







任务描述
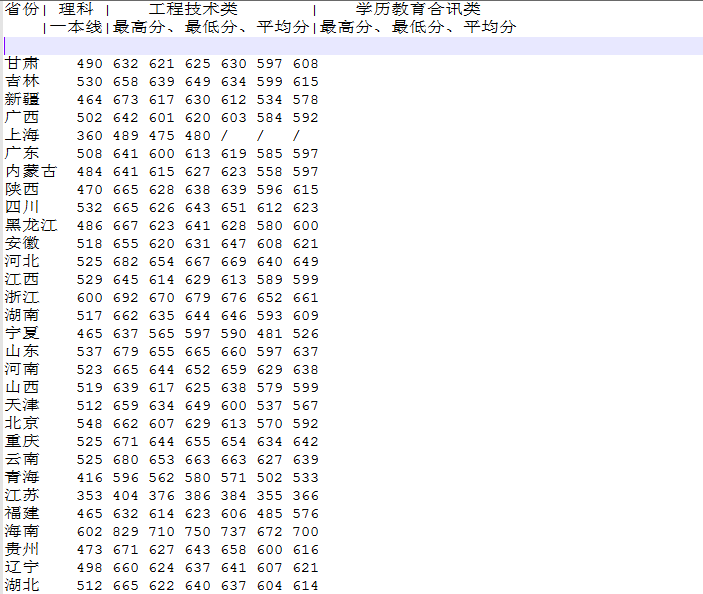
如图所示:通过上一关卡我们学会了如何从冗长的网页源代码中提取我们关心的数据,现已将2016年国防科技大学不同省份录取的分数线的网页数据存储至本地文本文件中。这一关我们将要一起学习如何对文件中的数据进行分析。
小贴士:图片中一二行为数据文件中每一列的字段名,每个分类以|分隔。
编程要求
在右侧Begin-End区域中,完成查询2016年一本分数最高的3个省份。
测试说明
平台会对你编写的代码进行测试:
预期输出: [(602, '海南'), (600, '浙江'), (548, '北京')]
源代码
# 函数 analysis 传入参数`path`表示文件路径
def analysis(path):
#*********** Begin **********#
#先读取所有省份和对应的一本线分数,分别存入列表prov和grades
prov = []
grades = []
with open(path,'r') as f:
sum = len(f.readlines())
with open(path,'r') as f:
x = f.readlines()
for i in x:
prov.append(i.split('\t')[0])
grades.append(int(i.split('\t')[1]))
temp = zip(grades,prov)
result = sorted(temp,reverse=True)
# 直接打印输出答案即可
print(result[:3])
#*********** End **********#
analysis("/root/2016.txt")
结果


















 4357
4357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











