







这篇博客主要是记录本学期的一门课上写的小程序,课程是《数据挖掘应用与技术》,程序是文本分类,老师本来的要求比较简单,不过写着写着就超过了老师的要求,所以这里记录一下。
1 分词算法
1.1 流程图
首先是一个简单的流程图
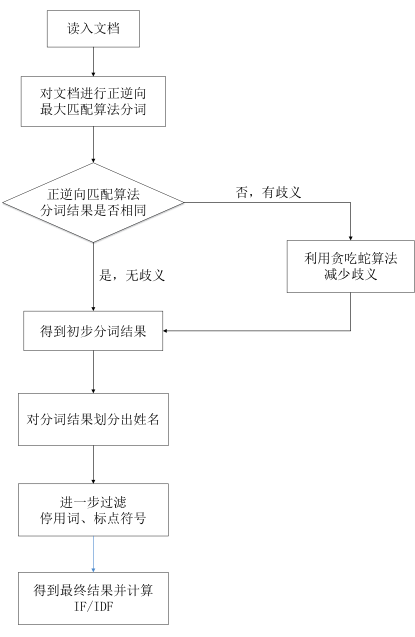
1.2 正逆向匹配算法
本系统采用的分词算法是基于词典的分词算法,它的主要思想是基于字符串匹配的机械分词,即按照一定的策略将待分词的汉字串与一个“充分大的”分词词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功,即识别出一个词。因此根据文本扫描的方向和匹配原则,可以分为正向最大匹配、逆向最大匹配、逐词匹配、最少切分、全切分等匹配方法。而在实际应用中,常常将上述方法结合起来。
(1)正向最大匹配算法
正向最大匹配算法是最基本的机械匹配算法之一,它的基本思想是
A)从左往右取不超过词典最大长度的汉字作为匹配字段;
B)查询词典并进行匹配,若能匹配,则将这个匹配字段作为一个词切分出来;
C)若不能匹配,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配;
D)循环操作,直到匹配字段字数为零为止;
E)重复正向最大匹配过程,直到切分出所有词为止。
(2)逆向最大匹配算法
逆向最大匹配算法原理类似于正向最大匹配算法,它的具体原理是:
A)从右往左取不超过词典最大长度的汉字作为匹配字段;
B)查询词典并进行匹配,若能匹配,则将这个匹配字段作为一个词切分出来;
C)若不能匹配,则将这个匹配字段的最前一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配;
D)循环操作,直到匹配字段字数为零为止;
E)重复逆向最大匹配过程,直到切分出所有词为止。
正向最大匹配算法和逆向最大匹配算法的区别在于正向最大匹配算法是从左往右依次取匹配字段,而逆向最大匹配算法则是从右往左依次取匹配字段,二者的匹配方法相同,但方向不同。
1.3 贪吃蛇算法(减少歧义)
PS:这个算法是参考另外一个博客上的,但是时间有些久了,如果原作者看到请跟我联系,我会加上原文引用
由于正向最大匹配算法和逆向最大匹配算法均存在歧义问题,为了减少歧义分词的出现,本程序将同时采用正向最大匹配算法和逆向最大匹配算法。首先对待处理的文档进行正向最大匹配算法分词,接着用逆向最大匹配算法得到逆向的分词结果,紧接着对得到的两种分词结果进行对比。如果两种算法得到的分词数组一样,那么说明分词结果不存在歧义;如果得到的分词结果不一致,那么就说明分词存在歧义现象。这时候就必须对结果进行歧义消除。
常见的歧义消除方法是,从正反向的分词结果中:选择分词数量较少的那个 或者 选择单字较少的那个 或者 选择分词长度方差最小的那个。而本算法是运用游戏贪食蛇的原理进行歧义的消除,这里称为“贪食蛇法”。具体思路是这样的:要进行分词的字符串,就是食物。有2个贪吃蛇,一个从左向右吃;另一个从右向左吃。只要左右分词结果有歧义,2条蛇就咬下一口。贪吃蛇吃下去的字符串,就变成分词。 如果左右分词一直有歧义,两条蛇就一直吃。两条蛇吃到字符串中间交汇时,就肯定不会有歧义了。这时候,左边贪吃蛇肚子里的分词,中间没有歧义的分词,右边贪吃蛇肚子里的分词,3个一拼,就是最终的分词结果。通俗地说,对字符串进行左右(正反)分词,如果有歧义,就截取字符串两头的第一个分词,作为最终分词结果的两头。两头被各吃一口的字符串,就变短了。这个变短的字符串,重新分词,再次比较左右分词有没有歧义。如果一直有歧义,就一直循环。直到没有歧义,或者字符串不断被从两头截短,最后什么也不剩下,也就不可能有歧义了。这个方法,就是把正向分词结果的左边,和反向分词结果的右边,不断的向中间进行拼接,最终得到分词结果。
1.4 结果处理
这个地方主要包括几个方面:
第一个是标点符号的去除,我的方法是用正则表达式来进行,效果比较好。
第二个是停用词的去除,也就是去掉一些十分常见的词语,这个步骤是为课程剩余实验做准备的
第三个是姓名的划分,首先根据百家姓来查找可能存在的姓名,然后匹配后面的字,一般来说名字如果是三个字,后面两个字通常不是词组,根据这个就可以分辨出大多数的名字。
1.5 准确率测试
根据别人提供的一个人工划分的标准划分文本,我写了比对算法,成功算出了分词的准确率
2、 代码
这个是主要算法实现的代码,其余还有相应的调用,具体请参看我的github代码库:https://github.com/GumpCode/DataMining/tree/master/WordCut
package Gump.DataMing;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 基于正逆双向最大匹配分词算法实现
*
*/
public class TextManipulation {
/**
* 存储分词词典
*/
private Map<String, Integer> DictMap = new HashMap<String, Integer>();
private List<String> StopList = new ArrayList<String>();
private List<String> NameList = new ArrayList<String>();
private List<String> NoiseList = new ArrayList<String>();
private String DictPath = "./dictionary/dic.txt";
private String StopWordPath = "./dictionary/stopwords.txt";
private String NameWordPath = "./dictionary/surname.txt";
private String NoiseWordPath = "./dictionary/noise.txt";
/**
* 最大切词长度,即为五个汉字
*/
private int MAX_LENGTH = 5;
/**
* 构造方法中读取分词词典,并存储到map中
*
* @throws IOException
*/
public TextManipulation() throws IOException {
BufferedReader br = new BufferedReader(new FileReader(DictPath));
String line = null;
while ((line = br.readLine()) != null) {
String[] temp = line.split(" ");
line = temp[0].trim();
DictMap.put(line, 0);
}
br.close();
}
/**
* 读取停词词典,并存储到map中
* @throws Exception
*/
private void getStopWord()  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









