







webbench压测源码分析
Webbench是知名的网站压力测试工具,它是由Lionbridge公司开发。Web Bench 是用于对 WWW 或代理服务器进行基准测试的非常简单的工具。使用 fork() 模拟多个客户端,可以使用 HTTP/0.9-HTTP/1.1 请求。这个基准测试不是很现实,但它可以测试您的 HTTPD 是否真的可以一次处理那么多客户端(尝试运行一些 CGI)而无需关闭您的机器。
Webbench源码代码量虽小(500行左右),但麻雀虽小五脏俱全。这其中包含了LInux下的网络Socket编程,HTTP报文,进程通信的信号与管道等系统编程知识,对于正在学习Linux环境下服务器编程的学习者来说可以是很好的入门源码分析对象。本文只起到抛砖引玉的作用。
基础知识
Linux网络编程基本流程
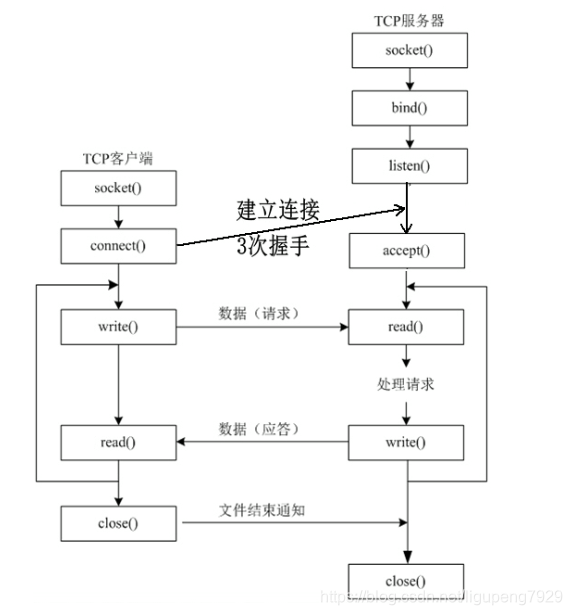
套接字地址结构体
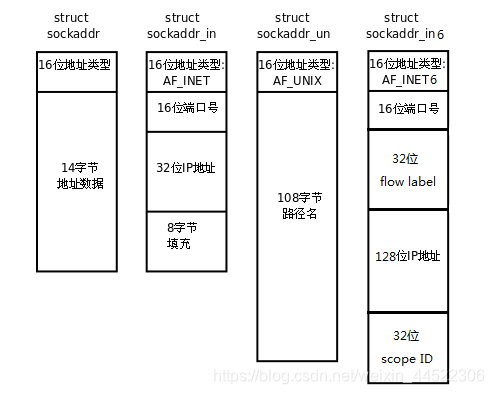
在Linux下进行套接字(Socket)编程时,主要涉及以下几个结构体:
-
struct sockaddr:
- 用于表示通用的套接字地址结构体。
- 包含地址族(address family)和地址数据等信息。
-
struct sockaddr_in:
- 用于表示 IPv4 的套接字地址结构体。
- 是在
netinet/in.h头文件中定义的,常用于 IPv4 套接字编程。 - 包含了 IPv4 的地址和端口等信息。
-
struct sockaddr_in6:
- 用于表示 IPv6 的套接字地址结构体。
- 是在
netinet/in.h头文件中定义的,用于 IPv6 套接字编程。 - 包含了 IPv6 的地址和端口等信息。
-
sockaddr_un是用于 Unix 域套接字(Unix Domain Socket)的结构体,用于表示 Unix 域套接字的地址信息。在 Linux 系统中,Unix 域套接字是一种特殊的套接字类型,用于在同一台主机上的进程间通信,而不需要经过网络协议栈。struct sockaddr_un { sa_family_t sun_family; // 地址族,通常设置为 AF_UNIX char sun_path[UNIX_PATH_MAX]; // 套接字路径名,UNIX_PATH_MAX 是路径名的最大长度限制 };sa_family_t是用于表示套接字地址族(Address Family)的数据类型,通常是一个无符号整数类型。在套接字编程中,地址族用于指定套接字的类型或协议族。常见的地址族包括:AF_INET:IPv4 地址族,用于 Internet 套接字。AF_INET6:IPv6 地址族,用于 Internet 套接字。AF_UNIX:Unix 域地址族,用于本地进程间通信的 Unix 域套接字。AF_PACKET:用于原始套接字的地址族,可用于发送和接收数据帧。Socket函数
Socket函数
该函数的作用是根据指定的主机名和端口号创建一个 TCP 套接字,并尝试连接到指定的主机和端口。
int Socket(const char *host, int clientPort)
{
int sock; // 定义套接字描述符
unsigned long inaddr; // 存储主机地址
struct sockaddr_in ad; // 定义套接字地址结构体
struct hostent *hp; // 存储主机信息
memset(&ad, 0, sizeof(ad)); // 初始化套接字地址结构体为零
ad.sin_family = AF_INET; // 设置地址族为 IPv4
inaddr = inet_addr(host); // 将主机名转换为网络字节序的 IP 地址
if (inaddr != INADDR_NONE)
memcpy(&ad.sin_addr, &inaddr, sizeof(inaddr)); // 如果转换成功,则将地址复制到地址结构体中
else
{
hp = gethostbyname(host); // 如果转换失败,则获取主机信息
if (hp == NULL)
return -1; // 如果获取失败,则返回错误码 -1
memcpy(&ad.sin_addr, hp->h_addr, hp->h_length); // 将获取到的地址复制到地址结构体中
}
ad.sin_port = htons(clientPort); // 将客户端端口号转换为网络字节序,并存储在地址结构体中
sock = socket(AF_INET, SOCK_STREAM, 0); // 创建一个 TCP 套接字
if (sock < 0)
return sock; // 如果创建失败,则返回错误码
if (connect(sock, (struct sockaddr *)&ad, sizeof(ad)) < 0)
return -1; // 尝试连接到指定主机和端口,如果失败则返回错误码 -1
return sock; // 如果连接成功,则返回套接字描述符
}
注意:
在这里使用memcpy而不是=的目的是将
inaddr中的内容复制到ad.sin_addr中。尽管inaddr和ad.sin_addr都是unsigned long类型的变量,但它们可能在内存中的存储方式或大小端字节序上有所不同。
memcpy函数可以确保在不同类型之间进行字节级别的拷贝,而不受内存布局或字节序的影响。这样可以确保在复制数据时保持数据的准确性和完整性。另外,
inaddr可能是在host为点分十进制 IP 地址时使用inet_addr函数转换的,而ad.sin_addr是struct sockaddr_in结构体中的字段,直接赋值可能会导致类型不匹配或数据不一致的问题,因此使用memcpy更为安全和可靠。
webbench主函数
HTTP基础知识
HTTP请求报文结构

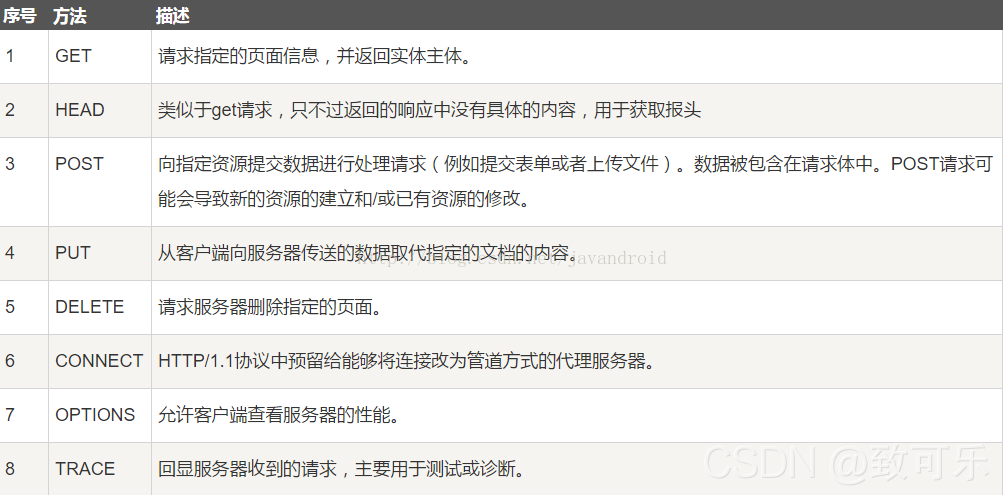
HTTP GET和POST方法之间的区别
- GET 方法:
- 用于请求从服务器获取数据。
- 参数在 URL 中传递,通过查询字符串(Query String)的形式附加在 URL 后面。
- GET 请求可以被缓存,可以被书签收藏,并且可以被历史记录保存。
- GET 请求的长度有限制,因为参数会附加在 URL 上,因此可能受到 URL 长度限制的影响。
- 不安全敏感的数据(如密码)不应该通过 GET 请求发送,因为它们会显示在 URL 中,可能被截获或泄露。
- POST 方法:
- 用于向服务器提交数据,通常用于提交表单数据。
- 参数在请求体中传递,而不是在 URL 中。因此,POST 请求可以发送大量数据,并且不受 URL 长度限制。
- POST 请求不会被缓存,不会被保存在历史记录中。
- POST 请求在用户交互后可能会显示一个警告对话框,提示用户是否要重新发送数据。
- POST 请求更安全,适合发送敏感信息,因为参数不会显示在 URL 中。
总的来说,GET 方法用于获取数据,通常是读取操作;而 POST 方法用于提交数据,通常是写入操作。
HTTP请求方法
HTTP响应报文结构

构造请求报文
这段代码主要是根据传入的URL和其他参数构建一个HTTP请求字符串,其中包括请求方法、协议版本、主机名、端口号等信息。根据不同的情况,拼接不同的信息到请求字符串中。
void build_request(const char *url)
{
char tmp[10]; // 临时存储的字符数组
int i; // 用于循环计数的变量
bzero(host,MAXHOSTNAMELEN); // 清空host数组
bzero(request,REQUEST_SIZE); // 清空request数组
if(force_reload && proxyhost!=NULL && http10<1) http10=1;
if(method==METHOD_HEAD && http10<1) http10=1;
if(method==METHOD_OPTIONS && http10<2) http10=2;
if(method==METHOD_TRACE && http10<2) http10=2;
switch(method) // 根据请求方法类型选择相应的字符串
{
default:
case METHOD_GET: strcpy(request,"GET");break; // GET请求
case METHOD_HEAD: strcpy(request,"HEAD");break; // HEAD请求
case METHOD_OPTIONS: strcpy(request,"OPTIONS");break; // OPTIONS请求
case METHOD_TRACE: strcpy(request,"TRACE");break; // TRACE请求
}
strcat(request," "); // 在请求字符串后面拼接空格
if(NULL==strstr(url,"://")) // 检查URL是否包含"://"
{
fprintf(stderr, "\n%s: is not a valid URL.\n",url); // 输出错误信息
exit(2); // 退出程序
}
if(strlen(url)>1500) // 检查URL长度是否超过1500
{
fprintf(stderr,"URL is too long.\n"); // 输出错误信息
exit(2); // 退出程序
}
if(proxyhost==NULL) // 如果没有设置代理
if (0!=strncasecmp("http://",url,7)) // 如果URL不以"http://"开头
{ fprintf(stderr,"\nOnly HTTP protocol is directly supported, set --proxy for others.\n"); // 输出错误信息
exit(2); // 退出程序
}
/* protocol/host delimiter */
i=strstr(url,"://")-url+3; // 获取协议和主机名的分隔位置
if(strchr(url+i,'/')==NULL) { // 检查URL是否包含'/'
fprintf(stderr,"\nInvalid URL syntax - hostname don't ends with '/'.\n"); // 输出错误信息
exit(2); // 退出程序
}
if(proxyhost==NULL) // 如果没有设置代理
{
/* get port from hostname */
if(index(url+i,':')!=NULL && // 如果URL包含端口号
index(url+i,':')<index(url+i,'/'))
{
strncpy(host,url+i,strchr(url+i,':')-url-i); // 获取主机名
bzero(tmp,10); // 清空临时数组
strncpy(tmp,index(url+i,':')+1,strchr(url+i,'/')-index(url+i,':')-1); // 获取端口号
proxyport=atoi(tmp); // 将端口号转换为整数
if(proxyport==0) proxyport=80; // 如果端口号为0,默认设为80
} else
{
strncpy(host,url+i,strcspn(url+i,"/")); // 获取主机名
}
strcat(request+strlen(request),url+i+strcspn(url+i,"/")); // 拼接请求字符串
} else
{
strcat(request,url); // 如果设置了代理,直接将URL拼接到请求字符串中
}
if(http10==1)
strcat(request," HTTP/1.0"); // 如果是HTTP/1.0版本,拼接到请求字符串中
else if (http10==2)
strcat(request," HTTP/1.1"); // 如果是HTTP/1.1版本,拼接到请求字符串中
strcat(request,"\r\n"); // 拼接回车换行符
if(http10>0)
strcat(request,"User-Agent: WebBench "PROGRAM_VERSION"\r\n"); // 拼接用户代理信息
if(proxyhost==NULL && http10>0)
{
strcat(request,"Host: "); // 拼接主机名
strcat(request,host);
strcat(request,"\r\n");
}
if(force_reload && proxyhost!=NULL)
{
strcat(request,"Pragma: no-cache\r\n"); // 拼接Pragma信息
}
if(http10>1)
strcat(request,"Connection: close\r\n"); // 如果是HTTP/1.1,拼接Connection信息
/* add empty line at end */
if(http10>0) strcat(request,"\r\n"); // 拼接最后的空行
// printf("Req=%s\n",request); // 打印请求字符串
}
进程通信基础知识
这一部分其实需要了解一定的操作系统知识,这里只是简单的阐述一些webbench源码中的关键点。
具体参考:
[进程的基本属性|父子进程关系](【Linux】进程的基本属性|父子进程关系-阿里云开发者社区 (aliyun.com))
以fork()为例详解进程的创建过程与父子进程关系
父子进程
在 Unix 和 Linux中,每个进程都有一个唯一的进程标识符(PID),以及一个父进程标识符(PPID),这两个值使得子进程能够知道它们的父进程是什么。
- PID(Process ID):这是操作系统分配给每个进程的唯一标识符。每个进程都有一个唯一的 PID。
- PPID(Parent Process ID):这是进程的父进程的 PID。PPID 指示了哪个进程创建了当前进程。
当进程 A 调用 fork() 时,会创建一个子进程 B。对于子进程 B,它的 PPID 会被设置为进程 A 的 PID。
Process A: PID = 12345
Parent process: PID = 12345, Child PID = 12346
Child process: PID = 12346, PPID = 12345
同时父进程会获得一个非零的PID(子进程的PID),而子进程会获得0作为返回值。这使得我们可以通过检查返回值的大小来区分父子进程
注意这里的返回0并不是将子进程PID设为0,而是出于以下方面考虑:
-
区分父进程和子进程的执行流
当调用
fork()时,会创建一个新的子进程。fork()在父进程中返回子进程的 PID,而在子进程中返回 0。这种设计让同一段代码能够在两个不同的进程中执行不同的逻辑。 -
简化错误处理
如果
fork()返回一个负值(通常是 -1),这表明进程创建失败。父进程可以立即检查这个返回值并进行相应的错误处理。 -
方便进程间通信和同步
由于
fork()在子进程中返回 0,父进程可以使用返回的子进程 PID 来进行进程间的通信和同步操作。例如,父进程可以等待子进程结束,或者通过信号与子进程进行通信。 -
实现多进程并发
fork()机制使得多进程并发编程变得简单。父进程可以连续调用fork()多次,创建多个子进程来处理不同的任务或相同任务的不同部分,从而实现并发处理。
信号机制
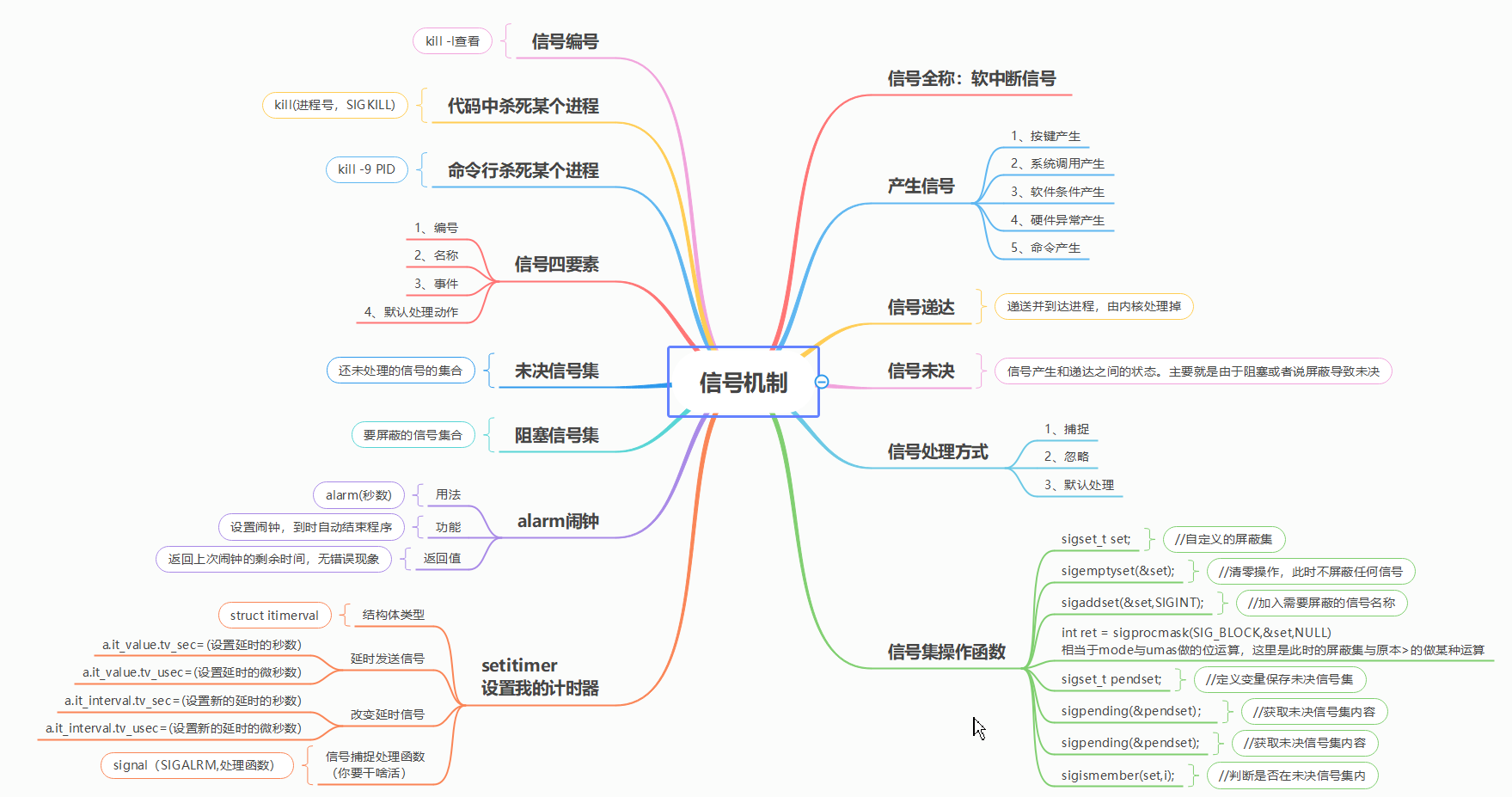
信号:信号是 Linux 进程间通信的一种简单机制。它是由操作系统或进程向另一个进程发送的软件中断,用于通知进程发生了某种事件。
信号处理程序:每个信号都与一个信号处理程序相关联,用于在收到信号时执行特定的操作。信号处理程序可以是预定义的函数,也可以是用户自定义的函数。
信号的发送和接收:信号可以由内核、其他进程或进程自身发送。接收信号的进程可以选择忽略信号、执行默认操作或安装自定义的信号处理程序。
常见的信号:Linux 系统定义了许多标准信号,如 SIGALRM(定时器到期)、SIGINT(终端中断)、SIGKILL(强制终止进程)等。
信号的处理方式:每个进程都有一个信号处理表,记录了每个信号的处理方式。可以通过
sigaction()函数来修改信号处理方式。信号的异步性:信号是异步事件,即进程可能在任何时刻接收到信号,而不一定是在某个特定的程序点。因此,编写信号处理程序时需要注意处理信号的竞态条件和可重入性。
使用Linux信号机制具体步骤:
- 定义信号处理程序:编写一个函数来处理特定的信号。
- 注册信号处理程序:使用
signal()或sigaction()函数将信号处理程序与特定的信号关联起来。 - 触发信号:通过特定的操作或系统调用触发信号,或使用
kill()函数向自己或其他进程发送信号。
代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
// 定义信号处理程序
void signal_handler(int sig) {
if (sig == SIGINT) {
printf("Received SIGINT (Ctrl+C). Exiting gracefully...\n");
exit(0);
} else if (sig == SIGALRM) {
printf("Received SIGALRM. Performing scheduled task...\n");
// 在这里执行你需要的操作
} else {
printf("Received signal %d\n", sig);
}
}
int main() {
// 注册信号处理程序
struct sigaction sa;
sa.sa_handler = signal_handler;
sa.sa_flags = 0;
sigemptyset(&sa.sa_mask);
if (sigaction(SIGINT, &sa, NULL) == -1) {
perror("Error registering SIGINT handler");
exit(1);
}
if (sigaction(SIGALRM, &sa, NULL) == -1) {
perror("Error registering SIGALRM handler");
exit(1);
}
// 设置一个定时器,5秒后发送 SIGALRM 信号
alarm(5);
// 无限循环,等待信号
while (1) {
printf("Waiting for signals...\n");
sleep(1);
}
return 0;
}
管道机制
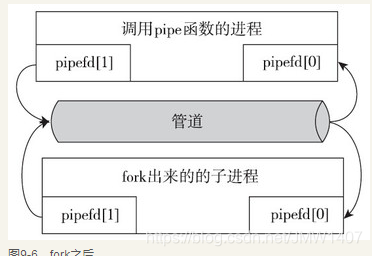
Linux的管道机制允许一个进程的输出直接作为另一个进程的输入,从而实现进程间的通信(IPC)。管道有两种:无名管道和命名管道(FIFO)。无名管道通常用于具有亲缘关系的进程之间的通信(如父子进程),而命名管道可以用于任意两个进程之间的通信。
管道的工作原理
管道在内核中创建一个缓冲区,一个进程可以向缓冲区写入数据,另一个进程可以从缓冲区读取数据。管道是单向的,即数据只能单方向流动。
管道通信与共享内存通信有何区别?
管道通信适用于有亲缘关系的进程,适合简单的数据传输;而共享内存通信适用于无亲缘关系的进程,适合大量数据共享和对性能要求较高的场景
管道通信:
-
- 管道是一种半双工的通信机制,只能在具有亲缘关系的进程之间使用(例如父子进程)。
- 管道是基于 I/O 流的通信方式,数据写入管道的一端,从另一端读出。
- 管道通信是通过操作系统提供的管道文件进行的,可以是匿名管道(只存在于进程间)或命名管道(存在于文件系统中)。
- 管道通信适用于需要在两个相关进程之间进行简单数据传输的场景。
- 共享内存通信:
- 共享内存是一种进程间通信的机制,可以在无亲缘关系的进程之间使用。
- 共享内存允许多个进程访问同一块物理内存空间,因此可以实现高效的数据共享。
- 共享内存通信需要使用操作系统提供的共享内存 API,通过映射共享内存区域来实现进程间数据共享。
- 共享内存通信适用于需要大量数据交换且对性能要求较高的场景,因为它避免了数据复制的开销。
使用管道的步骤
- 创建管道:使用
pipe()系统调用创建一个无名管道。 - 创建子进程:使用
fork()创建子进程。 - 重定向输入/输出:使用
dup2()将管道的读或写端重定向到标准输入或标准输出。 - 关闭不需要的管道端:父进程和子进程都要关闭各自不需要使用的管道端。
- 执行程序:使用
execlp()或其他exec函数执行新程序。
代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main() {
int pipe_fd[2];
pid_t pid;
char buf[1024];
const char *msg = "Hello from parent process!";
// 创建管道
if (pipe(pipe_fd) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
// 创建子进程
pid = fork();
if (pid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
if (pid == 0) { // 子进程
close(pipe_fd[1]); // 关闭写端
// 读取管道
ssize_t nbytes = read(pipe_fd[0], buf, sizeof(buf));
if (nbytes == -1) {
perror("read");
exit(EXIT_FAILURE);
}
// 打印读取到的消息
buf[nbytes] = '\0';
printf("Child received message: %s\n", buf);
close(pipe_fd[0]); // 关闭读端
exit(EXIT_SUCCESS);
} else { // 父进程
close(pipe_fd[0]); // 关闭读端
// 写入管道
if (write(pipe_fd[1], msg, strlen(msg)) == -1) {
perror("write");
exit(EXIT_FAILURE);
}
close(pipe_fd[1]); // 关闭写端
wait(NULL); // 等待子进程结束
exit(EXIT_SUCCESS);
}
}
其中pipe() 创建一个无名管道,pipe_fd 是一个包含两个文件描述符的数组,pipe_fd[0] 是读端,pipe_fd[1] 是写端。
在这个示例中没有使用 dup2() 重定向输入/输出,而是直接使用文件描述符进行读写。你也可以通过 dup2(pipe_fd[0], STDIN_FILENO) 或 dup2(pipe_fd[1], STDOUT_FILENO) 来重定向标准输入/输出。
注意:当父进程fork()出子进程时,子进程会继承父进程的文件描述符。因此,子进程可以直接使用这些继承而来的文件描述符来读取或写入数据,从而与父进程进行通信。而无需使用dup2()来重定向输入/输出。
将管道的读端重定向到标准输入或将管道的写端重定向到标准输出是实现进程间通信的一种常见方式。这种方法可以实现多个进程之间的数据传输,而无需使用临时文件进行交换。
例如,如果一个进程需要从另一个进程中读取数据,可以通过将管道的读端重定向到标准输入来实现。这样,另一个进程输出的数据就会被发送到管道中,而第一个进程可以通过标准输入读取这些数据。
这种方法的好处在于,它提供了一种简单而高效的方式让不同的进程之间进行数据交换,而不需要创建临时文件或者复杂的通信协议。这对于实现诸如管道、重定向、过滤器等功能非常有用,同时也能够方便地实现进程间的通信和协作。
网络压力测试函数
void benchcore(const char *host, const int port, const char *req)
{
int rlen;
char buf[1500];
int s, i;
struct sigaction sa;
/* 设置闹钟信号处理器 */
sa.sa_handler = alarm_handler;
sa.sa_flags = 0;
if (sigaction(SIGALRM, &sa, NULL))
exit(3);
alarm(benchtime);
rlen = strlen(req); // 计算请求字符串的长度
nexttry:
while (1)
{
if (timerexpired)
{
if (failed > 0)
{
/* 通过信号纠正失败次数 */
failed--;
}
return;
}
// 建立与主机的连接
s = Socket(host, port);
if (s < 0)
{
failed++;
continue;
}
// 发送请求到服务器
if (rlen != write(s, req, rlen))
{
failed++;
close(s);
continue;
}
// 如果使用 HTTP/1.0,关闭写入端
if (http10 == 0)
{
if (shutdown(s, 1))
{
failed++;
close(s);
continue;
}
}
// 如果不强制关闭连接,读取服务器的响应数据
if (force == 0)
{
/* 从套接字中读取所有可用的数据 */
while (1)
{
if (timerexpired)
break;
i = read(s, buf, 1500);
/* 检查读取结果 */
if (i < 0)
{
failed++;
close(s);
goto nexttry;
}
else if (i == 0)
{
break;
}
else
{
bytes += i; // 记录读取的字节数
}
}
}
// 关闭套接字连接
if (close(s))
{
failed++;
continue;
}
speed++; // 成功请求次数计数
}
}
benchcore 函数的主要作用是对指定的主机和端口发送 HTTP 请求,并记录响应数据以进行性能测试。这是一个典型的网络压力测试函数。具体步骤如下:
- 设置信号处理器:
- 使用
sigaction设置闹钟信号处理器alarm_handler,并启动定时器alarm(benchtime)来控制测试时间。
- 使用
- 循环发送请求并处理响应:
- 在
while循环中不断向服务器发送请求,直到定时器到期 (timerexpired为true)。 - 调用
Socket函数建立与服务器的连接,若连接失败,增加failed计数并继续下一次尝试。 - 使用
write将请求发送到服务器,如果写入失败,增加failed计数并关闭套接字,继续下一次尝试。 - 如果使用 HTTP/1.0 协议,通过
shutdown关闭写入端。 - 如果
force为0,则读取服务器的响应数据并累计读取的字节数bytes。 - 关闭套接字连接,若关闭失败,增加
failed计数并继续下一次尝试。 - 每次成功处理一个请求后,增加
speed计数。
- 在
通过这个函数,可以对服务器进行压力测试,统计在指定时间内成功处理的请求数 (speed) 和失败的请求数 (failed),以及累计读取的字节数 (bytes)。
基准测试
bench 函数的主要作用是执行基准测试,通过创建子进程并分发任务来模拟多个客户端对服务器的并发请求,并统计测试结果。具体步骤如下:
- 检查目标服务器的可用性:
- 调用
Socket函数尝试连接目标服务器,若连接失败则终止基准测试。
- 调用
- 创建管道:
- 使用
pipe函数创建一个管道,用于子进程和父进程之间的通信。
- 使用
- 分叉子进程:
- 使用
fork函数创建指定数量的子进程,并在子进程中执行任务。
- 使用
- 子进程执行任务:
- 每个子进程调用
benchcore函数执行基准测试任务,并将结果写入管道。
- 每个子进程调用
- 父进程读取子进程的结果:
- 父进程从管道中读取各个子进程执行任务的结果,并统计总体性能指标。
- 输出测试结果:
- 输出基准测试的结果,包括请求速度、传输速率以及成功和失败的请求数量。
通过这个函数,可以模拟多个并发用户对服务器进行压力测试,并获取测试结果以评估服务器的性能表现。
static int bench(void)
{
int i, j, k;
pid_t pid = 0;
FILE *f;
/* 检查目标服务器的可用性 */
i = Socket(proxyhost == NULL ? host : proxyhost, proxyport);
if (i < 0)
{
fprintf(stderr, "\n连接服务器失败。终止基准测试。\n");
return 1;
}
close(i);
/* 创建管道 */
if (pipe(mypipe))
{
perror("pipe failed.");
return 3;
}
/* 分叉子进程 */
for (i = 0; i < clients; i++)
{
pid = fork();
if (pid <= (pid_t)0)
{
/* 子进程或出错 */
sleep(1); /* 使子进程更快 */
break;
}
}
if (pid < (pid_t)0)
{
fprintf(stderr, "forking worker no. %d 出现问题\n", i);
perror("fork failed.");
return 3;
}
if (pid == (pid_t)0)
{
/* 我是一个子进程 */
if (proxyhost == NULL)
benchcore(host, proxyport, request);
else
benchcore(proxyhost, proxyport, request);
/* 将结果写入管道 */
f = fdopen(mypipe[1], "w");
if (f == NULL)
{
perror("打开管道写入失败。");
return 3;
}
/* fprintf(stderr,"Child - %d %d\n",speed,failed); */
fprintf(f, "%d %d %d\n", speed, failed, bytes);
fclose(f);
return 0;
}
else
{
f = fdopen(mypipe[0], "r");
if (f == NULL)
{
perror("打开管道读取失败。");
return 3;
}
setvbuf(f, NULL, _IONBF, 0);
speed = 0;
failed = 0;
bytes = 0;
while (1)
{
pid = fscanf(f, "%d %d %d", &i, &j, &k);
if (pid < 2)
{
fprintf(stderr, "我们的一些子进程已经退出。\n");
break;
}
speed += i;
failed += j;
bytes += k;
/* fprintf(stderr,"*Knock* %d %d read=%d\n",speed,failed,pid); */
if (--clients == 0)
break;
}
fclose(f);
printf("\n速度=%d 页面/分钟,%d 字节/秒。\n请求数: %d 成功,%d 失败。\n",
(int)((speed + failed) / (benchtime / 60.0f)),
(int)(bytes / (float)benchtime),
speed,
failed);
}
return i;
}
主函数
main 函数是 Webbench 工具的主要入口点,负责解析命令行参数、构建 HTTP 请求、执行基准测试,并输出测试结果。具体步骤如下:
- 解析命令行参数:
- 使用
getopt_long函数解析命令行参数,支持短选项(如-f,-r,-t)和长选项(如--help,--version)。 - 根据解析结果设置相应的全局变量,如
force、force_reload、benchtime等。
- 使用
- 构建 HTTP 请求:
- 调用
build_request函数根据用户提供的 URL 构建相应的 HTTP 请求,包括请求方法、协议版本等信息。
- 调用
- 执行基准测试:
- 调用
bench函数执行基准测试,该函数会模拟多个并发客户端向目标服务器发起请求
- 调用
int main(int argc, char *argv[])
{
int opt = 0;
int options_index = 0;
char *tmp = NULL;
// 如果没有提供任何参数,则显示用法信息并返回
if (argc == 1)
{
usage();
return 2;
}
// 解析命令行参数
while ((opt = getopt_long(argc, argv, "912Vfrt:p:c:?h", long_options, &options_index)) != EOF)
{
switch (opt)
{
case 0:
break;
case 'f':
force = 1;
break;
case 'r':
force_reload = 1;
break;
case '9':
http10 = 0;
break;
case '1':
http10 = 1;
break;
case '2':
http10 = 2;
break;
case 'V':
printf(PROGRAM_VERSION "\n");
exit(0);
case 't':
benchtime = atoi(optarg);
break;
case 'p':
/* 代理服务器解析 server:port */
tmp = strrchr(optarg, ':');
proxyhost = optarg;
if (tmp == NULL)
{
break;
}
if (tmp == optarg)
{
fprintf(stderr, "错误的选项 --proxy %s: 缺少主机名。\n", optarg);
return 2;
}
if (tmp == optarg + strlen(optarg) - 1)
{
fprintf(stderr, "错误的选项 --proxy %s: 缺少端口号。\n", optarg);
return 2;
}
*tmp = '\0';
proxyport = atoi(tmp + 1);
break;
case ':':
case 'h':
case '?':
usage();
return 2;
break;
case 'c':
clients = atoi(optarg);
break;
}
}
// 如果没有提供 URL,则显示错误信息并返回
if (optind == argc)
{
fprintf(stderr, "webbench: 缺少 URL!\n");
usage();
return 2;
}
// 设置默认客户端数量和测试时长
if (clients == 0)
clients = 1;
if (benchtime == 0)
benchtime = 60;
// 版权声明
fprintf(stderr, "Webbench - 简单的 Web 基准测试 " PROGRAM_VERSION "\n"
"版权所有 (C) Radim Kolar 1997-2004, GPL 开源软件。\n");
// 构建 HTTP 请求
build_request(argv[optind]);
// 打印基准测试信息
printf("\n正在进行基准测试: ");
switch (method)
{
case METHOD_GET:
default:
printf("GET");
break;
case METHOD_OPTIONS:
printf("OPTIONS");
break;
case METHOD_HEAD:
printf("HEAD");
break;
case METHOD_TRACE:
printf("TRACE");
break;
}
printf(" %s", argv[optind]);
switch (http10)
{
case 0:
printf(" (使用 HTTP/0.9)");
break;
case 2:
printf(" (使用 HTTP/1.1)");
break;
}
printf("\n");
if (clients == 1)
printf("1 个客户端");
else
printf("%d 个客户端", clients);
printf(", 运行 %d 秒", benchtime);
if (force)
printf(", 提前关闭套接字");
if (proxyhost != NULL)
printf(", 通过代理服务器 %s:%d", proxyhost, proxyport);
if (force_reload)
printf(", 强制重新加载");
printf(".\n");
// 执行基准测试
return bench();
}
完!
printf("GET");
break;
case METHOD_OPTIONS:
printf("OPTIONS");
break;
case METHOD_HEAD:
printf("HEAD");
break;
case METHOD_TRACE:
printf("TRACE");
break;
}
printf(" %s", argv[optind]);
switch (http10)
{
case 0:
printf(" (使用 HTTP/0.9)");
break;
case 2:
printf(" (使用 HTTP/1.1)");
break;
}
printf("\n");
if (clients == 1)
printf("1 个客户端");
else
printf("%d 个客户端", clients);
printf(", 运行 %d 秒", benchtime);
if (force)
printf(", 提前关闭套接字");
if (proxyhost != NULL)
printf(", 通过代理服务器 %s:%d", proxyhost, proxyport);
if (force_reload)
printf(", 强制重新加载");
printf(".\n");
// 执行基准测试
return bench();
}
***完!***
------















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









