






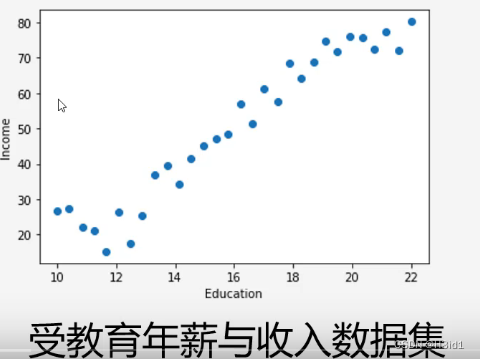
通过一个模型达到输入Education可以预测出Income:
单变量线性回归算法(比如,x代表学历,f(x)代表收入)︰
f(x)= w*x + b
我们使用f(x)这个函数来映射输入特征和输出值,即模型。
损失函数:使用均方差作为作为成本函数,也就是预测值和真实值之间差的平方取均值
优化的目标(y代表实际的收入)∶
找到合适的w和b,使得(f(x) - y)2越小越好。主要:如何求解参数w和b,从而确定该直线是在什么位置。
如何优化:使用梯度下降算法。
画数据的散点图:x轴为Education Y轴为Income
import csv
import torch
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_csv('datasets/Income.csv') #读取CSV文件数据
data #查看读取的数据
data info() #返回读取数据的整体情况
plt.scatter(data.Education, data.Income)#绘制散点图
画数据的折线图:(读完csv中数据后):
一张图中多条折线图:计数、幅值、峰频为输入,绝对能量为输出。
x1data = data.loc[:,'计数' ]#将csv中列名为“ ”的列存入xdata数组中
x2data = data.loc[:,'幅值' ]
x3data = data.loc[:,'峰频' ]
ydata = data.loc[:,'绝对能量']
plt.plot(x1data,ydata,color='r',marker='o',mec='r',mfc='w',label=u'计数')
plt.plot(x2data,ydata,color='b',marker='o',mec='r',mfc='w',label=u'幅值')
plt.plot(x3data,ydata,color='g',marker='o',mec='r',mfc='w',label=u'峰频')
plt.title(u"zhexiantu",size=10) #设置表名为“表名”
plt.legend()
plt.xlabel(u'X轴',size=10) #设置x轴名为“x轴"
plt.ylabel(u'Y轴',size=10) #设置y轴名为“y轴"一张图单条的话则分开即可。
loc函数:通过行索引 "Index" 中的具体值来取行数据
iloc函数:通过行号来取行数据















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









