






大家好,今天,我们将深入了解Stable diffusion的文生图功能,让你也能生成满意的图片!
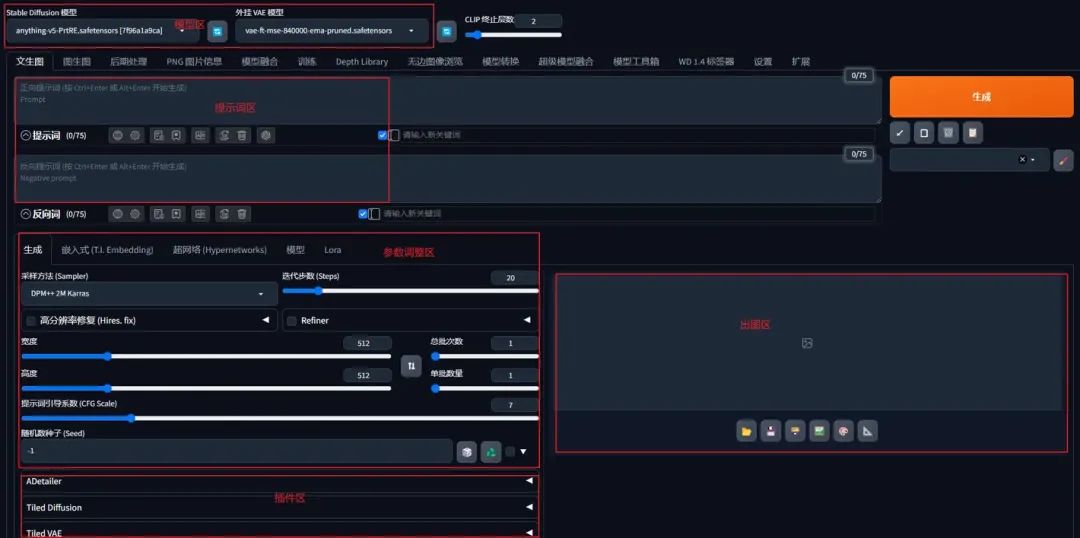
如上图,这是Stable diffusion的文生图界面,这个界面总体可以分为五个区域:
-
模型区:调整/更换模型的地方
-
提示词区:撰写提示词的地方
-
参数调整区:调整模型参数的地方
-
插件区:SD的各种插件
-
出图区:就是展示生成图片的地方
1、模型区
第一个区域是我们的模型区,这块区域可以选择不同的模型,模型决定了我们的出图风格,比如你的大模型是一个二次元模型,那么你最终出图的效果就会倾向于二次元;如果是真实系模型,最终出图就会比较像真人。
像秋叶大佬的整合包自带的 anything-v5-PrtRE 模型,就属于二次元模型,比如你输入提示词 1girl,最终大概率会得到一张二次元的女孩照片。

但SD的模型远比上面讲的要复杂得多,不仅有多种模型后缀,而且还有几种微调模型,如VAE和Lora等,不过别担心,这个我会在下一节进行一个详细说明。
2、提示词区
第二个区域是我们的提示词区,也就是写提示词的地方,提示词在文生图中的重要性不亚于上面提到的模型,准确有效的提示词是出好图的关键。
提示词分为两种,分别是正向提示词和反向提示词,正向提示词就是你想让SD展示的内容,反向提示词就是你不想让SD展示的内容(比如)。
如果你使用的 stable-diffusion-webui,那么在提示词这块可能会有点无从下手,因为需要自己去网上寻找提示词
但如果你用秋叶整合包,这个问题就得到很好的解决,因为它已经事先集成了很多我们常用的提示词,并分类好(这也是我为什么推荐新手小白使用的原因)
提示词这块其实还有复杂的用法,比如通过英文括号() 等控制提示词的权重,这个也不用担心,我后面也会单独出一篇文章进行说明
3、参数调整区
第三个区域是我们的参数调整区,这块的概念相对比较难理解,建议自己多尝试几遍
3.1 采样方法
要理解采样的工作原理,首先要理解Stable diffusion的一个出图原理。Stable diffusion的出图一共分为两步:
第一步是前向扩散,在这一步中,Stable diffusion会在一张图片上逐渐添加噪点,最后完全变成一张类似完全黑白的噪点图像,如下图(好比一滴墨水滴在清水上,然后逐渐扩散的过程)。

第二步可以理解为逆向扩散,在这一步中,Stable diffusion会对这张图片多次去噪,也就是逐步削减图片上噪点,最终变成一张清晰的,基于文本描述生成的图像,如下图
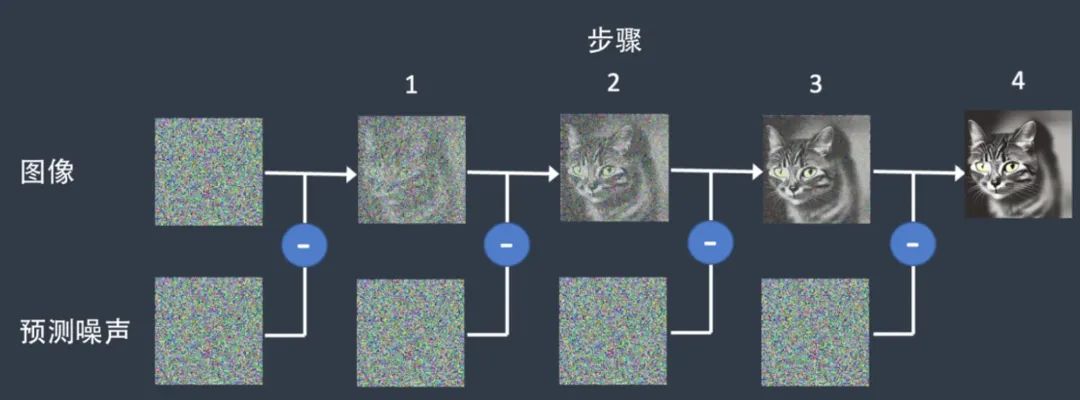
上面第二步中的去噪过程就被称为采样(sampling),这个过程采用的方法也称为采样方法(也可以通俗地将采样方法理解为SD的画图手法)。
说实话采样方法是挺让人困惑的,因为太多了,对于新手而言常常不知道要选哪种比较好!通过阅读一些书籍和网上的文章,我粗略地将其分为下面几类:
-
**1、**老式常微分采样:如 Euler、Henu、LMS,这类采样方法的特点是简单、快速、效果也还OK,基本20-30 steps 就能生成较好的图片
-
2、祖先采样(ancestral sampler):如 Euler a、DPM2 a、DPM++2S a等,这种采样一般名字里都会带有一个“字母a“。祖先采样属于随机采样,意图通过较少的steps 产生多样化的结果,但缺点就是图像不会收敛,也就是随着step的增加,图像并不会趋于稳定,而是多变的,所以如果你想得到稳定、可重现的图像,尽量避免使用祖先采样
-
3、Karras采样:如LMS Karras、DPM2 Karras 等,这种采样方法在开始时图片的噪声会比较多,但后期噪声比较少,有助于图像的质量提升,所以建议steps至少大于15步
-
4、已过时采样:如DDIM和PLMS,网上的说法是这两个采样方法已经过时,简单试了下,效果确实不太行,生成的图片感觉怪怪的
-
5、DPM采样:粗略看了下,DPM家族的采样方法是最多的,从DPM、DPM2、DPM++、DPM++ 2M等。DPM是一种扩散概率模型求解器,DPM2和DPM差不多,但它是二阶的,准确性更高但是速度稍慢;DPM++是对DPM的改进,速度更快,可以用更少的steps实现相同的效果;DPM++ 2M结果与Euler相似,但在速度和质量方面有很好的平衡;DPM fast 是DPM的快速版本,速度更快但牺牲了部分质量;DPM++ SDE使用的是随机微分方程(SDE)求解扩散过程,所以它和祖先采样方法一样是不收敛的。
-
6、UniPC采样:2023年发布的新采样方法,是目前最快最新的采样方法,可以在较少的steps内生成高质量的图片
看了那么多,可能大家还是很迷,这里给下自己用的一些采样方法:
-
如果是想生成简单普通的图片,对效果要求不是非常高,则可以试试老式常微分采样
-
如果是想生成新颖且质量不错的,可以试试DPM++ 2M Karras 和 UniPC
-
如果想得到质量不错,但是不关心图片是否收敛的,可以试试 DPM++ SDE Karras
如果想看不同采样方法下的图片生成对比,可以看看这篇文章[1]:

注:这里只是给出部分对比,完整对比文章有
3.2 迭代步数
迭代步数理解起来比较简单,指的是在生成图片时进行多少次扩散计算,也就是上面去除图片噪声的次数。迭代的步数越多,花费的时间也越长。
然而迭代步数并不是越多越好,跟上面提到的采样方法其实密切相关。比如你想得到一张稳定的图片,但却选择了祖先采样的采样方法,那么过多的步数其实作用不大。目前迭代步数一般在20-40即可,太少的步数可能由于噪声没有完全去除,所以生成的图片噪点很多,看起来可能比较模糊;而太多则是一种时间和资源的浪费。
3.3 高分辨率修复
高分辨率修复简单来说就是将生成的图片放大为分辨率更高的高清图片,像我们用SD生成图片,图片的尺寸一般在512-1024,这样尺寸的图片清晰度是不太够的,所以需要通过高分辨率修复功能提高图片清晰度。

3.4 图片精修Refiner
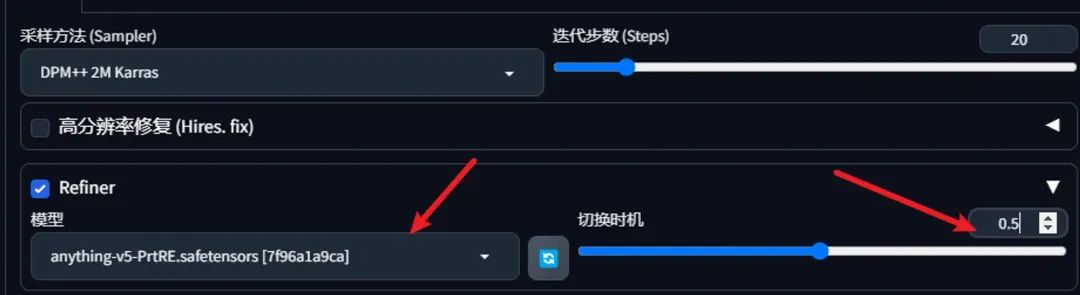
精修的作用就是将图片打磨得更漂亮,跟我们通常理解的图片精修是一个意思。Refiner有两个参数,第一个参数是选择精修的大模型,第二个参数是选择精修的时机,像下图迭代步数为20,切换时机为0.5,则从第20 * 0.5 = 10步开始精修。
3.5 面部修复
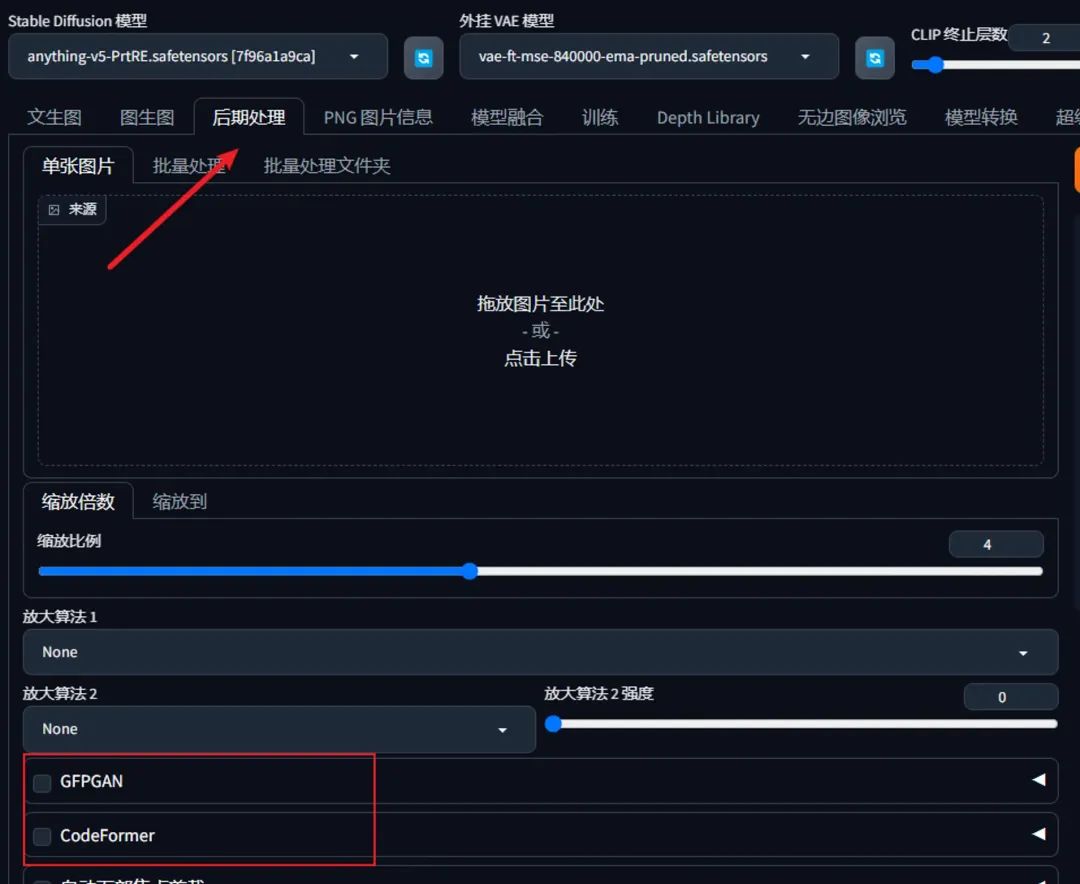
如果你的SD不是秋叶整合包,可能在高分辨率修复旁边还能看到一个面部修复,这个在秋叶整合包其实也是存在的,只不过位置不一样,移到后期处理Tab了。
之所以有面部修复,是因为图片本身尺寸较小,所以如果画人的话留给脸部的像素其实不多,这样AI其实不能画得很好,这时候就可以通过面部修复对面部进行“精修”
3.6 总批次数/单批数量
-
总批次数即一共执行多少次图片生成任务,默认值为1,最大值为100。
-
单批数量即每次任务生成多少张图片,默认值为1,最大值为8。
如果需要批量生成4张图片,设置“总批次数为4、单批数量为1”和设置“总批次数为1,单批数量为4”效果是一样的,但后者会更快一些,同时后者也需要更大的显存支持。如果显存较小的朋友,建议将单批数量置为1,通过调整总批次数来一次出多张图,相当于用时间换显存。
还有一个小细节就是,使用总批次数/单批数量,后一张图片的迭代步数是前一张图片的基础上加1,这样可以保证图片有变化,同时变化不太大。
3.7 提示词引导系数(CFG Scale)
这个参数决定了提示词对作图的影响,如果这个值越大,AI就会越严格地按照提示词进行创作;如果这个值越小,AI会越倾向于自由发挥。
比如我的提示词如下:1girl,red hair,tuxedo,high_heels( 1个女孩,红色头发,燕尾服,高跟鞋)
当引导系数的值为20的时候,生成的图片如下:

但当引导系数的值为3.5时,生成多几次,出现了这样的图片(违反了前面1个女孩的设定)

但这个也不是就那么绝对,我也试过在引导系数较大的情况下,多生成几次也出现了多人的情况,所以这个就是一个概率高低问题,一般我将其设置为 7-12 这个范围,这时候图片效果较好,既有创意又能围绕我们的提示词。
3.8 随机数种子
这玩意就好比画画时的线稿,如果你使用了上一张图片的随机数,那么这一次生成的图片大概率与上一张图片不会有太大的偏差。如果随机数种子设置为-1,则表示随机生成。
这个一般用于重复生成某张图片,因为就算你使用相同的提示词,采样方法和迭代步数,如果随机数相差较大,生成的图片差异也会很大,而如果这时候再使用相同的随机数,则能够在下一次生成图片的时候最大限度地进行还原(没办法保证100%,还是有随机性)
举个例子,上面的那张美女图片,我控制了相同的提示词,采样方法、迭代步数和随机数,最后出图的效果如下:

四、插件区和出图区
插件区域这块对于小白而言比较复杂,里面的功能暂时还用不到,等有对应的实战案例再单独讲下。
关于出图区,其实也比较简单,SD每次生成的图片都会保存下来,可以点击图像输出目录查看,另外几个其实都有对应中文说明,比如将图片发送到图生图选项卡,总结而言都是一些提升效率的快捷方式。
以上就是本次内容了,比较着重讲述的就是五大区域里面的参数调整区,因为这块区域对于小白而言用处较大,但是又有一定的复杂性,如果觉得本次内容对你有所帮助,还请多多点赞、在看支持!
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,。有需要的小伙伴文末扫码自行获取。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









