







 本文详细介绍了数据结构的基本概念,包括数据结构的定义、逻辑结构(如集合、线性、树形和图形结构)、存储结构(顺序存储、链式存储、索引和哈希存储)及其优缺点。同时探讨了算法的概念、设计目标和分析方法,重点讲解了时间复杂度和空间复杂度的评估。最后强调了数据结构与算法在编程中的重要性及它们之间的相互关系。
本文详细介绍了数据结构的基本概念,包括数据结构的定义、逻辑结构(如集合、线性、树形和图形结构)、存储结构(顺序存储、链式存储、索引和哈希存储)及其优缺点。同时探讨了算法的概念、设计目标和分析方法,重点讲解了时间复杂度和空间复杂度的评估。最后强调了数据结构与算法在编程中的重要性及它们之间的相互关系。
1.1什么是数据结构
1.1.1数据结构的定义
用计算机解决一个具体问题步骤:
- 分析问题,确定数据模型
- 设计相应的算法
- 编写程序,运行并调试程序,直至得到正确的结果
数据:描述客观事物的数和字符的集合。
数据项:具有独立含义的数据最小单位,也称为字段或域。
数据对象:指性质相同的数据元素的集合,他是数据的一个子集。
数据结构:指所有数据元素以及数据元素之间的关系,可以看作是相互之间存在着某种特定关系的数据元素的集合。
数据结构=数据+结构
数据结构包括以下几个方面:
- 数据的逻辑结构:由数据元素之间的逻辑关系构成。
- 数据的存储结构:数据元素及其关系在计算机存储器中的存储表示,也称为数据的物理结构
- 数据的运算:施加在该数据上的操作。
1.1.2逻辑结构
定义:数据的逻辑结构是从数据元素的逻辑关系上描述数据的,是值数据元素之间的逻辑关系的整体,通常是从求解问题中提炼出来的。
1.逻辑结构的表示
1)图表表示:采用表格或者图形直接描述数据的逻辑关系。如下所示:
| 学号 | 姓名 | 性别 | 班号 |
|---|---|---|---|
| 1 | 张三 | 男 | 9901 |
| 8 | 李四 | 女 | 9905 |
| 34 | 王五 | 男 | 9903 |

上图为学生表的图形表示
2)二元组表示:
二元组是一种通用的数据逻辑结构表示方式。一个二元组表示如下:
B=(D,R)
其中,B是一种数据逻辑结构,它由数据元素的集合D以及D上的二元关系的集合R所组成。
<
x
1
,
x
2
>
<
x
3
,
x
4
>
.
.
.
.
.
.
<x1,x2><x3,x4>......
<x1,x2><x3,x4>......
其中x1是x2的前驱元素,x2是x1的后继元素。若某个元素没有前驱元素,则称该元素为开始元素;若某个元素没有后继元素,则称该元素为终端元素。
2.逻辑结构的类型
1)集合
数据元素之间除了“同属一个集合”的关系以外别无其他关系。
2)线性结构
该结构中的数据元素之间存在一对一的关系。
特点:
- 开始元素和终端元素唯一
- 除开始元素和终端元素意外,其余元素都有且仅有一个前驱元素,有且仅有一个后继元素。
3)树形结构
结构中的数据元素之间存在一对多的关系。
特点:
- 除了开始元素以外每个元素有且仅有一个前驱节。
- 除终端元素以外,每个元素有一个或多个后继元素。
4)图形结构
该结构中的数据元素之间存在多对多的关系。
特点:每个元素的前驱元素和后继元素的个数可以是任意的。

由各定义可知,线性结构是树形结构的特殊情况,树形结构又是图形结构的特殊情况。
1.1.3存储结构
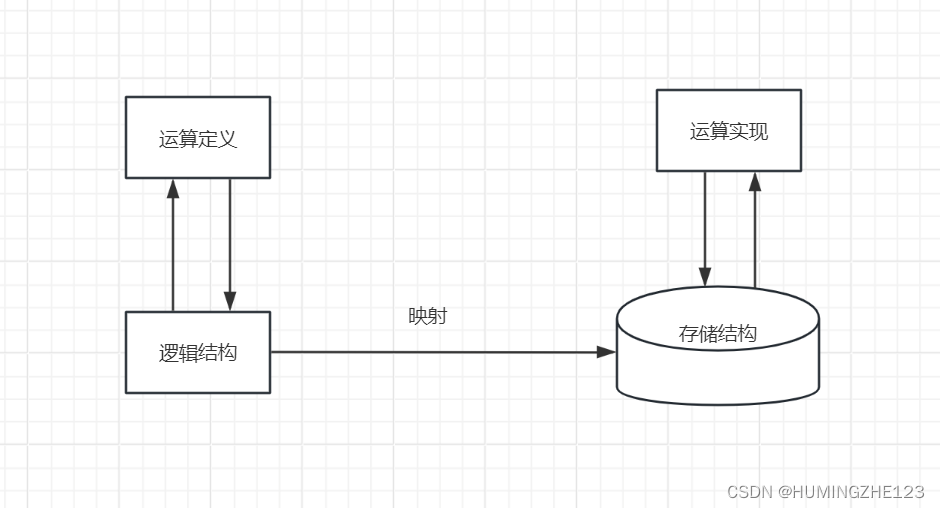
数据逻辑结构在计算存储器中的存储表示称为数据的存储结构(也称为映像),也就是逻辑结构在计算机中的存储实现。
数据结构的四种常用存储结构类型:
1.循序存储结构
采用一组连续的存储单元存放所有的数据元素。
struct
{int no;//存储学号
char name[8];//存储姓名
char sex[2];//存储性别
char class[4];//存储班号
}Stud[7]={{1,"张斌","男","9901"},...,{5,"王萍","女","9901"}};
1)优点:
- 是存储效率高,因为分配给数据的存储单元全用于存放数据元素,元素之间的逻辑关系没有占用额外的存储空间;
- 在采用这种存储方法时可实现对元素的随机存取,即每个元素对应一个逻辑序号,由该序号可直接计算出对应元素的存储地址,从而获取元素值。
2)缺点:
不便于数据修改,对元素的插入或删除操作可能需要移动一系列的元素。
2.链式存储结构
每个逻辑元素用一个内存结点存储,每个结点是单独分配的,所有的结点地址不一定是连续的,所以无须占用一整块存储空间。每个结点附加指针域表示元素之间的逻辑关系。
1)优点:便于数据修改。
2)缺点:存储空间的利用率较低,存储单元有一部分被用来存储结点之间的逻辑关系。
#include <stdio.h>
typedef struct Studnode
{int no;//存储学号
char name[8];//存储姓名
char sex[2];//存储性别
char class[4];//存储班号
struct Studnode * next;//存储指向下一个学生结点的指针
}StudType;//结点类型
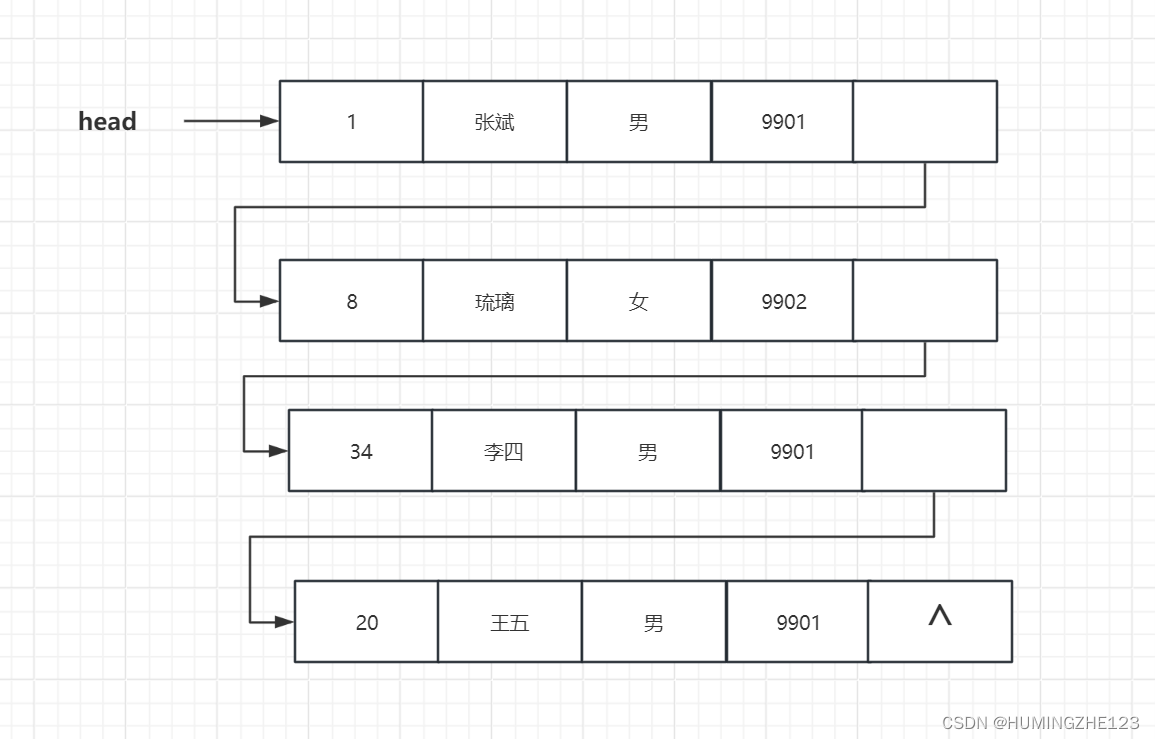
首节点的指针为head,用它来标识整个学生链表,尾结点的指针域为空。
3.索引存储结构
在存储数据元素信息的同时还建立附加的索引表
优点:查找效率高。
缺点:需要建立索引表,增加了空间开销。
4.哈希(或散列)存储结构
基本思想是根据元素的关键字通过哈希(或散列)函数直接计算出一个值,并将这个值作为该元素的存储地址。哈希表不存储元素之间的逻辑关系。
优点:查找速度快,只要给出待插元素的关键字就可立即计算出该元素的存储地址。
1.1.4数据运算
数据元素是指对数据实施的操作,每种数据结构都有一组相应的元素,最常用的运算有检索、插入、删除、更新和排序等。

1.1.5数据类型和抽象数据类型
1.数据类型
定义:一组性质相同的值的集合和定义在此集合上的一组操作的总称,是某种程序设计语言中已实现的数据结构。
1)C/C++语言中常用的数据类型
(1)基本数据类型
int、bool、float、double、char
int型有3个修饰符,short(短整数)、long(长整数)、unsigned(无符号整数)
(2)指针类型
int i,*p;
(3)数组类型
int a[10];
(4)结构体类型
`
#include <stdio.h>`
`typedef struct Studnode`
`{int no;//存储学号`
`char name[8];//存储姓名`
`char sex[2];//存储性别`
`char class[4];//存储班号`
`struct Studnode * next;//存储指向下一个学生结点的指针`
`}StudType;//结点类型
`
(5)共用体类型
把不同的成员组织为一个整体,它们在内存中共享一段存储单元,但不同成员以不同方式被解释。
//声明一个共用体类型
union Tag//Tag共用体
{short int n;//成员n占两个字节
char ch[2];//成员ch数组,占两个字节
};
定义一个共用体变量u并赋值
union Tag u;
u.n=0x4142;
(6)自定义类型
C/C++允许使用typedef关键字来指定一个新的数据类型名。
typedef char ElemType;
2)存储空间的分配
(1)静态存储空间分配方式
(2)动态存储空间分配方式
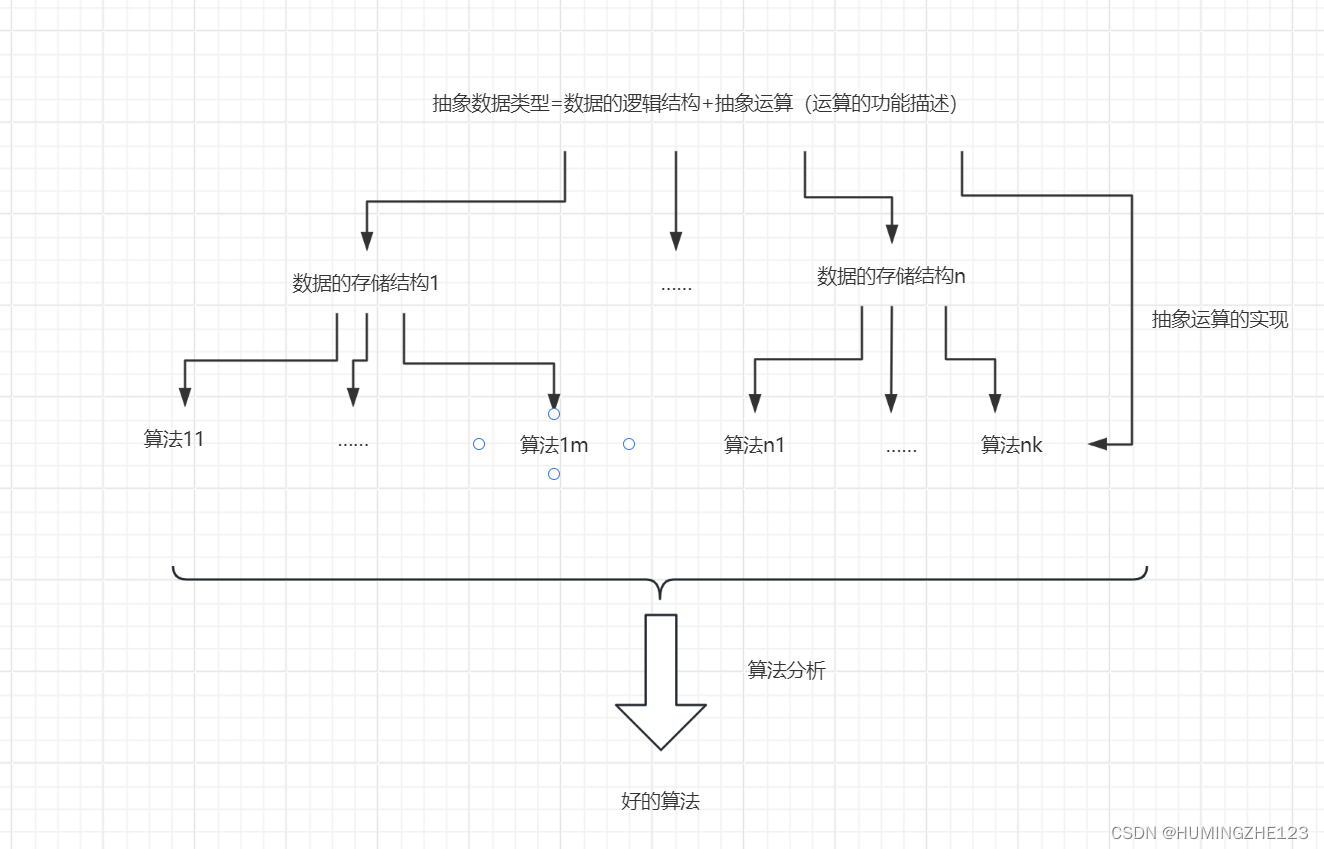
2.抽象数据类型
指的是用户进行软件系统设计时从问题的数据模型中抽象出来的逻辑数据结构和逻辑数据结构上的运算,而不考虑计算机的具体存储结构和运算的具体实现方法。
两个重要特征:数据抽象和数据封装
1.2算法及其描述
1.2.1什么是算法
算法是对特定问题求解步骤的一种描述,它是指令的有限序列。
具有以下5个重要的特性:
(1)有穷性(2)确定性(3)可行性(4)有输入(5)有输出
注:算法与程序是有区别的,程序是具体实现,算法只是解决问题的描述。
1.2.2算法设计的目标
(1)正确性
(2)可使用性:方便使用,用户友好性
(3)可读性
(4)健壮性:容错性
(5)高效率与低存储量需求
1.2.3算法描述
1.算法描述的一般格式和设计步骤
(1)分析算法的功能。
(2)确定算法有哪些输入,将这些输入设计成输入型参数;确定算法有哪些输出,将这些输出设计成输出型参数数。
(3)设计函数体,完成从输入到输出的操作过程。
2.输出型参数的设计
1.3算法设计
1.3.1算法分析概述
算法分析就是分析算法占用计算机资源的多少。计算机资源包括CPU时间和内存空间。
分析算法占用CPU时间的多少称为时间性能分析,分析算法占用内存空间的多少称为空间性能分析。
1.3.2算法时间性能分析
1.两种算法时间性能分析方法
(1)事后统计法:统计算法对应程序的执行时间
(2)事前估算法:不考虑计算机硬件、软件因素,仅考虑算法本身的效率高低。引出下面算法复杂度
2.算法时间复杂度分析
(1)计算算法的频度T(n)
即求算法所有原操作的执行次数(也称频度)
#define MAX 20
void matrixadd(int n,int A[MAX][MAX],int B[MAX][MAX],int C[MAX][MAX])
{int i,j;
for(i=0;i<n;i++){
for(j=0;j<n;j++){
C[i][j]=A[i][j]+B[i][j];
}
}
}
T ( n ) = n + 1 + n ( n + 1 ) + n 2 = 2 n 2 + 2 n + 1 T(n)=n+1+n(n+1)+n^2=2n^2+2n+1 T(n)=n+1+n(n+1)+n2=2n2+2n+1
2)T(n)用“O”表示
算法时间复杂度就是用T(n)的数量级表示为O(f(n))
O
(
1
)
<
O
(
l
o
g
n
)
<
O
(
n
)
<
O
(
n
l
o
g
n
)
<
O
(
n
2
)
<
O
(
n
3
)
<
O
(
2
n
)
<
O
(
n
!
)
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(n^3)<O(2^n)<O(n!)
O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)<O(n!)
注:此处皆为以2为底的对数
3)简化的算法时间复杂度分析
4)时间复杂度的求和、求积定理
求和定理:
T
1
(
n
)
+
T
2
(
n
)
=
O
(
M
A
X
(
f
(
n
)
,
g
(
n
)
)
)
T1(n)+T2(n)=O(MAX(f(n),g(n)))
T1(n)+T2(n)=O(MAX(f(n),g(n)))
求积定理:
T
1
(
n
)
∗
T
2
(
n
)
=
O
(
f
(
n
)
∗
g
(
n
)
)
T1(n)*T2(n)=O(f(n)*g(n))
T1(n)∗T2(n)=O(f(n)∗g(n))
3.算法的最好、最坏和平均时间复杂度
最好时间复杂度:指算法在最好情况下的时间复杂度
最坏时间复杂度:指算法在最坏情况下的时间复杂度
平均时间复杂度:
E
(
n
)
=
∑
P
(
I
)
∗
T
(
I
)
E(n)=∑P(I)*T(I)
E(n)=∑P(I)∗T(I)
P(I)是I出现的频率,T(I)是算法在输入I下所执行的基本操作次数。
4.递归算法的时间复杂度分析
1.3.3算法空间性能分析
1.算法空间复杂度分析
一个算法的存储量包括:输入数据所占的空间、程序本身所占的空间和临时变量所占的空间。
算法空间复杂度是对一个算法在运行过程中临时占用的存储空间大小的量度。若所需临时空间相对于问题规模来说是常数,则称此算法为原地工作算法或就地工作算法。
S(n)=O(g(n))
2.递归算法空间复杂度分析
对于递归算法,为了实现递归过程用到一个递归栈,所以需要根据递归深度得到算法的空间复杂度。
1.4数据结构+算法=程序
1.4.1程序和数据结构
一个程序所要进行的计算或处理总是以某些数据为对象的。将松散、无组织的数据按某种要求组成一种数据结构,对于设计一个简明、高效、可靠的程序是大有益处的。
1.4.2算法和程序
由程序设计语言描述的算法就是计算机程序。
1.4.3算法和数据结构
不能离开数据结构去抽象地考虑算法,也不能脱离算法去孤立地讨论数据结构,只能从算法与数据结构的统一上去认识程序。
数据的存储结构也会影响算法的好坏,存储结构对算法的影响主要由以下两个方面
1.存储结构的存储能力
如果存储结构的存储能力强、存储的信息多,算法将会较好设计。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









