






1.常用数据集
1.1 MNIST
MINIST数据集主要由一些手写数字的图片和对应标签组成,是常用的手写数字识别数据集,图片共有10类,分别对应从0~9;由60000个训练样本和10000个测试样本组成,每个样本都是一张28*28像素的手写灰度数字图片。

1.2 Fashion-MNIST数据集
Fashion-MNIST数据集是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando旗下的研究部门提供,涵盖了来自 10 种类别的共7万个不同商品的正面图片;FashionMNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致,仍为60000/10000 的训练测试数据划分,28x28 的灰度图片。下图是数据集中的类,以及每个类的十个随机图像:

1.3 CIFAR 10数据集
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每 个类有6000个图像。有50000个训练图像和10000个测试图像,数据集分为五个训练批次和一个测试批次,每个批次有10000 个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。以下是数据集中的类,以及来自每个类的10个随机图像:

1.4 PASCAL VOC数据集
PASCAL VOC数据集是目标分类(识别)、检测、分割最常用的数据集之一。该数据集包含了20个不同的类别,包括人、动物、车辆、家具等。每个图像都标注了对象的边界框和类别标签。该数据集通常用于训练和评估目标检测和图像分割模型。
1.5 MS COCO数据集
PASCAL的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集;数据集以scene understanding为目标,主要从复杂的日常场景中截取; 包含目标分类(识别)、检测、分割、语义标注等数据集;ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆;官网:http://cocodataset.org
1.6 ImageNet数据集与ILSVRC
ImageNet数据集始于2009年,李飞飞与Google的合作: “ImageNet: A Large-Scale Hierarchical Image Database”,其中总图像数据:14197122;总类别数:21841;带有标记框的图像数:1034908。
ISLVRC 2012子数据集的训练集:1281167张图片+标签;类别数:1000;验证集:50000张图片+标签;测试集:100000张图片。
2.深度学习视觉应用
2.1 算法评估
TP:被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
FP: 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
TN: 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
P(精确率): 𝑇𝑃/(𝑇𝑃 + 𝐹𝑃),标识“挑剔”的程度
R(召回率): 𝑇𝑃/(𝑇𝑃 + 𝐹𝑁)。召回率越高,准确度越低 标识“通过”的程度
精度(Accuracy): (𝑇𝑃 + 𝑇𝑁)/(𝑇𝑃 + 𝐹𝑃 + 𝑇𝑁 + 𝐹𝑁)
P-R的关系曲线图,表示了召回率和准确率之间的关系,精度(准确率)越高,召回率越低。
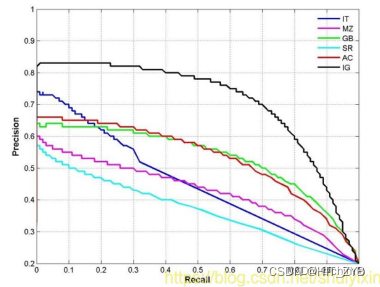
可以通过改变阈值,来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与 Recall值发生变化。
2.2 目标检测与YOLO
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。 物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图 片的任何地方,并且物体还可以是多个类别。
目标检测的基本思路:滑动窗口,两步法:可以确定那些更有可能出现目标的位置,再有针对性的用CNN进 行检测。但是仍存在费时的问题,进一步减少出现目标的位置,而且将目标分类检测和定位问题合在一个网络里——一步法(YOLO)
YOLO,一种实时目标检测算法,由Joseph Redmon等人在2015年提出。YOLO的核心思想是将目标检测任务看作一个回归问题,从而实现了端到端的目标检测,极大地提高了检测速度。















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









