






文章目录
一、程序分析
(1)将文件读到缓冲区
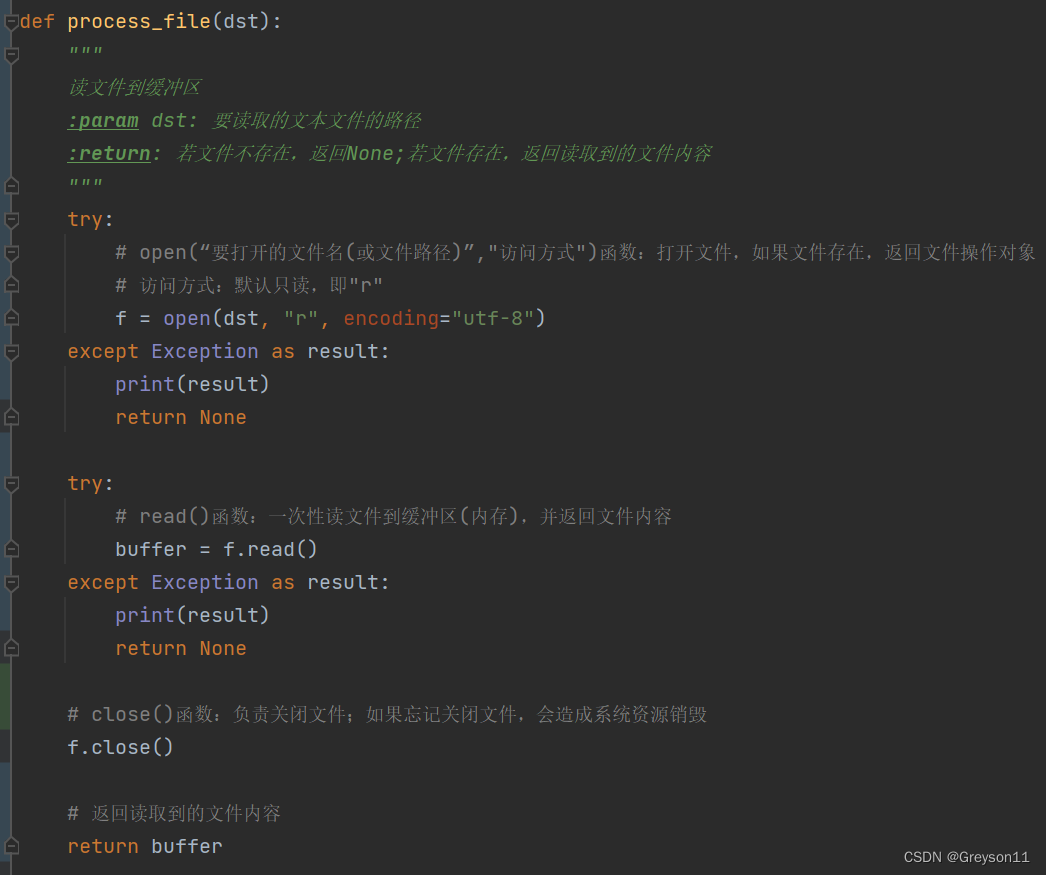
(2)对读到缓冲区的文件内容进行词频统计

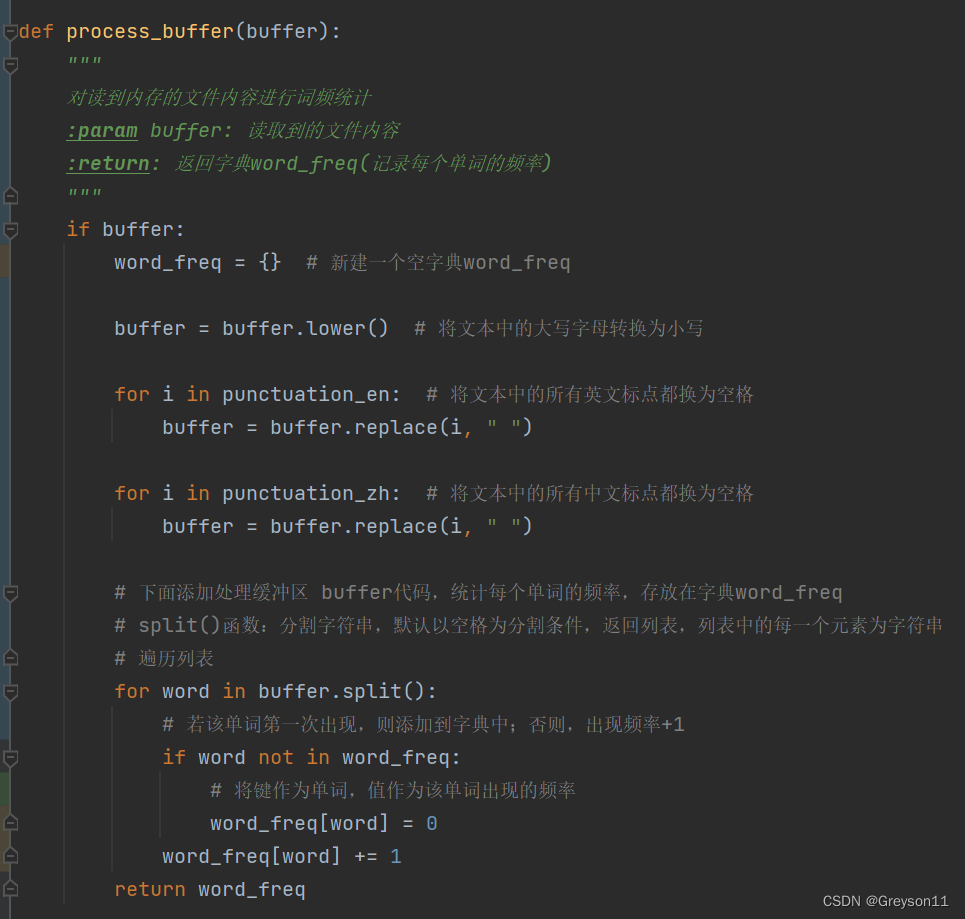
(3)得出单词频率统计结果,输出出现频率前10的单词
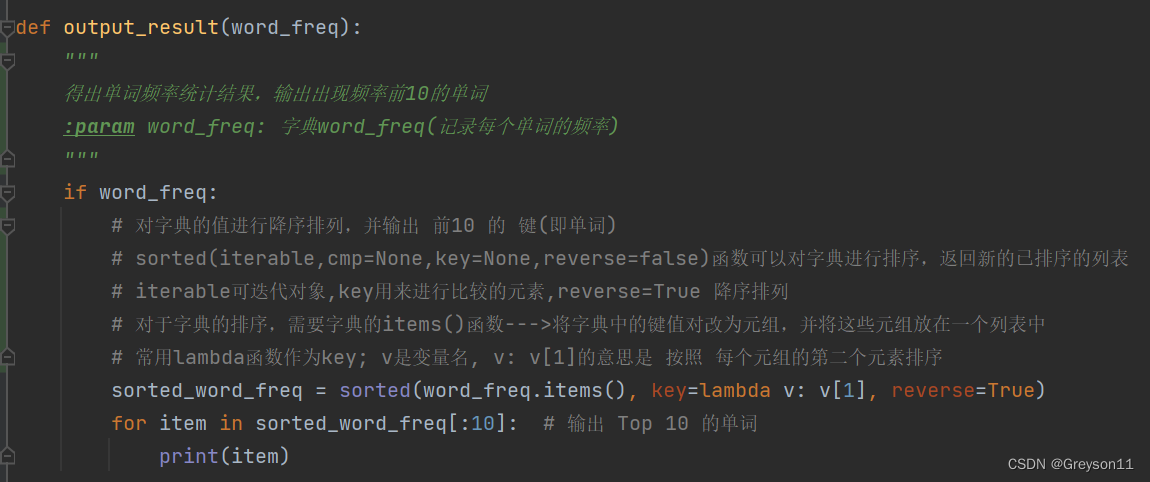
(4)设置一个main函数,将前面的函数进行调用封装

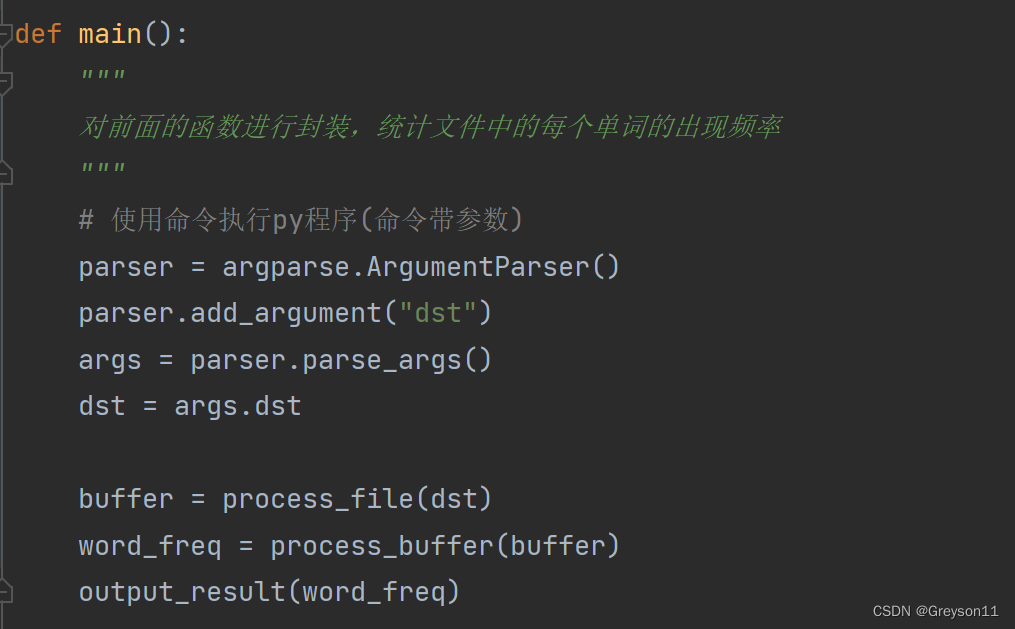
(5)测试
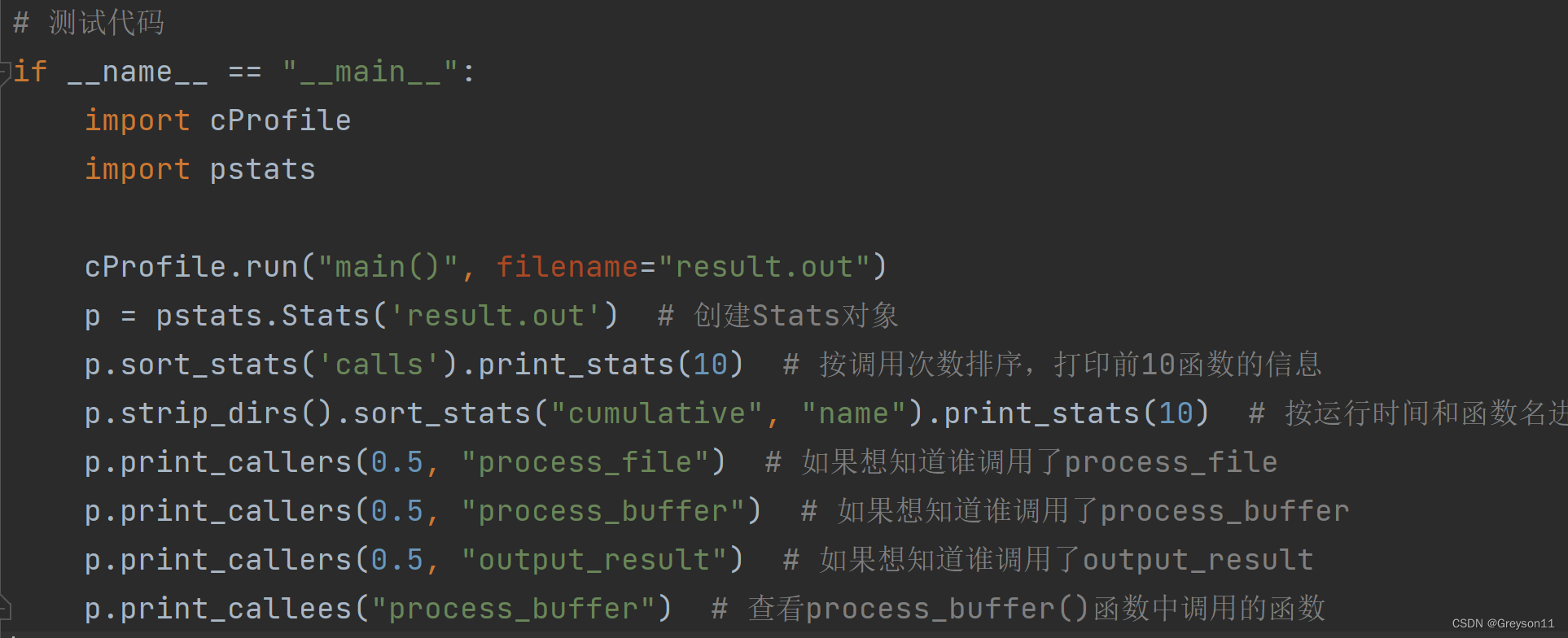
二、代码风格说明
(1)函数名应该小写,单词与单词之间使用"_"相隔
(2)代码块之间相隔两行
(3)注释以 # 和 一个空格 开始

(4)函数注释 一对"""之间

三、程序运行命令、运行结果
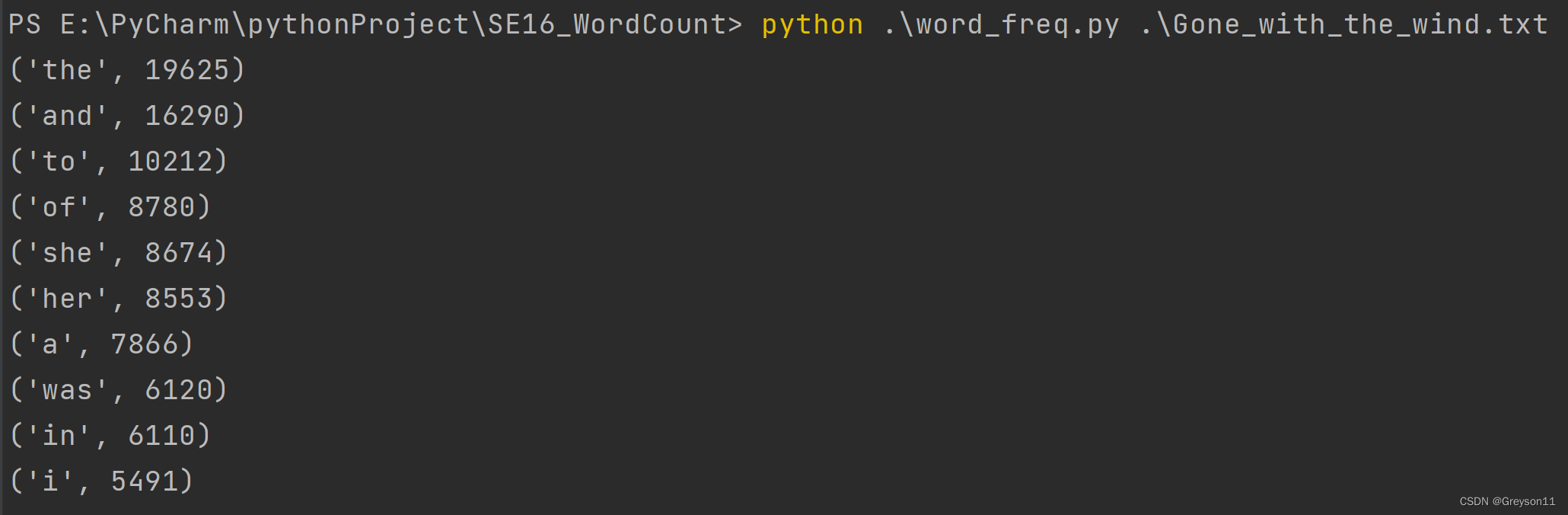
对 文件Gone_with_the_wind 进行词频统计
四、性能分析结果及改进
(1)按调用次数排序,打印前10函数的信息
总的运行时间 0.256秒
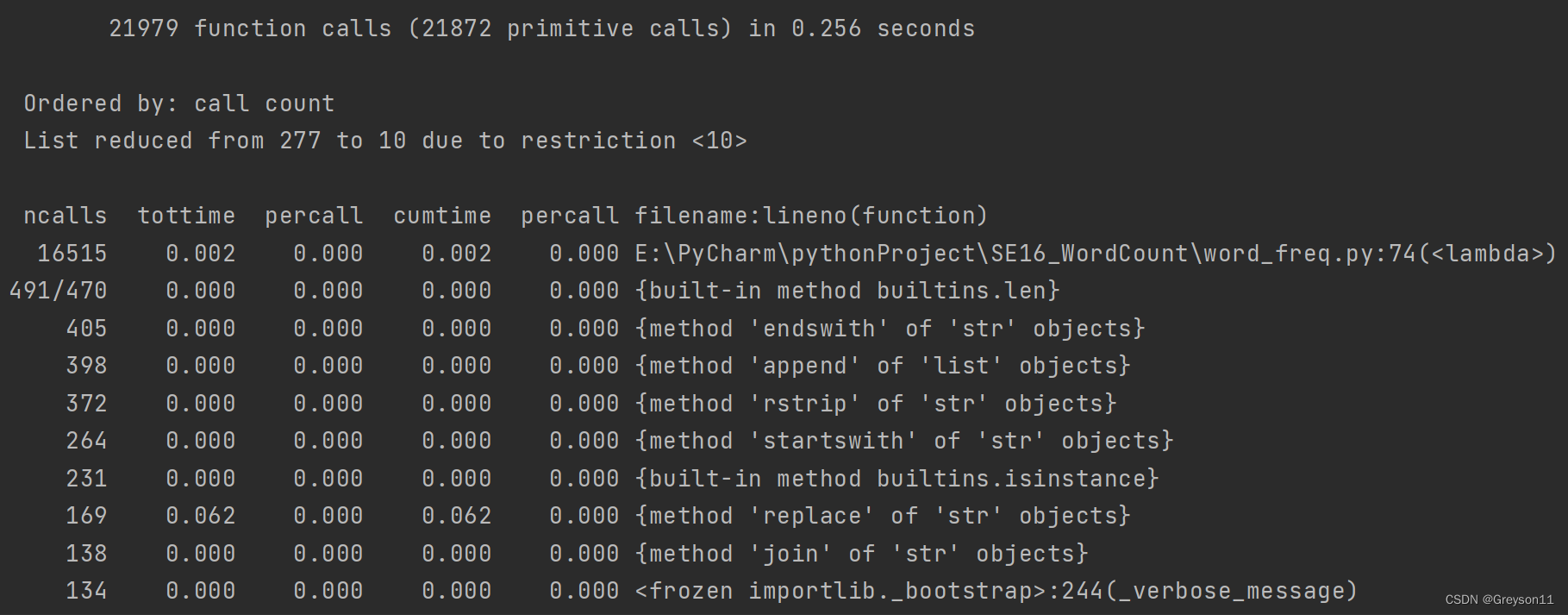
ncalls:表示函数调用的次数;
tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
percall:(第一个percall)等于 tottime/ncalls;
cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
percall:(第二个percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
filename:lineno(function):每个函数调用的具体信息;
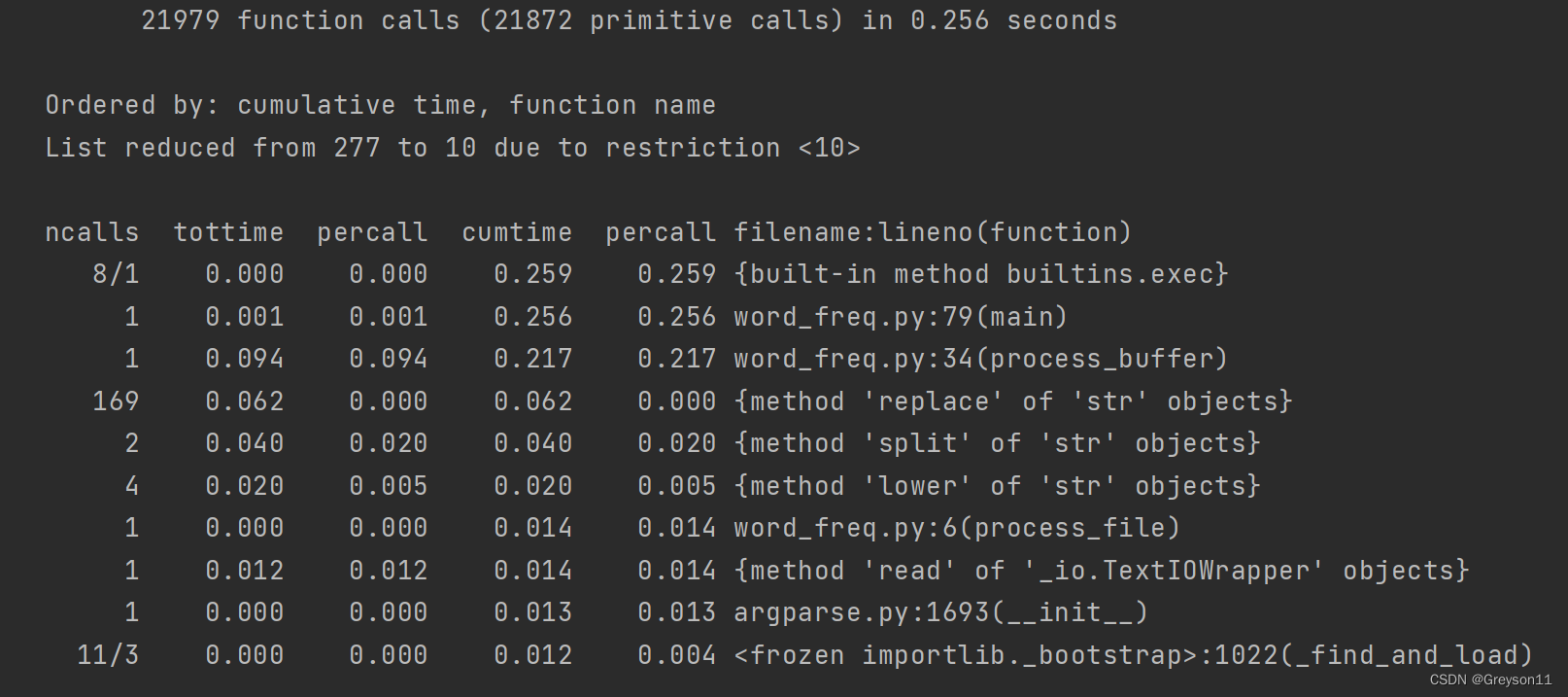
(2)按运行时间和函数名进行排序,打印前10行函数的信息
(3)每个函数具体占用时间
process_buffer函数运行的时间最长。
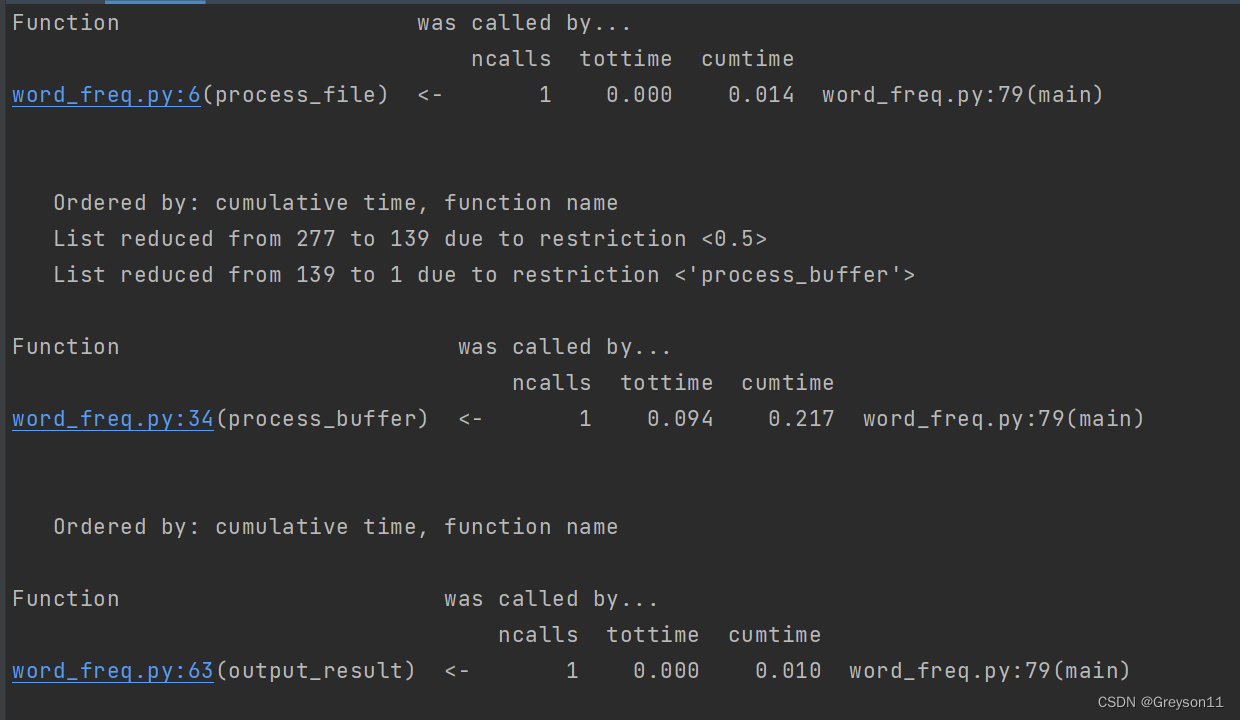
(4)具体看一下process_buffer函数调用了什么(代码改进)

代码改进:
从分析结果的截图中我们可以看出process_buffer函数在replace上花费了巨大的时间。
因此,将下方代码进行改进:
for i in punctuation_en: # 将文本中的所有英文标点都换为空格
buffer = buffer.replace(i, " ")
for i in punctuation_zh: # 将文本中的所有中文标点都换为空格
buffer = buffer.replace(i, " ")
改为:
for i in "!\"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆、 、〃〈〉《》【】〜〝〞〟–—‘’‛“”„‟…‧﹏﹑﹔·!?。。'":
buffer = buffer.replace(i, " ")

可以看出运行时间变快了
五、使用可视化分析
-
性能分析:
python -m cProfile -o result.out -s cumulative word_freq.py Gone_with_the_wind.txt;分析结果保存到 result.out 文件; -
转换为图形;gprof2dot 将 result.out 转换为 dot 格式;再由 graphvix 转换为 png 图形格式。 命令:
python gprof2dot.py -f pstats result.out | dot -Tpng -o result.png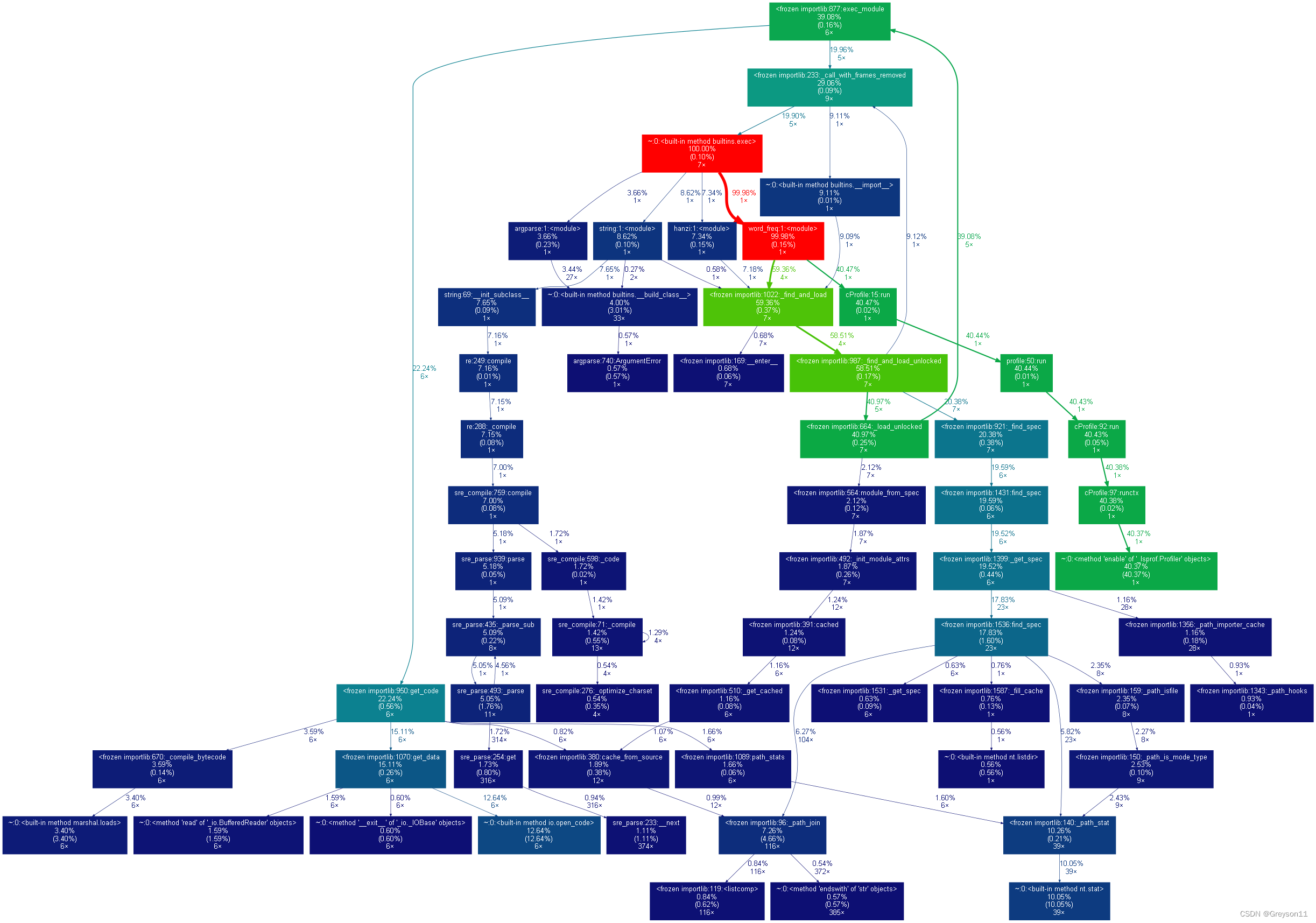















 3289
3289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









