









《机器学习工具与方法》— WEKA实战二
第一题
题目:Glass.arff-Classify-Ibk-10折交叉验证选择元学习器FilteredClassifier-IBk分类器,并选择AddNoise无监督属性过滤进行数据分析,同时可以根据数据画图进行结果分析。
解答:
-
导入玻璃数据集,分类器中选中weka.classifiers.meta.FilteredClassifier,选择元学习器weka.classifiers.lazy.IBk,即k邻近算法进行分类,同时选中过滤器weka.filters.unsupervised.attribute.AddNoise以增加数据噪声。操作截图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
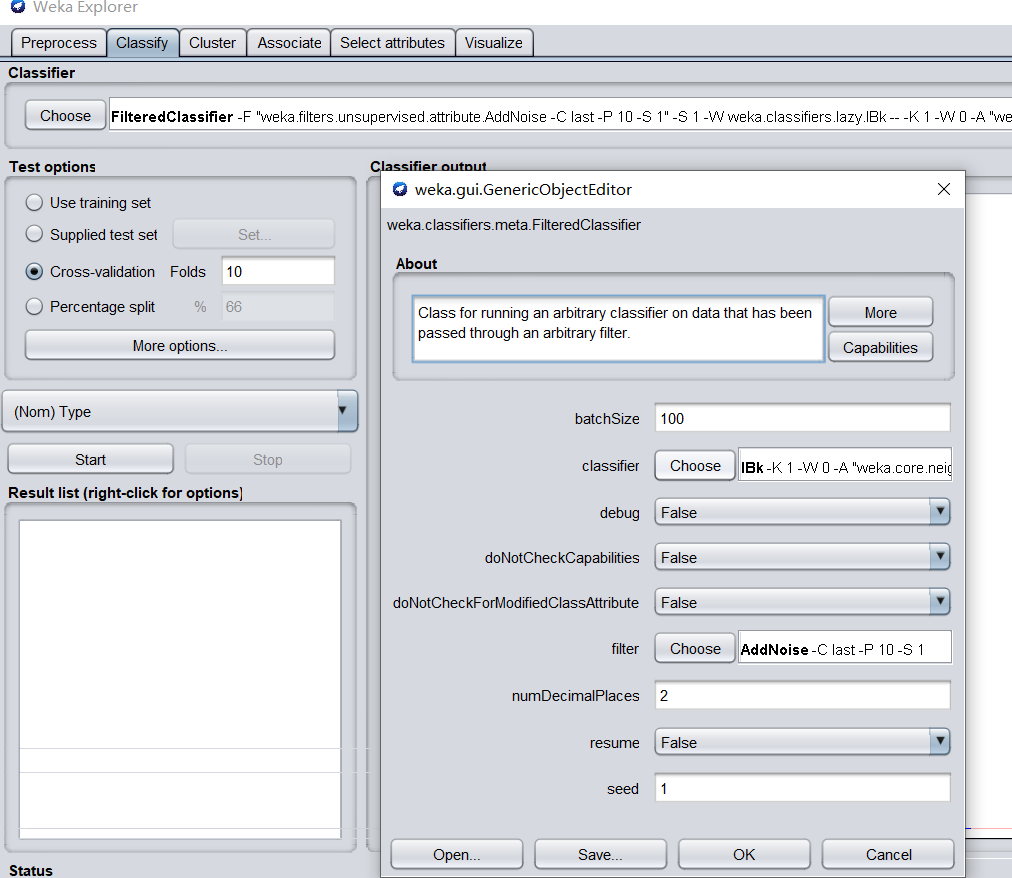
-
设置K邻近算法的K分别等于1,2,3 ,设置噪声百分比从0%增加到100%,进行分类正确率的汇总:
| 噪声百分比 | K = 1 | K = 2 | K = 3 |
|---|---|---|---|
| 0% | 70.56 | 67.75 | 71.96 |
| 10% | 61.21 | 66.82 | 70.56 |
| 20% | 52.80 | 60.74 | 65.88 |
| 30% | 45.79 | 55.14 | 61.24 |
| 40% | 36.92 | 47.20 | 50.00 |
| 50% | 33.18 | 41.12 | 43.46 |
| 60% | 27.57 | 36.92 | 38.79 |
| 70% | 20.56 | 28.97 | 29.91 |
| 80% | 16.82 | 22.90 | 23.83 |
| 90% | 12.62 | 17.29 | 19.63 |
| 100% | 6.07 | 7.94 | 7.01 |
表格单位填写的是在叠加噪声后数据在K邻近算法下的十折交叉验证分类正确率。
-
绘图分析:横坐标代表噪声百分比,纵坐标代表分类正确率。
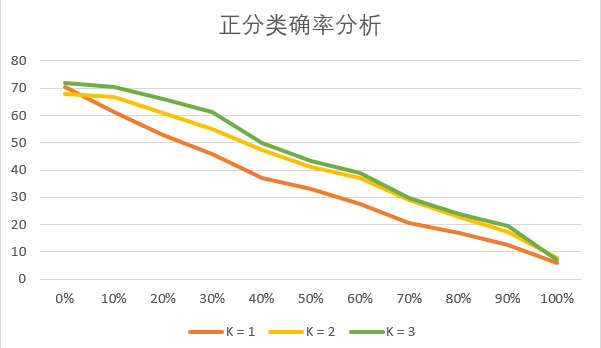
结合上图我们发现:
-
当噪声增大时,分类准确率随之降低
-
k值对分类正确率的影响需要分情况考量,增大k值会抑制噪声,增加分类准确率;k值过大且噪声百分比较小时,会降低分类准确率。
-
数据集会受到噪声的干扰,k邻近学习需要找到合适的k值,既能抑制噪声,又不会显著降低分类准确率。
-
第二题
题目:选择两个分类器进行实验,比较Glass-Ibk-J48、FilteredClassifier-Resample,进行不同采样百分比,进行分类实验。
解答:
-
导入glass数据集,分类器选中FilteredClassifier,其中classifier选中Ibk(K邻近 K=1)或J48(决策树),Filter选中resemple(重采样大小设置为10%~100%)操作如下图所示:
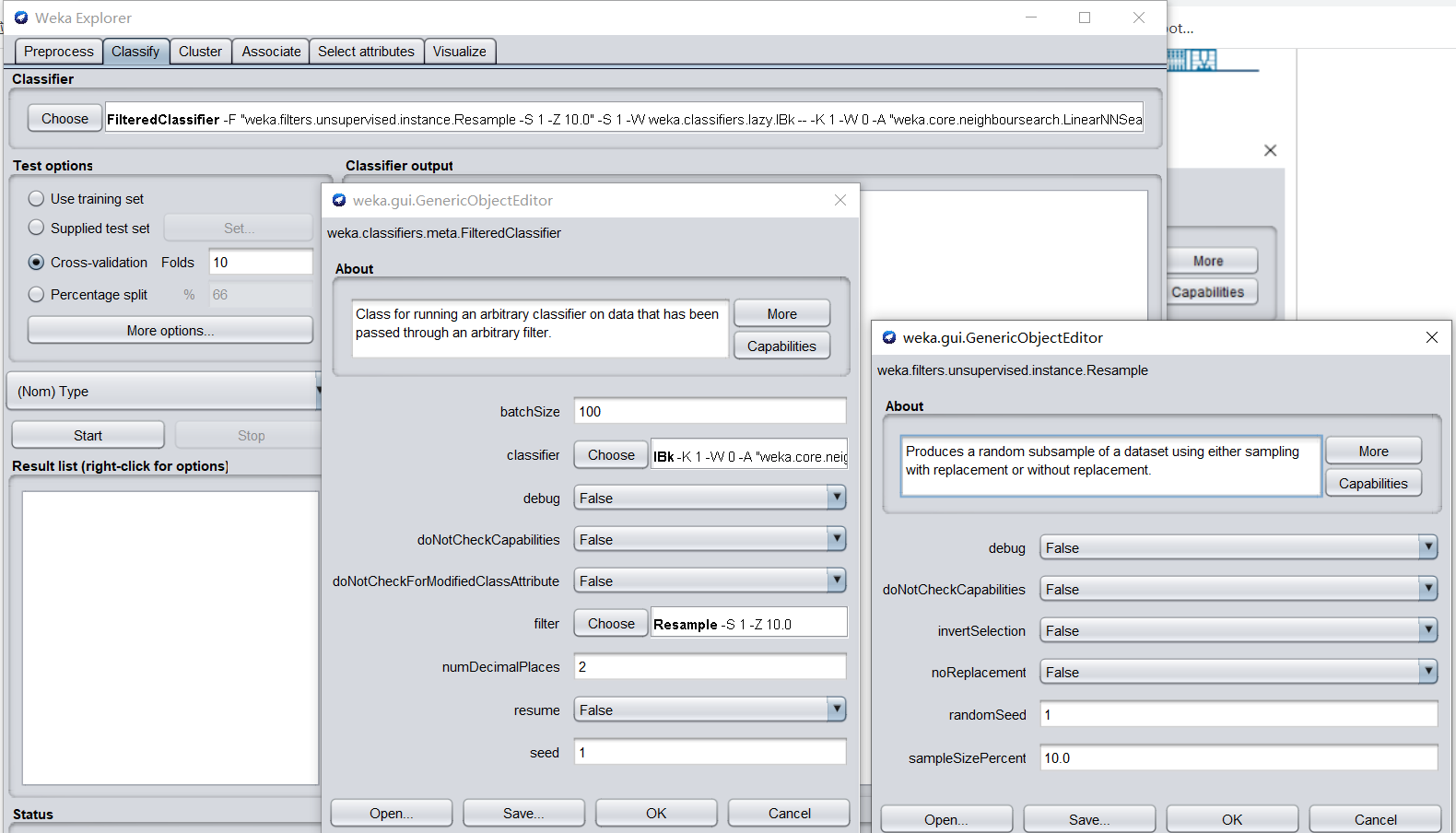
-
不断修改重采样比率填写下表:
| 训练集百分比 | IBK(K邻近算法) | J48(决策树算法) |
|---|---|---|
| 10% | 54.21 | 45.33 |
| 20% | 56.07 | 47.66 |
| 30% | 57.48 | 57.01 |
| 40% | 62.62 | 57.94 |
| 50% | 63.55 | 61.22 |
| 60% | 64.49 | 63.08 |
| 70% | 63.55 | 64.49 |
| 80% | 66.82 | 63.55 |
| 90% | 68.22 | 63.55 |
| 100% | 66.82 | 64.95 |
填入数据为算法在对应重采样下的分类准确率,单位为%。
-
绘图分析:
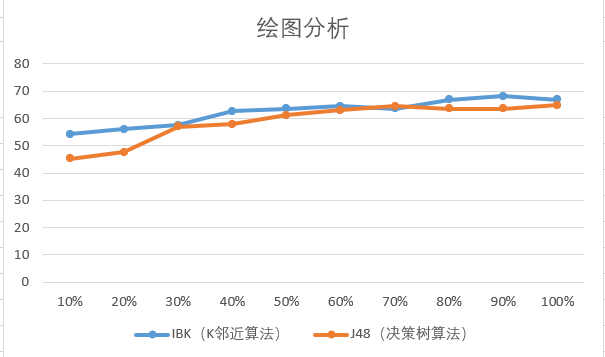
从上图中我们可以发现:
- 当增大训练数据量时,分类准确率会随之增加
- 相对于Ibk,增大训练数据量对J48的影响更显著















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









