







 本文介绍了决策树的基本概念,包括邮件处理系统的决策树应用和决策树的特点。讨论了决策树的构造过程,信息熵、信息增益和基尼指数的概念,并详细解释了C4.5和CART算法。此外,还通过海洋生物数据处理的例子展示了决策树的实际应用。
本文介绍了决策树的基本概念,包括邮件处理系统的决策树应用和决策树的特点。讨论了决策树的构造过程,信息熵、信息增益和基尼指数的概念,并详细解释了C4.5和CART算法。此外,还通过海洋生物数据处理的例子展示了决策树的实际应用。
决策树
1 决策树概念
A decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm.
Decision trees are commonly used in operations research, specifically in decision analysis, to help identify a strategy most likely to reach a goal, but are also a popular tool in machine learning.
决策树是使用树状图或决策模型的一个决策支持工具,其可能的产生的效果,包括机会事件结果,资源成本和效用。 它是显示算法的一种方式。
1.1 邮件处理系统的效率可以由决策树来表示:
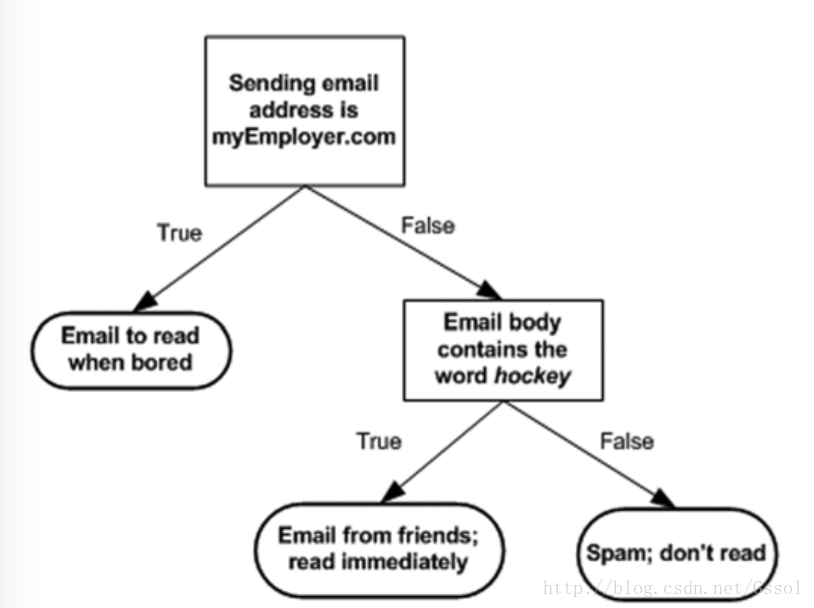
上图显示的是:根据一些特征来分类,看是不是迫切需要处理的还是需要处理的。
猜题游戏:参与游戏的一方可以确定一个答案,另一个人提问20个问题来确定答案,问题的答案只能用对错来回答,也可以使用决策树。
平常许多情况都需要用到决策树,决策树是最经常使用的数据挖掘算法。决策时不一定非要二叉树,多叉树也是可以的,每个结点显示的信息也不一定只能是一个,可以多条信息显示在一起。
决策树将一些事情很直观地显示出来,使其处理问题更加地简单。
1.2 决策树特点
- Pros:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不想管特征数据
- Cons:可能会产生过度匹配问题
- Works with:数值型和标称型
2 决策树构造
决策树分支构造步骤如下:
1. 检测数据集中得每个子项是否属于同一分类,“是”则返回节点并结束,“否”则2
2. 寻找划分数据集的最好特征,划分数据集,创建分支节点
3. 对每个划分的子集,进行1操作
创建分支的伪代码函数createBranch():
检测数据集中得每个子项是否属于同一类
if so return 类标签
ELSE
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBranch()并增加返回结果到分支节点中
return 分支节点决策树算法可以采用二分法、ID3算法划分数据集
3 信息熵、信息增益以及基尼指数
3.1 信息熵
- 集合信息的度量方式称为香农熵或者熵
- 熵是对信息不确定的度量
- 熵定义为信息的期望值
- 一个系统越有序,则信息熵越低,相反一个系统越是混乱,则它的信息熵越高。
如果待分类的事物可能划分在多个分类之中,则符号xi的信息定义为:
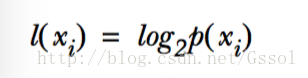
计算熵时我们需要计算所有类别所有可能值包含的信息期望值:
n为分类的数目
3.2 信息增益
- 划分数据集的大原则是:将无序的数据变得更加地有序。
- 在划分数据集之前之后信息发生的变化称为信息增益。
以天气预报的例子来详细说明信息增益的含义
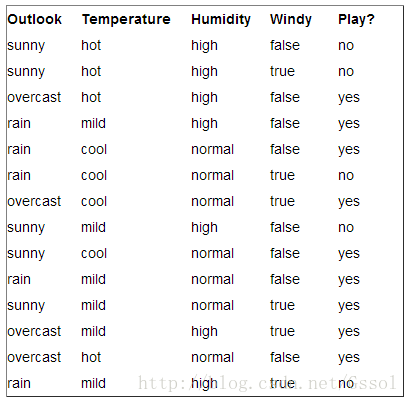
学习目标是play或者not play
一共有14个样例,9个正例和5个负例,当前信息的熵计算如下:
Entropy(S) = - 9/14 * log2(9/14) - 5/14 * log2(5/14)
在决策树分类问题中,信息增益就是决策树在进行属性划分前后信息的差值。假设利用属性Outlook来分类,那么如下图
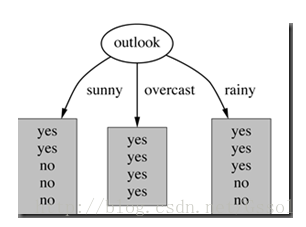
划分后,数据被分为三个部分,各个分支的信息熵计算如下:
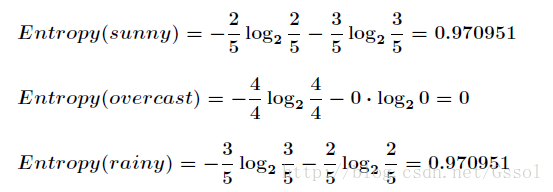
划分后的信息熵为:
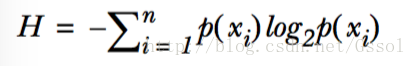
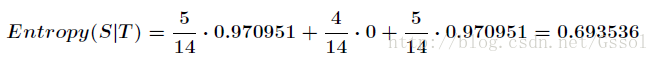
信息增益的计算公式:
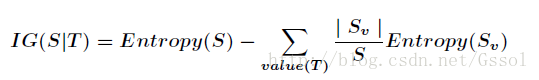
本例的信息增益:

在决策树的每一个非叶子节点划分之前,先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分,因为信息增益越大,区分样本能力就越强,越具有代表性,这是一种自顶向下的贪心策略。这也是ID3算法的核心思想。
3.3 基尼指数
- CART算法主要使用Gini指数。
- 在CART算法中,基尼不纯度表示一个随机选中的样本在子集中被分错的可能性。
- 基尼不纯度为这个样本被选中的概率乘以它被分错的概率
- 假设y的可能取值为{1,2,……,m},令fi是样本被赋予i的概率,则基尼指数可以通过如下计算:
4 C4.5算法&&ID3算法&&CART算法
4.1 C4.5算法
ID3算法的思想如上例所示,C4.5算法是机器学习中另一个分类决策树算法,它是基于ID3算法进行改进后的一种重要算法,改进有如下几个要点:
- 用信息增益率来选择属性。ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(entropy, 熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率。
- 在决策树构造过程中进行剪枝,因为某些具有很少元素的结点可能会使构造的决策树过适应(Overfitting),如果不考虑这些结点可能会更好。
- 对非离散数据也能处理。
- 能够对不完整数据进行处理。
上述例子使用C4.5算法:
计算分裂信息度量H(V):
H(Outlook) = - 5/14 * log2(5/14) - 4/14 * log2(4/14) - 5/14 * log2(5/14)
信息增益率:
IGR(Outlook) = Entropy(S|T) / H(Outlook)
4.2 CART算法
天气预报的CART算法的具体计算过程如下:
| Outlook | sunny | overcast | rain |
|---|---|---|---|
| YES | 2 | 4 | 3 |
| NO | 3 | 0 | 2 |
Gini(Sunny) = 1 - (2/5)^2 - (3/5)^2
Gini(Overcast) =1 - (4/4)^2 - (0/4)^2
Gini(rain) = 1 - (3/5)^2 - (2/5)^2
Gini= 5/14*Gini(Sunny) + 4/14*Gini(Overcast)+5/14*Gini(rain)
对离散值如{x,y,z},则在该属性上的划分有三种情况
空集和全集的划分除外
天气预报的例子的计算情况如下:
| Outlook | sunny or overcast | rain |
|---|---|---|
| YES | 6 | 3 |
| NO | 3 | 2 |
然后再进行计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









