







友情提示:右下角可以看目录哟
前言
相信大家都有过玩虚拟机的经验,也相信大家有想搭一个大数据集群偶尔在自己电脑上做做测试。使用虚拟机是可以完成的,但是过程非常漫长,而且很多操作不能以后重复使用。
这里我近期使用Docker完成了测试集群的搭建,我想用的时候,十几秒就可以直接启动,速度很快。而且所有的镜像都可以上传hub云端,想用的时候,从云端pull到任何一台有docker的电脑直接运行。
而且,以往我们使用虚拟机搭建集群,我们需要配置很多的免密,甚至Hadoop等文件,我们需要上传到各个节点上。使用Docker的 挂载卷 技术,我们只需要修改 一次Hadoop的配置,能够保证各个节点运行的都是一致的。避免使用虚拟机我们要一修改配置,还要各个节点同步。
相信大家已经很激动了,那我们开始吧!
这篇文章,默认大家已经安装了docker了,我就不发docker的安装教程了,网上一搜很多。
安装过程
一、基础JAVA镜像
由于要搭建集群,Hadoop集群又是依赖Java的,然后各个节点又需要免密登录,这里我开发了一个有JAVA 、SSH等的基础镜像,大家可以直接下载使用,我也会贴出Dockerfile 文件,大家可以参考一下。
https://registry.hub.docker.com/repository/docker/daixiaoyu/java
docker pull daixiaoyu/java:1.8Dockerfile如下(大家可以参考学习,这个不用修改)
FROM centos:7
MAINTAINER dxy "daixinyu.best@icloud.com"
RUN yum install -y passwd openssh-server openssh-clients
#RUN yum -y install bind-utils
#RUN yum -y install which
RUN yum -y install sudo
WORKDIR /usr/local/
# This is the Java file that I added
ADD jdk-8u241-linux-x64.tar.gz /usr/local/
ENV JAVA_HOME=/usr/local/jdk1.8.0_241
ENV CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV PATH=$JAVA_HOME/bin:$PATH
# This image already has a secret - free login
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys && \
sed -i 's/PermitEmptyPasswords yes/PermitEmptyPasswords no /' /etc/ssh/sshd_config && \
sed -i 's/PermitRootLogin without-password/PermitRootLogin yes /' /etc/ssh/sshd_config && \
echo " StrictHostKeyChecking no" >> /etc/ssh/ssh_config && \
echo " UserKnownHostsFile /dev/null" >> /etc/ssh/ssh_config && \
echo "root:1234" | chpasswd
CMD [ "sh", "-c", "sudo service ssh start; bash"]二、构建Hadoop镜像
使用Dokerfile 来构建镜像
1、进入一个工作目录 ,这个您们自己定一个就可以了
cd /Users/gump/docker2、创建一个构建镜像的文件夹
mkdir bigdatav1
cd bigdatav13、创建Dockerfile 文件 ,文件名必须是这个
vi Dockerfile4、将下面内容写入Dockerfile并保存
里面写了注释,相信大家都懵了,这么简单几句?就可以构建集群?哈哈哈哈
# 这里直接使用大家刚下载的java基础镜像
FROM daixiaoyu/java:1.8
# 指明该镜像的作者和电子邮箱
MAINTAINER dxy "daixinyu.best@icloud.com"
# 这里匿名挂载 两个文件夹在容器内部,一个是hadoop 程序,一个是hdfs用来存储数据的
VOLUME ["/opt/hadoop","/opt/hdfs"]
# 下面设置了环境变量,将hadoop 和 启动用户 都设置到环境变量里面
ENV HADOOP_HOME=/opt/hadoop
ENV PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
ENV HDFS_NAMENODE_USER="root"
ENV HDFS_DATANODE_USER="root"
ENV HDFS_SECONDARYNAMENODE_USER="root"
ENV YARN_RESOURCEMANAGER_USER="root"
ENV YARN_NODEMANAGER_USER="root"5、在文件夹内直接构建镜像
pwd
/Users/gump/docker/bigdatav1
# 这是构建镜像的命令,最后那个 . 不要忘了
docker build -t bigdata:v1 .
执行 docker images就可以看到下面的镜像了,一个是 pull 下来的,一个是构建的 ,其实我也可以直接给您们构建好,但是这里是个过程去熟悉怎么通过Dockerfile去构建镜像

6、下载hadoop 到宿主机,让所有容器共享
在刚才的工作目录 下创建一个 bigdata 和 hdfs 文件夹,一个用来装程序性,一个用来装数据
pwd
/Users/gump/docker
mkdir bigdata
mkdir hdfs将hadoop 放入到 bigdata文件夹内(hadoop 下载应该就不用介绍了,官网有的)

7、然后我们就开始配置Hadoop 吧
这里是为了几个节点共享一个hadoop程序,所以还是有这么一步,没有办法。我本来打算直接打在镜像里面的,但是这样的话,我们的Hadoop 还是每个节点一份,使用修改测试不方便
集群容器规划
| master | namenode resourceManager datanode nodemanager | |
| s1 | datanode nodemanager | |
| s2 | nodemanager datanode |
配置目录 Hadoop-3.2.1/etc/hadoop/ 目录下面
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>hadoop-env.sh 修改java 的环境,让Hadoop 知道java在哪里,这里容器内的地址哈
export JAVA_HOME=/usr/local/jdk1.8.0_241
export HADOOP_HOME=/opt/hadoophdfs-site.xml 这里主要是配置hdfs 的元数据和数据保存的地址,大家按照下面写就可以了
里面数据路径,都是容器内的路径,也就是我们刚刚挂在的匿名卷,大家千万别修改,容易出错
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hdfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>works 文件
这个就是集群的域名
master
s1
s2yarn-site.xml 这个是配置 yarn 的,让集群知道 resourceManager 在哪里,节点间好注册
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>配置就结束了,所有的节点都公用这个Hadoop,就放在宿主机
8、创建集群网络
这里是创建一个桥接网络,子网是 172.10.0.0/16 桥接名字叫 bigdata
docker network create --subnet=172.10.0.0/16 bigdata有这个就可以了 
9、启动master容器
启动容器这里是关键
首先给容器分配了 ip 、host
然后将 刚才宿主机的hadoop 映射给了容器 内的 /opt/hadoop 这也是为什么多个节点可以共用一个haddop 的原因
-v /Users/gump/docker/hdfs/master:/opt/hdfs \ 这个非常重要,每个节点都有一个属于自己的目录, 如 master /Users/gump/docker/hdfs/master
s1 /Users/gump/docker/hdfs/s1
如果用一个目录的话,hadoop 内部是有 lock 机制的,会出问题
-p 9870:9870 \
-p 8088:8088 \
-p 9000:9000 \
将宿主机的 端口和 master 的这些端口 映射了,可以在宿主机直接访问容器

docker run -d \
--add-host master:172.10.0.2 \
--net bigdata \
--ip 172.10.0.2 \
-v /Users/gump/docker/bigdata/hadoop-3.2.1:/opt/hadoop \
-v /Users/gump/docker/hdfs/master:/opt/hdfs \
-h master \
-p 9870:9870 \
-p 8088:8088 \
-p 9000:9000 \
--restart always \
--name master \--privileged \
bigdata:v1 \
/usr/sbin/init 10、启动s1 容器
docker run -d \
--add-host s1:172.10.0.3 \
--net bigdata \
--ip 172.10.0.3 \
-v /Users/gump/docker/bigdata/hadoop-3.2.1:/opt/hadoop \
-v /Users/gump/docker/hdfs/s1:/opt/hdfs \
-h s1 \
--restart always \
--name s1 \--privileged \
bigdata:v1 \
/usr/sbin/init 11、启动s2 容器
docker run -d \
--add-host s2:172.10.0.4 \
--net bigdata \
--ip 172.10.0.4 \
-v /Users/gump/docker/bigdata/hadoop-3.2.1:/opt/hadoop \
-v /Users/gump/docker/hdfs/s2:/opt/hdfs \
-h s2 \
--restart always \
--name s2 \--privileged \
bigdata:v1 \
/usr/sbin/init 
12 进入master 启动集群
这一步一定要等几个节点都成功运行之后才能执行,不然namenode会启动不成功
docker exec -it {master id} /bin/bash
# 格式化namenode
hdfs namenode -format
# 启动集群
start-all.sh13、在宿主机直接访问
因为端口已经映射了
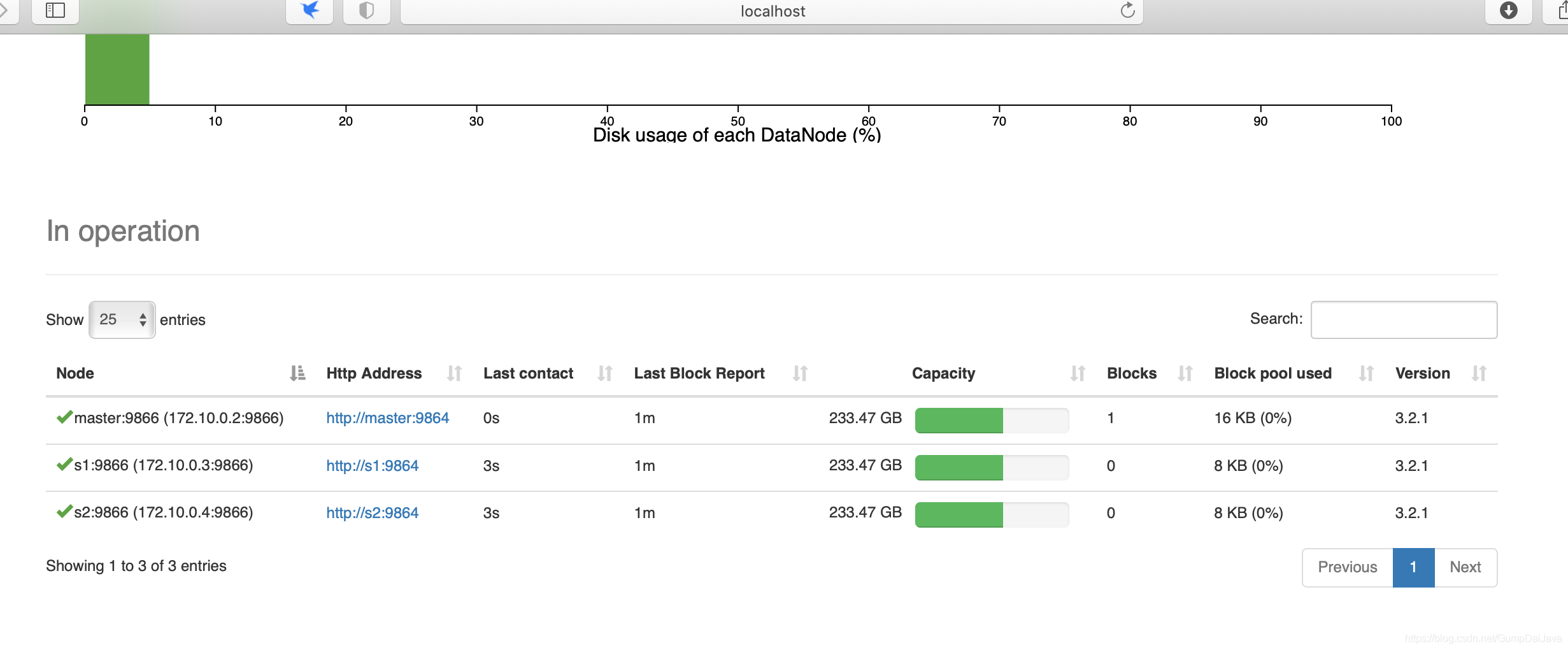
namenode http://localhost:9870
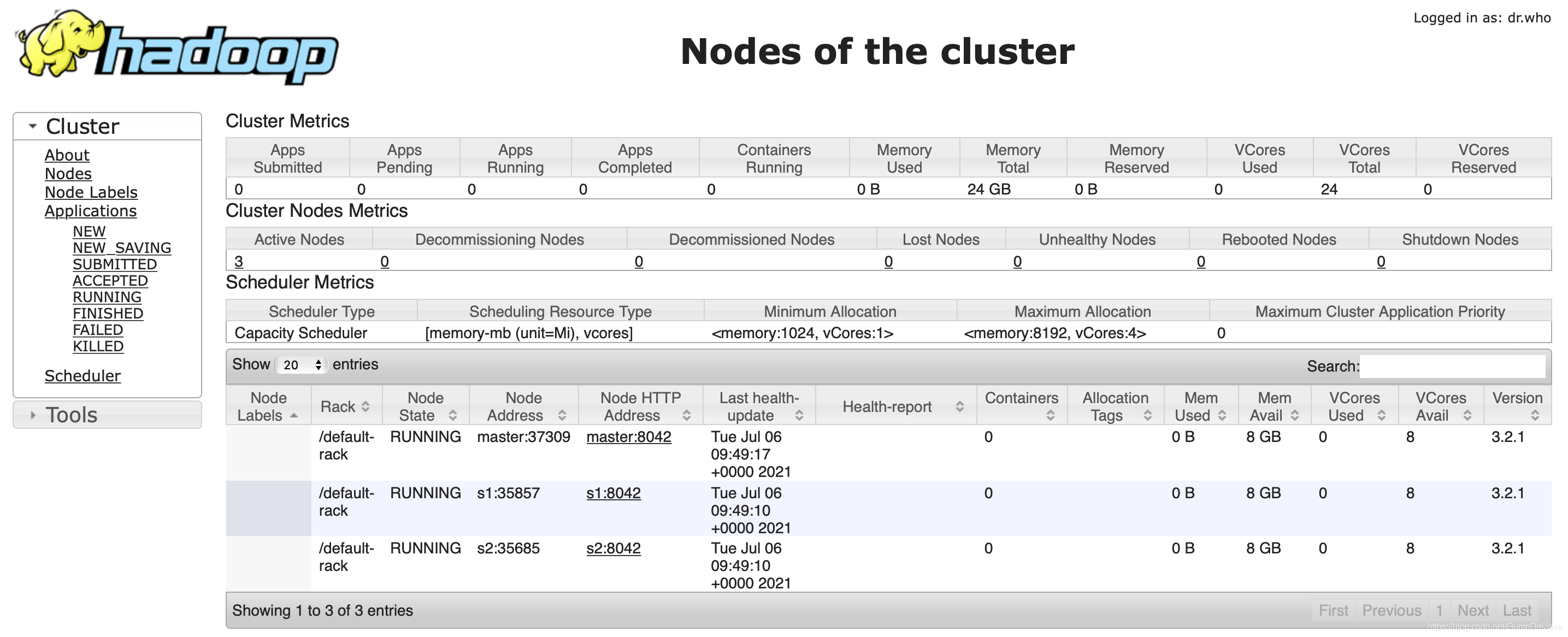
resourceManager http://localhost:8088
结语
这样就完成了
好处: 这样的步骤我们只需要一次,以后就直接拿 镜像运行就可以了
用来在我们本机的测试环境,我8G 内存的mac 都能搭很多很多节点
要测试新版本的Hadoop 的时候,我们只需要把 宿主机里面的更换 就行了,容器不用动,我们的测试成本就非常低了
这只是一个开始:后面我们可以使用容器编排技术,一切就更简单了














 5110
5110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









