况,例如在当前位置前的15个字节处,重复了20个字节,此时需要按位逐个复制。
1.9 radix树
radix Tree(基数树) 事实上就几乎相同是传统的二叉树。仅仅是在寻找方式上。利用比方一个unsigned int的类型的每个比特位作为树节点的推断。redis实现了不定长压缩前缀的radix tree,用在集群模式下存储slot对应的的所有key信息。
1.9.1 数据结构定义
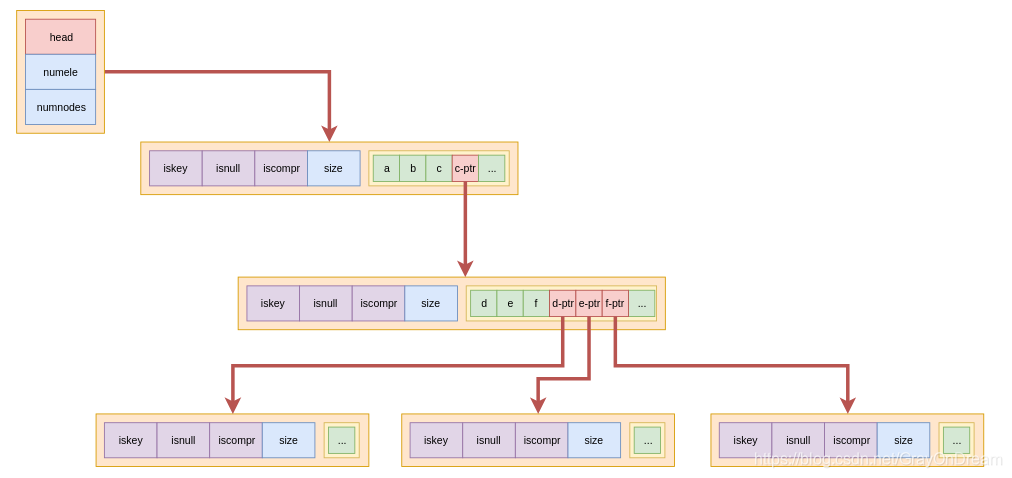
#define RAX_NODE_MAX_SIZE ((1<<29)-1)
typedef struct raxNode {
uint32_t iskey:1; /* Does this node contain a key? */
uint32_t isnull:1; /* Associated value is NULL (don't store it). */
uint32_t iscompr:1; /* Node is compressed. */
uint32_t size:29; /* Number of children, or compressed string len. */
unsigned char data[];
} raxNode;
各个元素的含义:
iskey:这个节点是够包含key;0:没有key;1:表示从头部到其父节点的路径完整的存储了key,查找的时候按子节点iskey=1来判断key是否存在;
isnull:是否有存储value值;iscompr:是否有前缀压缩,决定了data存储的数据结构;0:有size个字符,size个子节点;1:只有一个子节点
size:孩子个数或者该节点存储的字符个数;data:存储子节点的信息。
typedef struct rax {
raxNode *head; //头结点指针
uint64_t numele; //元素数量
uint64_t numnodes; //节点数量
} rax;
TODO:
1.10 对象
redis 并没有直接使用之前提到的数据结构来实现键值对数据库, 而是基于这些数据结构创建了一个对象系统, 这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象, 每种对象都用到了至少一种前面所介绍的数据结构。
1.10.1 不同的对象类型
1.10.1.1 基本的对象结构
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
/* The actual redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
#define OBJ_MODULE 5 /* Module object. */
#define OBJ_STREAM 6 /* Stream object. */
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
不同字段的含义:
type:占4个字节,表明对象的类型:OBJ_STRING:字符串对象;OBJ_LIST:列表对象;OBJ_SET:集合对象;OBJ_ZSET:有序集合对象;OBJ_HASH:哈希对象;
encoding:占4个字节,表明对象所使用的数据结构,即底层实现:OBJ_ENCODING_RAW:动态字符串;OBJ_ENCODING_INT:整数;OBJ_ENCODING_HT:哈希表;OBJ_ENCODING_ZIPMAP:压缩字典OBJ_ENCODING_LINKEDLIST:双向链表;OBJ_ENCODING_ZIPLIST:压缩表;OBJ_ENCODING_INTSET:整数集合;OBJ_ENCODING_SKIPLIST:跳跃表;OBJ_ENCODING_EMBSTR:embstr 编码的简单动态字符串;OBJ_ENCODING_QUICKLIST:快速链表;OBJ_ENCODING_STREAM:流,使用基数树实现
lru:占22bit,记录最后一次被命令程序访问的时间;refcount:占4个字节,引用计数;ptr:数据域,指向低层实现数据结构
通过 encoding 属性来设定对象所使用的编码, 而不是为特定类型的对象关联一种固定的编码, 极大地提升了 redis 的灵活性和效率, 因为 redis 可以根据不同的使用场景来为一个对象设置不同的编码, 从而优化对象在某一场景下的效率。
1.10.1.2 字符串对象
1.10.1.2.1 实现
从上面可以看到字符串对象可选编码分别为OBJ_ENCODING_RAW,OBJ_ENCODING_INT,OBJ_ENCODING_EMBSTR分别对应int,raw,embstr。
int:如果字符串为整数值,并且这个整数可以通过long类型表示,直接将数据域void*转换成long,并把字符串对象的编码设置为OBJ_ENCODING_INT;raw:如果给定的字符串长度大于39字节,则使用简单字符串(SDS)保存,编码设置为OBJ_ENCODING_RAW;emstr:如果字符串的长度小于等于39字节,则使用embstr编码进行保存,并且编码设置为OBJ_ENCODING_EMBSTR。
raw和embstr本质上是一样的,不相同的地方是:embstr是对raw的优化,从结构上来说完全相同,但是实现上embstr第一次申请内存时,直接申请sizeof(redis_object)+sizeof(sdshdr)大小的内存,再进行重新解释。
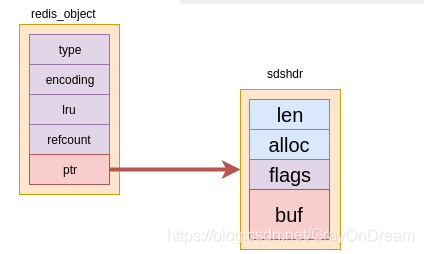
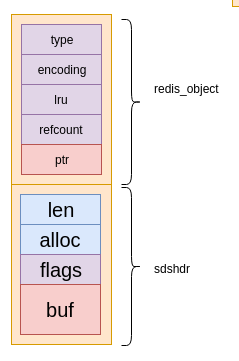
这样做的优点有:
embstr申请和释放空间只需要调用一次malloc或者free,而raw需要两次;embstr的内存是一块连续的内存对缓存更加友好。
需要注意的是redis中
long double是直接使用字符串存储的。
int,embstr编码在满足相关条件下会被转换成raw编码。
redis没有为
embstr提供相应的修改程序,实际上embstr是只读的,如果需要修改redis内部会先将embstr转换成raw。因此对embstr进行修改之后,编码就变成raw。
字符串对象是 redis 五种类型的对象中唯一一种会被其他四种类型对象嵌套的对象。
1.10.1.2.2 命令实现
| 命令 | int 编码的实现方法 | embstr 编码的实现方法 | raw 编码的实现方法 |
|---|---|---|---|
| SET | 使用 int 编码保存值。 | 使用 embstr 编码保存值。 | 使用 raw 编码保存值。 |
| GET | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后向客户端返回这个字符串值。 | 直接向客户端返回字符串值。 | 直接向客户端返回字符串值。 |
| APPEND 将对象转换成 raw 编码, 然后按raw 编码的方式执行此操作。 | 将对象转换成 raw 编 | 码, 然后按raw 编码的方式执行此操作。 | 调用 sdscatlen 函数, 将给定字符串追加到现有字符串的末尾。 |
| INCRBYFLOAT | 取出整数值并将其转换成 longdouble 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 | 取出字符串值并尝试将其转换成long double 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 | 取出字符串值并尝试将其转换成 longdouble 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 |
| INCRBY | 对整数值进行加法计算, 得出的计算结果会作为整数被保存起来。 | embstr 编码不能执行此 | 命令, 向客户端返回一个错误。 |
| DECRBY | 对整数值进行减法计算, 得出的计算结果会作为整数被保存起来。 embstr 编码不能执行此 | 命令, 向客户端返回一个错误。 | raw 编码不能执行此命令, 向客户端返回一个错误。 |
| STRLEN | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 计算并返回这个字符串值的长度。 | 调用 sdslen 函数, 返回字符串的长度。 | 调用 sdslen 函数, 返回字符串的长度。 |
| SETRANGE | 将对象转换成 raw 编码, 然后按raw 编码的方式执行此命令。 | 将对象转换成 raw | 编码, 然后按raw 编码的方式执行此命令。 |
| GETRANGE | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 |
1.10.1.3 列表对象
1.10.1.3.1实现原理
列表对象的编码可以使ziplist,linkedlist。
ziplist作为低层实现时,每个压缩列表节点(entry)保存了一个列表元素。
linkedlist编码的列表对象使用双端链表作为底层实现, 每个双端链表节点(node)都保存了一个字符串对象, 而每个字符串对象都保存了一个列表元素。
编码转换:
当列表对象满足如下两个条件时,列表对象使用ziplist:
- 列表对象保存的所有字符串元素的长度都小于 64 字节;
- 列表对象保存的元素数量小于 512 个。
否则,列表对象使用linkedlist编码。
以上两个条件的上限值是可以修改的, 具体请看配置文件中关于 list-max-ziplist-value 选项和 list-max-ziplist-entries 选项的说明。
1.10.1.3.2 命令实现
| 命令 | ziplist 编码的实现方法 | linkedlist 编码的实现方法 |
|---|---|---|
| LPUSH | 调用 ziplistPush 函数, 将新元素推入到压缩列表的表头。 | 调用 listAddNodeHead 函数, 将新元素推入到双端链表的表头。 |
| RPUSH | 调用 ziplistPush 函数, 将新元素推入到压缩列表的表尾。 | 调用 listAddNodeTail 函数, 将新元素推入到双端链表的表尾。 |
| LPOP | 调用 ziplistIndex 函数定位压缩列表的表头节点, 在向用户返回节点所保存的元素之后, 调用ziplistDelete 函数删除表头节点。 | 调用 listFirst 函数定位双端链表的表头节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表头节点。 |
| RPOP | 调用 ziplistIndex 函数定位压缩列表的表尾节点, 在向用户返回节点所保存的元素之后, 调用ziplistDelete 函数删除表尾节点。 | 调用 listLast 函数定位双端链表的表尾节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表尾节点。 |
| LINDEX | 调用 ziplistIndex 函数定位压缩列表中的指定节点, 然后返回节点所保存的元素。 | 调用 listIndex 函数定位双端链表中的指定节点, 然后返回节点所保存的元素。 |
| LLEN | 调用 ziplistLen 函数返回压缩列表的长度。 | 调用 listLength 函数返回双端链表的长度。 |
| LINSERT | 插入新节点到压缩列表的表头或者表尾时, 使用ziplistPush 函数; 插入新节点到压缩列表的其他位置时, 使用 ziplistInsert 函数。 | 调用 listInsertNode 函数, 将新节点插入到双端链表的指定位置。 |
| LREM | 遍历压缩列表节点, 并调用 ziplistDelete 函数删除包含了给定元素的节点。 遍历双端链表节点, 并调用 | listDelNode 函数删除包含了给定元素的节点。 |
| LTRIM | 调用 ziplistDeleteRange 函数, 删除压缩列表中所有不在指定索引范围内的节点。 | 遍历双端链表节点, 并调用 listDelNode 函数删除链表中所有不在指定索引范围内的节点。 |
| LSET | 调用 ziplistDelete 函数, 先删除压缩列表指定索引上的现有节点, 然后调用 ziplistInsert 函数, 将一个包含给定元素的新节点插入到相同索引上面。 | 调用 listIndex 函数, 定位到双端链表指定索引上的节点, 然后通过赋值操作更新节点的值。 |
1.10.1.4 哈希对象
1.10.1.4.1 实现原理
哈希对象的编码可以是 ziplist或者 hashtable即字典 。
ziplist编码的哈希对象使用压缩列表作为底层实现, 每当有新的键值对要加入到哈希对象时, 程序会先将保存了键的压缩列表节点推入到压缩列表表尾, 然后再将保存了值的压缩列表节点推入到压缩列表表尾, 因此:
- 保存了同一键值对的两个节点总是紧挨在一起, 保存键的节点在前, 保存值的节点在后;
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向, 而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
hashtable编码的哈希对象使用字典作为底层实现, 哈希对象中的每个键值对都使用一个字典键值对来保存:
- 字典的每个键都是一个字符串对象, 对象中保存了键值对的键;
- 字典的每个值都是一个字符串对象, 对象中保存了键值对的值。
编码转换:
当哈希对象可以同时满足以下两个条件时, 哈希对象使用 ziplist编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节;
- 哈希对象保存的键值对数量小于 512 个。
否则使用hashtable编码。
这两个条件的上限值是可以修改的, 具体请看配置文件中关于
hash-max-ziplist-value选项和hash-max-ziplist-entries选项的说明。
1.10.1.4.2 命令实现
| 命令 | ziplist 编码实现方法 | hashtable 编码的实现方法 |
|---|---|---|
| HSET 首先调用 ziplistPush 函数, 将键推入到压缩列表的表尾, 然后再次调用 | ziplistPush 函数, 将值推入到压缩列表的表尾。 | 调用 dictAdd 函数, 将新节点添加到字典里面。 |
| HGET | 首先调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 然后调用 ziplistNext 函数, 将指针移动到键节点旁边的值节点, 最后返回值节点。 | 调用 dictFind 函数, 在字典中查找给定键, 然后调用dictGetVal 函数, 返回该键所对应的值。 |
| HEXISTS | 调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 如果找到的话说明键值对存在, 没找到的话就说明键值对不存在。 | 调用 dictFind 函数, 在字典中查找给定键, 如果找到的话说明键值对存在, 没找到的话就说明键值对不存在。 |
| HDEL | 调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 然后将相应的键节点、 以及键节点旁边的值节点都删除掉。 | 调用 dictDelete 函数, 将指定键所对应的键值对从字典中删除掉。 |
| HLEN | 调用 ziplistLen 函数, 取得压缩列表包含节点的总数量, 将这个数量除以 2 , 得出的结果就是压缩列表保存的键值对的数量。 | 调用 dictSize 函数, 返回字典包含的键值对数量, 这个数量就是哈希对象包含的键值对数量。 |
| HGETALL | 遍历整个压缩列表, 用 ziplistGet 函数返回所有键和值(都是节点)。 | 遍历整个字典, 用 dictGetKey 函数返回字典的键, 用dictGetVal 函数返回字典的值。 |
1.10.1.5 集合对象
1.10.1.5.1 实现原理
集合对象的编码可以是intset或者 hashtable。
intset编码的集合对象使用整数集合作为底层实现, 集合对象包含的所有元素都被保存在整数集合里面。
hashtable编码的集合对象使用字典作为底层实现, 字典的每个键都是一个字符串对象, 每个字符串对象包含了一个集合元素, 而字典的值则全部被设置为 NULL。
编码转换:
当集合对象可以同时满足以下两个条件时, 对象使用 intset编码:
- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过 512 个。
不能满足这两个条件的集合对象需要使用 hashtable编码。
第二个条件的上限值是可以修改的, 具体请看配置文件中关于 set-max-intset-entries 选项的说明。
1.10.1.5.2 命令实现
| 命令 | intset 编码的实现方法 | hashtable 编码的实现方法 |
|---|---|---|
| SADD | 调用 intsetAdd 函数, 将所有新元素添加到整数集合里面。 | 调用 dictAdd , 以新元素为键, NULL 为值, 将键值对添加到字典里面。 |
| SCARD | 调用 intsetLen 函数, 返回整数集合所包含的元素数量, 这个数量就是集合对象所包含的元素数 | 量。 调用 dictSize 函数, 返回字典所包含的键值对数量, 这个数量就是集合对象所包含的元素数量。 |
| SISMEMBER | 调用 intsetFind 函数, 在整数集合中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 | 调用 dictFind 函数, 在字典的键中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 |
| SMEMBERS | 遍历整个整数集合, 使用 intsetGet 函数返回集合元素。 | 遍历整个字典, 使用 dictGetKey 函数返回字典的键作为集合元素。 |
| SRANDMEMBER | 调用 intsetRandom 函数, 从整数集合中随机返回一个元素。 | 调用 dictGetRandomKey 函数, 从字典中随机返回一个字典键。 |
| SPOP | 调用 intsetRandom 函数, 从整数集合中随机取出一个元素, 在将这个随机元素返回给客户端之后, 调用 intsetRemove 函数, 将随机元素从整数集合中删除掉。 | 调用 dictGetRandomKey 函数, 从字典中随机取出一个字典键, 在将这个随机字典键的值返回给客户端之后, 调用dictDelete 函数, 从字典中删除随机字典键所对应的键值对。 |
| SREM | 调用 intsetRemove 函数, 从整数集合中删除所有给定的元素。 | 调用 dictDelete 函数, 从字典中删除所有键为给定元素的键值对。 |
1.10.1.6 有序集合对象
1.10.1.6.1 实现原理
有序集合的编码可以是 ziplist或者 skiplist。
ziplist编码的有序集合对象使用压缩列表作为底层实现, 每个集合元素使用两个紧挨在一起的压缩列表节点来保存, 第一个节点保存元素的成员(member), 而第二个元素则保存元素的分值(score)。
压缩列表内的集合元素按分值从小到大进行排序, 分值较小的元素被放置在靠近表头的方向, 而分值较大的元素则被放置在靠近表尾的方向。
skiplist编码的有序集合对象使用 zset结构作为底层实现, 一个 zset结构同时包含一个字典和一个跳跃表:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
其中zsl跳跃表按分值从小到大保存了所有集合元素, 每个跳跃表节点都保存了一个集合元素: 跳跃表节点的object属性保存了元素的成员, 而跳跃表节点的score属性则保存了元素的分值。 通过这个跳跃表, 程序可以对有序集合进行范围型操作。
其中dict字典为有序集合创建了一个从成员到分值的映射, 字典中的每个键值对都保存了一个集合元素: 字典的键保存了元素的成员, 而字典的值则保存了元素的分值。 通过这个字典, 程序可以用 O(1)复杂度查找给定成员的分值。
有序集合每个元素的成员都是一个字符串对象, 而每个元素的分值都是一个 double类型的浮点数。虽然zset同时使用了跳跃表和字典,但是两个结构是共享数据成员的,因此不会有重复成员或者分值,造成内存浪费。
当有序集合对象可以同时满足以下两个条件时, 对象使用 ziplist编码:
- 有序集合保存的元素数量小于 128 个;
- 有序集合保存的所有元素成员的长度都小于 64 字节。
否则有序集合对象将使用 skiplist编码。
以上两个条件的上限值是可以修改的, 具体请看配置文件中关于
zset-max-ziplist-entries选项和zset-max-ziplist-value选项的说明。
1.10.1.6.2 命令实现
| 命令 | ziplist 编码的实现方法 | zset 编码的实现方法 |
|---|---|---|
| ZADD | 调用 ziplistInsert 函数, 将成员和分值作为两个节点分别插入到压缩列表。 | 先调用 zslInsert 函数, 将新元素添加到跳跃表, 然后调用 dictAdd 函数, 将新元素关联到字典。 |
| ZCARD | 调用 ziplistLen 函数, 获得压缩列表包含节点的数量, 将这个数量除以 2 得出集合元素的数量。 | 访问跳跃表数据结构的 length 属性, 直接返回集合元素的数量。 |
| ZCOUNT | 遍历压缩列表, 统计分值在给定范围内的节点的数量。 | 遍历跳跃表, 统计分值在给定范围内的节点的数量。 |
| ZRANGE | 从表头向表尾遍历压缩列表, 返回给定索引范围内的所有元素。 | 从表头向表尾遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZREVRANGE | 从表尾向表头遍历压缩列表, 返回给定索引范围内的所有元素。 | 从表尾向表头遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZRANK | 从表头向表尾遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 | 从表头向表尾遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREVRANK | 从表尾向表头遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 | 从表尾向表头遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREM | 遍历压缩列表, 删除所有包含给定成员的节点, 以及被删除成员节点旁边的分值节点。 | 遍历跳跃表, 删除所有包含了给定成员的跳跃表节点。 并在字典中解除被删除元素的成员和分值的关联。 |
| ZSCORE | 遍历压缩列表, 查找包含了给定成员的节点, 然后取出成员节点旁边的分值节点保存的元素分值。 | 直接从字典中取出给定成员的分值。 |
1.10.2 对象的使用和管理
1.10.2.1 类型检查和命令多态
redis 中用于操作键的命令基本上可以分为两种类型。
- 可以对任何类型的键执行, 比如说
DEL命令、EXPIRE命令、RENAME命令、TYPE命令、OBJECT命令, 等等。 - 只能对特定类型的键执行, 比如说:
SET、GET、APPEND、STRLEN等命令只能对字符串键执行;HDEL、HSET、HGET、HLEN等命令只能对哈希键执行;RPUSH、LPOP、LINSERT、LLEN等命令只能对列表键执行;SADD、SPOP、SINTER、SCARD等命令只能对集合键执行;ZADD、ZCARD、ZRANK、ZSCORE等命令只能对有序集合键执行。
类型特定命令所进行的类型检查是通过 redisObject 结构的 type 属性来实现的:
- 在执行一个类型特定命令之前, 服务器会先检查输入数据库键的值对象是否为执行命令所需的类型, 如果是的话, 服务器就对键执行指定的命令;
- 否则, 服务器将拒绝执行命令, 并向客户端返回一个类型错误。
多态命令的实现:
redis 除了会根据值对象的类型来判断键是否能够执行指定命令之外, 还会根据值对象的编码方式, 选择正确的命令实现代码来执行命令。本质上是检查编码和类型,比如下面部分代码:
if (o->type == OBJ_STRING) {
if(o->encoding == OBJ_ENCODING_INT) {
asize = sizeof(*o);
} else if(o->encoding == OBJ_ENCODING_RAW) {
asize = sdsAllocSize(o->ptr)+sizeof(*o);
} else if(o->encoding == OBJ_ENCODING_EMBSTR) {
asize = sdslen(o->ptr)+2+sizeof(*o);
} else {
serverPanic("Unknown string encoding");
}
} else if (o->type == OBJ_LIST) {
if (o->encoding == OBJ_ENCODING_QUICKLIST) {
quicklist *ql = o->ptr;
quicklistNode *node = ql->head;
asize = sizeof(*o)+sizeof(quicklist);
do {
elesize += sizeof(quicklistNode)+ziplistBlobLen(node->zl);
samples++;
} while ((node = node->next) && samples < sample_size);
asize += (double)elesize/samples*ql->len;
} else if (o->encoding == OBJ_ENCODING_ZIPLIST) {
asize = sizeof(*o)+ziplistBlobLen(o->ptr);
} else {
serverPanic("Unknown list encoding");
}
1.10.2.2 内存回收
C 语言并不具备自动的内存回收功能, 所以 redis 在自己的对象系统中构建了一个引用计数(reference counting)技术实现的内存回收机制, 通过这一机制, 程序可以通过跟踪对象的引用计数信息, 在适当的时候自动释放对象并进行内存回收。
- 在创建一个新对象时, 引用计数的值会被初始化为 1 ;
- 当对象被一个新程序使用时, 它的引用计数值会被增1;
- 当对象不再被一个程序使用时, 它的引用计数值会被减1;
- 当对象的引用计数值变为 0 时, 对象所占用的内存会被释放。
修改对象引用计数的 API:
| 函数 | 作用 |
|---|---|
| incrRefCount | 将对象的引用计数值增一。 |
| decrRefCount | 将对象的引用计数值减一, 当对象的引用计数值等于 0 时, 释放对象。 |
| resetRefCount | 将对象的引用计数值设置为 0 , 但并不释放对象, 这个函数通常在需要重新设置对象的引用计数值时使用。 |
1.10.2.3 对象共享
由于引用计数的存在,因此redis中的对象可以被多个数据共享使用,如果真的需要修改的时候再进行深拷贝,即copy-on-write。
当服务器考虑将一个共享对象设置为键的值对象时, 程序需要先检查给定的共享对象和键想创建的目标对象是否完全相同, 只有在共享对象和目标对象完全相同的情况下, 程序才会将共享对象用作键的值对象, 而一个共享对象保存的值越复杂, 验证共享对象和目标对象是否相同所需的复杂度就会越高, 消耗的 CPU 时间也会越多:
- 如果共享对象是保存整数值的字符串对象, 那么验证操作的复杂度为 O(1) ;
- 如果共享对象是保存字符串值的字符串对象, 那么验证操作的复杂度为 O(N) ;
- 如果共享对象是包含了多个值(或者对象的)对象, 比如列表对象或者哈希对象, 那么验证操作的复杂度将会是 O ( N 2 ) O(N^2) O(N2) 。
因此, 尽管共享更复杂的对象可以节约更多的内存, 但受到 CPU 时间的限制, redis 只对包含整数值的字符串对象进行共享。
目前来说, redis 会在初始化服务器时, 创建一万个字符串对象, 这些对象包含了从 0 到 9999 的所有整数值, 当服务器需要用到值为 0到 9999 的字符串对象时, 服务器就会使用这些共享对象, 而不是新创建对象。
创建共享字符串对象的数量可以通过修改 redis.h/OBJ_SHARED_INTEGERS 常量来修改。
1.10.2.4 对象的空转时长
除了引用计数,对象中的lru字段也会被用来记性对象的回收。
如果服务器打开了 maxmemory选项, 并且服务器用于回收内存的算法为 volatile-lru或者 allkeys-lru, 那么当服务器占用的内存数超过了 maxmemory选项所设置的上限值时, 空转时长较高的那部分键会优先被服务器释放, 从而回收内存。
2 单机数据库的实现
2.1 数据库
2.1.1 实现
/* redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
redis是一个键值对数据库服务器,每个数据库都是由上面的struct redisDb结构表示,其中dict字段是数据库所有的键值对空间。
- 键空间的键也就是数据库的键, 每个键都是一个字符串对象;
- 键空间的值也就是数据库的值, 每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象在内的任意一种 redis 对象。
因此在redis中对数据库中的数据进行添加,更新,删除等操作都是对该字典的操作。
当使用 redis 命令对数据库进行读写时, 服务器不仅会对键空间执行指定的读写操作, 还会执行一些额外的维护操作, 其中包括:
- 在读取一个键之后(读操作和写操作都要对键进行读取), 服务器会根据键是否存在, 以此来更新服务器的键空间命中(hit)次数或键空间不命中(miss)次数, 这两个值可以在 INFO stats 命令的
keyspace_hits属性和keyspace_misses属性中查看; - 在读取一个键之后, 服务器会更新键的 LRU (最后一次使用)时间, 这个值可以用于计算键的闲置时间, 使用命令
OBJECT idletime命令可以查看键 key 的闲置时间; - 如果服务器在读取一个键时, 发现该键已经过期, 那么服务器会先删除这个过期键, 然后才执行余下的其他操作;
- 如果有客户端使用 WATCH 命令监视了某个键, 那么服务器在对被监视的键进行修改之后, 会将这个键标记为脏(dirty), 从而让事务程序注意到这个键已经被修改过;
- 服务器每次修改一个键之后, 都会对脏(dirty)键计数器的值增一, 这个计数器会触发服务器的持久化以及复制操作执行;
- 如果服务器开启了数据库通知功能, 那么在对键进行修改之后, 服务器将按配置发送相应的数据库通知。
2.1.2 数据库管理
struct redisServer {
...
redisDb *db;
...
int dbnum; /* Total number of configured DBs */
...
};
redis中数据库的管理是通过redisServer中的redisDb数组进行管理,其中存储着所有的数据库,dbnum是数据库的数量,并且每一个数据都有一个自身的id,用户可以通过该id访问数据库。
- redis 使用惰性删除和定期删除两种策略来删除过期的键: 惰性删除策略只在碰到过期键时才进行删除操作, 定期删除策略则每隔一段时间, 主动查找并删除过期键;
- 执行
SAVE命令或者BGSAVE命令所产生的新RDB文件不会包含已经过期的键; - 执行
BGREWRITEAOF命令所产生的重写AOF文件不会包含已经过期的键; - 当一个过期键被删除之后, 服务器会追加一条
DEL命令到现有AOF文件的末尾, 显式地删除过期键; - 当主服务器删除一个过期键之后, 它会向所有从服务器发送一条
DEL命令, 显式地删除过期键; - 从服务器即使发现过期键, 也不会自作主张地删除它, 而是等待主节点发来
DEL命令, 这种统一、中心化的过期键删除策略可以保证主从服务器数据的一致性; - 当redis命令对数据库进行修改之后, 服务器会根据配置, 向客户端发送数据库通知。
2.2 过期键删除策略
2.2.1 删除策略
redis对于过期的键有三种删除策略:
- 定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器来临时,立即执行的键的删除;
- 优点:内存友好能够及时的删除不需要的键值;
- 缺点:CPU不友好,创建定时器和大量的集中删除可能导致服务器的性能下降;
- 惰性删除:放任键过期不管,每次从键空间中获取键值时,都检查该键是否过期,过期则删除,不过期则返回;
- 优点:CPU友好,只在读取时进删除;
- 缺点:内存不友好,如果出现不经常访问的键可能永远也不会删除;
- 定期删除:每隔一段时间就对整个数据库进行检查,删除过期键;
- 优点:可控性强;
- 缺点:影响服务器的吞吐量和性能。
redis采用的是惰性删除和定期删除配合使用,可以在性能和内存之间权衡。
2.2.2 实现
惰性删除的实现如下:
int expireIfNeeded(redisDb *db, robj *key) {
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a slave, instead of
* evicting the expired key from the database, we return ASAP:
* the slave key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time. */
if (server.masterhost != NULL) return 1;
/* Delete the key */
server.stat_expiredkeys++;
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
定期删除实现,该函数每次在服务器执行serverCron时都会执行:
void activeExpireCycle(int type) {
/* This function has some global state in order to continue the work
* incrementally across calls. */
static unsigned int current_db = 0; /* Last DB tested. */
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* When last fast cycle ran. */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
long long start = ustime(), timelimit, elapsed;
/* When clients are paused the dataset should be static not just from the
* POV of clients not being able to write, but also from the POV of
* expires and evictions of keys not being performed. */
if (clientsArePaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
/* Don't start a fast cycle if the previous cycle did not exit
* for time limit. Also don't repeat a fast cycle for the same period
* as the fast cycle total duration itself. */
if (!timelimit_exit) return;
if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return;
last_fast_cycle = start;
}
/* We usually should test CRON_DBS_PER_CALL per iteration, with
* two exceptions:
*
* 1) Don't test more DBs than we have.
* 2) If last time we hit the time limit, we want to scan all DBs
* in this iteration, as there is work to do in some DB and we don't want
* expired keys to use memory for too much time. */
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
/* We can use at max ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC percentage of CPU time
* per iteration. Since this function gets called with a frequency of
* server.hz times per second, the following is the max amount of
* microseconds we can spend in this function. */
timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION; /* in microseconds. */
/* Accumulate some global stats as we expire keys, to have some idea
* about the number of keys that are already logically expired, but still
* existing inside the database. */
long total_sampled = 0;
long total_expired = 0;
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
int expired;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle more than 25%
* of the keys were expired. */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots getting random
* keys is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (num && slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
ttl_sum = 0;
ttl_samples = 0;
if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;
while (num--) {
dictEntry *de;
long long ttl;
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
ttl = dictGetSignedIntegerVal(de)-now;
if (activeExpireCycleTryExpire(db,de,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet not expired. */
ttl_sum += ttl;
ttl_samples++;
}
total_sampled++;
}
total_expired += expired;
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples.
* We just use the current estimate with a weight of 2%
* and the previous estimate with a weight of 98%. */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle if there are less than 25% of keys
* found expired in the current DB. */
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}
elapsed = ustime()-start;
latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
/* Update our estimate of keys existing but yet to be expired.
* Running average with this sample accounting for 5%. */
double current_perc;
if (total_sampled) {
current_perc = (double)total_expired/total_sampled;
} else
current_perc = 0;
server.stat_expired_stale_perc = (current_perc*0.05)+
(server.stat_expired_stale_perc*0.95);
}
2.3 持久化
2.3.1 RDB持久化
RDB文件:

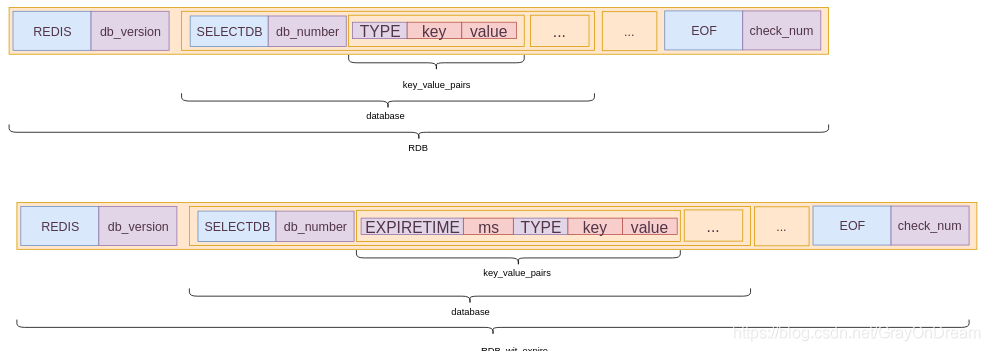
如上图,redis中的RDB文件的格式包含五个字段,其中两个为常量字段(大写),其他为变量(小写):
redis:占5个字节,即redis5个字符;db_version:占4个字节,是一个用字符串表示的整数,存储RDB文件的版本号;databases:包含0个或者多个数据库;EOF:占1个字节,是个常量,标志着RDB文件的结束;check_num:占8个字节,是一个无符号整数,是前4个字段的校验和。
databases:
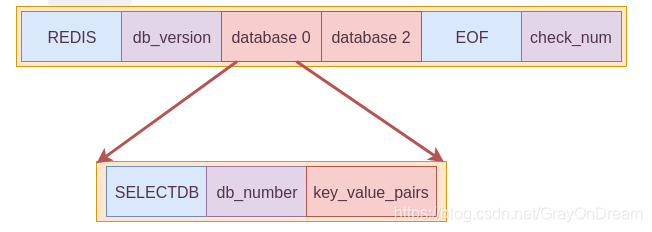
RDB可以包含0个或者多个数据库,每个数据库的文件格式如图中所示包含三个字段:
SELECTDB:占1个字节,用来标识数据库的开头;db_number:保存数据库的号码,可以是1、2或者5个字节;key_value_pairs:保存了数据库中所有键值对数据。 如果键值对带有过期时间, 那么过期时间也会和键值对保存在一起。 根据键值对的数量、类型、内容、以及是否有过期时间等条件的不同,key_value_pairs部分的长度也会有所不同。
#define RDB_OPCODE_SELECTDB 254 /* DB number of the following keys. */
#define RDB_OPCODE_EOF 255 /* End of the RDB file. */
key_value_pairs:
key_value_pairs部分都保存了一个或以上数量的键值对, 如果键值对带有过期时间的话, 那么键值对的过期时间也会被保存在内。
/* Map object types to RDB object types. Macros starting with OBJ_ are for
* memory storage and may change. Instead RDB types must be fixed because
* we store them on disk. */
#define RDB_TYPE_STRING 0
#define RDB_TYPE_LIST 1
#define RDB_TYPE_SET 2
#define RDB_TYPE_ZSET 3
#define RDB_TYPE_HASH 4
#define RDB_TYPE_ZSET_2 5 /* ZSET version 2 with doubles stored in binary. */
#define RDB_TYPE_MODULE 6
#define RDB_TYPE_MODULE_2 7 /* Module value with annotations for parsing without
不带过期时间的key_value_pairs:

分为简单的三个字段:
TYPE:占1个字节,记录value的类型,是多种编码类型之一;key:总是一个字符串对象,编码方式为RDB_TYPE_STRING;value:不同的编码方式采用不同的数据结构存储。
带过期时间的key_value_pairs:
#define RDB_OPCODE_EXPIRETIME_MS 252 /* Expire time in milliseconds. */
#define RDB_OPCODE_EXPIRETIME 253 /* Old expire time in seconds. */

EXPIRETIME:占1个字节,可选为RDB_OPCODE_EXPIRETIME_MS和RDB_OPCODE_EXPIRETIME,表示延时的计时单位;ms:占8字节,是一个带符号的整数,记录着一个以毫秒为单位的 UNIX 时间戳, 这个时间戳就是键值对的过期时间;type:同上;key:同上;value:同上。
字符串:
需要注意的字符串编码相对来说不太一样。字符串编码分为int,raw,embstr但是这里分为int,raw,lzf三种:
int:当字符串对象保存的是长度不超过32位的整数时采用,存储结构如下图;

raw:- 如果字符串的长度小于等于 20 字节, 那么这个字符串会直接被原样保存;
- 如果字符串的长度大于20字节,并且服务器开启了
rdbcompression压缩选项,则使用压缩格式存储;
lzf:如果字符串的长度大于20字节,并且服务器开启了rdbcompression压缩选项,则使用压缩格式存储。

上面几个图的各个字段的含义正如其中的文本所描述。
/* When a length of a string object stored on disk has the first two bits
* set, the remaining six bits specify a special encoding for the object
* accordingly to the following defines: */
#define RDB_ENC_INT8 0 /* 8 bit signed integer */
#define RDB_ENC_INT16 1 /* 16 bit signed integer */
#define RDB_ENC_INT32 2 /* 32 bit signed integer */
#define RDB_ENC_LZF 3 /* string compressed with FASTLZ */
总结:
RDB文件用于保存和还原 redis 服务器所有数据库中的所有键值对数据;SAVE命令由服务器进程直接执行保存操作,所以该命令会阻塞服务器;BGSAVE命令由子进程执行保存操作,所以该命令不会阻塞服务器;- 服务器状态中会保存所有用 save 选项设置的保存条件,当任意一个保存条件被满足时,服务器会自动执行 BGSAVE 命令;
RDB文件是一个经过压缩的二进制文件,由多个部分组成;- 对于不同类型的键值对, RDB 文件会使用不同的方式来保存它们。
2.3.2 AOF持久化
AOF :redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
命令追加:
struct redisServer {
...
sds aof_buf; /* AOF buffer, written before entering the event loop */
...
};
当 AOF持久化功能处于打开状态时, 服务器在执行完一个写命令之后, 会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾。
文件写入与同步:
redis 的服务器进程就是一个事件循环(loop), 这个循环中的文件事件负责接收客户端的命令请求, 以及向客户端发送命令回复, 而时间事件则负责执行像 serverCron函数这样需要定时运行的函数。
因为服务器在处理文件事件时可能会执行写命令, 使得一些内容被追加到 aof_buf缓冲区里面, 所以在服务器每次结束一个事件循环之前, 它都会调用flushAppendOnlyFile函数, 考虑是否需要将 aof_buf缓冲区中的内容写入和保存到 AOF 文件里面。
//伪代码
def eventLoop():
while True:
# 处理文件事件,接收命令请求以及发送命令回复
# 处理命令请求时可能会有新内容被追加到 aof_buf 缓冲区中
processFileEvents()
# 处理时间事件
processTimeEvents()
# 考虑是否要将 aof_buf 中的内容写入和保存到 AOF 文件里面
flushAppendOnlyFile()
flushAppendOnlyFile函数的行为由服务器配置的 appendfsync选项的值来决定, 各个不同值产生的行为如下表所示:
| appendfsync 选项的值 | flushAppendOnlyFile 函数的行为 |
|---|---|
always | 将 aof_buf缓冲区中的所有内容写入并同步到 AOF 文件。 |
everysec | 将 aof_buf 缓冲区中的所有内容写入到 AOF文件, 如果上次同步 AOF文件的时间距离现在超过一秒钟, 那么再次对 AOF文件进行同步, 并且这个同步操作是由一个线程专门负责执行的。 |
no | 将 aof_buf缓冲区中的所有内容写入到 AOF文件, 但并不对 AOF文件进行同步, 何时同步由操作系统来决定。 |
如果用户没有主动为appendfsync选项设置值, 那么appendfsync选项的默认值为 everysec, 关于 appendfsync选项的更多信息, 请参考 redis 项目附带的示例配置文件 redis.conf。
为了提高文件的写入效率, 在现代操作系统中, 当用户调用 write函数, 将一些数据写入到文件的时候, 操作系统通常会将写入数据暂时保存在一个内存缓冲区里面, 等到缓冲区的空间被填满、或者超过了指定的时限之后, 才真正地将缓冲区中的数据写入到磁盘里面。
这种做法虽然提高了效率, 但也为写入数据带来了安全问题, 因为如果计算机发生停机, 那么保存在内存缓冲区里面的写入数据将会丢失。
为此, 系统提供了 fsync和fdatasync两个同步函数, 它们可以强制让操作系统立即将缓冲区中的数据写入到硬盘里面, 从而确保写入数据的安全性。
服务器配置 appendfsync 选项的值直接决定 AOF 持久化功能的效率和安全性。
appendfsync == always时, 服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到AOF文件, 并且同步AOF文件, 所以always的效率是appendfsync选项三个值当中最慢的一个, 但从安全性来说,always也是最安全的, 因为即使出现故障停机,AOF持久化也只会丢失一个事件循环中所产生的命令数据。appendfsync == everysec时, 服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到AOF文件, 并且每隔超过一秒就要在子线程中对AOF文件进行一次同步: 从效率上来讲,everysec模式足够快, 并且就算出现故障停机, 数据库也只丢失一秒钟的命令数据。appendfsync == no时, 服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到AOF文件, 至于何时对AOF文件进行同步, 则由操作系统控制。因为处于no模式下的flushAppendOnlyFile调用无须执行同步操作, 所以该模式下的AOF文件写入速度总是最快的, 不过因为这种模式会在系统缓存中积累一段时间的写入数据, 所以该模式的单次同步时长通常是三种模式中时间最长的: 从平摊操作的角度来看,no模式和everysec模式的效率类似, 当出现故障停机时, 使用no模式的服务器将丢失上次同步AOF文件之后的所有写命令数据。
在执行 BGREWRITEAOF 命令时, redis 服务器会维护一个 AOF 重写缓冲区, 该缓冲区会在子进程创建新 AOF 文件的期间, 记录服务器执行的所有写命令。 当子进程完成创建新 AOF 文件的工作之后, 服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾, 使得新旧两个 AOF 文件所保存的数据库状态一致。 最后, 服务器用新的 AOF 文件替换旧的 AOF 文件, 以此来完成 AOF 文件重写操作。
2.4 事件
2.4.1 简介
Reactor 的一般工作过程是首先在 Reactor 中注册(Reactor)感兴趣事件,并在注册时候指定某个已定义的回调函数(callback);当客户端发送请求时,在 Reactor 中会触发刚才注册的事件,并调用对应的处理函数。在这一个处理回调函数中,一般会有数据接收、处理、回复请求等操作。
redis 基于Reactor模式开发了自己的网络事件处理器: 这个处理器被称为文件事件处理器(file event handler):
- 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器;
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行, 但通过使用I/O多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 redis 内部单线程设计的简单性。
2.4.2 文件事件的构成
文件事件处理器的四个组成部分:套接字、 I/O 多路复用程序、 文件事件分派器(dispatcher)、 以及事件处理器。
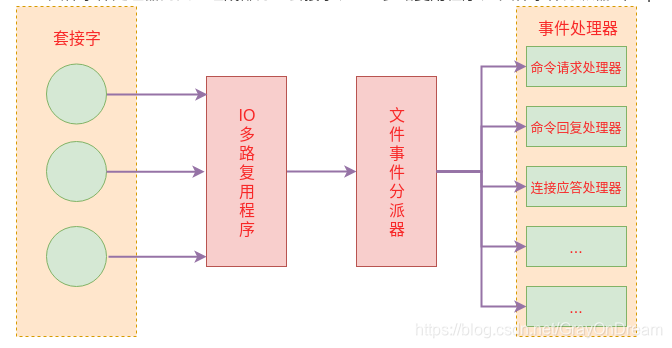
文件事件是对套接字操作的抽象, 每当一个套接字准备好执行连接应答(accept)、写入、读取、关闭等操作时, 就会产生一个文件事件。 因为一个服务器通常会连接多个套接字, 所以多个文件事件有可能会并发地出现。
I/O 多路复用程序负责监听多个套接字, 并向文件事件分派器传送那些产生了事件的套接字。
尽管多个文件事件可能会并发地出现, 但 I/O 多路复用程序总是会将所有产生事件的套接字都入队到一个队列里面, 然后通过这个队列, 以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字: 当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕), I/O 多路复用程序才会继续向文件事件分派器传送下一个套接字。
文件事件分派器接收 I/O 多路复用程序传来的套接字, 并根据套接字产生的事件的类型, 调用相应的事件处理器。
服务器会为执行不同任务的套接字关联不同的事件处理器, 这些处理器是一个个函数, 它们定义了某个事件发生时, 服务器应该执行的动作。
2.4.3 IO多路复用的实现
redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select、 epoll、 evport和 kqueue这些 I/O多路复用函数库来实现的, 每个 I/O 多路复用函数库在 redis 源码中都对应一个单独的文件, 比如ae_select.c、 ae_epoll.c、 ae_kqueue.c, 诸如此类。
因为 redis 为每个 I/O 多路复用函数库都实现了相同的 API , 所以 I/O 多路复用程序的底层实现是可以互换的。
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
2.4.4 事件类型及其API
事件类型:
I/O 多路复用程序可以监听多个套接字的 ae.h/AE_READABLE事件和ae.h/AE_WRITABLE事件, 这两类事件和套接字操作之间的对应关系:
- 当套接字变得可读时(客户端对套接字执行
write操作,或者执行close操作), 或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字执行connect操作), 套接字产生AE_READABLE事件; - 当套接字变得可写时(客户端对套接字执行
read操作), 套接字产生AE_WRITABLE事件。
I/O 多路复用程序允许服务器同时监听套接字的 AE_READABLE事件和 AE_WRITABLE事件, 如果一个套接字同时产生了这两种事件, 那么文件事件分派器会优先处理 AE_READABLE事件, 等到 AE_READABLE事件处理完之后, 才处理 AE_WRITABLE事件。
API:
ae.c/aeCreateFileEvent函数接受一个套接字描述符、 一个事件类型、 以及一个事件处理器作为参数, 将给定套接字的给定事件加入到 I/O 多路复用程序的监听范围之内, 并对事件和事件处理器进行关联;ae.c/aeDeleteFileEvent函数接受一个套接字描述符和一个监听事件类型作为参数, 让 I/O 多路复用程序取消对给定套接字的给定事件的监听, 并取消事件和事件处理器之间的关联;ae.c/aeGetFileEvents函数接受一个套接字描述符, 返回该套接字正在被监听的事件类型:- 如果套接字没有任何事件被监听, 那么函数返回
AE_NONE。 - 如果套接字的读事件正在被监听, 那么函数返回
AE_READABLE。 - 如果套接字的写事件正在被监听, 那么函数返回
AE_WRITABLE。 - 如果套接字的读事件和写事件正在被监听, 那么函数返回
AE_READABLE | AE_WRITABLE。
- 如果套接字没有任何事件被监听, 那么函数返回
ae.c/aeWait函数接受一个套接字描述符、一个事件类型和一个毫秒数为参数, 在给定的时间内阻塞并等待套接字的给定类型事件产生, 当事件成功产生, 或者等待超时之后, 函数返回;ae.c/aeApiPoll函数接受一个sys/time.h/struct timeval结构为参数, 并在指定的时间內, 阻塞并等待所有被aeCreateFileEvent函数设置为监听状态的套接字产生文件事件, 当有至少一个事件产生, 或者等待超时后, 函数返回;ae.c/aeProcessEvents函数是文件事件分派器, 它先调用aeApiPoll函数来等待事件产生, 然后遍历所有已产生的事件, 并调用相应的事件处理器来处理这些事件;ae.c/aeGetApiName函数返回 I/O 多路复用程序底层所使用的 I/O 多路复用函数库的名称: 返回 “epoll” 表示底层为epoll函数库, 返回"select" 表示底层为select函数库, 诸如此类。
2.4.5 文件事件处理器
redis 为文件事件编写了多个处理器, 这些事件处理器分别用于实现不同的网络通讯需求:
- 为了对连接服务器的各个客户端进行应答, 服务器要为监听套接字关联连接应答处理器;
- 为了接收客户端传来的命令请求, 服务器要为客户端套接字关联命令请求处理器;
- 为了向客户端返回命令的执行结果, 服务器要为客户端套接字关联命令回复处理器;
- 当主服务器和从服务器进行复制操作时, 主从服务器都需要关联特别为复制功能编写的复制处理器;
- 等等。
2.4.5.1 连接应答处理器
networking.c/acceptTcpHandler函数是 redis 的连接应答处理器, 这个处理器用于对连接服务器监听套接字的客户端进行应答, 具体实现为sys/socket.h/accept函数的包装。
当 redis 服务器进行初始化的时候, 程序会将这个连接应答处理器和服务器监听套接字的 AE_READABLE事件关联起来, 当有客户端用sys/socket.h/connect函数连接服务器监听套接字的时候, 套接字就会产生 AE_READABLE事件, 引发连接应答处理器执行, 并执行相应的套接字应答操作。
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
while(max--) {
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
acceptCommonHandler(cfd,0,cip);
}
}
2.4.5.2 命令请求处理器
networking.c/readQueryFromClient函数是 Redis 的命令请求处理器, 这个处理器负责从套接字中读入客户端发送的命令请求内容, 具体实现为 unistd.h/read函数的包装。
当一个客户端通过连接应答处理器成功连接到服务器之后, 服务器会将客户端套接字的 AE_READABLE事件和命令请求处理器关联起来, 当客户端向服务器发送命令请求的时候, 套接字就会产生 AE_READABLE事件, 引发命令请求处理器执行, 并执行相应的套接字读入操作。
在客户端连接服务器的整个过程中, 服务器都会一直为客户端套接字的 AE_READABLE事件关联命令请求处理器。
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
client *c = (client*) privdata;
int nread, readlen;
size_t qblen;
UNUSED(el);
UNUSED(mask);
readlen = PROTO_IOBUF_LEN;
/* If this is a multi bulk request, and we are processing a bulk reply
* that is large enough, try to maximize the probability that the query
* buffer contains exactly the SDS string representing the object, even
* at the risk of requiring more read(2) calls. This way the function
* processMultiBulkBuffer() can avoid copying buffers to create the
* Redis Object representing the argument. */
if (c->reqtype == PROTO_REQ_MULTIBULK && c->multibulklen && c->bulklen != -1
&& c->bulklen >= PROTO_MBULK_BIG_ARG)
{
ssize_t remaining = (size_t)(c->bulklen+2)-sdslen(c->querybuf);
/* Note that the 'remaining' variable may be zero in some edge case,
* for example once we resume a blocked client after CLIENT PAUSE. */
if (remaining > 0 && remaining < readlen) readlen = remaining;
}
qblen = sdslen(c->querybuf);
if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);
nread = read(fd, c->querybuf+qblen, readlen);
if (nread == -1) {
if (errno == EAGAIN) {
return;
} else {
serverLog(LL_VERBOSE, "Reading from client: %s",strerror(errno));
freeClient(c);
return;
}
} else if (nread == 0) {
serverLog(LL_VERBOSE, "Client closed connection");
freeClient(c);
return;
} else if (c->flags & CLIENT_MASTER) {
/* Append the query buffer to the pending (not applied) buffer
* of the master. We'll use this buffer later in order to have a
* copy of the string applied by the last command executed. */
c->pending_querybuf = sdscatlen(c->pending_querybuf,
c->querybuf+qblen,nread);
}
sdsIncrLen(c->querybuf,nread);
c->lastinteraction = server.unixtime;
if (c->flags & CLIENT_MASTER) c->read_reploff += nread;
server.stat_net_input_bytes += nread;
if (sdslen(c->querybuf) > server.client_max_querybuf_len) {
sds ci = catClientInfoString(sdsempty(),c), bytes = sdsempty();
bytes = sdscatrepr(bytes,c->querybuf,64);
serverLog(LL_WARNING,"Closing client that reached max query buffer length: %s (qbuf initial bytes: %s)", ci, bytes);
sdsfree(ci);
sdsfree(bytes);
freeClient(c);
return;
}
/* Time to process the buffer. If the client is a master we need to
* compute the difference between the applied offset before and after
* processing the buffer, to understand how much of the replication stream
* was actually applied to the master state: this quantity, and its
* corresponding part of the replication stream, will be propagated to
* the sub-slaves and to the replication backlog. */
processInputBufferAndReplicate(c);
}
2.4.5.3 命令回复处理器
networking.c/sendReplyToClient函数是 Redis 的命令回复处理器, 这个处理器负责将服务器执行命令后得到的命令回复通过套接字返回给客户端, 具体实现为 unistd.h/write函数的包装。
当服务器有命令回复需要传送给客户端的时候, 服务器会将客户端套接字的 AE_WRITABLE事件和命令回复处理器关联起来, 当客户端准备好接收服务器传回的命令回复时, 就会产生 AE_WRITABLE事件, 引发命令回复处理器执行, 并执行相应的套接字写入操作。
当命令回复发送完毕之后, 服务器就会解除命令回复处理器与客户端套接字的 AE_WRITABLE事件之间的关联。
/* Write event handler. Just send data to the client. */
void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
UNUSED(el);
UNUSED(mask);
writeToClient(fd,privdata,1);
}
2.4.5.4 总结
- Redis 服务器是一个事件驱动程序, 服务器处理的事件分为时间事件和文件事件两类;
- 文件事件处理器是基于
Reactor模式实现的网络通讯程序; - 文件事件是对套接字操作的抽象: 每次套接字变得可应答(
acceptable)、可写(writable)或者可读(readable)时, 相应的文件事件就会产生; - 文件事件分为
AE_READABLE事件(读事件)和AE_WRITABLE事件(写事件)两类; - 时间事件分为定时事件和周期性事件: 定时事件只在指定的时间达到一次, 而周期性事件则每隔一段时间到达一次;
- 服务器在一般情况下只执行
serverCron函数一个时间事件, 并且这个事件是周期性事件; - 文件事件和时间事件之间是合作关系, 服务器会轮流处理这两种事件, 并且处理事件的过程中也不会进行抢占;
- 时间事件的实际处理时间通常会比设定的到达时间晚一些。
2.4.6 时间事件
2.4.6.1 组成和实现
redis时间事件分为两类:
- 定时时间:一段时间后执行一次;
- 周期性事件:每隔一段时间执行一次。
时间事件组成:
/* Time event structure */
typedef struct aeTimeEvent {
long long id; /* time event identifier. */
long when_sec; /* seconds */
long when_ms; /* milliseconds */
aeTimeProc *timeProc;
aeEventFinalizerProc *finalizerProc;
void *clientData;
struct aeTimeEvent *prev;
struct aeTimeEvent *next;
} aeTimeEvent;
可以看到事件就是一个双向链表,新的时间事件总是插入到表头。每当时间事件执行器运行时就遍历整个链表,查找已经达到时间的事件,并调用响应的事件处理器。
typedef void aeEventFinalizerProc(struct aeEventLoop *eventLoop, void *clientData);
typedef void aeBeforeSleepProc(struct aeEventLoop *eventLoop);
2.4.6.2 serverCron
持续运行的redis服务器需要定期对自身的资源和状态进行检查和调整,从而确保服务可以长期稳定的运行,这些定期操作由serverCron负责:
- 更新服务器的各类统计信息,如时间,内存占用,数据库占用等;
- 清理数据库中的过期键值对;
- 关闭和清理链接失效的客户端;
- 尝试进行AOF,RDB持久化;
- 如果是主服务器则对从服务器进行定期同步;
- 如果处于集群模式,对集群进行定期同步和链接测试。
2.4.7 事件的调度
redis调度的伪代码如下:
def aeProcessEvents():
//寻找离当前时间最近的时间事件
time_eve = aeSearchNearestTimer()
//计算距离
remaid_tim = tim_eve - unix_ts_now()
if remaid_tim < 0:
remaid_tim = 0
time_val = create_timeval_ms(remaid_tim)
//阻塞并等待文件事件产生
aeApiPoll(time_val)
//处理已产生的文件事件
processFileEvents()
//处理所有已经到达的时间事件
processTimeEvents()
这样做的一个好处:
- 避免轮询造成的忙等待,阻塞时间由最接近的时间事件决定,而且服务器本身维护
serverCron事件,一定会在较短的时间内完成事件处理;
2.5 客户端属性
客户端属性分为两类:特定属性和通用属性(顾名思义)。
/* With multiplexing we need to take per-client state.
* Clients are taken in a linked list. */
typedef struct client {
uint64_t id; /* Client incremental unique ID. */
int fd; /* Client socket. */
redisDb *db; /* Pointer to currently SELECTed DB. */
robj *name; /* As set by CLIENT SETNAME. */
sds querybuf; /* Buffer we use to accumulate client queries. */
size_t qb_pos; /* The position we have read in querybuf. */
sds pending_querybuf; /* If this client is flagged as master, this buffer
represents the yet not applied portion of the
replication stream that we are receiving from
the master. */
size_t querybuf_peak; /* Recent (100ms or more) peak of querybuf size. */
int argc; /* Num of arguments of current command. */
robj **argv; /* Arguments of current command. */
struct redisCommand *cmd, *lastcmd; /* Last command executed. */
int reqtype; /* Request protocol type: PROTO_REQ_* */
int multibulklen; /* Number of multi bulk arguments left to read. */
long bulklen; /* Length of bulk argument in multi bulk request. */
list *reply; /* List of reply objects to send to the client. */
unsigned long long reply_bytes; /* Tot bytes of objects in reply list. */
size_t sentlen; /* Amount of bytes already sent in the current
buffer or object being sent. */
time_t ctime; /* Client creation time. */
time_t lastinteraction; /* Time of the last interaction, used for timeout */
time_t obuf_soft_limit_reached_time;
int flags; /* Client flags: CLIENT_* macros. */
int authenticated; /* When requirepass is non-NULL. */
int replstate; /* Replication state if this is a slave. */
int repl_put_online_on_ack; /* Install slave write handler on ACK. */
int repldbfd; /* Replication DB file descriptor. */
off_t repldboff; /* Replication DB file offset. */
off_t repldbsize; /* Replication DB file size. */
sds replpreamble; /* Replication DB preamble. */
long long read_reploff; /* Read replication offset if this is a master. */
long long reploff; /* Applied replication offset if this is a master. */
long long repl_ack_off; /* Replication ack offset, if this is a slave. */
long long repl_ack_time;/* Replication ack time, if this is a slave. */
long long psync_initial_offset; /* FULLRESYNC reply offset other slaves
copying this slave output buffer
should use. */
char replid[CONFIG_RUN_ID_SIZE+1]; /* Master replication ID (if master). */
int slave_listening_port; /* As configured with: SLAVECONF listening-port */
char slave_ip[NET_IP_STR_LEN]; /* Optionally given by REPLCONF ip-address */
int slave_capa; /* Slave capabilities: SLAVE_CAPA_* bitwise OR. */
multiState mstate; /* MULTI/EXEC state */
int btype; /* Type of blocking op if CLIENT_BLOCKED. */
blockingState bpop; /* blocking state */
long long woff; /* Last write global replication offset. */
list *watched_keys; /* Keys WATCHED for MULTI/EXEC CAS */
dict *pubsub_channels; /* channels a client is interested in (SUBSCRIBE) */
list *pubsub_patterns; /* patterns a client is interested in (SUBSCRIBE) */
sds peerid; /* Cached peer ID. */
listNode *client_list_node; /* list node in client list */
/* Response buffer */
int bufpos;
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;
2.5.1 socket描述符
客户端状态的 fd属性记录了客户端正在使用的套接字描述符。根据客户端类型的不同, fd属性的值可以是 -1或者是大于 -1的整数:
- 伪客户端(
fake client)的fd属性的值为-1: 伪客户端处理的命令请求来源于AOF文件或者Lua脚本, 而不是网络, 所以这种客户端不需要套接字连接, 自然也不需要记录套接字描述符。 目前 Redis 服务器会在两个地方用到伪客户端, 一个用于载入 AOF 文件并还原数据库状态, 而另一个则用于执行 Lua 脚本中包含的 Redis 命令; - 普通客户端的
fd属性的值为大于-1的整数: 普通客户端使用套接字来与服务器进行通讯, 所以服务器会用fd属性来记录客户端套接字的描述符。 因为合法的套接字描述符不能是 -1 , 所以普通客户端的套接字描述符的值必然是大于-1的整数。
2.5.2 名字
名字可以用来标示客户端,方便操作。在默认情况下, 一个连接到服务器的客户端是没有名字的。
2.5.3 标志
/* Client flags */
#define CLIENT_SLAVE (1<<0) /* This client is a slave server */
#define CLIENT_MASTER (1<<1) /* This client is a master server */
#define CLIENT_MONITOR (1<<2) /* This client is a slave monitor, see MONITOR */
#define CLIENT_MULTI (1<<3) /* This client is in a MULTI context */
#define CLIENT_BLOCKED (1<<4) /* The client is waiting in a blocking operation */
#define CLIENT_DIRTY_CAS (1<<5) /* Watched keys modified. EXEC will fail. */
#define CLIENT_CLOSE_AFTER_REPLY (1<<6) /* Close after writing entire reply. */
#define CLIENT_UNBLOCKED (1<<7) /* This client was unblocked and is stored in
server.unblocked_clients */
#define CLIENT_LUA (1<<8) /* This is a non connected client used by Lua */
#define CLIENT_ASKING (1<<9) /* Client issued the ASKING command */
#define CLIENT_CLOSE_ASAP (1<<10)/* Close this client ASAP */
#define CLIENT_UNIX_SOCKET (1<<11) /* Client connected via Unix domain socket */
#define CLIENT_DIRTY_EXEC (1<<12) /* EXEC will fail for errors while queueing */
#define CLIENT_MASTER_FORCE_REPLY (1<<13) /* Queue replies even if is master */
#define CLIENT_FORCE_AOF (1<<14) /* Force AOF propagation of current cmd. */
#define CLIENT_FORCE_REPL (1<<15) /* Force replication of current cmd. */
#define CLIENT_PRE_PSYNC (1<<16) /* Instance don't understand PSYNC. */
#define CLIENT_READONLY (1<<17) /* Cluster client is in read-only state. */
#define CLIENT_PUBSUB (1<<18) /* Client is in Pub/Sub mode. */
#define CLIENT_PREVENT_AOF_PROP (1<<19) /* Don't propagate to AOF. */
#define CLIENT_PREVENT_REPL_PROP (1<<20) /* Don't propagate to slaves. */
#define CLIENT_PREVENT_PROP (CLIENT_PREVENT_AOF_PROP|CLIENT_PREVENT_REPL_PROP)
#define CLIENT_PENDING_WRITE (1<<21) /* Client has output to send but a write
handler is yet not installed. */
#define CLIENT_REPLY_OFF (1<<22) /* Don't send replies to client. */
#define CLIENT_REPLY_SKIP_NEXT (1<<23) /* Set CLIENT_REPLY_SKIP for next cmd */
#define CLIENT_REPLY_SKIP (1<<24) /* Don't send just this reply. */
#define CLIENT_LUA_DEBUG (1<<25) /* Run EVAL in debug mode. */
#define CLIENT_LUA_DEBUG_SYNC (1<<26) /* EVAL debugging without fork() */
#define CLIENT_MODULE (1<<27) /* Non connected client used by some module. */
#define CLIENT_PROTECTED (1<<28) /* Client should not be freed for now. */
客户端的标志属性 flags记录了客户端的角色(role), 以及客户端目前所处的状态。
每个标志使用一个常量表示, 一部分标志记录了客户端的角色:
- 在主从服务器进行复制操作时, 主服务器会成为从服务器的客户端, 而从服务器也会成为主服务器的客户端。
CLIENT_MASTER标志表示客户端代表的是一个主服务器,CLIENT_SLAVE标志表示客户端代表的是一个从服务器; CLIENT_PRE_PSYNC标志表示客户端代表的是一个版本低于 Redis 2.8 的从服务器, 主服务器不能使用PSYNC命令与这个从服务器进行同步。 这个标志只能在CLIENT_SLAVE标志处于打开状态时使用;CLIENT_LUA_CLIENT标识表示客户端是专门用于处理 Lua 脚本里面包含的 Redis 命令的伪客户端;
而另外一部分标志则记录了客户端目前所处的状态:
CLIENT_MONITOR标志表示客户端正在执行MONITOR命令;CLIENT_UNIX_SOCKET标志表示服务器使用UNIX套接字来连接客户端;CLIENT_BLOCKED标志表示客户端正在被BRPOP、BLPOP等命令阻塞;CLIENT_UNBLOCKED标志表示客户端已经从CLIENT_BLOCKED标志所表示的阻塞状态中脱离出来, 不再阻塞。CLIENT_UNBLOCKED标志只能在CLIENT_BLOCKED标志已经打开的情况下使用;CLIENT_MULTI标志表示客户端正在执行事务;CLIENT_DIRTY_CAS标志表示事务使用WATCH命令监视的数据库键已经被修改,CLIENT_DIRTY_EXEC标志表示事务在命令入队时出现了错误, 以上两个标志都表示事务的安全性已经被破坏, 只要这两个标记中的任意一个被打开,EXEC命令必然会执行失败。 这两个标志只能在客户端打开了CLIENT_MULTI标志的情况下使用;CLIENT_CLOSE_ASAP标志表示客户端的输出缓冲区大小超出了服务器允许的范围, 服务器会在下一次执行serverCron函数时关闭这个客户端, 以免服务器的稳定性受到这个客户端影响。 积存在输出缓冲区中的所有内容会直接被释放, 不会返回给客户端;CLIENT_CLOSE_AFTER_REPLY标志表示有用户对这个客户端执行了CLIENT_KILL命令, 或者客户端发送给服务器的命令请求中包含了错误的协议内容。 服务器会将客户端积存在输出缓冲区中的所有内容发送给客户端, 然后关闭客户端;CLIENT_ASKING标志表示客户端向集群节点(运行在集群模式下的服务器)发送了 ASKING 命令;CLIENT_FORCE_AOF标志强制服务器将当前执行的命令写入到AOF文件里面,CLIENT_FORCE_REPL标志强制主服务器将当前执行的命令复制给所有从服务器。 执行PUBSUB命令会使客户端打开CLIENT_FORCE_AOF标志, 执行SCRIPT_LOAD命令会使客户端打开CLIENT_FORCE_AOF标志和CLIENT_FORCE_REPL标志;- 在主从服务器进行命令传播期间, 从服务器需要向主服务器发送
REPLICATION ACK命令, 在发送这个命令之前, 从服务器必须打开主服务器对应的客户端的CLIENT_MASTER_FORCE_REPLY标志, 否则发送操作会被拒绝执行。
PUBSUB命令和 SCRIPT LOAD命令的特殊性:
通常情况下, Redis 只会将那些对数据库进行了修改的命令写入到 AOF 文件, 并复制到各个从服务器: 如果一个命令没有对数据库进行任何修改, 那么它就会被认为是只读命令, 这个命令不会被写入到 AOF文件, 也不会被复制到从服务器。
以上规则适用于绝大部分 Redis 命令, 但 PUBSUB命令和 SCRIPT_LOAD命令是其中的例外。
PUBSUB命令虽然没有修改数据库, 但 PUBSUB命令向频道的所有订阅者发送消息这一行为带有副作用, 接收到消息的所有客户端的状态都会因为这个命令而改变。 因此, 服务器需要使用 REDIS_FORCE_AOF标志, 强制将这个命令写入 AOF文件, 这样在将来载入 AOF文件时, 服务器就可以再次执行相同的 PUBSUB命令, 并产生相同的副作用。
SCRIPT_LOAD命令的情况与 PUBSUB命令类似: 虽然 SCRIPT_LOAD命令没有修改数据库, 但它修改了服务器状态, 所以它是一个带有副作用的命令, 服务器需要使用 REDIS_FORCE_AOF标志, 强制将这个命令写入 AOF文件, 使得将来在载入 AOF文件时, 服务器可以产生相同的副作用。
另外, 为了让主服务器和从服务器都可以正确地载入 SCRIPT_LOAD命令指定的脚本, 服务器需要使用 REDIS_FORCE_REPL标志, 强制将SCRIPT_LOAD命令复制给所有从服务器。
2.5.4 输入缓冲区
客户端状态的输入缓冲区用于保存客户端发送的命令请求(querybuf),输入缓冲区的大小会根据输入内容动态地缩小或者扩大, 但它的最大大小不能超过 1 GB , 否则服务器将关闭这个客户端。
2.5.5 命令与命令参数
在服务器将客户端发送的命令请求保存到客户端状态的 querybuf属性之后, 服务器将对命令请求的内容进行分析, 并将得出的命令参数以及命令参数的个数分别保存到客户端状态的 argv属性和 argc属性:
argv属性是一个数组, 数组中的每个项都是一个字符串对象: 其中 argv[0]是要执行的命令, 而之后的其他项则是传给命令的参数。argc属性则负责记录 argv数组的长度。
2.5.6 命令实现函数
当服务器从协议内容中分析并得出 argv属性和 argc属性的值之后, 服务器将根据项 argv[0]的值, 在命令表中查找命令所对应的命令实现函数。
该表是一个字典, 字典的键是一个 SDS结构, 保存了命令的名字, 字典的值是命令所对应的redisCommand结构, 这个结构保存了命令的实现函数、 命令的标志、 命令应该给定的参数个数、 命令的总执行次数和总消耗时长等统计信息。
当程序在命令表中成功找到 argv[0]所对应的 redisCommand结构时, 它会将客户端状态的 cmd指针指向这个结构。之后, 服务器就可以使用cmd属性所指向的 redisCommand结构, 以及 argv、argc属性中保存的命令参数信息, 调用命令实现函数, 执行客户端指定的命令。
struct redisCommand {
char *name;
redisCommandProc *proc;
int arity;
char *sflags; /* Flags as string representation, one char per flag. */
int flags; /* The actual flags, obtained from the 'sflags' field. */
/* Use a function to determine keys arguments in a command line.
* Used for Redis Cluster redirect. */
redisGetKeysProc *getkeys_proc;
/* What keys should be loaded in background when calling this command? */
int firstkey; /* The first argument that's a key (0 = no keys) */
int lastkey; /* The last argument that's a key */
int keystep; /* The step between first and last key */
long long microseconds, calls;
};
2.5.7 输出缓冲区
执行命令所得的命令回复会被保存在客户端状态的输出缓冲区里面, 每个客户端都有两个输出缓冲区可用, 一个缓冲区的大小是固定的, 另一个缓冲区的大小是可变的:
- 固定大小的缓冲区用于保存那些长度比较小的回复, 比如 OK 、简短的字符串值、整数值、错误回复,等等。大小为
PROTO_REPLY_CHUNK_BYTES,是16KB; - 可变大小的缓冲区用于保存那些长度比较大的回复, 比如一个非常长的字符串值, 一个由很多项组成的列表, 一个包含了很多元素的集合, 等等。可变大小缓冲区由 reply 链表和一个或多个字符串对象组成。
客户端的固定大小缓冲区由 buf 和 bufpos 两个属性组成。
2.5.8 身份验证
客户端状态的 authenticated 属性用于记录客户端是否通过了身份验证:
- 0,未通过;
- 1,通过。
2.5.9 时间
和时间相关的三个属性如下:
time_t ctime; /* Client creation time. */
time_t lastinteraction; /* Time of the last interaction, used for timeout */
time_t obuf_soft_limit_reached_time;
ctime:表示客户端创建时间;lastinteraction:标示最后一次进行互动的时间;obuf_soft_limit_reached_time:输出缓冲区第一次到达软性限制(soft limit)的时间。
2.6 服务器
redis中客户端发送一个命令完成一系列操作的基本过程如下:
- 客户端向服务端发送命令请求;
- 服务端接受客户端的命令并记性处理,产生返回码;
- 服务端将返回码发送给客户端;
- 客户端接受服务器的命令返回码,并输出到输出流。
2.6.1 发送命令
发送命令的基本过程为:用户----键入命令—>客户端-----将命令转换成协议格式发送----->服务端。
2.6.2 读取命令请求
当客户端与服务器之间的连接套接字因为客户端的写入而变得可读时, 服务器将调用命令请求处理器来执行以下操作:
- 读取套接字中协议格式的命令请求, 并将其保存到客户端状态的输入缓冲区里面;
- 对输入缓冲区中的命令请求进行分析, 提取出命令请求中包含的命令参数, 以及命令参数的个数, 然后分别将参数和参数个数保存到客户端状态的 argv 属性和 argc 属性里面;
- 调用命令执行器, 执行客户端指定的命令。
2.6.3 执行命令
2.6.3.1 查找命令实现
命令执行器要做的第一件事就是根据客户端状态的 argv[0]参数, 在命令表(command table)中查找参数所指定的命令, 并将找到的命令保存到客户端状态的 cmd属性里面。
命令表是一个字典, 字典的键是一个个命令名字,比如 "set" 、 "get" 、 "del"等等; 而字典的值则是一个个 redisCommand结构, 每个redisCommand结构记录了一个 Redis 命令的实现信息。
struct redisCommand {
char *name;
redisCommandProc *proc;
int arity;
char *sflags; /* Flags as string representation, one char per flag. */
int flags; /* The actual flags, obtained from the 'sflags' field. */
/* Use a function to determine keys arguments in a command line.
* Used for Redis Cluster redirect. */
redisGetKeysProc *getkeys_proc;
/* What keys should be loaded in background when calling this command? */
int firstkey; /* The first argument that's a key (0 = no keys) */
int lastkey; /* The last argument that's a key */
int keystep; /* The step between first and last key */
long long microseconds, calls;
};
name:命令的名字;proc:命令需要执行的函数,即typedef void redisCommandProc(client *c);;arity:命令参数的个数,用于检查命令请求的格式是否正确。 如果这个值为负数 -N ,那么表示参数的数量大于等于 N 。 注意命令的名字本身也是一个参数;sflags:字符串形式的标识值, 这个值记录了命令的属性, 比如这个命令是写命令还是读命令, 这个命令是否允许在载入数据时使用, 这个命令是否允许在 Lua 脚本中使用, 等等;flags:对 sflags 标识进行分析得出的二进制标识, 由程序自动生成。 服务器对命令标识进行检查时使用的都是flags属性而不是sflags属性;microseconds:服务器执行这个命令所耗费的总时长;calls:服务器总共执行了多少次这个命令。
sflags属性标识:
| 标识 | 意义 | 带有这个标识的命令 |
|---|---|---|
| w | 这是一个写入命令,可能会修改数据库。 | SET 、 RPUSH 、 DEL,等等。 |
| r | 这是一个只读命令,不会修改数据库。 | GET 、 STRLEN 、 EXISTS,等等。 |
| m | 这个命令可能会占用大量内存, 执行之前需要先检查服务器的内存使用情况, 如果内存紧缺的话就禁止执行这个命令。 | SET 、 APPEND 、 RPUSH 、 LPUSH 、 SADD 、SINTERSTORE,等等。 |
| a | 这是一个管理命令。 | SAVE 、 BGSAVE 、 SHUTDOWN,等等。 |
| p | 这是一个发布与订阅功能方面的命令。 | PUBLISH 、 SUBSCRIBE 、 PUBSUB,等等。 |
| s | 这个命令不可以在 Lua 脚本中使用。 | BRPOP 、 BLPOP 、 BRPOPLPUSH 、 SPOP,等等。 |
| R | 这是一个随机命令, 对于相同的数据集和相同的参数, 命令返回的结果可能不同。 | SPOP 、 SRANDMEMBER 、 SSCAN 、 RANDOMKEY,等等。 |
| S | 当在 Lua 脚本中使用这个命令时, 对这个命令的输出结果进行一次排序, 使得命令的结果有序。 | SINTER 、 SUNION 、 SDIFF 、 SMEMBERS 、KEYS,等等。 |
| l | 这个命令可以在服务器载入数据的过程中使用。 | INFO 、 SHUTDOWN 、 PUBLISH,等等。 |
| t | 这是一个允许从服务器在带有过期数据时使用的命令。 | SLAVEOF 、 PING 、 INFO,等等。 |
| M | 这个命令在监视器(monitor)模式下不会自动被传播(propagate)。 | EXEC |
2.6.3.2 执行预备操作
服务器已经将执行命令所需的命令实现函数(保存在客户端状态的 cmd 属性)、参数(保存在客户端状态的 argv属性)、参数个数(保存在客户端状态的 argc 属性)都收集齐了, 但是在真正执行命令之前, 程序还需要进行一些预备操作, 从而确保命令可以正确、顺利地被执行, 这些操作包括:
- 检查客户端状态的
cmd指针是否指向NULL, 如果是的话, 那么说明用户输入的命令名字找不到相应的命令实现, 服务器不再执行后续步骤, 并向客户端返回一个错误; - 根据客户端
cmd属性指向的redisCommand结构的arity属性, 检查命令请求所给定的参数个数是否正确, 当参数个数不正确时, 不再执行后续步骤, 直接向客户端返回一个错误。 比如说, 如果redisCommand结构的arity属性的值为 -3 , 那么用户输入的命令参数个数必须大于等于 3 个才行; - 检查客户端是否已经通过了身份验证, 未通过身份验证的客户端只能执行
AUTH命令, 如果未通过身份验证的客户端试图执行除AUTH命令之外的其他命令, 那么服务器将向客户端返回一个错误; - 如果服务器打开了 maxmemory 功能, 那么在执行命令之前, 先检查服务器的内存占用情况, 并在有需要时进行内存回收, 从而使得接下来的命令可以顺利执行。 如果内存回收失败, 那么不再执行后续步骤, 向客户端返回一个错误;
- 如果服务器上一次执行 BGSAVE 命令时出错, 并且服务器打开了 stop-writes-on-bgsave-error 功能, 而且服务器即将要执行的命令是一个写命令, 那么服务器将拒绝执行这个命令, 并向客户端返回一个错误;
- 如果客户端当前正在用
SUBSCRIBE命令订阅频道, 或者正在用PSUBSCRIBE命令订阅模式, 那么服务器只会执行客户端发来的SUBSCRIBE 、 PSUBSCRIBE 、 UNSUBSCRIBE 、 PUNSUBSCRIBE四个命令, 其他别的命令都会被服务器拒绝; - 如果服务器正在进行数据载入, 那么客户端发送的命令必须带有 l 标识(比如
INFO 、 SHUTDOWN 、 PUBLISH,等等)才会被服务器执行, 其他别的命令都会被服务器拒绝; - 如果服务器因为执行 Lua 脚本而超时并进入阻塞状态, 那么服务器只会执行客户端发来的
SHUTDOWN nosave命令和SCRIPT KILL命令, 其他别的命令都会被服务器拒绝; - 如果客户端正在执行事务, 那么服务器只会执行客户端发来的
EXEC 、 DISCARD 、 MULTI 、 WATCH四个命令, 其他命令都会被放进事务队列中; - 如果服务器打开了监视器功能, 那么服务器会将要执行的命令和参数等信息发送给监视器。
2.6.3.3 调用命令的实现函数
服务器已经将要执行命令的实现保存到了客户端状态的 cmd 属性里面, 并将命令的参数和参数个数分别保存到了客户端状态的 argv 属性和 argc 属性里面, 当服务器决定要执行命令时, 它只要执行以下语句:
client->cmd->proc(client);
2.6.3.4 执行后续工作
在执行完实现函数之后, 服务器还需要执行一些后续工作:
- 如果服务器开启了慢查询日志功能, 那么慢查询日志模块会检查是否需要为刚刚执行完的命令请求添加一条新的慢查询日志;
- 根据刚刚执行命令所耗费的时长, 更新被执行命令的
redisCommand结构的milliseconds属性, 并将命令的redisCommand结构的calls计数器的值增一; - 如果服务器开启了
AOF持久化功能, 那么 AOF 持久化模块会将刚刚执行的命令请求写入到AOF缓冲区里面; - 如果有其他从服务器正在复制当前这个服务器, 那么服务器会将刚刚执行的命令传播给所有从服务器。
2.6.4 发送返回码并输出
命令实现函数会将命令回复保存到客户端的输出缓冲区里面, 并为客户端的套接字关联命令回复处理器, 当客户端套接字变为可写状态时, 服务器就会执行命令回复处理器, 将保存在客户端输出缓冲区中的命令回复发送给客户端。
服务端—返回码转换成协议格式—>客户端—转成可读格式输出—>用户。
3 多机数据库的实现
3.1 复制
3.1.1 旧版本实现
Redis 的复制功能分为同步(sync)和命令传播(command propagate)两个操作:
- 同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态;
- 命令传播操作则用于在主服务器的数据库状态被修改, 导致主从服务器的数据库状态出现不一致时, 让主从服务器的数据库重新回到一致状态。
3.1.1.1 同步
当客户端向从服务器发送 SLAVEOF命令, 要求从服务器复制主服务器时, 从服务器首先需要执行同步操作, 也即是, 将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
从服务器对主服务器的同步操作需要通过向主服务器发送 SYNC命令来完成。步骤为:
- 从服务器向主服务器发送
SYNC; - 收到 SYNC 命令的主服务器执行
BGSAVE命令, 在后台生成一个RDB文件, 并使用一个缓冲区记录从现在开始执行的所有写命令; - 当主服务器的
BGSAVE命令执行完毕时, 主服务器会将 BGSAVE 命令生成的RDB文件发送给从服务器, 从服务器接收并载入这个RDB文件, 将自己的数据库状态更新至主服务器执行 BGSAVE 命令时的数据库状态; - 主服务器将记录在缓冲区里面的所有写命令发送给从服务器, 从服务器执行这些写命令, 将自己的数据库状态更新至主服务器数据库当前所处的状态。
3.1.1.2 命令传播
在同步操作执行完毕之后, 主从服务器两者的数据库将达到一致状态, 但这种一致并不是一成不变的 —— 每当主服务器执行客户端发送的写命令时, 主服务器的数据库就有可能会被修改, 并导致主从服务器状态不再一致。
为了让主从服务器再次回到一致状态, 主服务器需要对从服务器执行命令传播操作: 主服务器会将自己执行的写命令 —— 也即是造成主从服务器不一致的那条写命令 —— 发送给从服务器执行, 当从服务器执行了相同的写命令之后, 主从服务器将再次回到一致状态。
3.1.1.3 缺陷
SYNC命令是一个非常耗费资源的操作
每次执行SYNC命令,主从服务器需要执行以下动作:
- 主服务器需要执行BGSAVE命令来生成RDB文件,这个生成操作会耗费主服务器大量的CPU、内存和磁盘I/O资源。
- 主服务器需要将自己生成的RDB文件发送给从服务器,这个发送操作会耗费主从服务器大量的网络资源(带宽和流量),并对主服务器响应命令请求的时间产生影响。
- 接收到RDB文件的从服务器需要载入主服务器发来的RDB文件,并且在载入期间,从服务器会因为阻塞而没办法处理命令请求。
因为SYNC命令是一个如此耗费资源的操作,所以Redis有必要保证在真正有需要时才执行SYNC命令。
从服务器对主服务器的复制可以分为以下两种情况:
- 初次复制:从服务器以前没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同。
- 断线后重复制:处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过自动重连接重新连上了主服务器,并继续复制主服务器。
对于初次复制来说,旧版复制功能能够很好地完成任务,但对于断线后重复制来说,旧版复制功能虽然也能让主从服务器重新回到一致状态,但效率却非常低,从服务器需要让主服务器将所有执行的写命令的RDB文件,从新发送给从服务器。但主从服务器断开的时间可能很短,主服务器在断线期间执行的写命令可能很少,而执行少量写命令所产生的数据量通常比整个数据库的数据量要少得多,在这种情况下,为了让从服务器补足一小部分缺失的数据,却要让主从服务器重新执行一次SYNC命令,这种做法无疑是非常低效的。
3.1.2 新版实现
为了解决旧版复制功能在处理断线重复制情况时的低效问题,,Redis从2.8版本开始,使用PSYNC命令代替SYNC命令来执行复制时的同步操作。
PSYNC命令具有完整重同步( full resynchronization)和部分重同步( partial resynchronization)两种模式,
- 其中完整重同步用于处理初次复制情况:完整重同步的执行步骤和
SYNC命令的执行步骤基本一样,它们都是通过让主服务器创建并发送RDB文件,以及向从服务器发送保存在缓冲区里面的写命令来进行同步; - 部分重同步则用于处理断线后重复制情况:当从服务器在断线后重新连接主服务器时,如果条件允许,主服务器可以将主从服务器连接断开期间执行的写命令发送给从服务器,从服务器只要接收并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态。
PSYNC命令的部分重同步模式解决了旧版复制功能在处理断线后重复制时出现的低效情况。
3.1.2.1 部分同步的实现
部分重同步功能由以下三个部分构成:
- 主服务器的复制偏移量( replication offset )和从服务器的复制偏移量;
- 主服务器的复制积压缓冲区(replication backlog);
- 服务器的运行ID (run ID )。
复制偏移量:
执行复制的双方——主服务器和从服务器会分别维护一个复制偏移量:
- 主服务器每次向从服务器传播N个字节的数据时,就将自己的复制偏移量的值加上N;
- 从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N。
通过对比主从服务器的复制偏移量,程序可以很容易地知道主从服务器是否处于一致状态:
- 如果主从服务器处于一致状态,那么主从服务器两者的偏移量总是相同的;
- 相反,如果主从服务器两者的偏移量并不相同,那么说明主从服务器并未处于一致状态。
复制积压缓冲区:
复制积压缓冲区是由主服务器维护的一个固定长度(fixed-size )先进先出( FIFO )队列,默认大小为1MB。
当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器 还会将写命令人 队到复制积压缓冲区里面 。
因此,主服务器的复制积压缓冲区里面会保存着一部分最近传播的写命令,并且复制积压缓冲区会为队列中的每个字节记录相应的复制偏移量 。
当从服务器重新连上主服务器时,从服务器会通过PSYNC命令将自己的复制偏移量offset发送给主服务器,主服务器会根据这个复制偏移量来决定对从服务器执行何种同步操作:
- 如果offset偏移量之后的数据(也即是偏移量offset+1开始的数据)仍然存在于复制积压缓冲区里面、那么主服务器将对从服务器执行部分重同步操作;
- 相反,如果offset偏移量之后的数据已经不存在于复制积压缓冲区,那么主服务器将对从服务器执行完整重同步操作。
服务器运行ID:
除了复制偏移量和复制积压穿冲区之外,实现部分重同步还需要用到服务器运行ID:
- 每个Redis服务器,不论主服务器还是从服务,都会有自己的运行ID;
- 运行ID在服务器启动时自动生成,由40个随机的十六进制字符组成。
当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,而从服务器则会将这个运行ID保存起来。
当从服务器断线并重新连上一个主服务器时,从服务器将向当前连接的主服务器发送之前保存的运行ID:
- 如果从服务器保存的运行ID和当前连接的主服务器的运行ID相同,那么说明从服务器断线之前复制的就是当前连接的这个主服务器,主服务器可以继续尝试执行部分重同步操作;
- 相反地,如果从服务器保存的运行ID和当前连接的主服务器的运行ID并不相同,那么说明从服务器断线之前复制的主服务器并不是当前连接的这个主服务器,主服务器将对从服务器执行完整重同步操作。
3.2 Sentinel
redis-sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自懂切换。
它的主要功能有以下几点:
- 不时地监控redis是否按照预期良好地运行;
- 如果发现某个redis节点运行出现状况,能够通知另外一个进程(例如它的客户端);
- 能够进行自动切换。当一个master节点不可用时,能够选举出master的多个slave(如果有超过一个slave的话)中的一个来作为新的master,其它的slave节点会将它所追随的master的地址改为被提升为master的slave的新地址。
启动sentinel可以使用redis-sentinel /path/to/your/sentinel.conf或者redis-server /path/to/your/sentinel.conf --sentinel。启动一个sentinel时,它需要执行以下步骤:
- 初始化服务器;
- 将普通 Redis 服务器使用的代码替换成 Sentinel 专用代码;
- 初始化 Sentinel 状态;
- 根据给定的配置文件, 初始化 Sentinel 的监视主服务器列表;
- 创建连向主服务器的网络连接。
3.2.1 初始化服务器
因为 Sentinel 本质上只是一个运行在特殊模式下的 Redis 服务器, 所以启动 Sentinel 的第一步, 就是初始化一个普通的 Redis 服务器。但是Sentinel 执行的工作和普通 Redis 服务器执行的工作不同, 所以 Sentinel 的初始化过程和普通 Redis 服务器的初始化过程并不完全相同。
下表为Sentinel 模式下 Redis 服务器主要功能的使用情况:
| 功能 | 使用情况 |
|---|---|
| 数据库和键值对方面的命令, 比如 SET 、 DEL 、FLUSHDB 。 | 不使用。 |
| 事务命令, 比如 MULTI 和 WATCH 。 | 不使用。 |
| 脚本命令,比如 EVAL 。 | 不使用。 |
| RDB 持久化命令, 比如 SAVE 和 BGSAVE 。 | 不使用。 |
| AOF 持久化命令, 比如 BGREWRITEAOF 。 | 不使用。 |
| 复制命令,比如 SLAVEOF 。 | Sentinel 内部可以使用,但客户端不可以使用。 |
| 发布与订阅命令, 比如 PUBLISH 和 SUBSCRIBE 。 | SUBSCRIBE 、 PSUBSCRIBE 、 UNSUBSCRIBE PUNSUBSCRIBE 四个命令在 Sentinel 内部和客户端都可以使用, 但 PUBLISH 命令只能在 Sentinel 内部使用。 |
| 文件事件处理器(负责发送命令请求、处理命令回复)。 | Sentinel 内部使用, 但关联的文件事件处理器和普通 Redis 服务器不同。 |
| 时间事件处理器(负责执行 serverCron 函数)。 | Sentinel 内部使用, 时间事件的处理器仍然是 serverCron 函数, serverCron函数会调用 sentinel.c/sentinelTimer 函数, 后者包含了 Sentinel 要执行的所有操作。 |
3.2.2 使用 Sentinel 专用代码
struct redisCommand redisCommandTable[] = {
{"module",moduleCommand,-2,"as",0,NULL,0,0,0,0,0},
{"get",getCommand,2,"rF",0,NULL,1,1,1,0,0},
{"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0},
{"setnx",setnxCommand,3,"wmF",0,NULL,1,1,1,0,0},
{"setex",setexCommand,4,"wm",0,NULL,1,1,1,0,0},
{"psetex",psetexCommand,4,"wm",0,NULL,1,1,1,0,0},
{"append",appendCommand,3,"wm",0,NULL,1,1,1,0,0},
{"strlen",strlenCommand,2,"rF",0,NULL,1,1,1,0,0},
{"del",delCommand,-2,"w",0,NULL,1,-1,1,0,0},
{"unlink",unlinkCommand,-2,"wF",0,NULL,1,-1,1,0,0},
{"exists",existsCommand,-2,"rF",0,NULL,1,-1,1,0,0},
{"setbit",setbitCommand,4,"wm",0,NULL,1,1,1,0,0},
{"getbit",getbitCommand,3,"rF",0,NULL,1,1,1,0,0},
{"bitfield",bitfieldCommand,-2,"wm",0,NULL,1,1,1,0,0},
{"setrange",setrangeCommand,4,"wm",0,NULL,1,1,1,0,0},
{"getrange",getrangeCommand,4,"r",0,NULL,1,1,1,0,0},
{"substr",getrangeCommand,4,"r",0,NULL,1,1,1,0,0},
{"incr",incrCommand,2,"wmF",0,NULL,1,1,1,0,0},
{"decr",decrCommand,2,"wmF",0,NULL,1,1,1,0,0},
{"mget",mgetCommand,-2,"rF",0,NULL,1,-1,1,0,0},
{"rpush",rpushCommand,-3,"wmF",0,NULL,1,1,1,0,0},
{"lpush",lpushCommand,-3,"wmF",0,NULL,1,1,1,0,0},
{"rpushx",rpushxCommand,-3,"wmF",0,NULL,1,1,1,0,0},
{"lpushx",lpushxCommand,-3,"wmF",0,NULL,1,1,1,0,0},
{"linsert",linsertCommand,5,"wm",0,NULL,1,1,1,0,0},
{"rpop",rpopCommand,2,"wF",0,NULL,1,1,1,0,0},
{"lpop",lpopCommand,2,"wF",0,NULL,1,1,1,0,0},
{"brpop",brpopCommand,-3,"ws",0,NULL,1,-2,1,0,0},
{"brpoplpush",brpoplpushCommand,4,"wms",0,NULL,1,2,1,0,0},
{"blpop",blpopCommand,-3,"ws",0,NULL,1,-2,1,0,0},
{"llen",llenCommand,2,"rF",0,NULL,1,1,1,0,0},
{"lindex",lindexCommand,3,"r",0,NULL,1,1,1,0,0},
{"lset",lsetCommand,4,"wm",0,NULL,1,1,1,0,0},
{"lrange",lrangeCommand,4,"r",0,NULL,1,1,1,0,0},
{"ltrim",ltrimCommand,4,"w",0,NULL,1,1,1,0,0},
{"lrem",lremCommand,4,"w",0,NULL,1,1,1,0,0},
{"rpoplpush",rpoplpushCommand,3,"wm",0,NULL,1,2,1,0,0},
{"sadd",saddCommand,-3,"wmF",0,NULL,1,1,1,0,0},
{"srem",sremCommand,-3,"wF",0,NULL,1,1,1,0,0},
{"smove",smoveCommand,4,"wF",0,NULL,1,2,1,0,0},
{"sismember",sismemberCommand,3,"rF",0,NULL,1,1,1,0,0},
{"scard",scardCommand,2,"rF",0,NULL,1,1,1,0,0},
{"spop",spopCommand,-2,"wRF",0,NULL,1,1,1,0,0},
{"srandmember",srandmemberCommand,-2,"rR",0,NULL,1,1,1,0,0},
{"sinter",sinterCommand,-2,"rS",0,NULL,1,-1,1,0,0},
{"sinterstore",sinterstoreCommand,-3,"wm",0,NULL,1,-1,1,0,0},
{"sunion",sunionCommand,-2,"rS",0,NULL,1,-1,1,0,0},
{"sunionstore",sunionstoreCommand,-3,"wm",0,NULL,1,-1,1,0,0},
{"sdiff",sdiffCommand,-2,"rS",0,NULL,1,-1,1,0,0},
{"sdiffstore",sdiffstoreCommand,-3,"wm",0,NULL,1,-1,1,0,0},
{"smembers",sinterCommand,2,"rS",0,NULL,1,1,1,0,0},
{"sscan",sscanCommand,-3,"rR",0,NULL,1,1,1,0,0},
{"zadd",zaddCommand,-4,"wmF",0,NULL,1,1,1,0,0},
{"zincrby",zincrbyCommand,4,"wmF",0,NULL,1,1,1,0,0},
{"zrem",zremCommand,-3,"wF",0,NULL,1,1,1,0,0},
{"zremrangebyscore",zremrangebyscoreCommand,4,"w",0,NULL,1,1,1,0,0},
{"zremrangebyrank",zremrangebyrankCommand,4,"w",0,NULL,1,1,1,0,0},
{"zremrangebylex",zremrangebylexCommand,4,"w",0,NULL,1,1,1,0,0},
{"zunionstore",zunionstoreCommand,-4,"wm",0,zunionInterGetKeys,0,0,0,0,0},
{"zinterstore",zinterstoreCommand,-4,"wm",0,zunionInterGetKeys,0,0,0,0,0},
{"zrange",zrangeCommand,-4,"r",0,NULL,1,1,1,0,0},
{"zrangebyscore",zrangebyscoreCommand,-4,"r",0,NULL,1,1,1,0,0},
{"zrevrangebyscore",zrevrangebyscoreCommand,-4,"r",0,NULL,1,1,1,0,0},
{"zrangebylex",zrangebylexCommand,-4,"r",0,NULL,1,1,1,0,0},
{"zrevrangebylex",zrevrangebylexCommand,-4,"r",0,NULL,1,1,1,0,0},
{"zcount",zcountCommand,4,"rF",0,NULL,1,1,1,0,0},
{"zlexcount",zlexcountCommand,4,"rF",0,NULL,1,1,1,0,0},
{"zrevrange",zrevrangeCommand,-4,"r",0,NULL,1,1,1,0,0},
{"zcard",zcardCommand,2,"rF",0,NULL,1,1,1,0,0},
{"zscore",zscoreCommand,3,"rF",0,NULL,1,1,1,0,0},
{"zrank",zrankCommand,3,"rF",0,NULL,1,1,1,0,0},
{"zrevrank",zrevrankCommand,3,"rF",0,NULL,1,1,1,0,0},
{"zscan",zscanCommand,-3,"rR",0,NULL,1,1,1,0,0},
{"zpopmin",zpopminCommand,-2,"wF",0,NULL,1,1,1,0,0},
{"zpopmax",zpopmaxCommand,-2,"wF",0,NULL,1,1,1,0,0},
{"bzpopmin",bzpopminCommand,-3,"wsF",0,NULL,1,-2,1,0,0},
{"bzpopmax",bzpopmaxCommand,-3,"wsF",0,NULL,1,-2,1,0,0},
{"hset",hsetCommand,-4,"wmF",0,NULL,1,1,1,0,0},
{"hsetnx",hsetnxCommand,4,"wmF",0,NULL,1,1,1,0,0},
{"hget",hgetCommand,3,"rF",0,NULL,1,1,1,0,0},
{"hmset",hsetCommand,-4,"wmF",0,NULL,1,1,1,0,0},
{"hmget",hmgetCommand,-3,"rF",0,NULL,1,1,1,0,0},
{"hincrby",hincrbyCommand,4,"wmF",0,NULL,1,1,1,0,0},
{"hincrbyfloat",hincrbyfloatCommand,4,"wmF",0,NULL,1,1,1,0,0},
{"hdel",hdelCommand,-3,"wF",0,NULL,1,1,1,0,0},
{"hlen",hlenCommand,2,"rF",0,NULL,1,1,1,0,0},
{"hstrlen",hstrlenCommand,3,"rF",0,NULL,1,1,1,0,0},
{"hkeys",hkeysCommand,2,"rS",0,NULL,1,1,1,0,0},
{"hvals",hvalsCommand,2,"rS",0,NULL,1,1,1,0,0},
{"hgetall",hgetallCommand,2,"rR",0,NULL,1,1,1,0,0},
{"hexists",hexistsCommand,3,"rF",0,NULL,1,1,1,0,0},
{"hscan",hscanCommand,-3,"rR",0,NULL,1,1,1,0,0},
{"incrby",incrbyCommand,3,"wmF",0,NULL,1,1,1,0,0},
{"decrby",decrbyCommand,3,"wmF",0,NULL,1,1,1,0,0},
{"incrbyfloat",incrbyfloatCommand,3,"wmF",0,NULL,1,1,1,0,0},
{"getset",getsetCommand,3,"wm",0,NULL,1,1,1,0,0},
{"mset",msetCommand,-3,"wm",0,NULL,1,-1,2,0,0},
{"msetnx",msetnxCommand,-3,"wm",0,NULL,1,-1,2,0,0},
{"randomkey",randomkeyCommand,1,"rR",0,NULL,0,0,0,0,0},
{"select",selectCommand,2,"lF",0,NULL,0,0,0,0,0},
{"swapdb",swapdbCommand,3,"wF",0,NULL,0,0,0,0,0},
{"move",moveCommand,3,"wF",0,NULL,1,1,1,0,0},
{"rename",renameCommand,3,"w",0,NULL,1,2,1,0,0},
{"renamenx",renamenxCommand,3,"wF",0,NULL,1,2,1,0,0},
{"expire",expireCommand,3,"wF",0,NULL,1,1,1,0,0},
{"expireat",expireatCommand,3,"wF",0,NULL,1,1,1,0,0},
{"pexpire",pexpireCommand,3,"wF",0,NULL,1,1,1,0,0},
{"pexpireat",pexpireatCommand,3,"wF",0,NULL,1,1,1,0,0},
{"keys",keysCommand,2,"rS",0,NULL,0,0,0,0,0},
{"scan",scanCommand,-2,"rR",0,NULL,0,0,0,0,0},
{"dbsize",dbsizeCommand,1,"rF",0,NULL,0,0,0,0,0},
{"auth",authCommand,2,"sltF",0,NULL,0,0,0,0,0},
{"ping",pingCommand,-1,"tF",0,NULL,0,0,0,0,0},
{"echo",echoCommand,2,"F",0,NULL,0,0,0,0,0},
{"save",saveCommand,1,"as",0,NULL,0,0,0,0,0},
{"bgsave",bgsaveCommand,-1,"as",0,NULL,0,0,0,0,0},
{"bgrewriteaof",bgrewriteaofCommand,1,"as",0,NULL,0,0,0,0,0},
{"shutdown",shutdownCommand,-1,"aslt",0,NULL,0,0,0,0,0},
{"lastsave",lastsaveCommand,1,"RF",0,NULL,0,0,0,0,0},
{"type",typeCommand,2,"rF",0,NULL,1,1,1,0,0},
{"multi",multiCommand,1,"sF",0,NULL,0,0,0,0,0},
{"exec",execCommand,1,"sM",0,NULL,0,0,0,0,0},
{"discard",discardCommand,1,"sF",0,NULL,0,0,0,0,0},
{"sync",syncCommand,1,"ars",0,NULL,0,0,0,0,0},
{"psync",syncCommand,3,"ars",0,NULL,0,0,0,0,0},
{"replconf",replconfCommand,-1,"aslt",0,NULL,0,0,0,0,0},
{"flushdb",flushdbCommand,-1,"w",0,NULL,0,0,0,0,0},
{"flushall",flushallCommand,-1,"w",0,NULL,0,0,0,0,0},
{"sort",sortCommand,-2,"wm",0,sortGetKeys,1,1,1,0,0},
{"info",infoCommand,-1,"ltR",0,NULL,0,0,0,0,0},
{"monitor",monitorCommand,1,"as",0,NULL,0,0,0,0,0},
{"ttl",ttlCommand,2,"rFR",0,NULL,1,1,1,0,0},
{"touch",touchCommand,-2,"rF",0,NULL,1,1,1,0,0},
{"pttl",pttlCommand,2,"rFR",0,NULL,1,1,1,0,0},
{"persist",persistCommand,2,"wF",0,NULL,1,1,1,0,0},
{"slaveof",replicaofCommand,3,"ast",0,NULL,0,0,0,0,0},
{"replicaof",replicaofCommand,3,"ast",0,NULL,0,0,0,0,0},
{"role",roleCommand,1,"lst",0,NULL,0,0,0,0,0},
{"debug",debugCommand,-2,"as",0,NULL,0,0,0,0,0},
{"config",configCommand,-2,"last",0,NULL,0,0,0,0,0},
{"subscribe",subscribeCommand,-2,"pslt",0,NULL,0,0,0,0,0},
{"unsubscribe",unsubscribeCommand,-1,"pslt",0,NULL,0,0,0,0,0},
{"psubscribe",psubscribeCommand,-2,"pslt",0,NULL,0,0,0,0,0},
{"punsubscribe",punsubscribeCommand,-1,"pslt",0,NULL,0,0,0,0,0},
{"publish",publishCommand,3,"pltF",0,NULL,0,0,0,0,0},
{"pubsub",pubsubCommand,-2,"pltR",0,NULL,0,0,0,0,0},
{"watch",watchCommand,-2,"sF",0,NULL,1,-1,1,0,0},
{"unwatch",unwatchCommand,1,"sF",0,NULL,0,0,0,0,0},
{"cluster",clusterCommand,-2,"a",0,NULL,0,0,0,0,0},
{"restore",restoreCommand,-4,"wm",0,NULL,1,1,1,0,0},
{"restore-asking",restoreCommand,-4,"wmk",0,NULL,1,1,1,0,0},
{"migrate",migrateCommand,-6,"wR",0,migrateGetKeys,0,0,0,0,0},
{"asking",askingCommand,1,"F",0,NULL,0,0,0,0,0},
{"readonly",readonlyCommand,1,"F",0,NULL,0,0,0,0,0},
{"readwrite",readwriteCommand,1,"F",0,NULL,0,0,0,0,0},
{"dump",dumpCommand,2,"rR",0,NULL,1,1,1,0,0},
{"object",objectCommand,-2,"rR",0,NULL,2,2,1,0,0},
{"memory",memoryCommand,-2,"rR",0,NULL,0,0,0,0,0},
{"client",clientCommand,-2,"as",0,NULL,0,0,0,0,0},
{"eval",evalCommand,-3,"s",0,evalGetKeys,0,0,0,0,0},
{"evalsha",evalShaCommand,-3,"s",0,evalGetKeys,0,0,0,0,0},
{"slowlog",slowlogCommand,-2,"aR",0,NULL,0,0,0,0,0},
{"script",scriptCommand,-2,"s",0,NULL,0,0,0,0,0},
{"time",timeCommand,1,"RF",0,NULL,0,0,0,0,0},
{"bitop",bitopCommand,-4,"wm",0,NULL,2,-1,1,0,0},
{"bitcount",bitcountCommand,-2,"r",0,NULL,1,1,1,0,0},
{"bitpos",bitposCommand,-3,"r",0,NULL,1,1,1,0,0},
{"wait",waitCommand,3,"s",0,NULL,0,0,0,0,0},
{"command",commandCommand,0,"ltR",0,NULL,0,0,0,0,0},
{"geoadd",geoaddCommand,-5,"wm",0,NULL,1,1,1,0,0},
{"georadius",georadiusCommand,-6,"w",0,georadiusGetKeys,1,1,1,0,0},
{"georadius_ro",georadiusroCommand,-6,"r",0,georadiusGetKeys,1,1,1,0,0},
{"georadiusbymember",georadiusbymemberCommand,-5,"w",0,georadiusGetKeys,1,1,1,0,0},
{"georadiusbymember_ro",georadiusbymemberroCommand,-5,"r",0,georadiusGetKeys,1,1,1,0,0},
{"geohash",geohashCommand,-2,"r",0,NULL,1,1,1,0,0},
{"geopos",geoposCommand,-2,"r",0,NULL,1,1,1,0,0},
{"geodist",geodistCommand,-4,"r",0,NULL,1,1,1,0,0},
{"pfselftest",pfselftestCommand,1,"a",0,NULL,0,0,0,0,0},
{"pfadd",pfaddCommand,-2,"wmF",0,NULL,1,1,1,0,0},
{"pfcount",pfcountCommand,-2,"r",0,NULL,1,-1,1,0,0},
{"pfmerge",pfmergeCommand,-2,"wm",0,NULL,1,-1,1,0,0},
{"pfdebug",pfdebugCommand,-3,"w",0,NULL,0,0,0,0,0},
{"xadd",xaddCommand,-5,"wmFR",0,NULL,1,1,1,0,0},
{"xrange",xrangeCommand,-4,"r",0,NULL,1,1,1,0,0},
{"xrevrange",xrevrangeCommand,-4,"r",0,NULL,1,1,1,0,0},
{"xlen",xlenCommand,2,"rF",0,NULL,1,1,1,0,0},
{"xread",xreadCommand,-4,"rs",0,xreadGetKeys,1,1,1,0,0},
{"xreadgroup",xreadCommand,-7,"ws",0,xreadGetKeys,1,1,1,0,0},
{"xgroup",xgroupCommand,-2,"wm",0,NULL,2,2,1,0,0},
{"xsetid",xsetidCommand,3,"wmF",0,NULL,1,1,1,0,0},
{"xack",xackCommand,-4,"wF",0,NULL,1,1,1,0,0},
{"xpending",xpendingCommand,-3,"rR",0,NULL,1,1,1,0,0},
{"xclaim",xclaimCommand,-6,"wRF",0,NULL,1,1,1,0,0},
{"xinfo",xinfoCommand,-2,"rR",0,NULL,2,2,1,0,0},
{"xdel",xdelCommand,-3,"wF",0,NULL,1,1,1,0,0},
{"xtrim",xtrimCommand,-2,"wFR",0,NULL,1,1,1,0,0},
{"post",securityWarningCommand,-1,"lt",0,NULL,0,0,0,0,0},
{"host:",securityWarningCommand,-1,"lt",0,NULL,0,0,0,0,0},
{"latency",latencyCommand,-2,"aslt",0,NULL,0,0,0,0,0},
{"lolwut",lolwutCommand,-1,"r",0,NULL,0,0,0,0,0}
};
struct redisCommand sentinelcmds[] = {
{"ping",pingCommand,1,"",0,NULL,0,0,0,0,0},
{"sentinel",sentinelCommand,-2,"",0,NULL,0,0,0,0,0},
{"subscribe",subscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"unsubscribe",unsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"psubscribe",psubscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"punsubscribe",punsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"publish",sentinelPublishCommand,3,"",0,NULL,0,0,0,0,0},
{"info",sentinelInfoCommand,-1,"",0,NULL,0,0,0,0,0},
{"role",sentinelRoleCommand,1,"l",0,NULL,0,0,0,0,0},
{"client",clientCommand,-2,"rs",0,NULL,0,0,0,0,0},
{"shutdown",shutdownCommand,-1,"",0,NULL,0,0,0,0,0},
{"auth",authCommand,2,"sltF",0,NULL,0,0,0,0,0}
};
3.2.3 初始化 Sentinel 状态
接下来, 服务器会初始化一个 sentinel.c/sentinelState 结构(后面简称“Sentinel 状态”), 这个结构保存了服务器中所有和 Sentinel 功能有关的状态 (服务器的一般状态仍然由 redis.h/redisServer 结构保存)。
/* Main state. */
struct sentinelState {
char myid[CONFIG_RUN_ID_SIZE+1]; /* This sentinel ID. */
uint64_t current_epoch; /* Current epoch. */
dict *masters; /* Dictionary of master sentinelRedisInstances.
Key is the instance name, value is the
sentinelRedisInstance structure pointer. */
int tilt; /* Are we in TILT mode? */
int running_scripts; /* Number of scripts in execution right now. */
mstime_t tilt_start_time; /* When TITL started. */
mstime_t previous_time; /* Last time we ran the time handler. */
list *scripts_queue; /* Queue of user scripts to execute. */
char *announce_ip; /* IP addr that is gossiped to other sentinels if
not NULL. */
int announce_port; /* Port that is gossiped to other sentinels if
non zero. */
unsigned long simfailure_flags; /* Failures simulation. */
int deny_scripts_reconfig; /* Allow SENTINEL SET ... to change script
paths at runtime? */
} sentinel;
3.2.4 初始化 Sentinel 状态的 masters 属性
Sentinel 状态中的 masters 字典记录了所有被 Sentinel 监视的主服务器的相关信息
- 字典的键是被监视主服务器的名字;
- 字典的值则是被监视主服务器对应的 sentinel.c/sentinelRedisInstance 结构。
每个 sentinelRedisInstance 结构(后面简称“实例结构”)代表一个被 Sentinel 监视的 Redis 服务器实例(instance), 这个实例可以是主服务器、从服务器、或者另外一个 Sentinel 。
typedef struct sentinelRedisInstance {
int flags; /* See SRI_... defines */
char *name; /* Master name from the point of view of this sentinel. */
char *runid; /* Run ID of this instance, or unique ID if is a Sentinel.*/
uint64_t config_epoch; /* Configuration epoch. */
sentinelAddr *addr; /* Master host. */
instanceLink *link; /* Link to the instance, may be shared for Sentinels. */
mstime_t last_pub_time; /* Last time we sent hello via Pub/Sub. */
mstime_t last_hello_time; /* Only used if SRI_SENTINEL is set. Last time
we received a hello from this Sentinel
via Pub/Sub. */
mstime_t last_master_down_reply_time; /* Time of last reply to
SENTINEL is-master-down command. */
mstime_t s_down_since_time; /* Subjectively down since time. */
mstime_t o_down_since_time; /* Objectively down since time. */
mstime_t down_after_period; /* Consider it down after that period. */
mstime_t info_refresh; /* Time at which we received INFO output from it. */
dict *renamed_commands; /* Commands renamed in this instance:
Sentinel will use the alternative commands
mapped on this table to send things like
SLAVEOF, CONFING, INFO, ... */
/* Role and the first time we observed it.
* This is useful in order to delay replacing what the instance reports
* with our own configuration. We need to always wait some time in order
* to give a chance to the leader to report the new configuration before
* we do silly things. */
int role_reported;
mstime_t role_reported_time;
mstime_t slave_conf_change_time; /* Last time slave master addr changed. */
/* Master specific. */
dict *sentinels; /* Other sentinels monitoring the same master. */
dict *slaves; /* Slaves for this master instance. */
unsigned int quorum;/* Number of sentinels that need to agree on failure. */
int parallel_syncs; /* How many slaves to reconfigure at same time. */
char *auth_pass; /* Password to use for AUTH against master & slaves. */
/* Slave specific. */
mstime_t master_link_down_time; /* Slave replication link down time. */
int slave_priority; /* Slave priority according to its INFO output. */
mstime_t slave_reconf_sent_time; /* Time at which we sent SLAVE OF <new> */
struct sentinelRedisInstance *master; /* Master instance if it's slave. */
char *slave_master_host; /* Master host as reported by INFO */
int slave_master_port; /* Master port as reported by INFO */
int slave_master_link_status; /* Master link status as reported by INFO */
unsigned long long slave_repl_offset; /* Slave replication offset. */
/* Failover */
char *leader; /* If this is a master instance, this is the runid of
the Sentinel that should perform the failover. If
this is a Sentinel, this is the runid of the Sentinel
that this Sentinel voted as leader. */
uint64_t leader_epoch; /* Epoch of the 'leader' field. */
uint64_t failover_epoch; /* Epoch of the currently started failover. */
int failover_state; /* See SENTINEL_FAILOVER_STATE_* defines. */
mstime_t failover_state_change_time;
mstime_t failover_start_time; /* Last failover attempt start time. */
mstime_t failover_timeout; /* Max time to refresh failover state. */
mstime_t failover_delay_logged; /* For what failover_start_time value we
logged the failover delay. */
struct sentinelRedisInstance *promoted_slave; /* Promoted slave instance. */
/* Scripts executed to notify admin or reconfigure clients: when they
* are set to NULL no script is executed. */
char *notification_script;
char *client_reconfig_script;
sds info; /* cached INFO output */
} sentinelRedisInstance;
/* Address object, used to describe an ip:port pair. */
typedef struct sentinelAddr {
char *ip;
int port;
} sentinelAddr;
对 Sentinel 状态的初始化将引发对 masters 字典的初始化, 而 masters 字典的初始化是根据被载入的 Sentinel 配置文件来进行的。
3.2.5 创建连向主服务器的网络连接
初始化 Sentinel 的最后一步是创建连向被监视主服务器的网络连接: Sentinel 将成为主服务器的客户端, 它可以向主服务器发送命令, 并从命令回复中获取相关的信息。
对于每个被 Sentinel 监视的主服务器来说, Sentinel 会创建两个连向主服务器的异步网络连接:
- 一个是命令连接, 这个连接专门用于向主服务器发送命令, 并接收命令回复。
- 一个是订阅连接, 这个连接专门用于订阅主服务器的
__sentinel__:hello频道。
需要两个链接的原因:
在 Redis 目前的发布与订阅功能中, 被发送的信息都不会保存在 Redis 服务器里面, 如果在信息发送时, 想要接收信息的客户端不在线或者断线, 那么这个客户端就会丢失这条信息。
因此, 为了不丢失 __sentinel__:hello频道的任何信息, Sentinel 必须专门用一个订阅连接来接收该频道的信息。
而另一方面, 除了订阅频道之外, Sentinel 还又必须向主服务器发送命令, 以此来与主服务器进行通讯, 所以 Sentinel 还必须向主服务器创建命令连接。并且因为 Sentinel 需要与多个实例创建多个网络连接, 所以 Sentinel 使用的是异步连接。
3.3 集群
一个 Redis 集群通常由多个节点(node)组成, 在刚开始的时候, 每个节点都是相互独立的, 它们都处于一个只包含自己的集群当中, 要组建一个真正可工作的集群, 我们必须将各个独立的节点连接起来, 构成一个包含多个节点的集群。
3.3.1 链接节点
向一个节点 node 发送CLUSTER MEET命令, 可以让 node 节点与 ip 和 port 所指定的节点进行握手(handshake), 当握手成功时, node节点就会将 ip 和 port 所指定的节点添加到 node 节点当前所在的集群中。
CLUSTER MEET <ip> <port>
3.3.2 启动节点
一个节点就是一个运行在集群模式下的 Redis 服务器, Redis 服务器在启动时会根据 cluster-enabled配置选项的是否为 yes 来决定是否开启服务器的集群模式。
节点(运行在集群模式下的 Redis 服务器)会继续使用所有在单机模式中使用的服务器组件, 比如说:
- 节点会继续使用文件事件处理器来处理命令请求和返回命令回复;
- 节点会继续使用时间事件处理器来执行
serverCron函数, 而serverCron函数又会调用集群模式特有的clusterCron函数:clusterCron函数负责执行在集群模式下需要执行的常规操作, 比如向集群中的其他节点发送 Gossip 消息, 检查节点是否断线; 又或者检查是否需要对下线节点进行自动故障转移, 等等; - 节点会继续使用数据库来保存键值对数据,键值对依然会是各种不同类型的对象;
- 节点会继续使用 RDB 持久化模块和 AOF 持久化模块来执行持久化工作;
- 节点会继续使用发布与订阅模块来执行
PUBLISH 、 SUBSCRIBE等命令; - 节点会继续使用复制模块来进行节点的复制工作;
- 节点会继续使用 Lua 脚本环境来执行客户端输入的 Lua 脚本。
除此之外, 节点会继续使用redisServer结构来保存服务器的状态, 使用 redisClient结构来保存客户端的状态, 至于那些只有在集群模式下才会用到的数据, 节点将它们保存到了 cluster.h/clusterNode结构,cluster.h/clusterLink结构, 以及 cluster.h/clusterState结构里面。
3.3.3 集群数据结构
clusterNode结构保存了一个节点的当前状态。每个节点都会使用一个 clusterNode结构来记录自己的状态, 并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构, 以此来记录其他节点的状态。
typedef struct clusterNode {
mstime_t ctime; /* Node object creation time. */
char name[CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
int flags; /* CLUSTER_NODE_... */
uint64_t configEpoch; /* Last configEpoch observed for this node */
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
int numslaves; /* Number of slave nodes, if this is a master */
struct clusterNode **slaves; /* pointers to slave nodes */
struct clusterNode *slaveof; /* pointer to the master node. Note that it
may be NULL even if the node is a slave
if we don't have the master node in our
tables. */
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
mstime_t orphaned_time; /* Starting time of orphaned master condition */
long long repl_offset; /* Last known repl offset for this node. */
char ip[NET_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known clients port of this node */
int cport; /* Latest known cluster port of this node. */
clusterLink *link; /* TCP/IP link with this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
clusterNode结构的 link属性是一个clusterLink结构, 该结构保存了连接节点所需的有关信息, 比如套接字描述符, 输入缓冲区和输出缓冲区。
/* clusterLink encapsulates everything needed to talk with a remote node. */
typedef struct clusterLink {
mstime_t ctime; /* Link creation time */
int fd; /* TCP socket file descriptor */
sds sndbuf; /* Packet send buffer */
sds rcvbuf; /* Packet reception buffer */
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;
redisClient 结构和 clusterLink 结构都有自己的套接字描述符和输入、输出缓冲区, 这两个结构的区别在于, redisClient 结构中的套接字和缓冲区是用于连接客户端的, 而 clusterLink 结构中的套接字和缓冲区则是用于连接节点的。
每个节点都保存着一个 clusterState 结构, 这个结构记录了在当前节点的视角下, 集群目前所处的状态 —— 比如集群是在线还是下线, 集群包含多少个节点, 集群当前的配置纪元, 诸如此类。
typedef struct clusterState {
clusterNode *myself; /* This node */
uint64_t currentEpoch;
int state; /* CLUSTER_OK, CLUSTER_FAIL, ... */
int size; /* Num of master nodes with at least one slot */
dict *nodes; /* Hash table of name -> clusterNode structures */
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
clusterNode *migrating_slots_to[CLUSTER_SLOTS];
clusterNode *importing_slots_from[CLUSTER_SLOTS];
clusterNode *slots[CLUSTER_SLOTS];
uint64_t slots_keys_count[CLUSTER_SLOTS];
rax *slots_to_keys;
/* The following fields are used to take the slave state on elections. */
mstime_t failover_auth_time; /* Time of previous or next election. */
int failover_auth_count; /* Number of votes received so far. */
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
int cant_failover_reason; /* Why a slave is currently not able to
failover. See the CANT_FAILOVER_* macros. */
/* Manual failover state in common. */
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
long long mf_master_offset; /* Master offset the slave needs to start MF
or zero if stil not received. */
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The followign fields are used by masters to take state on elections. */
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
/* Messages received and sent by type. */
long long stats_bus_messages_sent[CLUSTERMSG_TYPE_COUNT];
long long stats_bus_messages_received[CLUSTERMSG_TYPE_COUNT];
long long stats_pfail_nodes; /* Number of nodes in PFAIL status,
excluding nodes without address. */
} clusterState;
3.3.4 CLUSTER MEET 命令的实现
- 节点 A 会为节点 B 创建一个
clusterNode结构, 并将该结构添加到自己的clusterState.nodes字典里面。 - 之后, 节点 A 将根据
CLUSTER MEET命令给定的 IP 地址和端口号, 向节点 B 发送一条 MEET 消息(message)。 - 如果一切顺利, 节点 B 将接收到节点 A 发送的 MEET 消息, 节点 B 会为节点 A 创建一个
clusterNode结构, 并将该结构添加到自己的clusterState.nodes字典里面。 - 之后, 节点 B 将向节点 A 返回一条 PONG 消息。
- 如果一切顺利, 节点 A 将接收到节点 B 返回的
PONG消息, 通过这条 PONG 消息节点 A 可以知道节点 B 已经成功地接收到了自己发送的 MEET 消息。 - 之后, 节点 A 将向节点 B 返回一条
PING消息。 - 如果一切顺利, 节点 B 将接收到节点 A 返回的 PING 消息, 通过这条
PING消息节点 B 可以知道节点 A 已经成功地接收到了自己返回的PONG消息, 握手完成。
之后, 节点 A 会将节点 B 的信息通过 Gossip协议传播给集群中的其他节点, 让其他节点也与节点 B 进行握手, 最终, 经过一段时间之后, 节点 B 会被集群中的所有节点认识。
4 独立功能的实现
4.1 频道订阅与退订
当一个客户端执行 SUBSCRIBE命令, 订阅某个或某些频道的时候, 这个客户端与被订阅频道之间就建立起了一种订阅关系。redis将所有频道的订阅关系都保存在服务器状态的 pubsub_channels字典里面, 这个字典的键是某个被订阅的频道, 而键的值则是一个链表, 链表里面记录了所有订阅这个频道的客户端。
struct redisServer{
dict *pubsub_channels; /* channels a client is interested in (SUBSCRIBE) */
list *pubsub_patterns; /* patterns a client is interested in (SUBSCRIBE) */
};
4.1.1 订阅频道
每当客户端执行 SUBSCRIBE命令, 订阅某个或某些频道的时候, 服务器都会将客户端与被订阅的频道在 pubsub_channels字典中进行关联。
根据频道是否已经有其他订阅者, 关联操作分为两种情况执行:
- 如果频道已经有其他订阅者, 那么它在
pubsub_channels字典中必然有相应的订阅者链表, 程序唯一要做的就是将客户端添加到订阅者链表的末尾; - 如果频道还未有任何订阅者, 那么它必然不存在于
pubsub_channels字典, 程序首先要在pubsub_channels字典中为频道创建一个键, 并将这个键的值设置为空链表, 然后再将客户端添加到链表, 成为链表的第一个元素。
4.1.2 退订频道
UNSUBSCRIBE命令的行为和 SUBSCRIBE命令的行为正好相反 —— 当一个客户端退订某个或某些频道的时候, 服务器将从pubsub_channels中解除客户端与被退订频道之间的关联:
- 程序会根据被退订频道的名字, 在
pubsub_channels字典中找到频道对应的订阅者链表, 然后从订阅者链表中删除退订客户端的信息; - 如果删除退订客户端之后, 频道的订阅者链表变成了空链表, 那么说明这个频道已经没有任何订阅者了, 程序将从
pubsub_channels字典中删除频道对应的键。
4.2 事务
一个事务从开始到结束通常会经历以下三个阶段:
- 事务开始;
- 命令入队;
- 事务执行。
事务开始:
MULTI命令的执行标志着事务的开始。MULTI命令可以将执行该命令的客户端从非事务状态切换至事务状态, 这一切换是通过在客户端状态的 flags属性中打开 CLIENT_MULTI标识来完成的。
事务入队:
当一个客户端处于非事务状态时, 这个客户端发送的命令会立即被服务器执行。与此不同的是, 当一个客户端切换到事务状态之后, 服务器会根据这个客户端发来的不同命令执行不同的操作:
如果客户端发送的命令为 EXEC 、 DISCARD 、 WATCH 、 MULTI四个命令的其中一个, 那么服务器立即执行这个命令。
与此相反, 如果客户端发送的命令是 EXEC 、 DISCARD 、 WATCH 、 MULTI四个命令以外的其他命令, 那么服务器并不立即执行这个命令, 而是将这个命令放入一个事务队列里面, 然后向客户端返回 QUEUED回复。
事务队列:
每个 Redis 客户端都有自己的事务状态, 这个事务状态保存在客户端状态的 mstate属性里面。事务状态包含一个事务队列, 以及一个已入队命令的计数器 (也可以说是事务队列的长度)。事务队列是一个 multiCmd 类型的数组, 数组中的每个 multiCmd结构都保存了一个已入队命令的相关信息, 包括指向命令实现函数的指针, 命令的参数, 以及参数的数量。事务队列以先进先出(FIFO)的方式保存入队的命令: 较先入队的命令会被放到数组的前面, 而较后入队的命令则会被放到数组的后面。
struct client{
multiState mstate;
};
typedef struct multiState {
multiCmd *commands; /* Array of MULTI commands */
int count; /* Total number of MULTI commands */
int cmd_flags; /* The accumulated command flags OR-ed together.
So if at least a command has a given flag, it
will be set in this field. */
int minreplicas; /* MINREPLICAS for synchronous replication */
time_t minreplicas_timeout; /* MINREPLICAS timeout as unixtime. */
} multiState;
/* Client MULTI/EXEC state */
typedef struct multiCmd {
robj **argv;
int argc;
struct redisCommand *cmd;
} multiCmd;
执行事务:
当一个处于事务状态的客户端向服务器发送 EXEC命令时, 这个 EXEC命令将立即被服务器执行: 服务器会遍历这个客户端的事务队列, 执行队列中保存的所有命令, 最后将执行命令所得的结果全部返回给客户端。
4.3 lua脚本
4.4 排序
SORT命令可以对数据进行排序。SORT 命令为每个被排序的键都创建一个与键长度相同的数组, 数组的每个项都是一个 redisSortObject 结构, 根据 SORT 命令使用的选项不同, 程序使用 redisSortObject 结构的方式也不同。
typedef struct _redisSortObject {
robj *obj;
union {
double score;
robj *cmpobj;
} u;
} redisSortObject;
typedef struct _redisSortOperation {
int type;
robj *pattern;
} redisSortOperation;
4.5 二进制位数组
GETBIT 命令用于返回位数组 bitarray 在 offset 偏移量上的二进制位的值。
GETBIT 命令的执行过程如下:
- 计算 $byte = \lfloor offset \div 8 \rfloor $, byte 值记录了 offset 偏移量指定的二进制位保存在位数组的哪个字节。
- 计算 $bit = (offset \bmod 8) + 1 $, bit 值记录了 offset 偏移量指定的二进制位是 byte 字节的第几个二进制位。
- 根据 byte 值和 bit 值, 在位数组 bitarray 中定位 offset 偏移量指定的二进制位, 并返回这个位的值。
4.6 慢查询日志
Redis 的慢查询日志功能用于记录执行时间超过给定时长的命令请求, 用户可以通过这个功能产生的日志来监视和优化查询速度。
4.7 监视器
发送 MONITOR 命令可以让一个普通客户端变为一个监视器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









