







简单分析W13scan漏洞扫描器插件系统实现
源代码地址:w-digital-scanner/w13scan: Passive Security Scanner (被动式安全扫描器) (github.com)
这里先分析主动扫描执行流程
KB字典的定义
这个类的设计主要是为了增强字典的功能,使其具备类似属性访问的能力。其设计思想包括以下几点:
- 方便性:通过将字典的键值对映射为属性,可以更直观地访问和操作字典的内容,使代码更加简洁易懂。
- 灵活性:该类允许在初始化时设置附加属性,这些属性与字典的键值对并行存在,提供了更灵活的使用方式。
- 一致性:在初始化后,设置属性与设置字典项的操作是相同的,这样可以保持代码的一致性,减少使用者的困惑。
- 兼容性:该类实现了
__getstate__和__setstate__方法,使得对象可以被正确地序列化和反序列化,这样就可以在不同的环境中进行传输和存储。 - 深拷贝支持:通过实现
__deepcopy__方法,使得对象可以正确地进行深度复制,包括对附加属性和字典键值对的复制。
KB = AttribDict()
class AttribDict(dict):
"""
这个类定义了一个具有额外功能的字典,可以将成员访问为属性。
"""
def __init__(self, indict=None, attribute=None):
"""
初始化 AttribDict 对象。
Args:
indict (dict): 用于填充 AttribDict 的初始字典(默认为 None)。
attribute (any): AttribDict 对象的附加属性(默认为 None)。
"""
if indict is None:
indict = {}
# 在初始化之前设置任何属性 - 这些属性仍然是普通属性
self.attribute = attribute
dict.__init__(self, indict)
self.__initialised = True
# 初始化后,设置属性与设置项相同
def __getattr__(self, item):
"""
将值映射到属性。
仅在不存在具有该名称的属性时调用。
"""
try:
return self.__getitem__(item)
except KeyError:
raise AttributeError("无法访问项目 '%s'" % item)
def __setattr__(self, item, value):
"""
将属性映射到值。
仅在我们初始化时调用。
"""
# 此测试允许在 __init__ 方法中设置属性
if "_AttribDict__initialised" not in self.__dict__:
return dict.__setattr__(self, item, value)
# 任何普通属性都以常规方式处理
elif item in self.__dict__:
dict.__setattr__(self, item, value)
else:
self.__setitem__(item, value)
def __getstate__(self):
"""
返回对象的状态以进行 pickling。
"""
return self.__dict__
def __setstate__(self, dict):
"""
在反 pickling 后设置对象的状态。
"""
self.__dict__ = dict
def __deepcopy__(self, memo):
"""
对对象执行深层复制。
Args:
memo (dict): 用于存储已复制对象的字典。
Returns:
AttribDict: 对象的深层副本。
"""
retVal = self.__class__()
memo[id(self)] = retVal
for attr in dir(self):
if not attr.startswith('_'):
value = getattr(self, attr)
if not isinstance(value, (types.BuiltinFunctionType, types.FunctionType, types.MethodType)):
setattr(retVal, attr, copy.deepcopy(value, memo))
for key, value in self.items():
retVal.__setitem__(key, copy.deepcopy(value, memo))
return retVal
接着重点分析一下插件化系统的实现
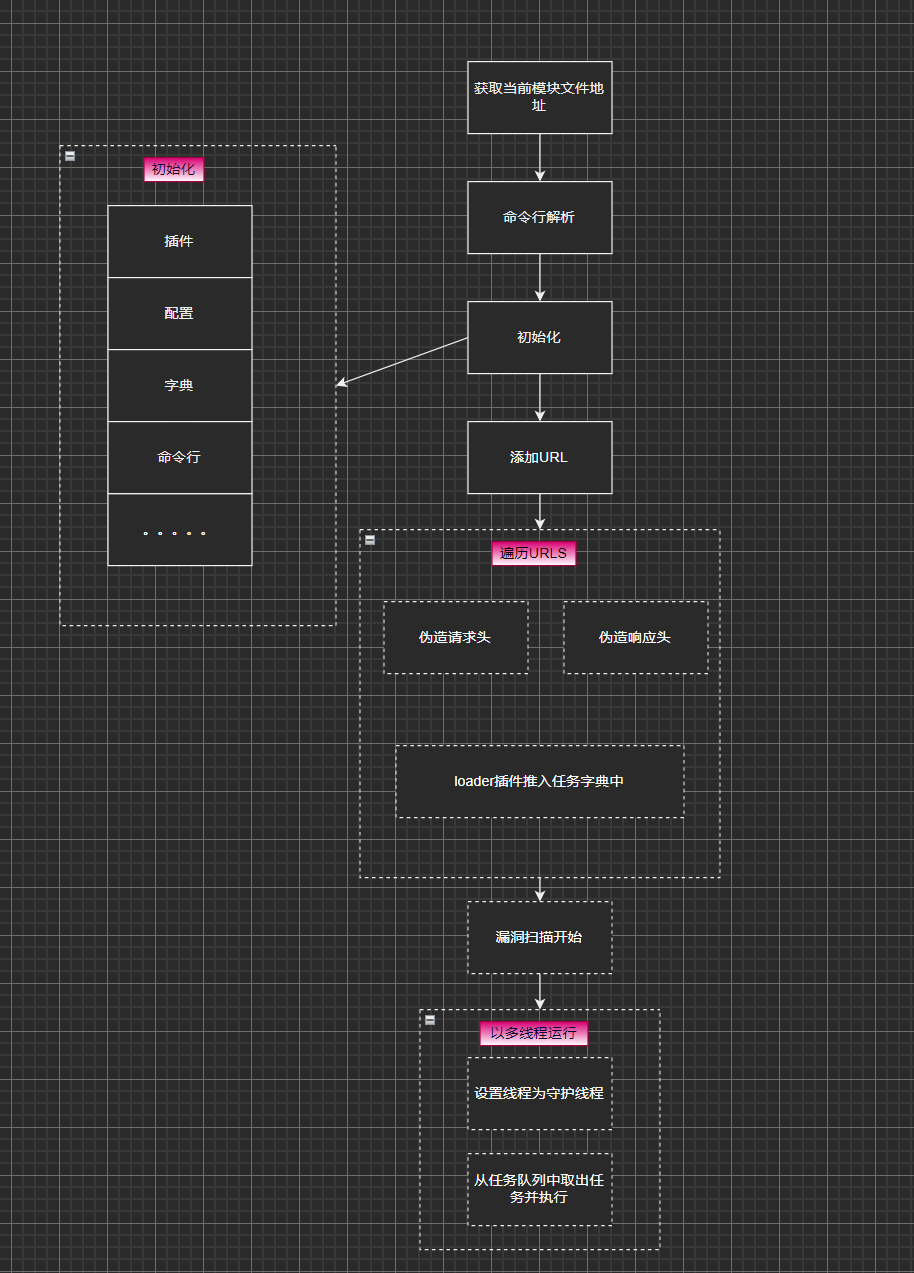
插件初始化
def initPlugins():
# 加载检测插件
for root, dirs, files in os.walk(path.scanners): # 遍历检测插件目录
# 过滤出以.py结尾且不以双下划线开头的文件
files = filter(lambda x: not x.startswith("__") and x.endswith(".py"), files)
for _ in files:
q = os.path.splitext(_)[0] # 获取文件名(不含扩展名)
if conf.able and q not in conf.able and q != 'loader': # 检查是否在允许列表中
continue
if conf.disable and q in conf.disable: # 检查是否在禁止列表中
continue
filename = os.path.join(root, _) # 构建完整路径
mod = load_file_to_module(filename) # 加载模块
try:
mod = mod.W13SCAN() # 获取插件对象
mod.checkImplemennted() # 检查插件是否实现了指定方法
plugin = os.path.splitext(_)[0] # 获取插件名
plugin_type = os.path.split(root)[1] # 获取插件类型
relative_path = ltrim(filename, path.root) # 计算相对路径
if getattr(mod, 'type', None) is None: # 如果插件对象没有 type 属性,则设置插件类型
setattr(mod, 'type', plugin_type)
if getattr(mod, 'path', None) is None: # 如果插件对象没有 path 属性,则设置相对路径
setattr(mod, 'path', relative_path)
KB["registered"][plugin] = mod # 将插件注册到注册表中
except PluginCheckError as e: # 插件检查异常
logger.error('Not "{}" attribute in the plugin:{}'.format(e, filename))
except AttributeError: # 属性错误
logger.error('Filename:{} not class "{}"'.format(filename, 'W13SCAN'))
logger.info('Load scanner plugins:{}'.format(len(KB["registered"]))) # 记录加载的检测插件数量
# 加载指纹识别插件
num = 0 # 初始化插件计数器
for root, dirs, files in os.walk(path.fingprints): # 遍历指纹识别插件目录
files = filter(lambda x: not x.startswith("__") and x.endswith(".py"), files) # 过滤文件列表
for _ in files:
filename = os.path.join(root, _) # 构建完整路径
if not os.path.exists(filename): # 检查文件是否存在
continue
name = os.path.split(os.path.dirname(filename))[-1] # 获取插件类型名
mod = load_file_to_module(filename) # 加载模块
if not getattr(mod, 'fingerprint'): # 检查模块是否具有 'fingerprint' 属性
logger.error("filename:{} load faild,not function 'fingerprint'".format(filename))
continue
if name not in KB["fingerprint"]: # 如果插件类型名不在指纹识别字典中,则添加
KB["fingerprint"][name] = []
KB["fingerprint"][name].append(mod) # 将插件对象添加到指纹识别列表中
num += 1 # 计数器加一
logger.info('Load fingerprint plugins:{}'.format(num)) # 记录加载的指纹识别插件数量
重点关注
#一行用来加载插件文件并将其转换为模块对象的代码。具体来说,这行代码的作用是动态加载插件文件,将其内容作为一个模块导入到当前程序中。
mod = load_file_to_module(filename) # 加载模块
接受一个文件路径(filename)作为参数,并动态地将这个文件作为一个模块加载。这个函数通常会使用 Python 的内置模块如 imp 或 importlib 来实现动态加载。在许多插件系统中,我们需要在运行时加载并执行插件代码,而不是在程序启动时就全部加载。这个函数实现了这一需求。
举例说明:
filename = 'path/to/example.py'
mod = load_file_to_module(filename) # 动态加载 example.py 并转换为模块对象
# 实例化 W13SCAN 类
plugin_instance = mod.W13SCAN()
# 调用类中的方法
plugin_instance.checkImplemennted()
说明插件文件 example.py 对应的模块对象:
- 插件文件:
example.py是一个插件文件,包含了定义插件行为的代码。 - 模块对象:通过
load_file_to_module('path/to/example.py')动态加载example.py文件,并将其作为模块对象mod导入到当前程序中。 - 访问模块内容:可以通过
mod访问example.py中定义的所有内容。例如,mod.W13SCAN访问example.py中的W13SCAN类。
确保每个插件模块都有明确的类型和路径属性,方便后续管理和使用。其类型为插件所在子目录名称
plugin_type = os.path.split(root)[1] # 获取插件类型
relative_path = ltrim(filename, path.root) # 计算相对路径
if getattr(mod, 'type', None) is None: # 如果插件对象没有 type 属性,则设置插件类型
setattr(mod, 'type', plugin_type)
if getattr(mod, 'path', None) is None: # 如果插件对象没有 path 属性,则设置相对路径
setattr(mod, 'path', relative_path)
KB["registered"][plugin] = mod # 将插件注册到注册表中
initPlugins()举例说明:
例如,如果 path.scanners 目录下的文件结构如下:
path.scanners
│
├── plugin1.py
└── plugin2.py
执行
initPlugins()后,全局注册表KB["registered"]中将包含两个键值对:
plugin1: 对应plugin1.py文件加载的插件对象plugin2: 对应plugin2.py文件加载的插件对象
目前,KB[registered]中存储这所有插件,如:
KB = {
"registered": {
"command_asp_code": W13SCAN(),//type=PerFile
"port_scan": W13SCAN(),//type=1
"sensitive_info": W13SCAN()//type=2
.........
},
"task_queue": Queue()
}
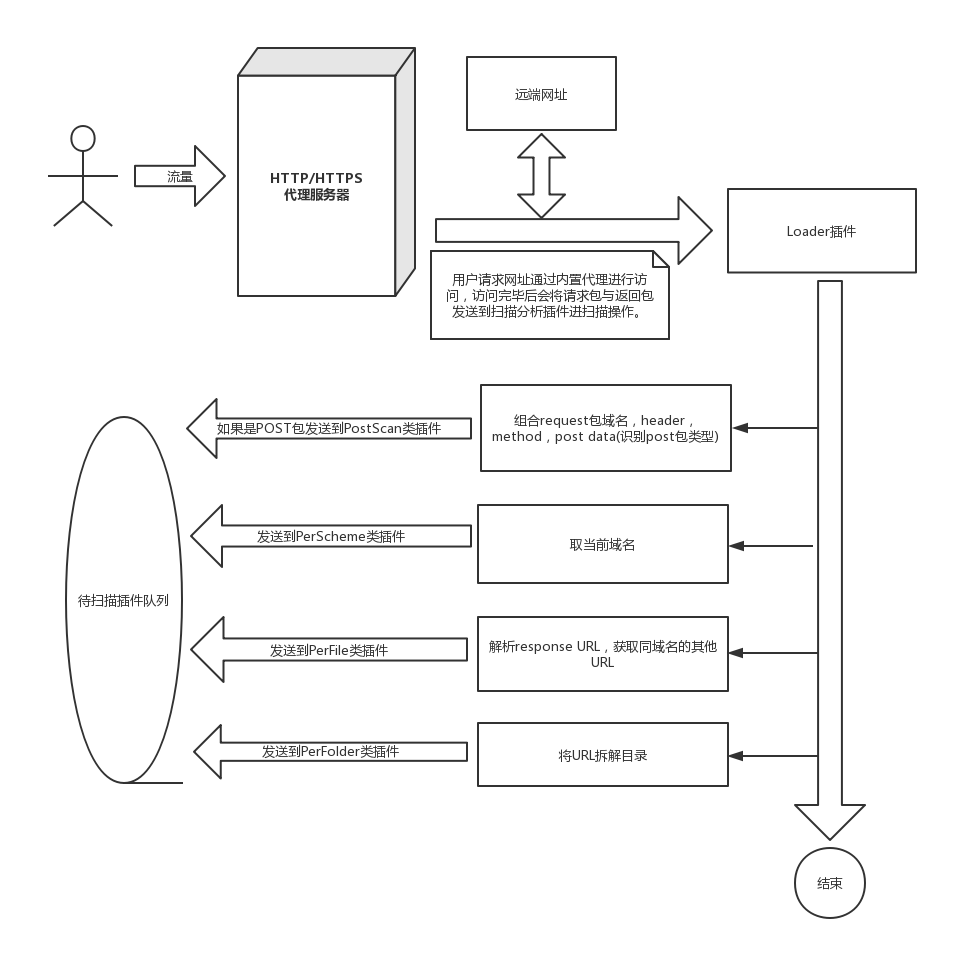
loader插件
主要负责将不同类型的插件推入相应类型的插件队列中
if KB["spiderset"].add(url, 'PerFile'):
task_push('PerFile', self.requests, self.response)
# Send PerServer
p = urlparse(url)
domain = "{}://{}".format(p.scheme, p.netloc)
if KB["spiderset"].add(domain, 'PerServer'):
req = requests.get(domain, headers=headers, allow_redirects=False)
fake_req = FakeReq(domain, headers, HTTPMETHOD.GET, "")
fake_resp = FakeResp(req.status_code, req.content, req.headers)
task_push('PerServer', fake_req, fake_resp)
# Collect directory from response
urls = set(get_parent_paths(url))
for parent_url in urls:
if not KB["spiderset"].add(parent_url, 'get_link_directory'):
continue
req = requests.get(parent_url, headers=headers, allow_redirects=False)
if KB["spiderset"].add(req.url, 'PerFolder'):
fake_req = FakeReq(req.url, headers, HTTPMETHOD.GET, "")
fake_resp = FakeResp(req.status_code, req.content, req.headers)
task_push('PerFolder', fake_req, fake_resp)
任务推送示例
假设我们现在有一个漏洞扫描任务需要推送。漏洞扫描任务的 request 和 response 对象如下:
request = {
"url": "http://example.com",
"method": "GET"
}
response = {
"status_code": 200,
"body": "<html>...</html>"
}
我们调用 task_push 函数,将这个任务推送到漏洞扫描插件:
task_push("PerFile", request, response)
我们调用 task_push 函数,将这个任务推送到漏洞扫描插件:
def task_push(plugin_type, request, response):
for _ in KB["registered"].keys():
module = KB["registered"][_]
if module.type == plugin_type:
KB['task_queue'].put((_, copy.deepcopy(request), copy.deepcopy(response)))
- 遍历
KB["registered"]中的所有插件。 - 对于每个插件,检查其
type属性是否为"PerFile"。 - 如果匹配,将任务(插件名称,请求副本,响应副本)推送到任务队列
KB['task_queue']中。
在这个例子中,只有 command_asp_code 插件的 type 属性为 "PerFile",所以只有它会接收到任务。
结果
任务队列 KB['task_queue'] 中会有一个任务项,如下所示:
# 假设队列的实现是一个简单的列表
KB['task_queue'] = [
("command_asp_code", copy.deepcopy(request), copy.deepcopy(response))
]
其他类型的插件(如 PerServer 和 PerFolder)不会接收到这个任务,因为它们的 type 属性与传入的 plugin_type 不匹配。
通过这种方式,task_push 函数能够根据插件类型准确地分发任务,确保每个任务都由适当的插件来处理。这样设计使得系统具有良好的扩展性和灵活性。
插件的执行
多线程方式任务执行
创建并启动指定数量的线程,并等待所有线程执行完毕。在启动线程时,如果出现异常,会记录错误信息并终止创建线程。在等待线程执行完毕时,每隔0.1秒检查一次线程是否仍在运行,直到所有线程都执行完毕或者捕获到 KeyboardInterrupt 信号时,结束等待。
def run_threads(num_threads, thread_function, args: tuple = ()):
threads = []
try:
info_msg = "Staring [#{0}] threads".format(num_threads)
logger.info(info_msg)
# 启动线程
for num_threads in range(num_threads):
# 创建线程对象
thread = threading.Thread(target=exception_handled_function, name=str(num_threads),
args=(thread_function, args))
thread.setDaemon(True) # 设置为守护线程
try:
thread.start() # 启动线程
except Exception as ex:
err_msg = "error occurred while starting new thread ('{0}')".format(str(ex))
logger.critical(err_msg)
break
threads.append(thread) # 将线程对象添加到列表中
# 等待所有线程执行完毕
alive = True
while alive:
alive = False
for thread in threads:
if thread.is_alive(): # 检查线程是否仍在运行
alive = True
time.sleep(0.1) # 等待0.1秒
except KeyboardInterrupt as ex:
KB['continue'] = False # 捕获到 KeyboardInterrupt 信号,设置 KB['continue'] 为 False
raise
except Exception as ex:
logger.error("thread {0}: {1}".format(threading.currentThread().getName(), str(ex)))
traceback.print_exc() # 打印异常信息
finally:
dataToStdout('\n') # 输出换行符,标识线程执行结束
从任务队列取出任务执行
循环执行任务队列中的任务,直到任务队列为空且 KB[“continue”] 为 False,期间会根据任务的执行情况更新执行计数信息,并在执行过程中保证并发安全。
def task_run():
# 循环执行任务,直到 KB["continue"] 为 False 并且任务队列为空
while KB["continue"] or not KB["task_queue"].empty():
# 从任务队列中获取任务信息
poc_module_name, request, response = KB["task_queue"].get()
# 获取锁,确保多线程环境下的并发安全
KB.lock.acquire()
# 增加正在运行的任务数量
KB.running += 1
# 如果当前模块不在运行中的插件列表中,则将其添加,并初始化计数为 0
if poc_module_name not in KB.running_plugins:
KB.running_plugins[poc_module_name] = 0
KB.running_plugins[poc_module_name] += 1
# 释放锁
KB.lock.release()
# 打印执行进度信息
printProgress()
# 深度拷贝注册表中的插件模块,以避免对原模块的影响
poc_module = copy.deepcopy(KB["registered"][poc_module_name])
# 执行插件模块的 execute 方法,传入请求和响应对象
poc_module.execute(request, response)
# 获取锁,确保并发安全
KB.lock.acquire()
# 完成任务后更新计数信息
KB.finished += 1
KB.running -= 1
KB.running_plugins[poc_module_name] -= 1
# 如果当前模块的运行数量为 0,则从运行中的插件列表中移除
if KB.running_plugins[poc_module_name] == 0:
del KB.running_plugins[poc_module_name]
# 释放锁
KB.lock.release()
# 打印执行进度信息
printProgress()
# 打印最终的执行进度信息
printProgress()
# TODO
# set task delay 设置任务延迟(待实现)
插件基类
class PluginBase(object):
def __init__(self):
self.type = None
self.path = None
self.target = None
self.requests: FakeReq = None
self.response: FakeResp = None
def new_result(self) -> ResultObject:
return ResultObject(self)
def success(self, msg: ResultObject):
if isinstance(msg, ResultObject):
msg = msg.output()
elif isinstance(msg, dict):
pass
else:
raise PluginCheckError('self.success() not ResultObject')
KB.output.success(msg)
def checkImplemennted(self):
name = getattr(self, 'name')
if not name:
raise PluginCheckError('name')
def audit(self):
raise NotImplementedError
def generateItemdatas(self, params=None):
iterdatas = []
if self.requests.method == HTTPMETHOD.GET:
_params = params or self.requests.params
iterdatas.append((_params, PLACE.GET))
elif self.requests.method == HTTPMETHOD.POST:
_params = params or self.requests.post_data
iterdatas.append((_params, PLACE.POST))
if conf.level >= 3:
_params = self.requests.cookies
iterdatas.append((_params, PLACE.COOKIE))
# if conf.level >= 4:
# # for uri
# iterdatas.append((self.requests.url, PLACE.URI))
return iterdatas
def paramsCombination(self, data: dict, place=PLACE.GET, payloads=[], hint=POST_HINT.NORMAL, urlsafe='/\\'):
"""
组合dict参数,将相关类型参数组合成requests认识的,防止request将参数进行url转义
:param data:
:param hint:
:return: payloads -> list
"""
result = []
if place == PLACE.POST:
if hint == POST_HINT.NORMAL:
for key, value in data.items():
new_data = copy.deepcopy(data)
for payload in payloads:
new_data[key] = payload
result.append((key, value, payload, new_data))
elif hint == POST_HINT.JSON:
for payload in payloads:
for new_data in updateJsonObjectFromStr(data, payload):
result.append(('', '', payload, new_data))
elif place == PLACE.GET:
for payload in payloads:
for key in data.keys():
temp = ""
for k, v in data.items():
if k == key:
temp += "{}={}{} ".format(k, quote(payload, safe=urlsafe), DEFAULT_GET_POST_DELIMITER)
else:
temp += "{}={}{} ".format(k, quote(v, safe=urlsafe), DEFAULT_GET_POST_DELIMITER)
temp = temp.rstrip(DEFAULT_GET_POST_DELIMITER)
result.append((key, data[key], payload, temp))
elif place == PLACE.COOKIE:
for payload in payloads:
for key in data.keys():
temp = ""
for k, v in data.items():
if k == key:
temp += "{}={}{}".format(k, quote(payload, safe=urlsafe), DEFAULT_COOKIE_DELIMITER)
else:
temp += "{}={}{}".format(k, quote(v, safe=urlsafe), DEFAULT_COOKIE_DELIMITER)
result.append((key, data[key], payload, temp))
elif place == PLACE.URI:
uris = splitUrlPath(data, flag="<--flag-->")
for payload in payloads:
for uri in uris:
uri = uri.replace("<--flag-->", payload)
result.append(("", "", payload, uri))
return result
def req(self, position, params, headers=None):
r = False
if headers is None:
headers = self.requests.headers
if position == PLACE.GET:
r = requests.get(self.requests.netloc, params=params, headers=headers)
elif position == PLACE.POST:
r = requests.post(self.requests.url, data=params, headers=headers)
elif position == PLACE.COOKIE:
headers = self.requests.headers
if 'Cookie' in headers:
del headers["Cookie"]
if 'cookie' in headers:
del headers["cookie"]
if isinstance(params, dict):
headers["Cookie"] = url_dict2str(params, PLACE.COOKIE)
else:
headers["Cookie"] = params
if self.requests.method == HTTPMETHOD.GET:
r = requests.get(self.requests.url, headers=headers)
elif self.requests.method == HTTPMETHOD.POST:
r = requests.post(self.requests.url, data=self.requests.post_data, headers=headers,
cookies=params)
elif position == PLACE.URI:
r = requests.get(params, headers=self.requests.headers)
return r
def execute(self, request: FakeReq, response: FakeResp):
self.target = ''
self.requests = request
self.response = response
output = None
try:
output = self.audit()
except NotImplementedError:
msg = 'Plugin: {0} not defined "{1} mode'.format(self.name, 'audit')
dataToStdout('\r' + msg + '\n\r')
except (ConnectTimeout, requests.exceptions.ReadTimeout, urllib3.exceptions.ReadTimeoutError, socket.timeout):
retry = conf.retry
while retry > 0:
msg = 'Plugin: {0} timeout, start it over.'.format(self.name)
if conf.debug:
dataToStdout('\r' + msg + '\n\r')
try:
output = self.audit()
break
except (
ConnectTimeout, requests.exceptions.ReadTimeout, urllib3.exceptions.ReadTimeoutError,
socket.timeout):
retry -= 1
except Exception:
return
else:
msg = "connect target '{0}' failed!".format(self.target)
# Share.dataToStdout('\r' + msg + '\n\r')
except HTTPError as e:
msg = 'Plugin: {0} HTTPError occurs, start it over.'.format(self.name)
# Share.dataToStdout('\r' + msg + '\n\r')
except ConnectionError:
msg = "connect target '{0}' failed!".format(self.target)
# Share.dataToStdout('\r' + msg + '\n\r')
except requests.exceptions.ChunkedEncodingError:
pass
except ConnectionResetError:
pass
except TooManyRedirects as e:
pass
except NewConnectionError as ex:
pass
except PoolError as ex:
pass
except UnicodeDecodeError:
# 这是由于request redirect没有处理编码问题,导致一些网站编码转换被报错,又不能hook其中的关键函数
# 暂时先pass这个错误
# refer:https://github.com/boy-hack/w13scan/labels/Requests%20UnicodeDecodeError
pass
except UnicodeError:
# https://github.com/w-digital-scanner/w13scan/issues/238
# bypass unicode奇葩错误
pass
except (
requests.exceptions.InvalidURL, requests.exceptions.InvalidSchema,
requests.exceptions.ContentDecodingError):
# 出现在跳转上的一个奇葩错误,一些网站会在收到敏感操作后跳转到不符合规范的网址,request跟进时就会抛出这个异常
# refer: https://github.com/boy-hack/w13scan/labels/requests.exceptions.InvalidURL
# 奇葩的ContentDecodingError
# refer:https://github.com/boy-hack/w13scan/issues?q=label%3Arequests.exceptions.ContentDecodingError
pass
except KeyboardInterrupt:
raise
except Exception:
errMsg = "W13scan plugin traceback:\n"
errMsg += "Running version: {}\n".format(VERSION)
errMsg += "Python version: {}\n".format(sys.version.split()[0])
errMsg += "Operating system: {}\n".format(platform.platform())
if request:
errMsg += '\n\nrequest raw:\n'
errMsg += request.raw
excMsg = traceback.format_exc()
dataToStdout('\r' + errMsg + '\n\r')
dataToStdout('\r' + excMsg + '\n\r')
if createGithubIssue(errMsg, excMsg):
dataToStdout('\r' + "[x] a issue has reported" + '\n\r')
return output
其中execute方法用于执行插件的 audit 方法,处理了各种可能出现的异常情况,并根据不同的异常类型采取相应的处理措施。而 audit 方法是一个抽象方法,没有具体的实现。在实际使用中,需要在插件类的子类中重写这个方法,给出具体的逻辑实现。
.version.split()[0])
errMsg += “Operating system: {}\n”.format(platform.platform())
if request:
errMsg += ‘\n\nrequest raw:\n’
errMsg += request.raw
excMsg = traceback.format_exc()
dataToStdout(‘\r’ + errMsg + ‘\n\r’)
dataToStdout(‘\r’ + excMsg + ‘\n\r’)
if createGithubIssue(errMsg, excMsg):
dataToStdout(‘\r’ + “[x] a issue has reported” + ‘\n\r’)
return output
其中execute方法用于执行插件的 audit 方法,处理了各种可能出现的异常情况,并根据不同的异常类型采取相应的处理措施。而 audit 方法是一个抽象方法,没有具体的实现。在实际使用中,需要在插件类的子类中重写这个方法,给出具体的逻辑实现。
------















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









