






一、数据结构之哈希表
所谓哈希表,是一种数据的存储结构,我们可以通过数据的“关键码值”来直接访问表。通过散列的方法(可以理解为一种特殊的数学过程=_=),我们可以把关键码值映射到数组中的不同位置。
设计散列系统的目标是对于任一个关键码值Key,都能通过某散列函数的计算来得到一个数组中的存储下标,使得该位置存储值Value。这样一来就很可能出现不同的关键码值对应同一个数组下标的情况,因此设计冲突解决策略也是必须的。
一种很容易想到的解决冲突的策略是,每当要存储一个关键值为Key的数据时,首先判断计算出的存储下标处是否已经存储了一个数据,如果是则将下标值进行“+1”操作,继续判断,直到判断为否时存入数据。
根据以上原理我们可以设计一个简单的程序来模拟哈希表的实现(这里假设Key和Value的数据类型都是int)
public class HashDemo {
static int size = 1000;
static int[] hash = new int[size];
int currsize = 0;
int Key, Value;
static {
for (int i = 0; i < size; i++) {
hash[i] = -1;
}
}
// 构造方法
public HashDemo(int Key, int Value) {
this.Key = Key;
this.Value = Value;
}
public HashDemo() {}
// 计算hashcode
public int hashcode(int Key) {
int index = Key % size;
if (currsize == size) {
return -1;
} else {
while (index >= 0 && index < size && hash[index] != -1) {
index++;
if (index == size - 1) {
index++;
}
}
return index;
}
}
// 往HashDemo中插入测试数据
public boolean put(int Key, int Value) {
int index = hashcode(Key);
if (index == -1 || index < 0 || index >= size)
return false;
else {
hash[index] = Value;
return true;
}
}
public void Tester() {
HashDemo hd = new HashDemo();
long starttime = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
hd.put(i * i, i * i);
}
long endtime = System.currentTimeMillis();
System.out.println("100000次put所用时间:" + (endtime - starttime) + "ms");
}
}
二、java中hashmap的具体实现
import java.util.HashMap;
public class HashTest {
public void Tester(){
HashMap<Integer,Integer> hm=new HashMap<Integer,Integer>();
long starttime=System.currentTimeMillis();
for(int i=0;i<1000000;i++){
Integer n=new Integer(i);
hm.put(n*n,n*n );
}
long endtime=System.currentTimeMillis();
System.out.println("100000次put所用时间:"+(endtime-starttime)+"ms");
starttime=System.currentTimeMillis();
for(int i=0;i<1000000;i++){
Integer n=new Integer(i);
Integer m=hm.get(n*n);
}
endtime=System.currentTimeMillis();
System.out.println("100000次get所用时间:"+(endtime-starttime)+"ms");
starttime=System.currentTimeMillis();
for(int i=0;i<1000000;i++){
Integer n=new Integer(i);
hm.remove(n*n);
}
endtime=System.currentTimeMillis();
System.out.println("100000次remove所用时间:"+(endtime-starttime)+"ms");
}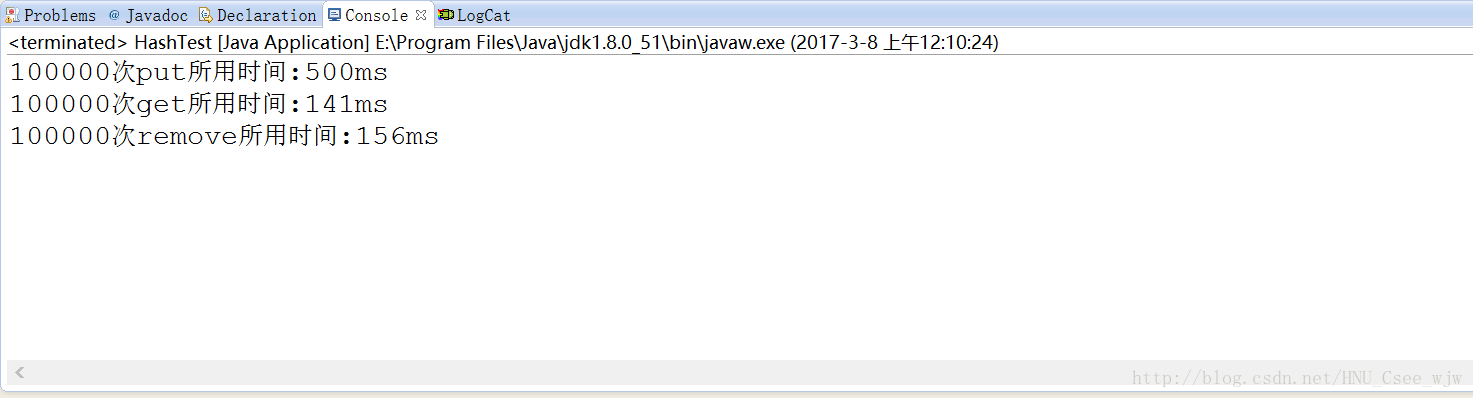
可以看到使用java中自带的hashmap类执行put操作时,和上述思路所花费的时间有较大的出入,并且可以发现多次put和get操作所花费的时间也有较大的差别。
通过查看源代码其实不难发现,java中的哈希表中每一个位置不会只存储一个元素,如果有多个Key值计算出来的hashcode结果是相同的,则这几个元素并不会移动存储的位置,也就是说,hashcode一旦被计算出来,就不会在改变。
那么多个数据是怎么存储在数组的一个位置上呢,其实很简单,我们可以联想数据结构中的“图”,其中有一种表示方法叫做临接表表示法,将存储在同一位置的数据用链表的形式连接起来来进行存储,其实HashMap有一个叫做Entry的内部类,它用来存储key-value对。
```
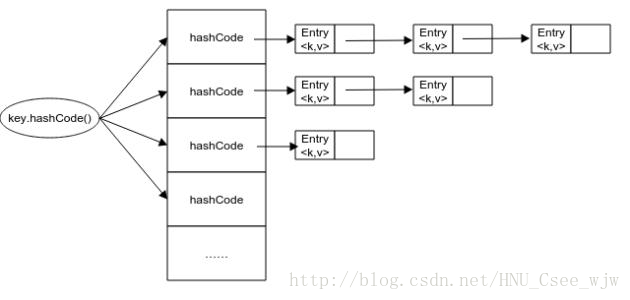
由于put时每一次都要实例化Entry内部类的对象,所以put方法要使用比get方法更久的时间。
三、hashcode的计算方法
由于java中有许多的数据类型,而且有时传入的Key是一个类的对象。所以hashcode的计算并不是那么容易。在设计一个类的时候,很可能要重写类的hashCode()方法,根据哈希表的特点,重写的hashCode()方法需要遵守以下准则:
①同一个对象调用hashCode()时,应返回相同的值
②若两个对象通过equals()方法比较返回true的时候,两个对象的hashCode()方法应返回相同的值
③对象调用equals()方法参与比较的值,都应该拿来计算hashCode()
对象中不同的值对应不同的计算方法:
```

将所有的数据计算出来的hashCode相加即为该对象的hashCode();为了避免重复,可以让各个数据乘以不同的权值后再相加。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











