







似乎很多人不理解voliate和atomic啥区别,本文主要主要描述volatile的作用和使用场景。对比了atomic和volatile的区别,以及性能差异。最后补充了几条可能导致C++代码测试volatile导致正确结果错误结论的依据。
1 volatile
1.1 c++标准中对于volatile的定义
Every access (read or write operation, member function call, etc.) made through a glvalue expression of volatile-qualified type is treated as a visible side-effect for the purposes of optimization (that is, within a single thread of execution, volatile accesses cannot be optimized out or reordered with another visible side effect that is sequenced-before or sequenced-after the volatile access. This makes volatile objects suitable for communication with a signal handler, but not with another thread of execution, see std::memory_order). Any attempt to access a volatile object through a glvalue of non-volatile type (e.g. through a reference or pointer to non-volatile type) results in undefined behavior.
CPP Reference中说的很清楚volatile的作用有两个:
- 提醒编译器不要对该变量相关的代码进行优化,避免出现意外的负面作用;
- 对类似的表达式不进行编译层面的指令重排。编译指令重排也是一种编译器优化手段,这条严格来说也是第一条的变种。
下面看一段比较简单的代码:
std::atomic<int> i = 0;
volatile int j = 0;
int g = 0;
int n = 100000000;
void func() {
for (int a = 0; a < n; a++) {
i++;
}
}
//func对应的汇编
//00AB1010 mov eax,5F5E100h
//00AB1015 lock inc dword ptr [i (0AB53FCh)]
//00AB101C sub eax,1
//00AB101F jne func+5h (0AB1015h)
void func1() {
for (int a = 0; a < n; a++) {
j++;
}
}
//func1 对应的汇编
//00AB1030 mov eax,5F5E100h
//00AB1035 nop word ptr [eax+eax]
//00AB1040 mov ecx,dword ptr [j (0AB53F8h)]
//00AB1046 inc ecx
//00AB1047 mov dword ptr [j (0AB53F8h)],ecx
//00AB104D sub eax,1
//00AB1050 jne func1+10h (0AB1040h)
void func2() {
for (int a = 0; a < n; a++) {
g++;
}
}
//func2对应的汇编
//add dword ptr [g (0AB5400h)],5F5E100h
上面的代码中可以看到对于普通变量的++直接被编译器在编译期间就分析出来结果,直接赋值了,for循环直接被干掉了。为了避免编译器在编译期间计算出结果,我们加一行printf。
void func1() {
for (int a = 0; a < n; a++) {
j++;
printf("");
}
}
//00CD1071 mov esi,5F5E100h
//00CD1076 nop word ptr [eax+eax]
//00CD1080 mov eax,dword ptr [j (0CD53F0h)]
//00CD1085 inc eax
//00CD1086 push offset string "" (0CD31C8h)
//00CD108B mov dword ptr [j (0CD53F0h)],eax
//00CD1090 call printf (0CD1010h)
//00CD1095 add esp,4
//00CD1098 sub esi,1
//00CD109B jne func1+10h (0CD1080h)
void func2() {
for (int a = 0; a < n; a++) {
g++;
printf("");
}
}
// for (int a = 0; a < n; a++) {
//00CD10A1 mov esi,5F5E100h
//00CD10A6 nop word ptr [eax+eax]
//00CD10B0 inc dword ptr [g (0CD53F8h)]
//00CD10B6 push offset string "" (0CD31C8h)
//00CD10BB call printf (0CD1010h)
//00CD10C0 add esp,4
//00CD10C3 sub esi,1
//00CD10C6 jne func2+10h (0CD10B0h)
可以看到普通类型编译的代码直接操作的内存,而volatile修饰的代码和没有开优化的代码一样。
顺带贴一段llvm中关于volatile的描述。
If R is volatile, the result is target-dependent. (Volatile is supposed to give guarantees which can support
sig_atomic_tin C/C++, and may be used for accesses to addresses that do not behave like normal memory. It does not generally provide cross-thread synchronization.
1.2 volatile的实际应用
volatile主要应用是和硬件打交道的代码中会用到,比如嵌入式等,另外,还有cppreference中提到了信号处理程序。比如下面的代码就是一个简单的定时器代码,Timer0Handler是时钟0的终端事件,程序的行为预期是经过一段时间即50个小时,程序退出。
uint32_t volatile times= 0;
void main(){
//时钟初始化
while(times < 50 * 60 * 60){
}
}
void Timer0Handler() interrupt 1{
++times;
}
如果times不加volatile就会被编译器常量优化,导致while变成死循环。
2 volatile和atomic
先说结论volatile和atomic没有任何关系。volatile不保证原子性。
2.1 msvc的扩展
msvc对于volatile的实现不符合标准,自己扩展了volatile的语义。msvc提供了两种volatile,分别为/volatile:iso和/volatile:ms,其中x86机器上后者为默认,arm上前者为默认,详情参考msvc-volatile
- volatile:Selects strict volatile semantics as defined by the ISO-standard C++ language. Acquire/release semantics are not guaranteed on volatile accesses. If the compiler targets ARM (except ARM64EC), this is the default interpretation of volatile.
- volatile:ms:Selects Microsoft extended volatile semantics, which add memory ordering guarantees beyond the ISO-standard C++ language. Acquire/release semantics are guaranteed on volatile accesses. However, this option also forces the compiler to generate hardware memory barriers, which might add significant overhead on ARM and other weak memory-ordering architectures. If the compiler targets ARM64EC or any non-ARM platform, this is default interpretation of volatile.
所以如果要在msvc上测试volatile要自己手动关掉选项。
2.2 Intel的基础类型原子性
首先明确一个问题基础类型是原子的吗?不是。首先CPP标准没有规定,其次现有的主流处理器也不都是,有一部分在特定场景下是。Intel保证对于aligned数据的访问是原子的。
下面的内容来自于Intel® 64 and IA-32 Architectures Software Developer’s Manual Combined Volumes: 1, 2A, 2B, 2C, 2D, 3A, 3B, 3C, 3D, and 49.1.1 Guaranteed Atomic Operations。
The Intel486 processor (and newer processors since) guarantees that the following basic memory operations will
always be carried out atomically:
• Reading or writing a byte.
• Reading or writing a word aligned on a 16-bit boundary.
• Reading or writing a doubleword aligned on a 32-bit boundary.
The Pentium processor (and newer processors since) guarantees that the following additional memory operations
will always be carried out atomically:
• Reading or writing a quadword aligned on a 64-bit boundary.
• 16-bit accesses to uncached memory locations that fit within a 32-bit data bus.
The P6 family processors (and newer processors since) guarantee that the following additional memory operation will always be carried out atomically:
• Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache line。
上面的文字简单总结下就是说对于部分新处理器读取特定大小的内存是原子的。为什么提这个,是因为你如果你用Intel处理器测试volatile,很大程度上会发现居然是原子的,导致错误的理解。
2.3 原子变量、Volatile和普通类型的速度
先说结论:原子变量<volatile<普通类型,越大越快。下面是测试代码:
std::atomic<int> i = 0;
volatile int j = 0;
int g = 0;
int n = 100000000;
static void AtomicValue(benchmark::State& state) {
// Code inside this loop is measured repeatedly
for (auto _ : state) {
for(volatile int k = 0;k < n;k ++){
i++;
}
}
}
static void VolatileValue(benchmark::State& state) {
// Code before the loop is not measured
for (auto _ : state) {
for(volatile int k = 0;k < n;k ++){
j++;
}
}
}
static void IntValue(benchmark::State& state) {
// Code before the loop is not measured
for (auto _ : state) {
for(volatile int k = 0;k < n;k ++){
g++;
}
}
}
BENCHMARK(AtomicValue);
BENCHMARK(VolatileValue);
BENCHMARK(IntValue);
测试结果:
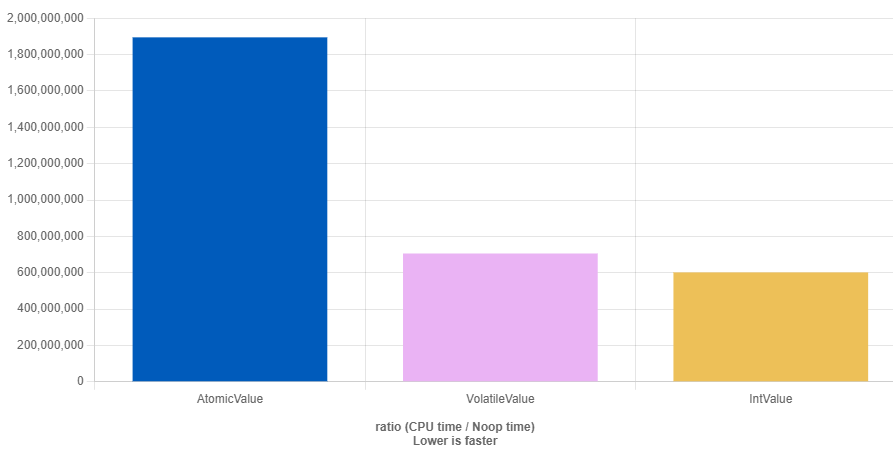
volatile比普通类型慢的原因是少了一些编译器的代码优化导致多次访问内存。而atomic因为要同步SB、L1、L2的数据到其他处理器缓存和内存导致变慢。对于早起的一些处理器实现atomic的方案比较粗暴,直接锁内存总线,直接导致所有CPU访存阻塞,性能更差。
最后简单总结下,如果不是写嵌入式没有理由用volatile,用volatile来实现同步也是不合理的。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









