






前面两篇文章,我们介绍了什么是机器学习以及机器学习的核心概念,今天我们就来看看一个完整的机器学习流程是怎么运作的。
下面通过一个简单的小案例,一步步演示机器学习项目的流程。
假设我们的任务是:根据水果的外观特征来识别它是香蕉还是橘子。 这其实是一个典型的机器学习分类问题(输出的是类别)。
通常,一个完整的机器学习项目可以分为以下几个步骤:
-
数据收集 – 获取训练模型所需的数据
-
数据预处理 – 清洗并整理数据,使其适合模型使用
-
特征工程 – 提取和选择有用的特征作为模型输入
-
模型选择 – 确定要使用的机器学习算法或模型类型
-
模型训练 – 用已有的数据让模型学习参数
-
模型评估 – 检测模型在未见过的数据上的效果,调整优化
-
模型部署 – 将训练好的模型投入实际使用,进行预测
一、数据收集
要让机器学习,先得有“教材”。数据就是机器学习的教材,模型能学到的东西很大程度上取决于数据质量和数量。常言道:“垃圾进,垃圾出”,如果喂给模型的是垃圾数据,它学到的也会是垃圾,自然表现不佳。所以,第一步我们需要尽可能收集充分且高质量的数据。
在水果识别的例子中,我们就要去收集各种各样的香蕉和橘子的数据。

比如,我们跑一趟水果市场,买回来不同品种、不同大小的香蕉和橘子各若干。对于每一个水果,我们记录下能够量化的特征。这里简单起见,我们选两个特征:颜色和形状。香蕉通常是黄色、长条形,橘子通常是橙色、圆形。因此,我们可以用「颜色」和「形状」作为特征,并且记录每个样本的标签(香蕉或橘子)。收集的数据可能用表格表示如下:
| 颜色(波长) | 形状 | 类别(标签) |
|---|---|---|
| 580 | 长条形 | 香蕉 |
| 605 | 圆形 | 橘子 |
| ... | ... | ... |
(注:以上数值只是为了举例说明,比如颜色可以用一定范围内的数值代表不同的颜色波长。)
在实际的机器学习项目中,数据收集的方式多种多样,可能包括:从公开数据源下载数据(如Kaggle数据集)、通过问卷或传感器获取数据、从数据库/日志中提取业务数据,甚至亲自手动标注数据等。不管来源如何,有两个要点需要牢记:
-
数据要有代表性: 所收集的数据应尽量覆盖问题空间的各种情况,避免严重偏斜。例如,如果我们的水果照片全都是在白天拍摄的,模型可能学会依赖明亮背景,一到夜晚就认不出。这就要求我们收集香蕉和橘子的样本要多样,包括颜色深浅不同的香蕉,大小不同的橘子,甚至可能包括青香蕉、半青半黄的橘子等,确保模型不会只学到某些特殊情况下的特征。代表性的数据能让模型更健壮,不容易一遇到稍有差别的新情况就出错。
-
数据量要尽可能充分: 机器学习是“用数据说话”,一般来说,数据量越多,模型能学得越全面。当然也不是无限多就一定好,但少量的数据往往难以支撑训练出一个效果稳定的模型。就像我们教小孩认字,给他看10个字肯定比不上看1000个字学得扎实。对于我们的水果分类例子,如果只收集了三五个水果样本,让模型学习显然不够,我们至少要上百上千张香蕉和橘子的图片或度量数据才比较稳妥。
在收集数据时,还要顺带明确我们的任务和目标。换句话说,要想清楚“我们要用这些数据预测什么”。这一点在实际项目中非常重要。
比如你想用用户行为数据来预测流失用户还是续费用户?想用医疗数据预测患者是否患某种疾病?任务定义清晰,才知道需要收集哪些数据,预测哪个目标。
在我们的例子里,我们的目标很明确:根据颜色和形状分类水果种类(香蕉或橘子)。因此收集回来的每条数据,我们都贴上了对应的类别标签,这就是一个监督学习的数据集(带有正确答案供学习)。
总之,数据收集是整个机器学习流程的基石。这一步做好了,后面的路会顺畅得多。如果把机器学习比作造房子,数据就像砖瓦原料,只有备料充足、材质过关,房子才能盖得稳固。
二、数据预处理
拿到了原始数据后,并不能直接拿来喂给模型。现实中的数据常常是“杂乱无章”的——可能有缺失值(比如有些水果漏记了颜色)、有异常值(输入错误导致某个香蕉颜色记录成了不可能的数字)、不同单位尺度不统一(比如高度用厘米,重量用公斤)等等。在进入建模阶段之前,我们需要对数据进行预处理,把它整理干净,变成模型能消化的形式。
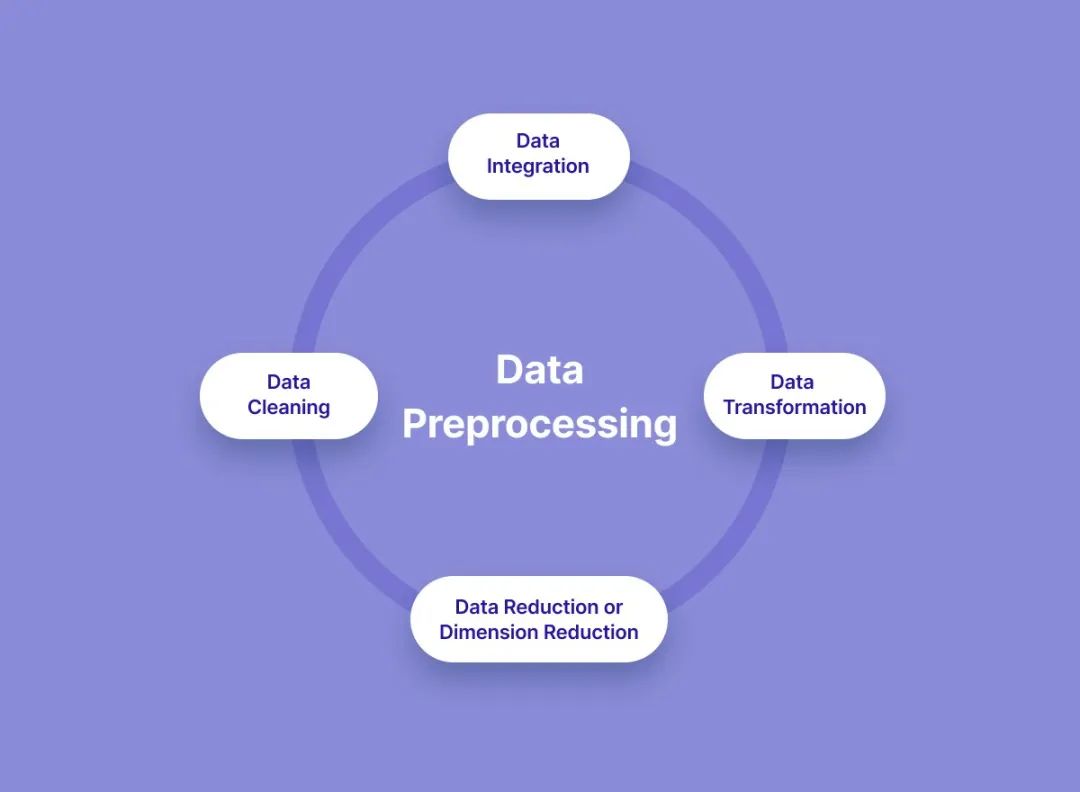
数据预处理的具体操作会因项目而异,但典型的工作包括以下几方面:
-
数据清洗:处理数据中的异常和缺失。例如,如果某些样本缺少“形状”信息,我们可以选择剔除这些不完整样本,或者用出现频率最高的形状来填补缺失值。在我们的水果例子中,如果发现一条记录颜色缺失,我们可以删除这条记录(在数据量足够大的前提下影响不大)或者重新测量补上。还要检查有无错误数据,比如有人误把香蕉记成了“蓝色”,这种明摆着不合理的数据需要更正或丢弃。数据清洗就像做实验前整理实验材料,确保没有“噪音”干扰结果。
-
数据格式转换:将数据转换成适合分析的形式。举例来说,颜色和形状在我们的记录中可能是用文字描述的(“黄色”、“长条”),但计算机模型更擅长处理数字。我们可能需要把分类数据数值化(例如用0代表圆形、1代表长条形),或者把文本转成标准形式。又比如日期类型,我们可能拆分成年、月、日三列数值,或者转换成距离某个基准日的天数。总之,要让定性的信息用定量方式表达出来。
-
特征缩放(规范化):如果各特征的取值范围相差悬殊,模型训练时可能会偏向数值大的特征,需要进行缩放处理。例如某数据集里“收入”以元计动辄上万,而“评分”是1到5,这时常用的方法是做归一化/标准化,把特征值转换到相近的尺度范围。这样可以加速模型收敛,也防止某些算法受大数值主导。对于我们的例子,假设颜色已经用数值波长表示大约在400-700范围,而形状我们用0/1表示,数值量级不同,我们也可以考虑把颜色值归一化到0-1区间。
-
数据集划分:这是非常重要的一步 —— 划分训练集、验证集和测试集。简单来说,我们不会把所有收集到的数据一股脑拿去训练模型,否则就无法评估模型对新数据的表现。这就像老师教学生时,会留一些题目不讲,等考试时再拿出来测试学生。通常的做法是将数据随机分为三部分:
举例来说,如果我们总共收集了1000个水果样本,可能划分出700用于训练,150验证,150测试。在整个训练过程中,测试集的数据我们绝对不去碰,直到最后评估才用。这能确保评估结果客观反映模型对“新样本”的泛化能力。对于小型项目,有时也会合并验证集和测试集,但严格来说有单独验证集会更科学一些。
-
训练集(train set):用来训练模型,占总数据的最大一部分,比如60%-80%。
-
验证集(validation set):在训练过程中用于调参和验证模型的中间表现,占总数据的10%-20%。验证集相当于平时的测验,帮助我们调整模型以防止过拟合等问题。
-
测试集(test set):在模型训练完毕后最终评估模型性能的数据,占总数据的剩余10%-20%。测试集就好比最终的期末考,只有一次机会来检验模型的真正能力。
-
经过这一系列预处理步骤,我们的数据就干净又整齐了,可以满足模型训练的要求。对于我们的水果数据,此时可能已经变成这样一种结构:
颜色波长 形状编码 标签
0.75 1 0 <--(0表示香蕉)
0.82 0 1 <--(1表示橘子)
... ... ...
颜色波长被归一化到了0.0~1.0区间,形状“长条/圆形”被编码为1或0,缺失的数据行已清理,数据集也已经随机打乱并按照7:2:1的比例划分好了。现在,我们终于可以进入建模阶段了。
❝归一化和标准化都是数据预处理方法,用于消除量纲差异。归一化(如Min-Max)将数据缩放到固定范围(如0-1),适用于依赖距离的模型(如KNN);标准化(如Z-score)使数据均值为0、方差为1,保留异常值影响,适用于数据分布不稳定或算法假设正态分布的场景(如线性回归)。 核心区别:归一化受极值影响大,标准化对异常值更鲁棒。
三、特征工程
机器学习有句话:“数据和特征决定了模型性能的上限,算法和模型只是逼近这个上限。” 经过预处理,我们已经有了比较干净的数据,但还需要考虑一个问题:哪些数据特征能用于预测,我们是否需要创造或挑选特征? 这就是特征工程要解决的事情。
特征(Feature)指用来描述数据的可量化属性。在我们的例子中,“颜色的波长值”和“形状类别”就是两项特征。对于不同的问题,特征可能是原始数据直接提供的(例如房价预测中房子的面积、卧室数就是天然的特征),也可能需要我们从原始数据中提炼。特征工程主要包含两部分:
-
特征构造:有时候原始数据并不能直接拿来用,需要根据原始数据衍生出新的有效特征。例如,在房价预测问题中,我们也许会用“每平米房价”作为特征,而原始数据里只有总价和面积,我们可以用总价除以面积得到每平米价这个新特征。又比如在用户行为预测中,可能需要从原始的点击记录计算出“平均停留时长”这样的特征。特征构造往往需要领域知识的支撑:你对问题理解越深入,越知道哪些潜在因素可能重要,从而设计出更有预测力的特征。
-
特征选择:并非特征越多越好,太多无关或冗余的特征不仅增加计算开销,还可能让模型分辨不清重点,反而降低效果。因此,我们常常需要从候选特征中挑选出最有效的那些。这可以通过统计指标(如计算每个特征与目标的相关性)或者基于模型的方式(如决策树模型自带的特征重要性评估)来完成。特征选择有点像做菜挑料,用最合适的食材,去掉那些不起作用甚至有害的调料,才能做出好菜。比如在水果识别中,如果我们还记录了“水果重量”这个特征,但发现香蕉和橘子的重量区分度不大,反而因为测量误差还引入噪声,那我们可以选择不使用“重量”这个特征,以免干扰模型学习。
简单来说,特征工程就是要让有用的信息尽可能有效地呈现给模型,同时减少无用信息的干扰。在我们的案例里,因为一开始就选取了很有区分度的颜色和形状作为特征,可能不需要额外构造新特征,也暂时没有太多特征需要筛选(因为总共才两三个特征)。但在实际问题中,特征工程往往是最花时间也最考验功力的一步。很多时候,一个简单模型如果有好的特征,效果会胜过复杂模型配一般特征。
对于初学者,可以记住:特征是模型学习的依据,好的特征能让复杂问题变简单。 在这个过程中,多和业务领域专家沟通、发挥常识和创造力,往往能找到更佳的特征表示方法。特征工程做得好,后面的模型训练就会事半功倍。
❝在深度学习兴起之前,特征工程几乎是每个机器学习项目的重头戏;而深度学习模型能够自己从海量数据中学特征,比如卷积神经网络可以自动从图像学到边缘、纹理等高阶特征,因此在某些领域,人工特征工程的重要性有所下降。但对于结构化数据问题,特征工程依然非常关键。
四、模型选择
数据和特征都准备好了,现在要选择用什么“模型”来学习这些数据的规律。所谓模型(Model),可以理解为一个拟合数据的数学函数或算法, 它接收输入特征,输出预测结果。在机器学习中,不同类型的问题和数据往往适合不同的模型,就像对症下药,选择合适的工具一样。
模型选择包含两个层面的含义:一是选择模型类型/算法,二是设计模型的结构和参数(如果是复杂模型的话)。对于初学者,我们先关注模型类型的选择。在机器学习领域,有各种各样的模型可供选择,例如:
-
如果要解决分类问题(比如判别邮件是否垃圾邮件、图片里是谁的脸),可以考虑的模型有逻辑回归、决策树、支持向量机、神经网络等。
-
如果是回归问题(预测连续值,比如明天的股票价格),可以用线性回归、回归树、梯度提升机等。
-
如果是处理图像、语音等感知类数据,深度学习(卷积神经网络CNN、循环神经网络RNN等)在这些领域表现突出。
-
如果没有标签数据,需要做聚类或者降维分析,则可以选择K-means聚类、主成分分析(PCA)之类的无监督学习方法。
总之,不同模型各有优劣:有的模型简单直观但可能精度有限(如线性模型),有的模型强大灵活但需要更多数据和计算资源(如深度神经网络)。我们需要结合任务类型、数据特点以及资源限制来决定用哪一种模型。
回到我们的水果分类小例子。我们其实有很多选择——由于特征很简单,我们完全可以使用决策树模型:它会根据颜色和形状学一个判断规则,比如“如果形状是长条则判为香蕉,否则如果颜色数值大于某阈值则判为橘子”等等。这种规则其实和人类直觉类似。我们也可以用逻辑回归模型,根据两个特征训练出一个分类边界。甚至可以训练一个小型神经网络来完成这个二分类任务。不过考虑到数据量不大、特征也就两个,用复杂模型大材小用,我们更倾向于选一个简单易解释的模型,比如决策树或逻辑回归。模型越简单,越不容易过拟合,而且训练速度也快——这也是现实中常见的考虑,不必一上来就用最复杂的新潮模型,而是选择一个恰当能解决问题的即可。
模型选择过程有点像买工具:修电脑需要螺丝刀还是扳手,干重活要卡车还是小轿车,不同情况需要的工具不同。同样地,我们为问题挑选合适的模型,也是为了后续训练能顺利且有效。如果拿错了“家伙”,要么学不出东西,要么浪费资源效果还不好。
在确定模型类型之后,还涉及一些模型结构或超参数的选择。比如神经网络要决定有几层、每层多少神经元,决策树要考虑最大深度等。不过这些细节超出了本文的基础范围,而且通常可以通过实验来调整。对于入门学习,先了解各种模型的大概适用场景,多练习几种算法,会对模型选择的直觉越来越有帮助。
五、模型训练
选定了要用的模型,现在进入机器学习最核心的阶段——训练。这一阶段,我们将让模型在已有的数据上“学习”出规律,也就是确定模型的具体参数,使模型能够较好地拟合输入与输出的关系。
通俗来讲,训练模型就像教模型去认识我们的数据。对模型来说,训练集里的每一条样本都是一堂课。它会根据当前参数对样本做出预测,然后和真实标签比对,看看自己答得对不对、误差有多大。接着,模型根据这些误差来调整自身的参数(这个调整的过程由特定的学习算法完成,比如梯度下降法会沿着减小误差的方向优化参数)。模型不断地在所有训练样本上反复试错和改进,就像学生反复做题、订正、再做题一样,慢慢地,模型的预测误差会越来越小,表现越来越好。
在一开始,模型往往是“啥也不会”,比如我们初始化一个模型来分辨香蕉和橘子,最初它可能完全随机地瞎猜,错误百出。但通过训练,它会逐渐学会:“哦,看到形状长长的更可能是香蕉”“颜色偏橙的更可能是橘子”,内部参数不断更新。训练的目标就是让模型在训练数据上表现良好,即找出一个能将输入映射到正确输出的函数近似。
值得注意的是,我们并不希望模型把训练集死记硬背,而是希望它学到普遍规律。如果模型过度追求训练误差为零,可能陷入过拟合(Overfitting)的陷阱——就像有的学生只会做老师画过的原题,遇到新题就不行了。因此在训练过程中,我们通常会一边训练一边监控模型在验证集上的表现。如果发现训练集准确率一直提高但验证集准确率反而下降,就意味着模型可能开始过拟合了,这时应该停止训练或采用一些正则化技术来约束模型复杂度。
对于我们的水果模型,由于特征简单清晰,一个非常简单的模型训练几轮可能就趋于收敛(达到最好状态)。比如一个决策树很快就能找到基于颜色和形状分类的分割点,使得训练集上几乎100%正确。然而,我们更关心的是它对验证集和未来新样本的表现,所以我们不会仅以训练集的成绩评价模型好坏,而是为下一步的评估做好准备。
总结来说,模型训练就是让模型不断调整自己去拟合训练数据。这个过程需要耐心和良好的监控。有些模型训练非常快速(秒级就完事),有些比如深度学习训练一个模型可能要跑好几个小时甚至几天。这一步也对应了机器学习中的“学习”二字,是实现智能预测能力的关键环节。
六、模型评估
模型训练完成后,我们需要冷静地检验模型到底表现如何,这就是模型评估阶段。评估的目的是了解模型在未见过的数据上的性能,以确定它是否真的学到了有用的东西,还是仅仅“记住”了训练集。还记得我们之前留出的测试集吗?现在是时候用它来考验模型了。

评估时,我们会将测试集(或验证集)输入训练好的模型,得到预测结果,然后将这些预测和真实的标签进行对比,计算一些评价指标。常用的评价指标取决于任务类型:
-
对于分类问题,准确率(Accuracy)是最直观的指标之一,即模型预测正确的比例。有时候我们也会关注精确率(Precision)和召回率(Recall)(特别是在正负样本不平衡时),以及它们的调和平均数F1-score。这些指标能更全面地反映分类模型的性能,例如精确率高表示预测为正的那些多数是对的,召回率高表示实际为正的多数被找出来了。
-
对于回归问题,常用指标有均方误差(MSE)、平均绝对误差(MAE)等,衡量模型预测的数值与真实值的偏差程度。
-
此外还有一些可视化方法辅助评估,比如分类问题可以绘制混淆矩阵(观察各类别被误分类的情况),二分类问题可以看ROC曲线和AUC值,回归问题可以画出预测值vs真实值的散点图等等。
对于初学者,可以先从准确率等简单指标入手理解。例如,我们的水果分类模型在测试集上测试,如果100个水果里模型正确地分对了90个,那准确率就是90%。如果发现准确率只有60%,那说明模型可能还不够好,要么训练不到位,要么选错了特征或模型,需要回去查找原因。
模型评估除了告诉我们成绩,也可以暴露模型存在的问题。最常见的现象有两种:过拟合(Overfitting)和欠拟合(Underfitting)。
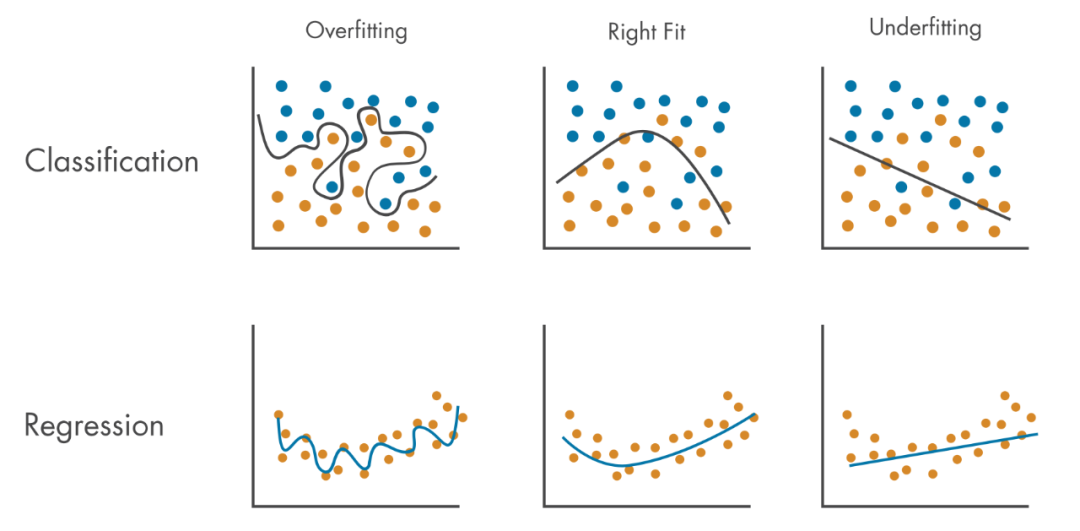
过拟合前面提过,表现为训练集结果很好但测试集结果很差,说明模型把训练集特殊性当作普遍规律了,针对这种情况我们可以考虑简化模型、加入正则化或者增加训练数据。
欠拟合则是训练集本身效果就不好,模型根本没学明白,通常可以通过提高模型复杂度或训练更久、提供更多特征来改善。一个诀窍是画出模型的学习曲线(训练集和验证集的错误率随训练样本数的变化曲线),可以帮助判断目前处于过拟合还是欠拟合状态。
评估阶段往往决定了接下来如何改进模型。如果模型在测试集上的表现达到了预期,那皆大欢喜,可以准备部署了;但很多时候初版模型效果不理想,这很正常,需要分析问题出在哪,然后“回炉返工”。
这个返工不一定是坏事,实际上机器学习项目都是一种迭代过程:评估->发现问题->改进->再训练->再评估...循环往复把性能逼近理想水平。
例如,我们的水果模型如果发现老是把某些浅黄色橘子错认成香蕉,我们可能意识到单用颜色和形状还不够区分这些情况,或许还需要增加“表皮纹理”这样的新特征,于是回到特征工程阶段新增特征;又或者发现模型选择不当,那就尝试换一个模型再训练看看。每一次评估反馈都指导我们做出相应调整,使模型逐步完善。
最后,在我们对模型进行充分评估并觉得其性能达到业务需求后,就可以进入最终阶段——部署和预测。当然,如果评估结果不达标,就需要回到前面的步骤继续打磨。
七、模型部署与预测
经过反复打磨,我们终于得到了一个在测试集上表现优秀的模型。现在到了收获成果的时候:将模型投入实际使用,也就是进行部署和预测。所谓部署(Deployment),是指把模型集成到现实的应用环境中,让真实的数据通过模型得到预测结果,为用户或业务创造价值。
部署的方式可以有很多种,取决于具体应用场景:
-
嵌入到应用程序中:比如把模型打包进一个手机APP,当用户拍摄一张水果的照片,我们的模型就运行在APP里,立即给出这是香蕉还是橘子的预测。这种方式要求模型比较小巧高效,因为要在终端设备上执行。
-
作为云端服务:很多情况下,模型会被部署在服务器上,提供API接口。各地的应用把数据发到云端,请求模型服务返回预测结果。例如一家电商把用户资料发送到云端模型服务,返回该用户是否流失的预测概率。部署在云端便于集中管理和更新模型,但需要保障服务的稳定性和响应速度。
-
嵌入物联网设备:有些模型会部署在工厂的流水线上或智能硬件中,比如我们的水果分类模型可以部署在一个自动分拣机器上,机器通过摄像头捕捉到水果图像,模型实时判断其种类,然后机械臂将香蕉和橘子分开放置。这类部署通常对实时性要求高,而且模型可能需要在有限算力设备上运行。
在部署模型时,还需要考虑一些工程问题,比如模型保存和加载(通常我们会将训练好的模型参数序列化保存,以便部署时读取)、预测效率(是否需要优化模型计算,加速预测速度)、可扩展性(如果请求量很大如何扩容服务)等等。初学者可以先了解概念,不用深入细节。
一旦模型部署就绪,新的数据源源不断地进来,模型就开始为我们提供预测了。这时我们要保持对模型的监控,因为真实环境可能和测试集有所差别。如果模型在实际使用中遇到很多罕见情况,性能可能下降,需要定期通过新的数据来重新训练或更新模型,保持模型的鲜活度。机器学习部署并非终点,更像是进入了一个维护阶段,需要持续观察和改进。
经过这七个步骤,我们完成了从无到有训练一个机器学习模型并实际应用的全过程。当然,每个步骤在现实项目中都可能比我们描述的复杂得多,但基本思路是一致的:明确问题->获取并准备数据->选择并训练模型->评估效果->上线使用。
机器学习项目本质上是不断尝试和优化的过程。
资源推荐
系统入门课程:建议先系统学习一下机器学习的入门课程。例如吴恩达(Andrew Ng)的机器学习课程是全球知名的经典入门课,内容通俗易懂,对数学要求不高,还有中文字幕版可供学习【在B站等视频网站搜索“吴恩达 机器学习课程”即可找到】。这门课程会带你深入了解常用算法原理和实战应用。Google出品的机器学习速成课程(Machine Learning Crash Course)也非常适合初学者,自带交互式案例练习,而且有中文版网站。(学习资料已经打包好放下面啦!)
实践练手:机器学习是实践驱动的,光看不练是不行的。可以从一些简单的实例入手练习编程实现,比如预测房价、分类鸢尾花数据集等经典题目。常用的编程工具是Python搭配scikit-learn库(一个功能完备的机器学习Python库,封装了各种算法,使用简单)。

最后
如果你真的想学习人工智能,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
这里也给大家准备了人工智能各个方向的资料,大家可以微信扫码找我领取哈~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









