



 本文详细介绍了Java中的异常处理机制,包括Error和Exception的区别,如何使用try-catch-finally捕获和处理异常,自定义异常的步骤,包装类的作用,以及泛型在集合中的应用。还探讨了String、StringBuilder和BigDecimal的使用技巧。
本文详细介绍了Java中的异常处理机制,包括Error和Exception的区别,如何使用try-catch-finally捕获和处理异常,自定义异常的步骤,包装类的作用,以及泛型在集合中的应用。还探讨了String、StringBuilder和BigDecimal的使用技巧。
1.捕获与抛出;
在Java的程序运行时很多问题是难以避免的,在程序运行时发生了不被期望的事件导致程序没有按照程序员的预期执行的都是异常,异常发生时,是任程序自生自灭,立刻退出终止,还是输出错误给用户?这些就要用到捕获与抛出;
在说捕获与抛出之前先说说Java中的常见异常
Ⅰ.Error:一般是Java虚拟机的问题用代码一般不能处理大致有以下两种情况
| VirtualMachineError | 其中又包含StackOverFlowError和OutOfMemoryError |
| AWTError |
Ⅱ.Exception:在程序运行中产生的异常,是可以被我们处理的异常大致分为两类,一类是IOEException(输入输出异常),另一个是RunTimeException(运行时异常);
IOEException主要有以下几类
| EOFException | 文件结束异常 |
| FileNotFoundException | 没找到文件 |
RunTimeException有以下几类
| ArithmeticException | 当出现异常的运算条件时,抛出此异常 |
| ArrayIndexOutOfBoundsException | 用非法索引访问数组时抛出的异常 |
| NullPointerException | 当应用程序试图在需要对象的地方使用 null 时,抛出该异常 |
| ArrayStoreException | 试图将错误类型的对象存储到一个对象数组时抛出的异常 |
| IllegalArgumentException | 抛出的异常表明向方法传递了一个不合法或不正确的参数 |
| IndexOutOfBoundsException | 指示某排序索引超出范围时抛出 |
| NegativeArraySizeException | 如果应用程序试图创建大小为负的数组,则抛出该异常 |
OK,那么现在知道Java可能会有这么多的异常,我们怎么才能确保用户在使用我们编写的程序的时候,不会因为乱输入数据而导致程序爆炸呢,那就要提到捕获与抛出;
a.捕获(catch):顾名思义捕获就是要把错误抓住,那么想要抓住异常就得先对某些语句进行监视,这就要引出另一个关键词try,如果try中的语句出现问题那么就要执行catch中的语句否则执行try中的语句;这套流程的大概格式就是
try{
要捕获的语句
}catch(语句会发生的异常 实例名){
捕获后执行的语句
}final{
执行语句
}
比如以下图中这个代码中出现除数为零这个异常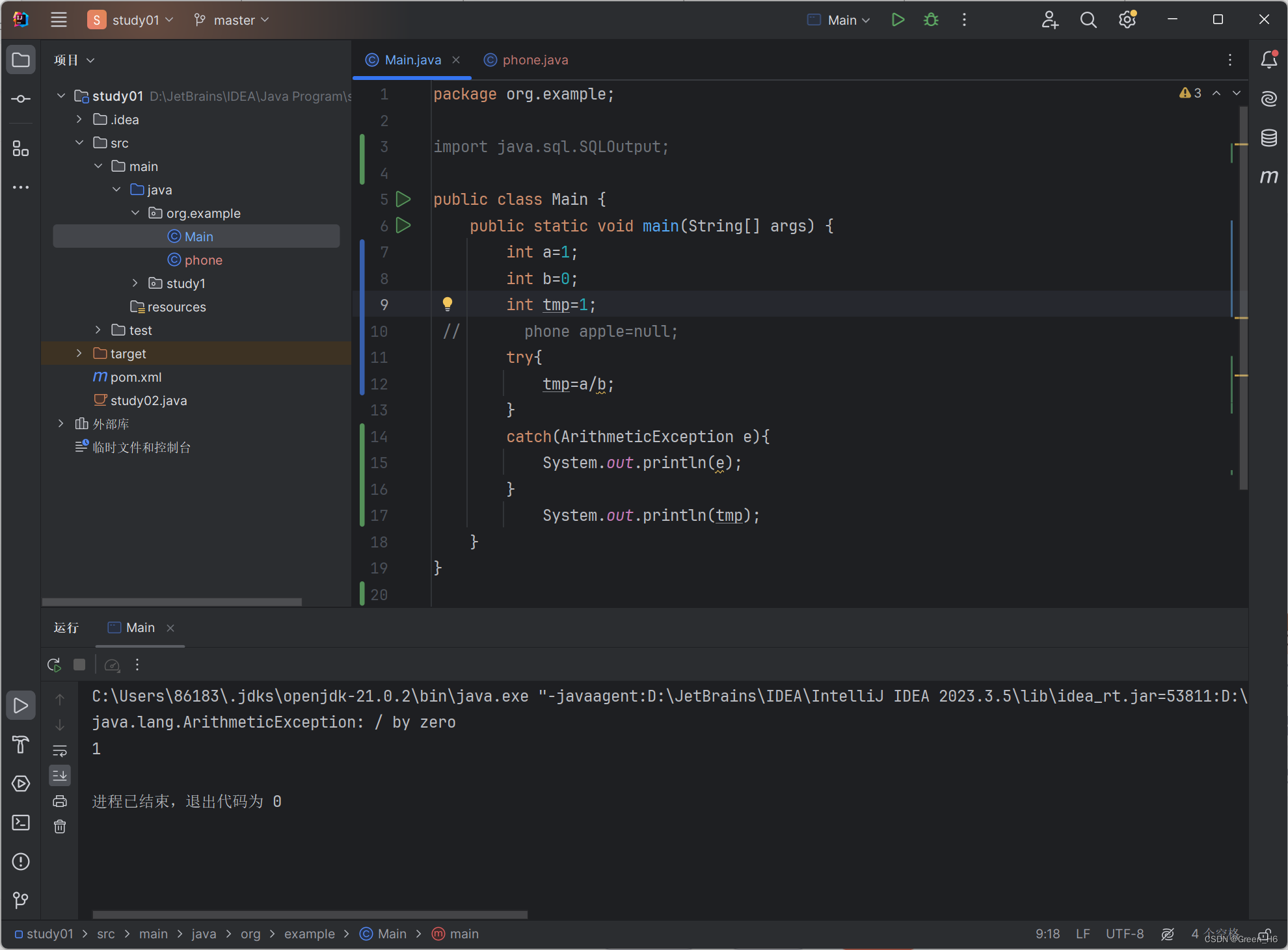
同时一个try语句可以与多个catch语句进行搭配,换一种空指针赋值会得到另一种报错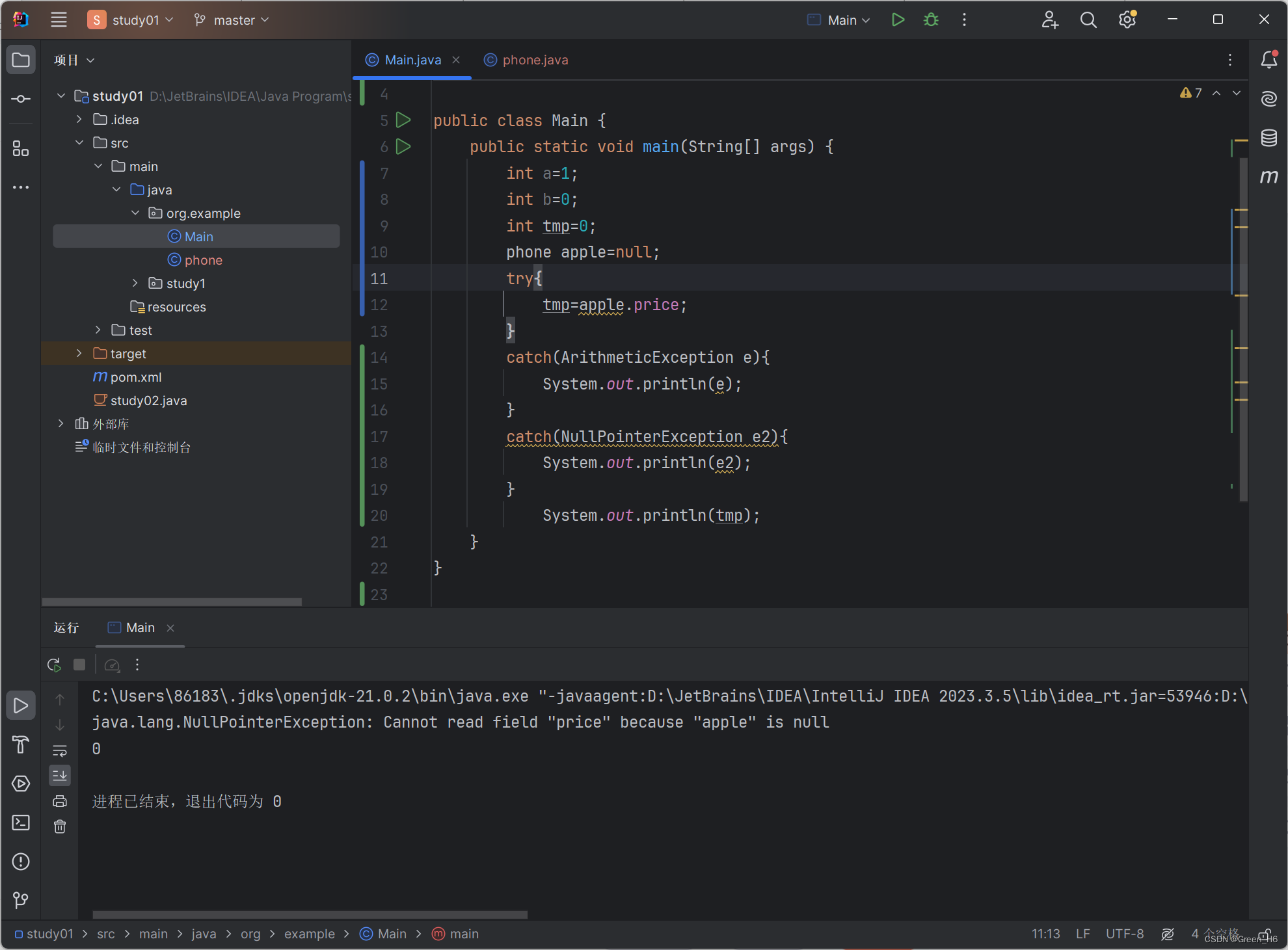
同样的try中也可以存在多个判断语句,但是会在第一个出错的语句截止,截止后的语句不做判断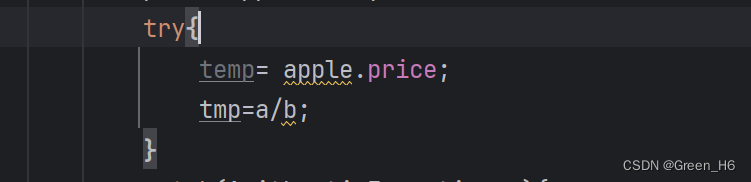 把上面的代码局部改成这样会得到空指针报错,把tmp与temp换位置后会得到分母为零的报错。
把上面的代码局部改成这样会得到空指针报错,把tmp与temp换位置后会得到分母为零的报错。
但是如果try中的语句异常类型没有与catch中的异常类型匹配,那么就不会被捕获,最终会交给虚拟机处理,发生报错;
b.抛出(throw和throws两者都是在方法里面使用的) Ⅰ.throws写在方法的定义处用来说明该方法可能会出现那些异常,格式如下
public void 方法名() throws 异常类名1,异常类名2,....{
....
}
编译时的异常一定要写,运行时的异常可以省略不写。
Ⅱ.throw写在方法内,用于结束方法 并抛出异常对象交给调用者,之后的代码也就不会运行了
public void 方法名(){
throw new 异常类名;
}
抛出是为了在方法出现异常时结束,并告诉调用者该方法出现了问题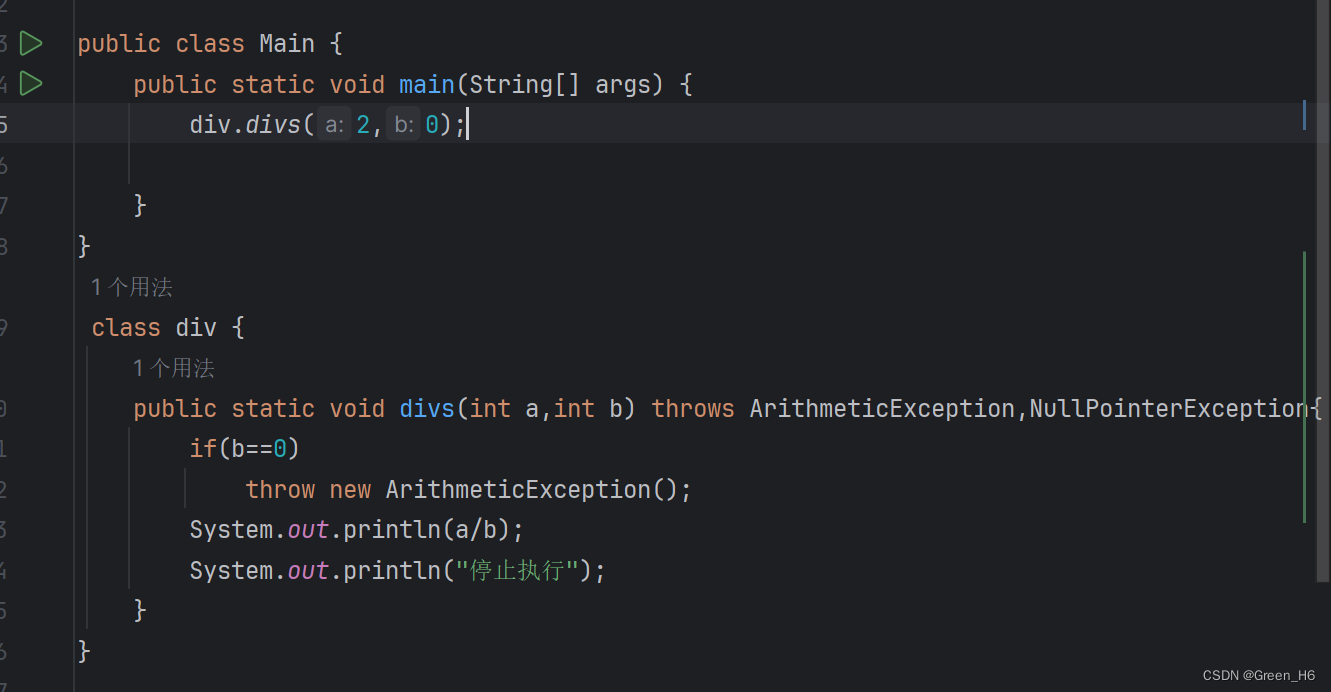 程序会在异常处停止
程序会在异常处停止
c.自定义异常:为了让控制台的报错信息更加见名知意 自定义异常大概分为四步: 一.定义异常类. (在定义的时候一定要见名只意) 二.写继承关系. 三.空参构造. 四.代参构造. 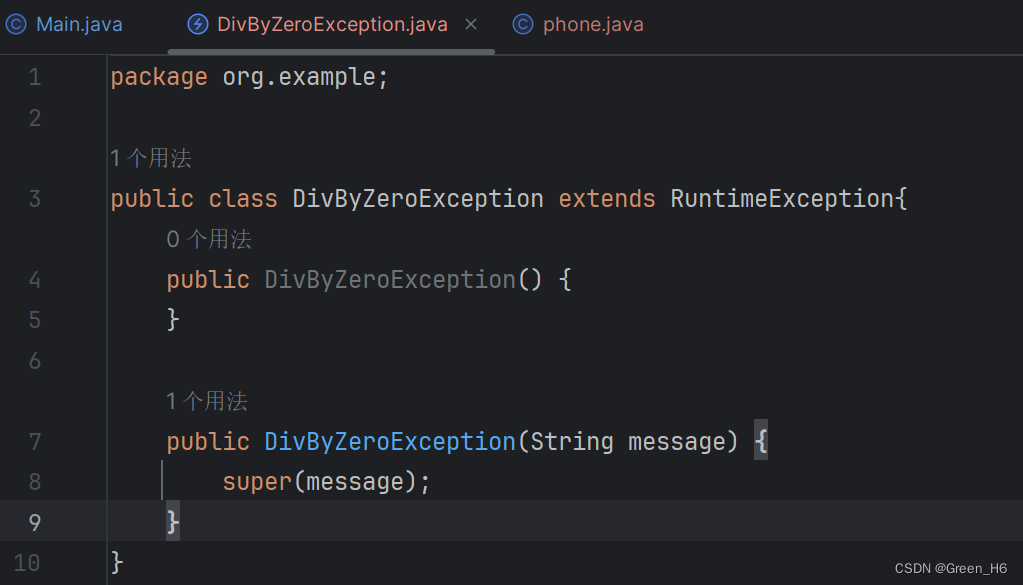 先自定义一个异常,异常如果是运行时异常要继承RunTimeException如果是编译时异常则直接继承Exception,(同理别忘了如果方法类可能出现编译时错误要在方法后用throws声明,之前提到过)
先自定义一个异常,异常如果是运行时异常要继承RunTimeException如果是编译时异常则直接继承Exception,(同理别忘了如果方法类可能出现编译时错误要在方法后用throws声明,之前提到过)
因为自定义的异常的构造函数中有一个是有参的,所有可以在之后的抛出时输出想要打印的语句,
throw new DivByZeroException("分母不能为0")
用这种异常再次运行上次那个分母为0的代码,得到的结果如下图 可以看见报错中有明显的提示,分母不能为0.
可以看见报错中有明显的提示,分母不能为0.
2.Ⅰ.包装类(基本数据类型对应的引用类型)
| 基本数据类型 | 包装类型 |
| byte | Byte |
| short | Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
对包装类进行赋值时,会有类型的转换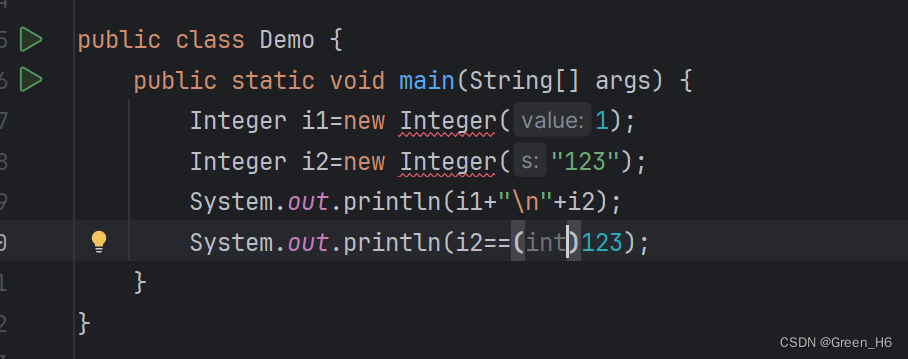 虽然i2是new的是一个字符型,但最后的结果i2还int型的
虽然i2是new的是一个字符型,但最后的结果i2还int型的 也可以用以下这种方式对integer进行赋值
也可以用以下这种方式对integer进行赋值
Integer i1=Integer.valueof((字符串类型)"数值",进制)

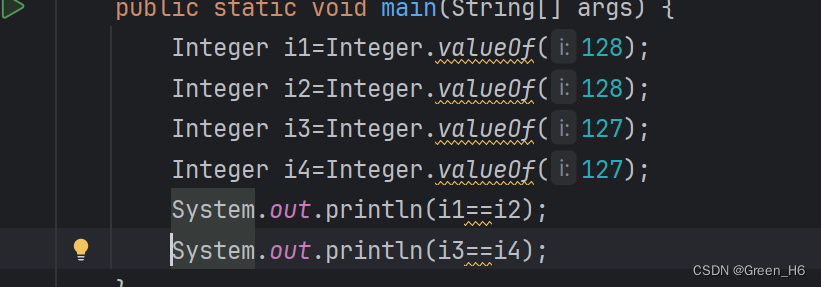
 结果如图,Integer.valueof()函数在-128~127内有优化,在这个范围内的数字可以比较大小,而在这之外的则不行
结果如图,Integer.valueof()函数在-128~127内有优化,在这个范围内的数字可以比较大小,而在这之外的则不行
 在jdk5之前包装类之间的计算还需要拆箱与装箱,但是在jdk‘5之后Java底层会自动装箱与拆箱,所以就不用多讲了。(因为支持自动装箱与拆箱所以Integer与int类型的区别其实不是特别大)
在jdk5之前包装类之间的计算还需要拆箱与装箱,但是在jdk‘5之后Java底层会自动装箱与拆箱,所以就不用多讲了。(因为支持自动装箱与拆箱所以Integer与int类型的区别其实不是特别大)
在包装类中除了char都有对string进行的数据转换,即用parse....语句,例如
int i=Integer.parseInt("双引号内只能是数字")
boolean b=Boolean.parseBoolean(str)//str只能是"true"或者"false"
Ⅱ.String(buffer和builder)
String的特性:被final修饰,不能被继承;具有不可变性,支持序列化和比较大小;
Stringbuilder:可以看作是一个容器,里面的内容是可变的。(可以提高对字符串的操作效率)构造时可以无参构造,相当于一个空容器。也可以有参构造,相当于容器中已经有东西了;
StringBuffer:String类型时不可改变的,但是StringBuffer专门时用来改变String的一类方法 有下面是常见的几种方法
| 方法名 | 作用 |
| public StringBuilder append(任意类型) | 添加数据并返回对象本身 |
| public StringBuilder reverse() | 反转容器内的内容 |
| public int length() | 返回长度 |
| delete(int start,int end) | 删除指定区间内的字符(左开右闭) |
| public String toString() | 把StringBuilder转换为字符型 |
| insert(int offset,String str) | 在指定位置插入字符串 |
| replace(int start,int end,String str) | 用指定字符串替换指定区间 |
 当我们要用多个append进行连接时,也可以用链式编程让过程更加快捷方便
当我们要用多个append进行连接时,也可以用链式编程让过程更加快捷方便

Ⅲ.BigDecimal(用来表示很大的小数,或者对高精度的小数进行计算):不可变的,任意精度的有符号十进制数;
最好用String类型的数据来进行BigDecimal运算,因为即使是double型的数据也有很大的可能损失导致BigDecimal不够准确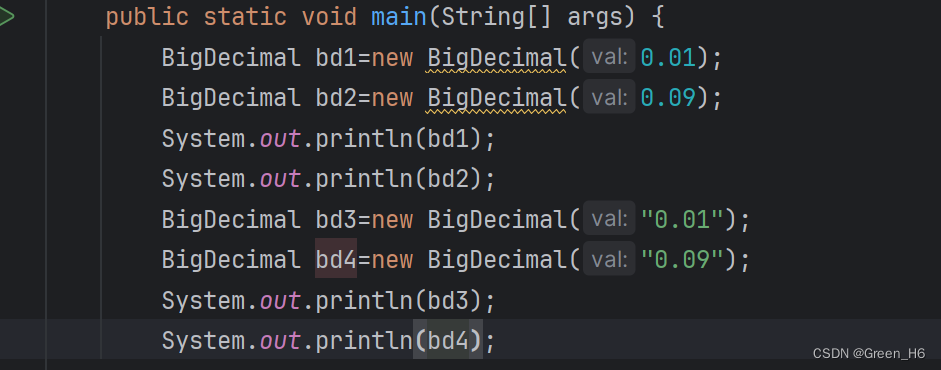
 下面是BigDecimal之间的运算
下面是BigDecimal之间的运算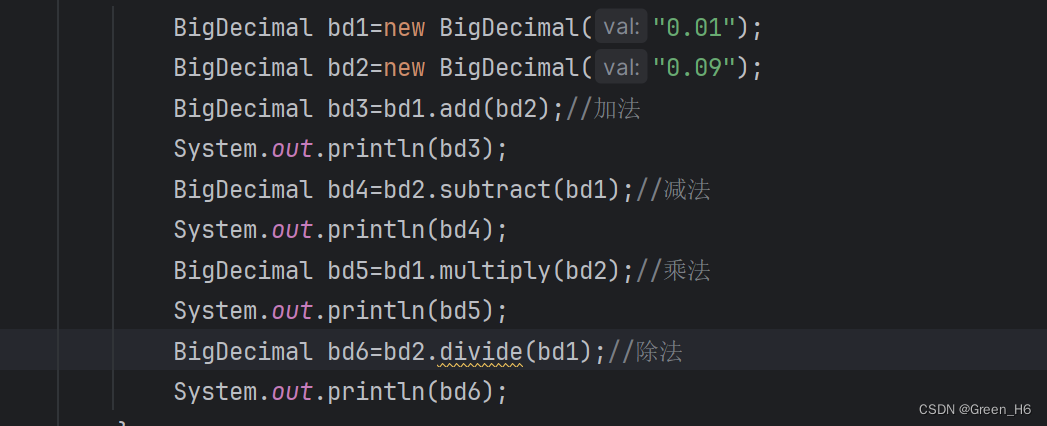
 其中除法更加细致,如果bd1除bd2除不尽的话就会发生报错
其中除法更加细致,如果bd1除bd2除不尽的话就会发生报错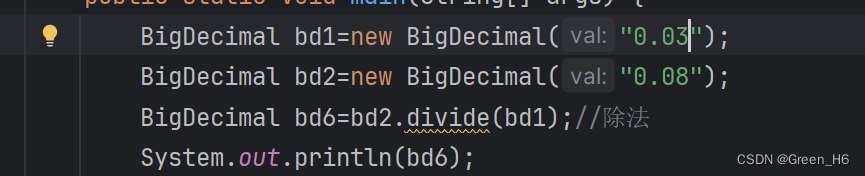
 这时候就应该用下面这种表达方式来说明应该保留几位,以及舍入模式;
这时候就应该用下面这种表达方式来说明应该保留几位,以及舍入模式;
BigDecimal bd3=bd1.divide(bd2,精确到几位,舍入模式)
修改以后的代码和输出结果

 输出模式可以在BigDecimal.或者RoundingMode.中找. up代表沿数轴的远0方向舍入,down则反之。ceiling代表沿数轴正方向舍入,floor反之。
输出模式可以在BigDecimal.或者RoundingMode.中找. up代表沿数轴的远0方向舍入,down则反之。ceiling代表沿数轴正方向舍入,floor反之。
BigDecimal用字符串存储时在底层其实是用数组存储每一个字符的ASC码值;
3.泛型简介
泛型:可以在编译阶段结束操作的数据类型,并进行检查;格式:<数据类型>. 泛型只能用引用数据类型不可以用基本数据类型(如果想用基本数据类型,就可以其对应的包装类)
如果没有使用泛型则集合在输入数据时没有任何限制,可以是任何数据类型的,但是Java对数据的类型又极其敏感可能会导致报错,所以泛型的出现就是为了限制一关集合输入的数据类型,防止此类问题的出现。
例如这个代码
ArrayList list =new Arrlist();
list.add(123);
list.add("aaa");
list.add(new Student());
如果这个集合我想要测他的长度时,int型就不能换为String就不能用length
ArrayList <String> list =new Arrlist<>();
这样就限定了集合进入的数据,如果不符合泛型的数据类型就会报错。 PS:泛型中不能写基本数据类型;指定泛型的具体类型后可以传入该类型及其子类;如果不写泛型就默认为object,即所有的数据类型都可以输入;
下面是几种常见的方法
| boolean add() | 添加元素 |
| boolean remove() | 删除指定元素 |
| E remove() | 删除指定索引元素 |
| E set(int index E e) | 修改指定检索的元素 |
| E get(int index) | 获得指定的索引元素 |
| int size() | 获得集合的长度 |
(1)列表(list),
List是位于java.util下的一个接口,有序集合(也称为序列)。此界面的用户可以精确控制每个元素在列表中的插入位置。用户可以通过整数索引(列表中的位置)访问元素,并在列表中搜索元素;
其中有一个常用的子类就是上面的ArrayList,初始时ArrayList会创建一个初始容量为十的空列表,超出后会自动扩容;简单举个例子
ArrayList<String> list = new ArrayList<>();
list.add("原神");
list.add("启动");
list.add("!!!!");
System.out.println(list);
运行结果如图 每个元素之间会默认以 , 为间隔符,并把所有元素用[]括起来;
每个元素之间会默认以 , 为间隔符,并把所有元素用[]括起来;
除此在外还有列表还有LinkedList(使用双向链表,会一直往后接数据),和Vector(与ArrayList非常类似);
(2).Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用
| 方法名称 | 说明 |
| V put(k key,V value) | 添加元素 |
| V remove(object key) | 删除键值对元素 |
| void clear() | 移除所有键值对元素 |
| boolean containsKey(object key) | 判断是否包含指定元素的键 |
| boolean containsValue(object value) | 判断是否包含指定值的键 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合长度,即键值对数 |
Map<String,String> GenShin_Player=new HashMap<>();
GenShin_Player.put("原神","启动!!");
System.out.println(GenShin_Player);
 Map的key与Value会用等号连接起来,然后用{}把所有的元素括起来;在添加时,如果键不存在就把键添加集合中并返回null,如果存在就要覆盖并把覆盖的值返回;
Map的key与Value会用等号连接起来,然后用{}把所有的元素括起来;在添加时,如果键不存在就把键添加集合中并返回null,如果存在就要覆盖并把覆盖的值返回;
GenShin_Player.clear();再加上这个语句后输出结果为
去掉clear语句后再试试containsKey语句
 打印result后输出结果为true;
打印result后输出结果为true;
(3)set集合(与list集合的性质几乎完全相反,list时有序,可重复,有索引;而set是无序,不重复,无索引),分为HashSet与TreeSet,使用的接口也是collection接口,所有与Map用的方法大致相同(Map中的containsKey和containsValue改成了contains)
判断以下代码会输出什么?
Set<String> Ikun=new HashSet<>();
boolean r1=Ikun.add("Ikun");
boolean r2=Ikun.add("Ikun");
System.out.println(r1);
System.out.println(r2);
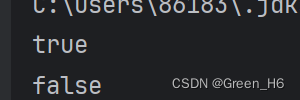 第一个是true,第二个是false,为什么?这是set不可重复的原因,所以第二个是false; 下面在看看无序性;
第一个是true,第二个是false,为什么?这是set不可重复的原因,所以第二个是false; 下面在看看无序性;
Set<String> Ikun=new HashSet<>();
Ikun.add("Ikun");
Ikun.add("喜欢");
Ikun.add("背带裤");
System.out.println(Ikun);
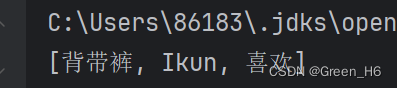 输出的结果不是Ikun喜欢背带裤,而是一个无序的组合
输出的结果不是Ikun喜欢背带裤,而是一个无序的组合

















 2374
2374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









