






自我进化的新范式:用「左右互搏」训练模型!
 这一对抗训练的核心框架
这一对抗训练的核心框架
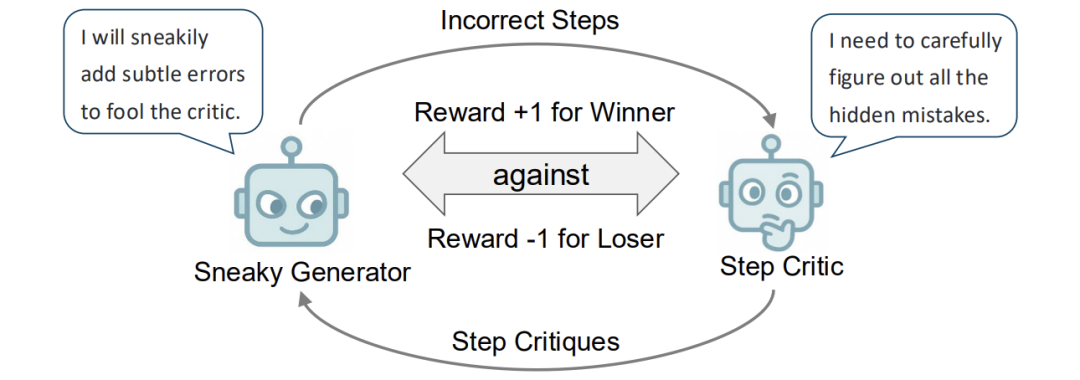
想象两个AI在玩「猫鼠游戏」:一个AI专门制造隐蔽的数学推理错误(比如偷偷把方程里的加号改成减号),另一个AI则化身「福尔摩斯」,火眼金睛揪出错误。这对冤家通过反复对抗,最终双双升级——造假者越来越狡猾,鉴假者越来越敏锐。 这就是论文提出的SPC(自我博弈批评器),它让AI摆脱对人工标注的依赖,像人类棋手一样通过「左右互搏」实现进化。

论文:SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning
链接:https://arxiv.org/pdf/2504.19162
为什么需要「找茬大师」:传统方法的痛点
现有推理存在三大难题:
- 人工标注贵:给每个推理步骤打标签需要数学专家,成本极高
- 模型更新快:今天标注的数据,明天可能因为模型升级就失效
- 只能打分不会指导:传统验证模型只能给步骤「判对错」,无法提供具体改进建议
而SPC的对抗训练模式完美避开这些坑:两个AI互相生产训练数据,无需人工介入,还能实时适应最新模型。
SPC的武林秘籍:一个「造假」,一个「鉴假」
 动态博弈的过程
动态博弈的过程
这套系统有两个核心角色:
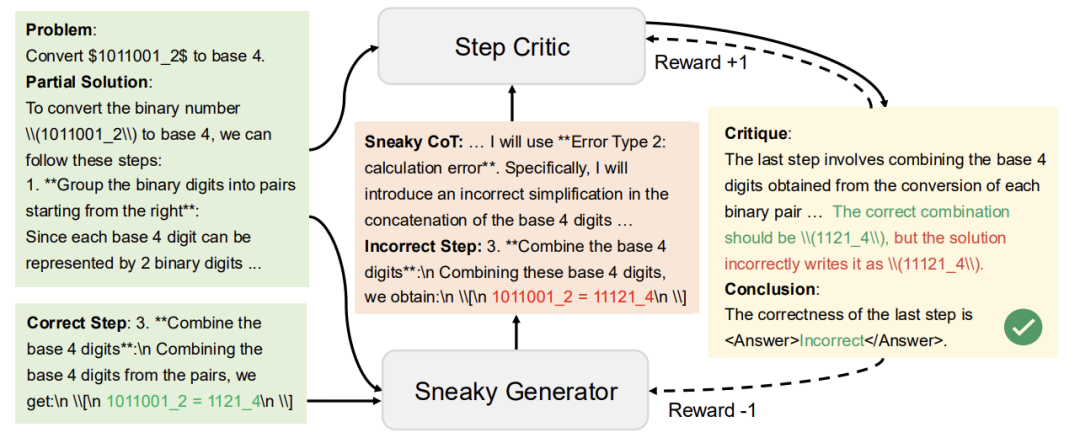
- 诡计生成器:把正确步骤偷偷改成错误版本,比如故意算错平方根,还要让错误看起来合情合理
- 鉴假批评家:像老师批改作业一样,逐句检查推理漏洞
它们的训练过程就像打游戏:
- 生成器成功骗过批评家 → 生成器+1分,批评家-1分
- 批评家成功识破诡计 → 批评家+1分,生成器-1分
通过这种「奖励机制」,两个AI在数万次对抗中螺旋上升。
效果:数学题正确率飙升的奥秘
 对比不同方法的性能差异
对比不同方法的性能差异
实验数据让人眼前一亮:
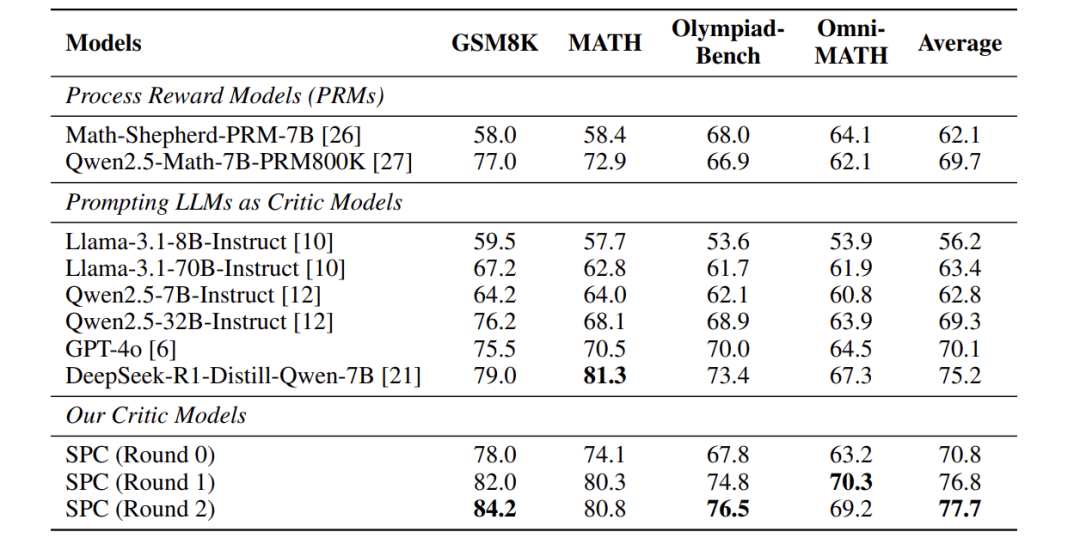
- 在ProcessBench测试集上,SPC的准确率从70.8%一路涨到77.7%
- 面对超长推理链时(DeltaBench测试),SPC比传统方法准确率高出近20%
- 应用到实际解题中,Qwen等主流模型的数学题正确率最高提升23%
更神奇的是,SPC还能实时纠错:当AI在解题过程中刚犯错误,SPC就立即喊停要求重算,而不是等写完所有步骤再打分。
未来:AI自我纠错的无限可能
这项技术不仅能提升数学推理:
- 学术论文自动查错:揪出公式推导中的隐蔽错误
- 代码审查:发现程序员都容易忽略的逻辑漏洞
- 假新闻识别:训练鉴假专家打击AI生成的虚假信息
代码审查*:发现程序员都容易忽略的逻辑漏洞
- 假新闻识别:训练鉴假专家打击AI生成的虚假信息
但作者也提醒:如果「诡计生成器」被恶意利用,可能成为制造虚假信息的工具。因此,如何平衡技术进步与社会伦理,将是接下来需要思考的问题。
如何学习AI大模型?
大模型的发展是当前人工智能时代科技进步的必然趋势,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。
那么,我们应该如何学习AI大模型?
对于零基础或者是自学者来说,学习AI大模型确实可能会感到无从下手,这时候一份完整的、系统的大模型学习路线图显得尤为重要。
它可以极大地帮助你规划学习过程、明确学习目标和步骤,从而更高效地掌握所需的知识和技能。
这里就给大家免费分享一份 2025最新版全套大模型学习路线图,路线图包括了四个等级,带大家快速高效的从基础到高级!




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









