









RCU机制
RCU(Read-Copy-Update),是Linux内核重要的同步机制。Linux内核有原子操作,读写信号量,为什么要单独设计一个比较复杂的新机制呢?
- spinlock和mutex信号量都使用了原子操作,多CPU在访问共享变量的时候Cache一致性会变得非常糟糕,有时候会使得整个性能下降。
- 允许多个读者存在,但是读和写不能同时存在。
- RCU让读者没有或者让同步开销变得更小,不需要锁和原子操作指令。将需要同步的任务交给写线程,等读者线程读完再更新数据。
- 在RCU机制中如果有多个写的存在,需要额外的保护机制。
原理
RCU记录所有指向共享数据的指针使用者,当要修改共享数据时,首先创建一个副本,在副本中修改。所有读访问线程都离开临界区后,指针指向新的修改后副本的指针,并且删除旧数据。
- 写者修改:首先复制一个副本,然后更新副本,最后使用新对象替换旧对象。
- 写者删除对象:必须等待所有访问被删除对象读者访问结束的时候,才能执行销毁操作实现。
- 优点:RCU优势是读者没有任何同步开销;不需要获取任何锁,不需要执行原子指令。
- 缺点:写者的同步开销比较大,写者需要延迟释放对象、复制被修改的对象,写者之间必须使用锁互斥操作的方法。
用于读者性能要求高的场景。只保护动态分配的数据结构,必须通过指针访问此数据结构;受RCU保护的临界区不能sleep;读写不对成,对写的性能没有要求,但是对读要求高。
应用场景
链表:有效提高遍历读取数据,读取链表成员数据只要rcu_read_lock(),允许多个线程同时读取,允许一个线程同时修改,RCU的意思是读-复制-更新。
static inline void list_add_rcu(struct list_head *new, struct list_head *head)
{
__list_add_rcu(new, head, head->next);
}
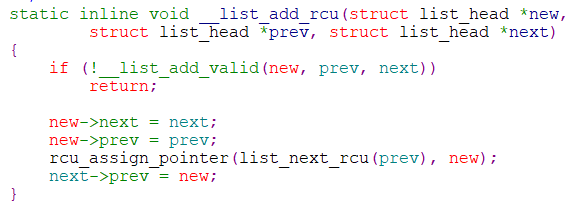
static inline void list_del_rcu(struct list_head *entry)
{
__list_del_entry(entry);
entry->prev = LIST_POISON2;
}

- 替换

在整个操作过程中,要防止编译器和CPU优化代码执行的顺序。smp_wmb()保证在他前两行代码执行完毕再执行后两行。
RCU层次架构
RCU根据CPU数量的大小按照树形结构来组成其层次结构,称为RCU Hierarchy。具体内核源码分析如下:
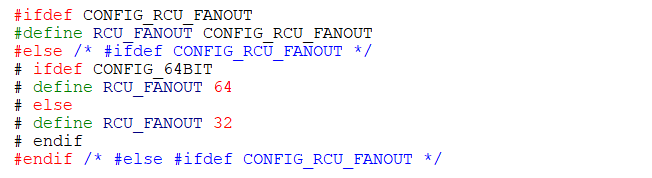
/*
* Define shape of hierarchy based on NR_CPUS, CONFIG_RCU_FANOUT, and
* CONFIG_RCU_FANOUT_LEAF.
* In theory, it should be possible to add more levels straightforwardly.
* In practice, this did work well going from three levels to four.
* Of course, your mileage may vary.
*/
#ifdef CONFIG_RCU_FANOUT
#define RCU_FANOUT CONFIG_RCU_FANOUT
#else /* #ifdef CONFIG_RCU_FANOUT */
# ifdef CONFIG_64BIT
# define RCU_FANOUT 64
# else
# define RCU_FANOUT 32
# endif
#endif /* #else #ifdef CONFIG_RCU_FANOUT */
#ifdef CONFIG_RCU_FANOUT_LEAF
#define RCU_FANOUT_LEAF CONFIG_RCU_FANOUT_LEAF
#else /* #ifdef CONFIG_RCU_FANOUT_LEAF */
#define RCU_FANOUT_LEAF 16
#endif /* #else #ifdef CONFIG_RCU_FANOUT_LEAF */
#define RCU_FANOUT_1 (RCU_FANOUT_LEAF)
#define RCU_FANOUT_2 (RCU_FANOUT_1 * RCU_FANOUT)
#define RCU_FANOUT_3 (RCU_FANOUT_2 * RCU_FANOUT)
#define RCU_FANOUT_4 (RCU_FANOUT_3 * RCU_FANOUT)
RCU层次结构根据CPU熟练决定,内核中有宏帮助构建RCU层次结构,其中
CONFIG_RCU_FANOUT_LEAF表示一个子叶子节点的CPU数量,CONFIG_RCU_FANOUT表示每个层数最多支持多少个叶子数量。
优化内存屏障
优化屏障
在编程的时候,指令一般不按照源程序顺序执行,原因是为了提高程序性能,会对他进行优化,主要分两种:编译器优化和CPU执行优化。优化屏障避免编译的重新排序优化操作,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
- 编译器优化:为提高系统性能,编译器在不影响逻辑的情况下会调整指令的执行顺序。
- CPU执行优化:为提高流水线性能,CPU的乱序执行可能会让后面的寄存器重提的汇编指先于前面指令完成。
Linux使用宏barrier实现优化屏障,如gcc编译器的优化屏障宏定义具体查阅Linux源码如下:
/* Optimization barrier */
/* The "volatile" is due to gcc bugs */
#define barrier() __asm__ __volatile__("": : :"memory")
内存屏障
内存屏障(也称内存栅障或屏障指令等),是一类同步屏障指令,是编译器或CPU对内存访问操作的时候,严格按照一定顺序来执行,也就是memory barrier之前的指令和memory barrier之后的指令不会由于系统优化等原因而导致乱序的。
Linux内核支持三种内存屏障:编译器屏障、处理器屏障、【内存映射I/O写屏障(Memory Mapping I/O,MMIO)。此屏障已废弃新驱动不应该使用】
- 内存屏障是一种保证访问顺序的方法,解决内存屏障内存访问乱序问题:
- 编译器编译代码时可能重新排序汇编指令,使编译出来的程序在处理器上执行速度更快,但是有时候优化的结果可能不符合软件开发工程师的意图。
- 新式处理器采用超标量体系结构和乱序执行技术,能够在一个时钟周期并行执行多条指令。一句话总结为:顺序取指令,乱序执行,顺序提交执行结果。
- 多处理器系统中,硬件工程师使用存储缓冲区、使无效队列协助缓存和缓存一致性协议实现高性能,引入处理器之间的内存访问乱序问题。
- 使用顺序
假使使用禁止内核抢占方法保护临界区:
preempt_desable();
临界区
preempt_enable();
- 为了阻止编译器错误重排指令,在禁止内核抢占和开启内核抢占的里面添加编译器优先屏障,具体如下:
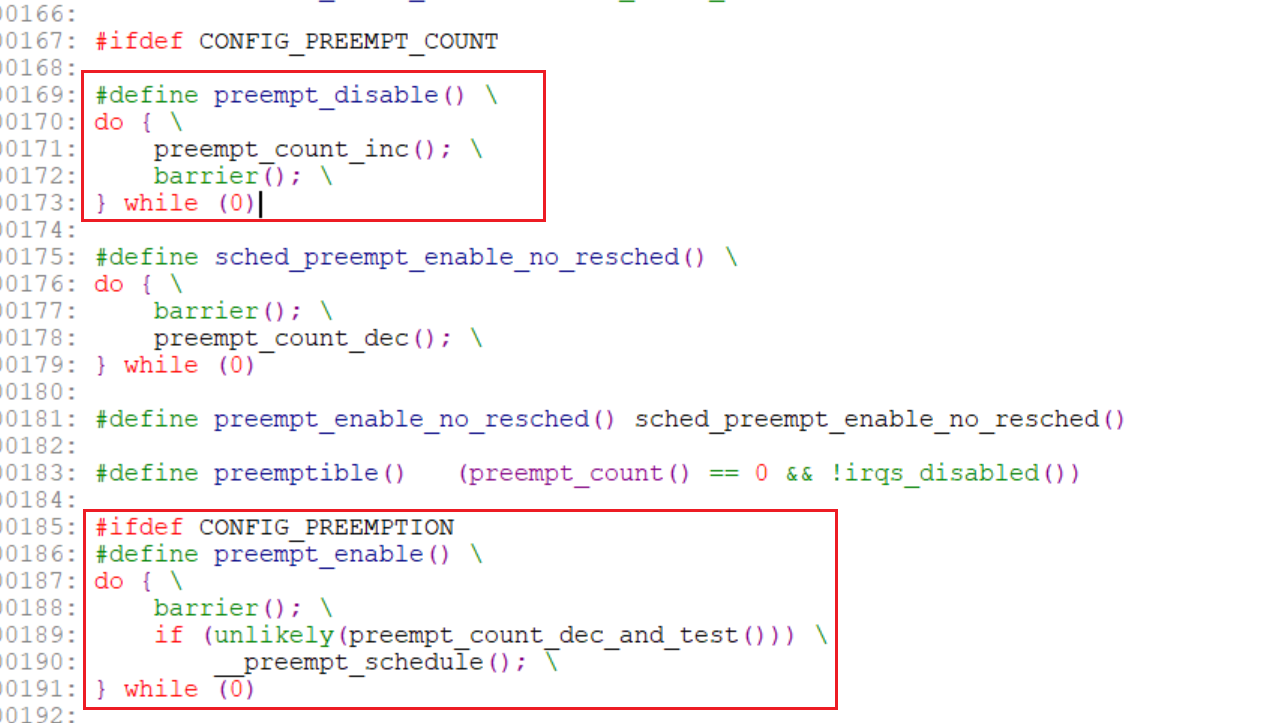
- GCC编译器定义宏
/* Optimization barrier */
/* The "volatile" is due to gcc bugs */
#define barrier() __asm__ __volatile__("": : :"memory")
关键字为__volatile__告诉编译器:禁止优化代码,不需要改变barrier()前面的代码块、barrier()和后面的代码块这三个代码块的顺序。
处理器内存屏障
处理器内存屏障解决CPU之间的内存访问乱序问题和处理器访问外围设备的乱序问题。
| 内存屏障类型 | 强制性的内存屏障 | SMP的内存屏障 |
|---|---|---|
| 通用内存屏障 | mb() | smp_mb() |
| 写内存屏障 | wmb() | smp_wmb() |
| 读内存屏障 | rmb() | smp_rmb() |
| 数据依赖屏障 | read_barrier_depends() | smp_read_barrier_depends() |
- 除了数据依赖屏障之外,所有处理器内存屏障隐含编译器优化屏障。
SMP屏障只有在SMP系统中才有,在单核心处理器中没有SMP屏障。
推荐课程:https://xxetb.xetslk.com/s/3oyV5o















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









