







李宏毅深度学习
对于图像分类当然也可以使用一般的DNN;例如要对一张 100 × 100 100\times100 100×100的彩色图像进行分类,如下图:
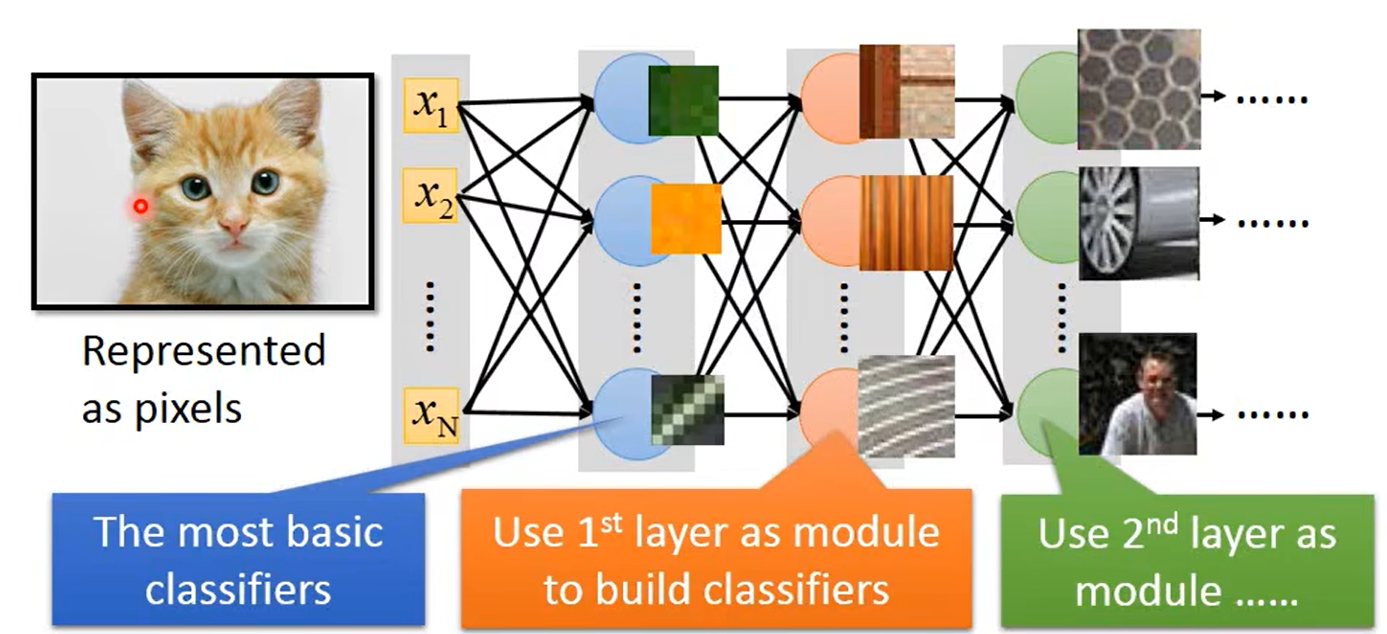
将 100 × 100 100\times100 100×100的彩色图片平铺成 100 × 100 × 3 100\times100 \times3 100×100×3的一维数据作为DNN的输入(维度很大);
DNN中的每个神经节点都可以看作是一个小的 c l a s s i f i e r s classifiers classifiers,如第一层第一个神经节点用于判断是否存在绿色;第二层的神经节点使用第一层的模块去处理更复杂的任务,如第二层的第二个节点用于判断是否存在竖直的条纹。
既然DNN也能够完成任务,那为什么要使用CNN来代替DNN做图像处理呢?
Why CNN for Image?
-
Reason1:Some patterns are much smaller than the whole image.
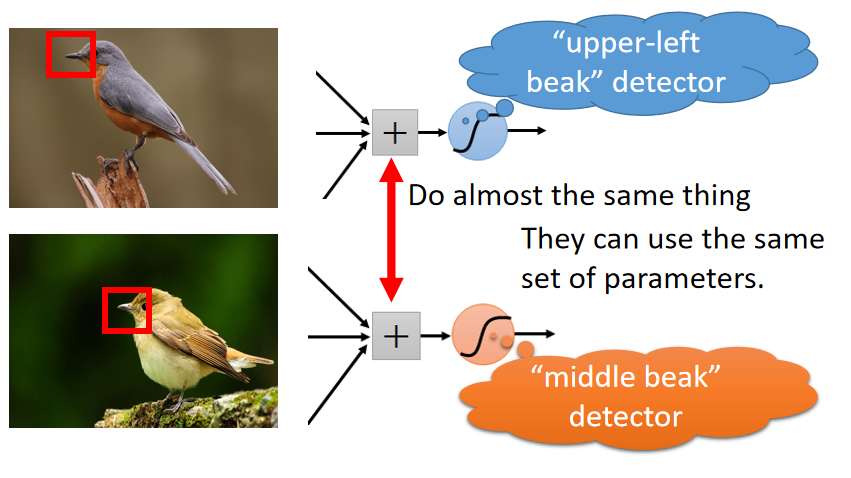
假设某个神经元的任务是判断图片是否有鸟喙,这个神经元没有必要去看整个图像来判断鸟喙的寻找,可以仅通过一小部分区域就可以判断了;如下图:

前面DNN的例子,第一层判断是否存在绿色的神经元接收了全部的图像数据才进行判断,即接收了很多冗余数据。 -
Reason2:The same patterns appear in different regions.
鸟喙很有可能存在于图片的不同区域,若专门设置 2 2 2个不同的神经元来分布处理左上角和中间部分是否存在鸟喙(DNN中的神经元可能在执行类似的任务),这些神经节点的任务是类似的,没必要设置这么多冗余的神经节点。
-
Reason3:Subsampling the pixels will not change the object.
对图像进行降采样并不会对象的特征,如下图:

CNN的任务就是通过考虑图像的属性来简化DNN网络。
CNN整体结构如下图所示:
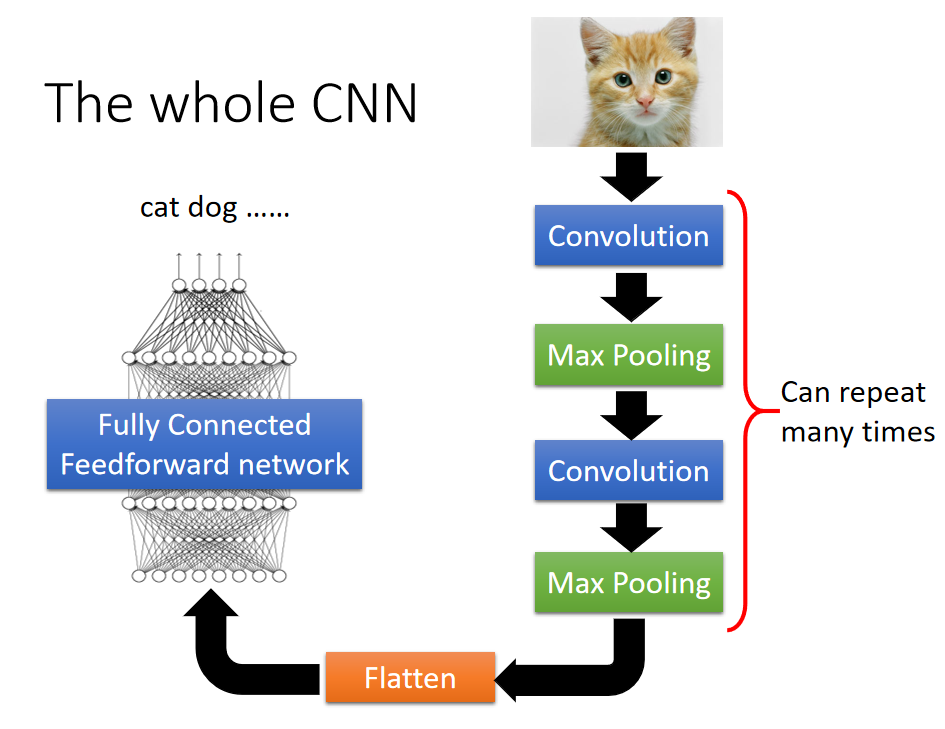
输入图像经过若干的 卷积层- 池化层,将输出结构平铺后再通过全连接层输出分类结果。
卷积层 ( C o n v o l u t i o n ) (Convolution) (Convolution)解决的是 r e a s o n 1 reason1 reason1和 r e a s o n 2 reason2 reason2,最大池化解决的是 r e a s o n 3 reason3 reason3。
Convolution:
吴恩达卷积网络基础
假设卷积层输入图像是一个0或1的
6
×
6
6\times 6
6×6的灰度图像,如下图:
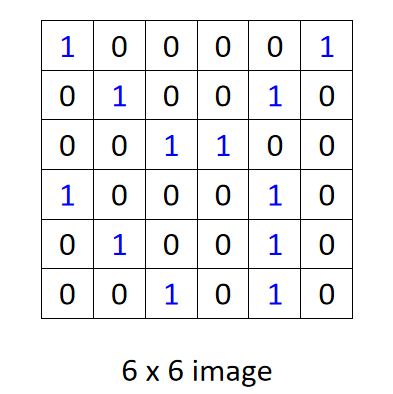
这个图像需要和 F i l t e r 1 Filter1 Filter1和 F i l t e r 2 Filter2 Filter2进行卷积,卷积核1、2都是 3 × 3 3\times3 3×3的,如下图所示:
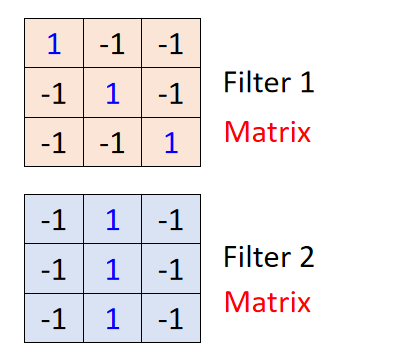
F i l t e r 1 Filter1 Filter1是用来检测输入图像的右斜线, F i l t e r 2 Filter2 Filter2用来检测输入图像的垂直线。
卷积就是将
F
i
l
t
e
r
Filter
Filter覆盖到图片上,对应位置进行相乘,最后将结果进行相加,如下图:
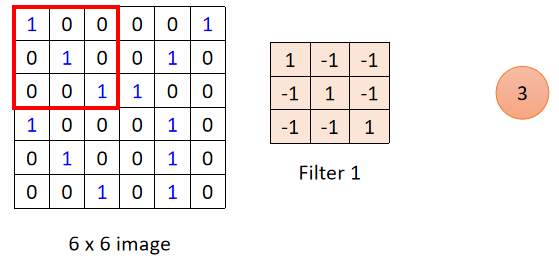
将
F
i
l
t
e
r
1
Filter1
Filter1覆盖到输入图像的红框处,对应位置相乘,再将矩阵中的数相加:
1
∗
1
+
0
∗
(
−
1
)
+
0
∗
(
−
1
)
+
0
∗
−
(
1
)
+
1
∗
1
+
0
∗
−
(
1
)
+
0
∗
−
(
1
)
+
0
∗
−
(
1
)
+
1
∗
1
=
3
1*1+0*(-1)+0*(-1)+0*-(1)+1*1+0*-(1)+0*-(1)+0*-(1)+1*1=3
1∗1+0∗(−1)+0∗(−1)+0∗−(1)+1∗1+0∗−(1)+0∗−(1)+0∗−(1)+1∗1=3
接下来就是根据步长 s t r i d e stride stride来移动红框,依次计算卷积结果; F i l t e r 1 Filter1 Filter1卷积结果如下:
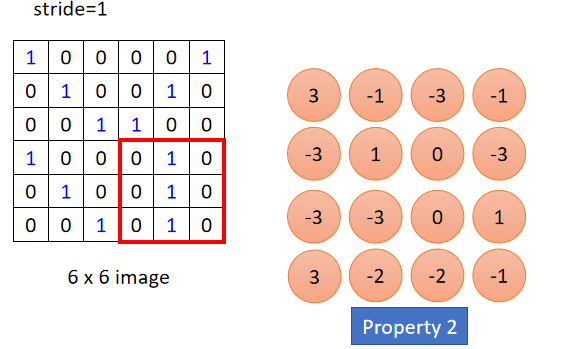
卷积结果左上角和左下角分别得到了最大的3,说明原始图片的左上角和左下角存在右斜线。
所以卷积结果是卷积核对原始图像特征的提取。
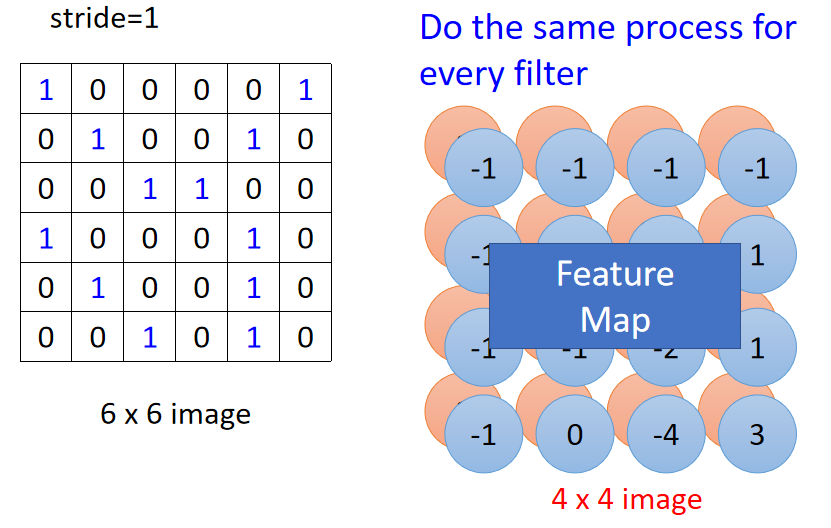
同样的操作给到 F i l t e r 2 Filter2 Filter2,卷积结果是两个 4 × 4 4\times4 4×4的矩阵,称之为 F e a t u r e M a p Feature\ Map Feature Map;如下图:
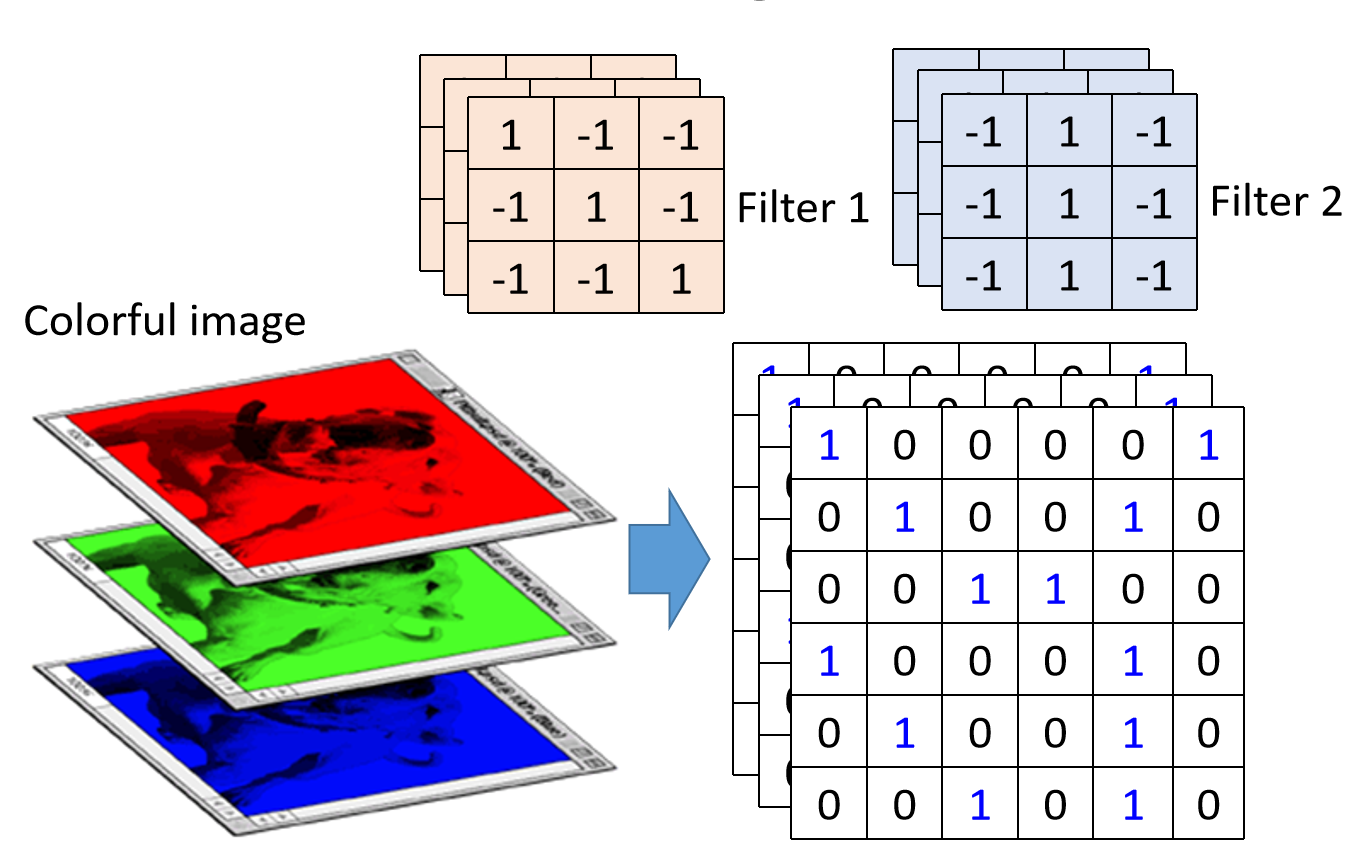
对于具有三个通道的彩色图片,每个卷积核 F i l t e r Filter Filter的通道数都需要和输入图片一致。即对RGB彩色图片,需要用三通道的卷积核来进行卷积操作;如下图:
Convolution v.s. Fully Connected:
CNN和一般的DNN存在什么联系呢?
以 F i l t e r 1 Filter 1 Filter1对 6 × 6 6\times6 6×6图像左上角进行卷积为例子,如下图:
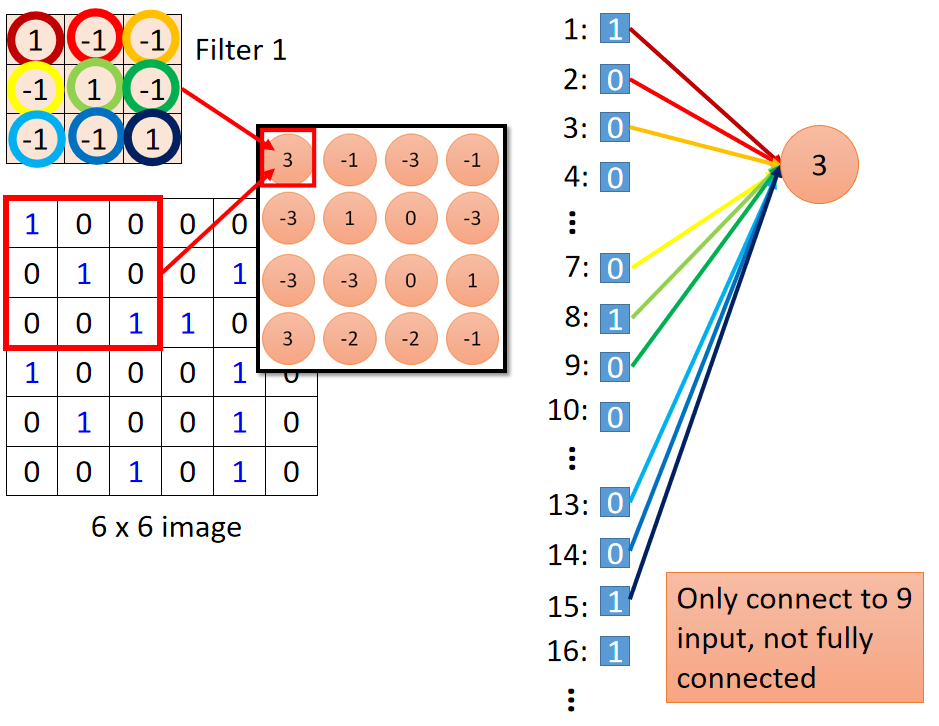
将原始图像平铺成一维数组,再与
F
i
l
t
e
r
Filter
Filter中的数值进行相乘。如上图右侧所示。
可以看出,红框部分就是原始图像的局部采样,相当于一般DNN中 i n p u t input input的部分输入;(这点即 W h y C N N ? Why\ CNN? Why CNN?的 r e a s o n 1 reason1 reason1)
F i l t e r Filter Filter就相当于一般DNN中的权重 w w w,但采用的不是 F u l l C o n n e c t i o n Full\ Connection Full Connection。
这样做的好处有:1. 更少的参数;2. 共享权重( F i l t e r Filter Filter)。
Max Pooling:
最大池化就是对卷积结果划分窗口,然后保留窗口中的最大值作为输出。
如下图,对
F
i
l
t
e
r
1
Filter1
Filter1和
F
i
l
t
e
r
2
Filter2
Filter2的卷积结果划分窗口,然后取最大值作为输出。

F
i
l
t
e
r
1
Filter1
Filter1的最大池化结果:
[
3
0
3
1
]
\begin{bmatrix} 3 & 0 \\ 3 & 1 \\ \end{bmatrix}
[3301]
F
i
l
t
e
r
2
Filter2
Filter2的最大池化结果:
[
−
1
1
0
3
]
\begin{bmatrix} -1 & 1 \\ 0 & 3 \\ \end{bmatrix}
[−1013]
这个过程像是 f e a t u r e s features features信息的压缩,如 F i l t e r 1 Filter1 Filter1的最大池化结果,保留了左上角和左下角的3,其余无效信息丢弃,保留了左上角和左下角存在右斜线的信息。
6
×
6
6\times6
6×6图片经过一层卷积+一层最大池化的结果如下图:
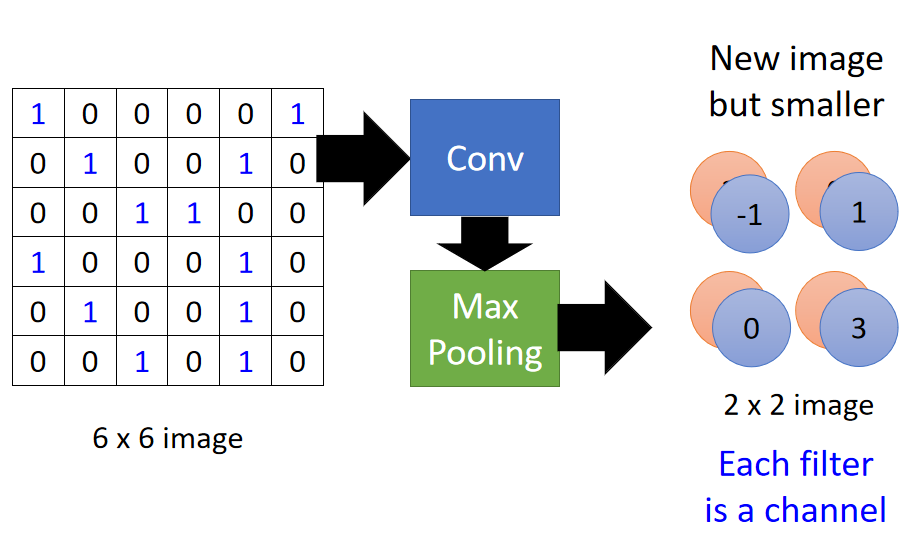
得到了一个保留原始图像大部分特征的更小维度的新图片。
卷积层有多少个卷积核,卷积结果就会有多少个通道。
如上述例子只有 f i l t e r 1 、 2 filter1、2 filter1、2两个卷积核,输出结果是一个 2 2 2通道的 4 × 4 图片 4\times4图片 4×4图片
池化层不会改变通道数,只会影响输出结果的宽和高。
如上述例子将 4 × 4 4\times4 4×4的卷积结果变成了 2 × 2 2\times2 2×2的矩阵。
.
【个人理解】所以卷积层的任务是提取图像特征,池化层是压缩卷积层提取的特征。
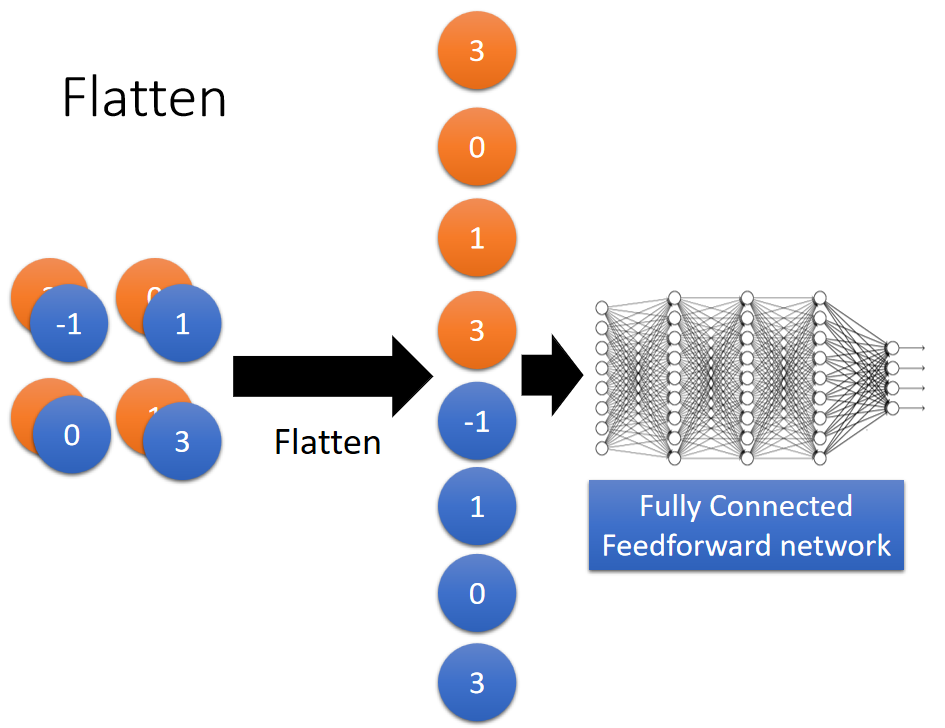
Flatten:
平铺层是将池化结果平铺成一维数组,作为输出输入到全连接神经网络中;如下图:
What does CNN learn?
以下面的CNN结构为例子进行讨论:
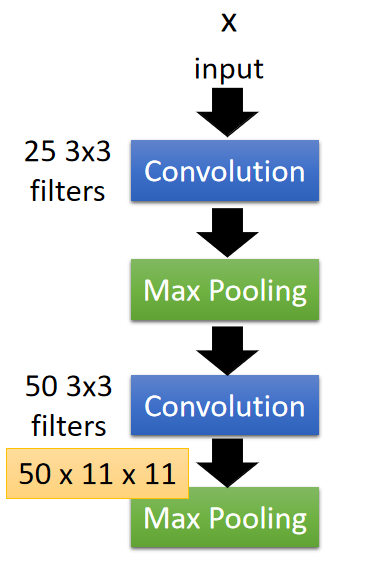
已知第 2 2 2个卷积层包含 50 50 50个 3 × 3 3\times3 3×3的 f i l t e r filter filter,输出的卷积结果维度为 50 × 11 × 11 50\times11\times11 50×11×11;抽取第 k k k个卷积核的卷积结果,如下图所示:
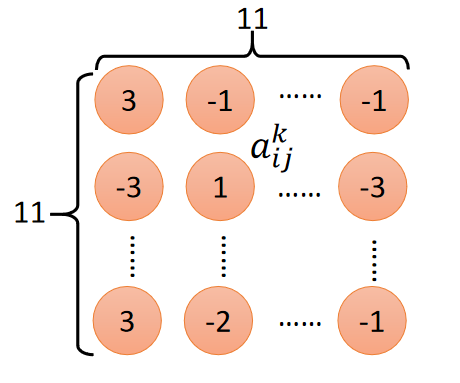
定义第 k k k卷积核的卷积输出的第 i i i行第 j j j列的元素为 a i j k a^k_{ij} aijk。
并定义第
k
k
k个卷积核的激活程度为:
a
k
=
∑
i
=
1
11
∑
j
=
1
11
a
i
j
k
a^k=\sum\limits_{i=1}^{11} \sum\limits_{j=1}^{11}a^k_{ij}
ak=i=1∑11j=1∑11aijk
为了可视化第
k
k
k个
f
i
l
t
e
r
filter
filter学到了什么,需要找到一张输入图片
x
x
x,能够使
a
k
a^k
ak最大化,即:
x
=
a
r
g
m
a
x
a
k
x=argmax\ a^k
x=argmax ak
x x x的值可以通过 g r a d i e n t d e s c e n t gradient\ descent gradient descent的方式去寻找,输入 x x x就是我们需要找到的参数。
个人理解:
第 k k k个 f i l t e r filter filter的卷积输出代表了这个 f i l t e r filter filter对输入图片 f e a t u r e s features features提取的结果。
当输入图片的特性( f e a t u r e s features features)越满足 f i l t e r filter filter提取的特征,激活程度 a k a^k ak就越大。
例如,假设 f i l t e r filter filter提取的是图像中的竖直条纹,当输入图像全是数值条纹时,该 f i l t e r filter filter对图像的卷积结果的值就会较大,那么 a k a^k ak也会很大。
下面是对其中 12 12 12个 f i l t e r filter filter执行上述操作得到的输入图像 x x x:

可以隐约看到最后一个 f i l t e r filter filter是对左斜线纹理的提取。
同样的原理,我们将目标转向找到输入图像
x
x
x,使全连接层的某个神经节点输出
a
j
a^j
aj达到最大值,如下图所示
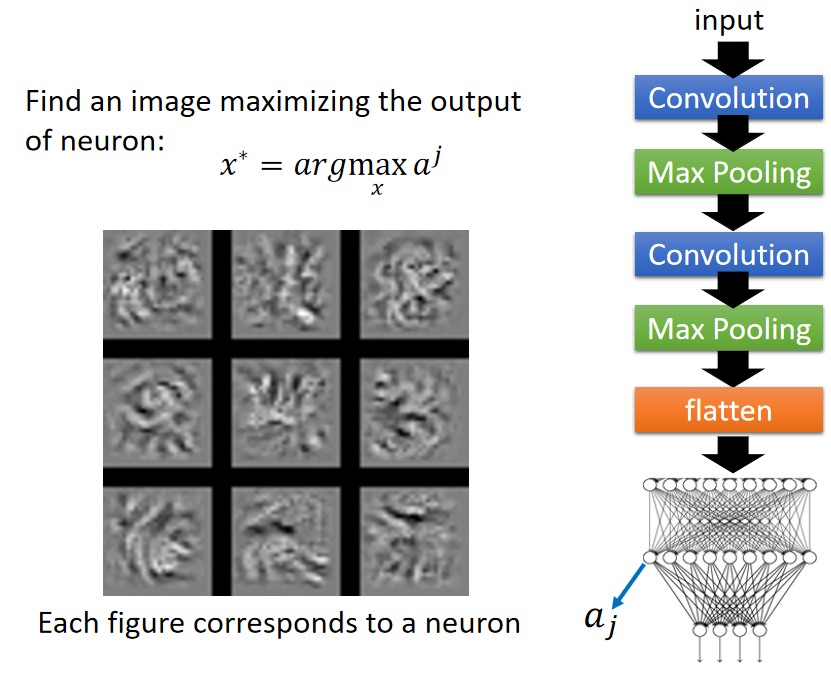
x x x可视化的结果如上图所在,这 9 9 9张图片和之前 f i l t e r filter filter所观察到的情形使很不一样的;不再是单一的纹理,而更倾向于探测一个完整的图案。
补充一点,这个卷积网络是用于手写数字识别的;现在将目光放到输出层上:
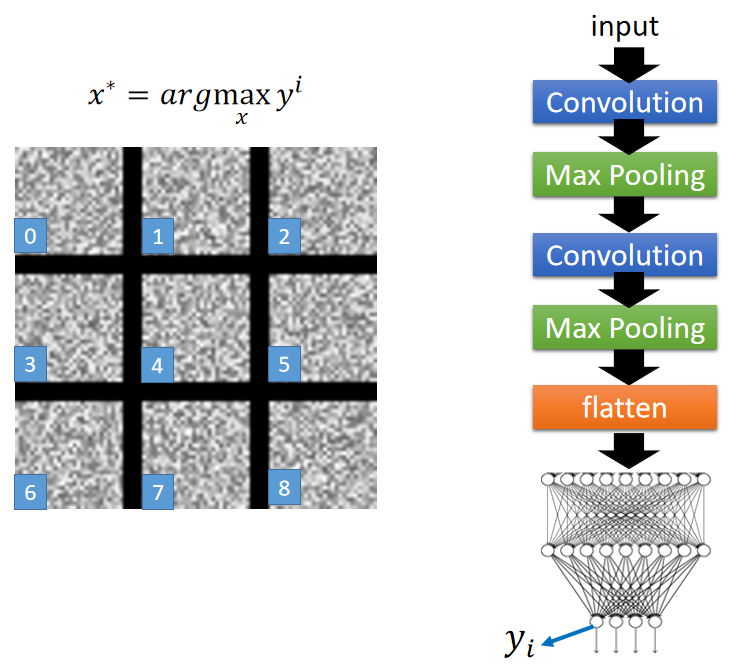
输出
x
x
x的可视化和手写体一点都不像,就像电视机没频道的样子。
为了验证是否是试验出了问题,尝试的去优化一下寻找
x
x
x的损失函数;
x
x
x输出图像中黑色代表空白处,白色代表笔迹;我们希望空白的地方不要那么多,笔迹能够少且更清楚一些。所以在
x
=
a
r
g
m
a
x
y
i
x=argmax\ y^i
x=argmax yi加上一个惩罚项(类似于正则化):
x
=
a
r
g
m
a
x
(
y
i
−
∑
i
,
j
∣
x
i
j
∣
)
x=argmax(y^i-\sum\limits_{i,j}|x_{ij}|)
x=argmax(yi−i,j∑∣xij∣)
得到的结果如下:

可以看到第 6 6 6张和手写数字 6 6 6还是有点像的。
但是其他有些就完全不一样,这样的原因是因为 n e u r a l n e t w o r k neural\ network neural network学到的东西和人类一般想象的认知是不一样的,
Deep Dream
D e e p D r e a m Deep\ Dream Deep Dream就是将CNN学到的东西可视化的一个例子。
准备好一个 C N N CNN CNN和一张图片,将图片丢到 C N N CNN CNN里面去;然后将 C N N CNN CNN中的 c o n v o l u t i o n l a y e r convolution\ layer convolution layer里面的 f i l t e r filter filter或者 f u l l y c o n n e c t e d l a y e r fully\ connected\ layer fully connected layer里的某一个 h i d d e n l a y e r hidden\ layer hidden layer的 o u t p u t output output拿出来,其实就是一个向量 ( v e c t o r ) (vector) (vector);如下图所示:
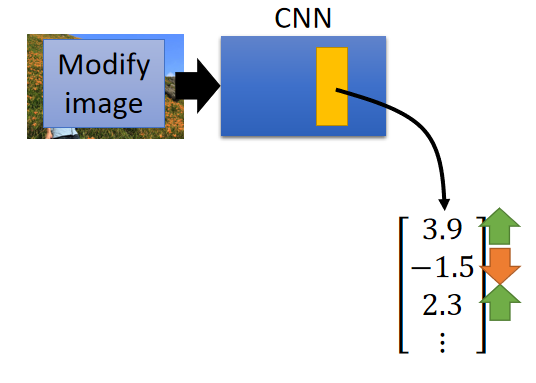
得到这个向量后,将正的值调大,将负的值调小;目的是为了夸大
C
N
N
CNN
CNN学到的东西。接下来以这个调整后的
v
e
c
t
o
r
vector
vector为目标,反向传播学习输入
x
x
x。
丢入的图片如下:

学习到的输入
x
x
x如下:

这图片多了好多动物,如右上角的石头变成了一只熊。对于机器来说这个石头可能有点像熊,经过我们的夸大学习目标后,这个石头看起来就变成了一只熊。这就是 D e e p D r e a m Deep \ Dream Deep Dream。
与之类是的还有 D e e p S t y l e Deep\ Style Deep Style,即神经风格迁移
CNN的更多应用:
(1)
P
l
a
y
i
n
g
G
o
Playing\ Go
Playing Go:
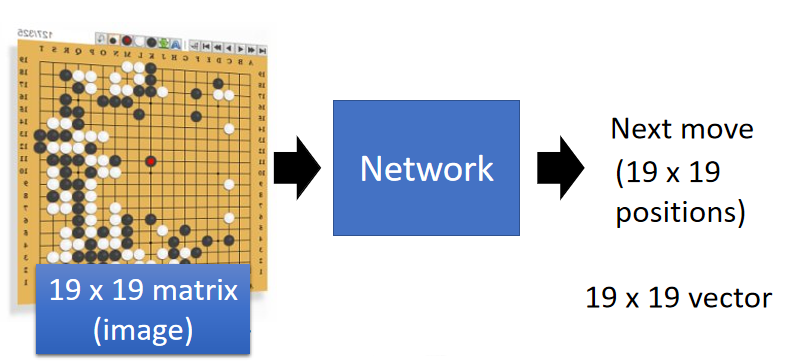
W h y C N N f o r p l a y i n g G o ? Why\ CNN\ for\ playing\ Go? Why CNN for playing Go?(上面的 r e a s o n 1 、 2 、 3 reason1、2、3 reason1、2、3)
-
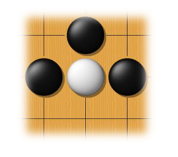
Some patterns are much smaller than the whole image
可能只需要看局部棋盘就能够决定下哪,如下图:
-
The same patterns appear in different regions.
棋盘上有很多一样的棋局,如下图:

-
关于 r e a s o n 3 reason3 reason3:Subsampling the pixels will not change the object.
A l p h a G o Alpha\ Go Alpha Go中是没有使用 M a x P o o l i n g Max\ Pooling Max Pooling的。
所以 C N N CNN CNN不一定只使用在图片上,有和图片相类似性质的都能够使用 C N N CNN CNN去操作。
C N N CNN CNN也可以应用到语音识别、文字情绪分类上。
总结
- 使用CNN的三个基础条件:
1、Some patterns are much smaller than the whole image
2、The same patterns appear in different regions
3、Subsampling the pixels will not change the object - C N N CNN CNN的卷积层针对上面的 1 1 1和 2 2 2,池化层针对 3 3 3
- C N N CNN CNN可以使用在非图像领域。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









