






 本文详细介绍了K近邻算法的基本概念,包括样本相似度计算、K值的选择策略,以及如何通过交叉验证和避免偶数K值问题。同时涵盖了特征预处理中的归一化和标准化,以及它们在异常点处理和不同应用场景中的适用性。
本文详细介绍了K近邻算法的基本概念,包括样本相似度计算、K值的选择策略,以及如何通过交叉验证和避免偶数K值问题。同时涵盖了特征预处理中的归一化和标准化,以及它们在异常点处理和不同应用场景中的适用性。
K近邻算法(KNN)
一个样本在特征空间(训练集中的样本数据)中的K个最相似的样本中大多数属于某一个类别,则该样本也属于这个类别
样本相似度:样本都是属于一个任务数据集,样本距离越近则越相似
K值选择
-
K值过小:用较小领域中训练实例进行预测
-
容易受到异常点影响
-
K值减小意味整体模型变得复杂,容易发生过拟合
-
-
K值过大:用较大领域中的训练实例进行预测
-
受到样本均衡问题
-
且K值的增大就意味整体的模型变得简单,欠拟合
-
-
如何避免上述问题?
-
交叉验证
-
网格搜索
-
-
K值不要偶数,尽量选奇数,比如,现有4个人投票个AB,现在都分别给AB投票2票,这样就形成了平数,导致无法判断
-
类别选择不要用偶数,比如,现有4个类别,2个猫类,2个狗类,现在新数据插入进来,但由于类别都相等,故无法判定属于哪一类
KNN算法及API
-
解决问题:分类问题、回归问题
-
算法思想:若一个样本在特征空间中的K个最相似样本大多数属于某一个类别,则该样本也属于这个类别
-
相似性:欧氏距离
KNN分类流程
-
计算未知样本到每一个训练样本距离
-
将训练样本根据距离大小升序排列
-
取出距离最近的K个训练样本
-
进行
多数表决,统计K个样本中的哪个类别样本个数最多 -
将未知样本归属到出现次数最多的类别
KNN回归流程
-
计算未知样本到每一个训练样本距离
-
将训练样本根据距离大小升序排列
-
取出距离最近的K个训练样本
-
把这个
K个样本目标值计算其平均值 -
作为将未知样本预测的值
KNN解决了什么问题?
KNN可解决分类和回归问题
解决的是寻找与未知样本最近邻的K个样本,并对未知样本所属分类或属性进行预测
距离度量
空间中两个样本距离通过欧氏距离来度量
KNN算法API
-
分类API
导包
from sklearn.neighbors import KNeighborsClassifier(n_neighbors=5)
n_neighbors:int可选(默认为5)
k_neighbors:查询默认使用的邻居数
实例化对象
estimator = KNeighborsClassifier(n_neighbors=1)
构造数据
x = [[1],[2],[3]]
y =[0,1,2]
训练模型并预测
estimator.fit(x,y)
estimator.predict([[1]])
-
回归API
导包
from sklearn.neighbors import KNeighborsRegressor
实例化对象
estimator = KNeighborsRegressor(n_neighbors=2)
构造数据
x = [[3,4,5],[6,7,8],[5,6,7]]
y = [0.3,0.4,0.5]
训练模型并预测
estimator.fit(x,y)
myret = estimator.predict([[4,5,6]])
print('myret :',myret)
距离度量
-
欧氏距离
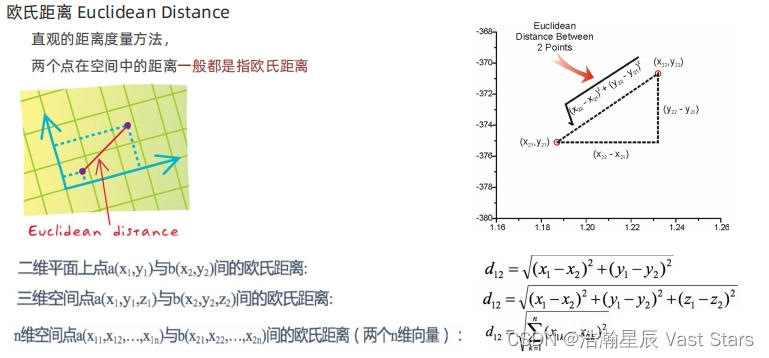
-
切比雪夫距离

-
闵可夫斯基距离

-
曼哈顿距离
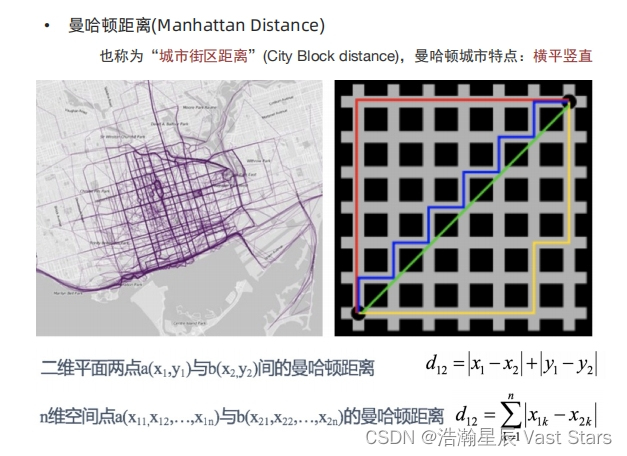
特征预处理
为什么做归一化和标准化?
特征单位或者大小相差较大,或者某特征方差相比其他特征要大出几个数量级,容易影响(支配)目标结果,使得一些模型(算法)无法学习到其他特征
归一化

数据归一化
通过对原始数据进行变换把数据映射到mi,mx之间
API:
skleam.preprocessing.MinMaxScaler(feature_range=(0,1)...) feature_range 缩放区间
fit_transform(x) 将特征进行归一化缩放
#导包
import numpy as np
form sklearn.preprocessing import MinMaxScaler
#创建函数
def dm01_MinMaxScaler():
# 准备数据
data = [[30,40,50],[60,70,80]]
# 初始化归一化对象
transformer = MinMaxScaler()
# 对原始特征进行变换
data = transformer.fit_transform(data)
# 打印归一化后的结果
print(data)
标准化

数据标准化:通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布数据
数据标准化API
sklearn.preprocessing.StandardScaler()
fit_transform(X)将特征进行归一化缩放
from sklearn.preprocessing import StandardScaler # 导入归一化方法 # 构造数据 data =[[90,2,10,40], [60,4,15,45], [75,3,13,46]] # 实例化特征工程方法 transformer = StandardScaler() # 对原始特征进行归一化处理及打印 print(transformer.fit_transform(data)) # fit_transform是一种归一化方法,输入原始数据,输出归一化后的数据 print(transformer.mean_) # 均值 print(transformer.var_) # 方差
-
数据归一化
如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变 应用场景:最大值与最小值非常容易受异常点影响,鲁棒性基较差,只适合传统精确小数据场景 图像处理 skilearn.preprocessing.MinMaxScaler(feature_range=(0,1))
-
数据标准化
若出现异常点,由于具有一定数据量,少量异常点对于平均值影响较小 应用场景:适合现代嘈杂大数据场景 sklearn.preprocessing.StandardScaler()















 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









