






目录
近期一直在玩大模型,对中文支持比较好的就是清华的chatGLM,目前chatGLM由v1升级到了chatGLM2。在gihub上介绍信息如下:
试用了一下,效果和速度确实有所提升。
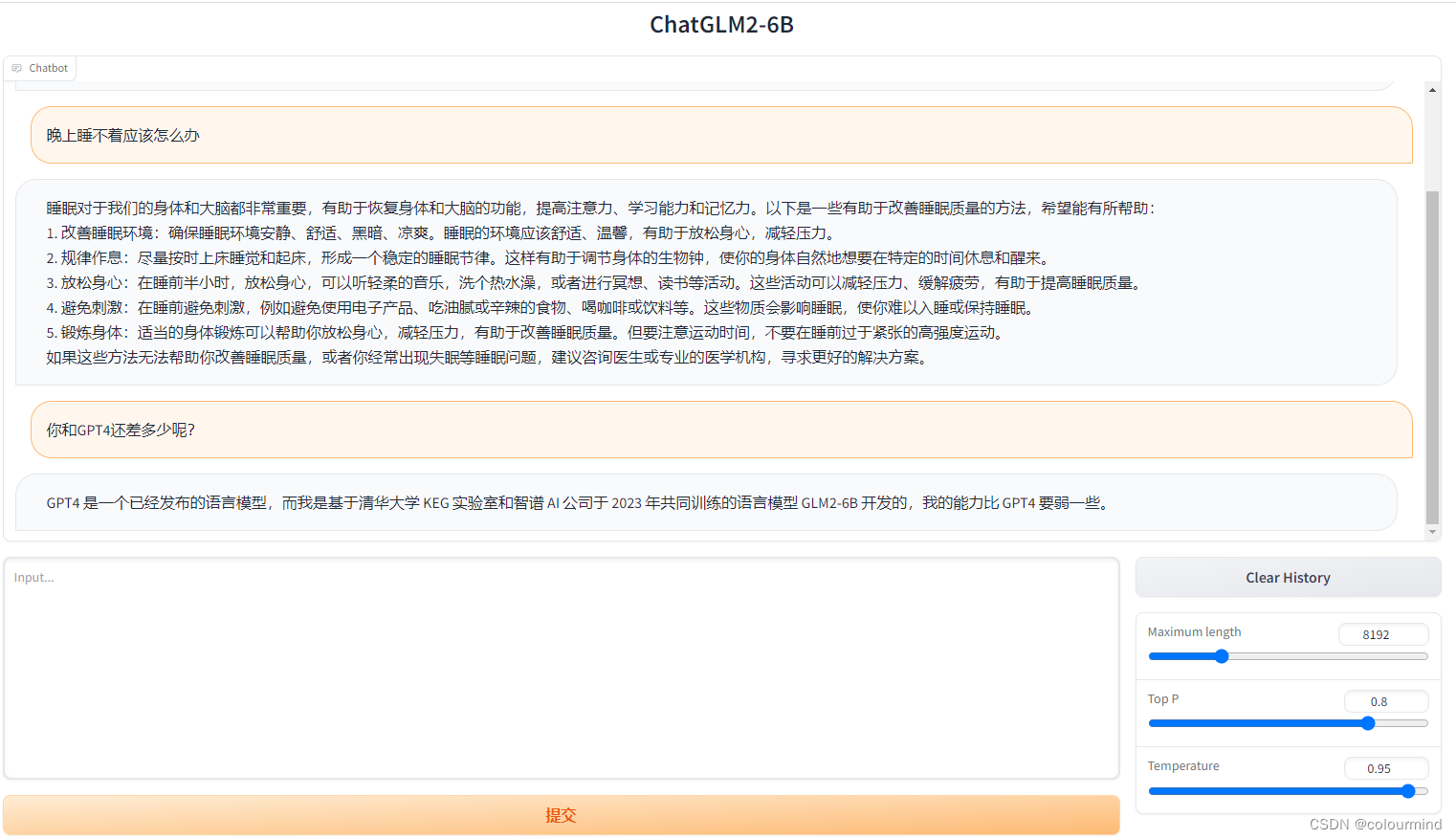
这个得益于chatGLM2应用了许多优化的技术,介绍中有提到过的FlashAttention技术、Multi Query Attention(MQA)技术和int4量化等等。其中MQA技术是对Multi head Attention(MHA)的一种优化实现,加快了技术速度的同时也保证了效果下降的不厉害。
原理简介
MQA最早是出现在2019年谷歌的一篇论文Fast Transformer Decoding: One Write-Head is All You Need,之所以没有关注到,是因为之前很少做文本生成,解码序列长度也没有现阶段大模型的要求那么高。MQA的思想其实比较简单(如果对MHA比较熟悉的话),论文中给出的描述如下:

论文的意思是:MQA和MHA除了不同的attention head共享一份keys和values权重之外,其他的都是一样的。现有4个head的attention,每个head分别进行softmax(QK)V注意力计算,那么这样设置的MHA和MQA示意图如下所示:


可以看到MHQ和MQA的不同之处仅仅在于每个头共享相同的K、V权重而Q不同享。
模型效果论文对比如下:
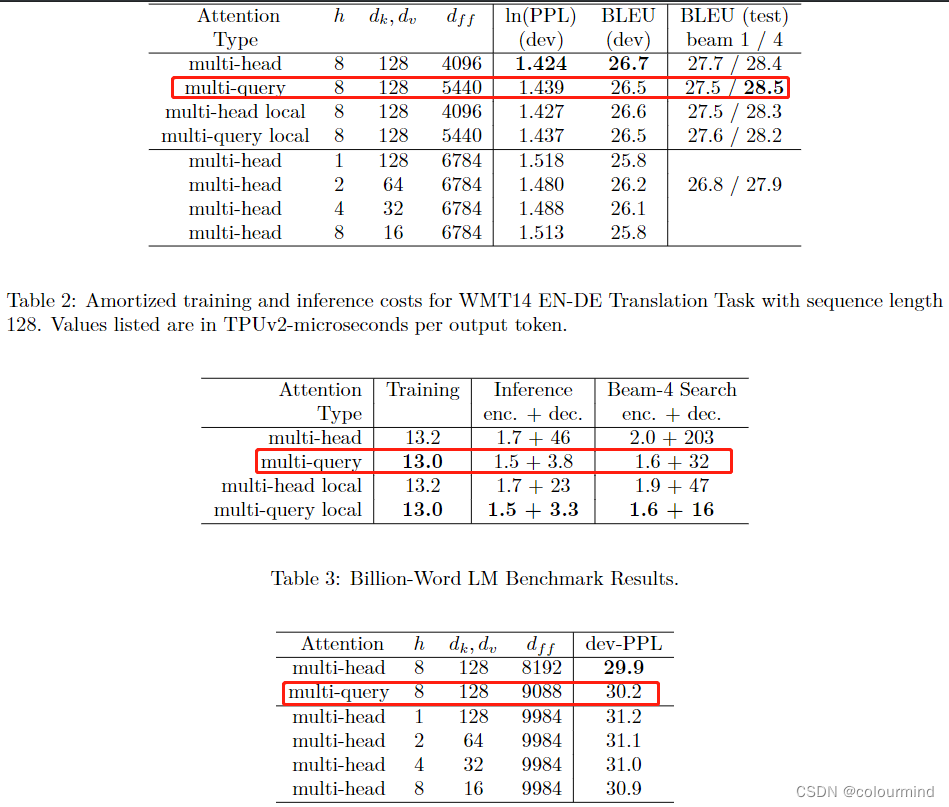
推理速度上生成一个token时MHA和MQA的encoder分别耗时1.7us和1.5us,而decoder分别46us和3.8us,说明decoder上MQA比MHA快很多。另外在效果上MQA的PPL(越小越好)有所上升,BLEU(越大越好)有所下降,换句话说就是效果有所下降。
代码实现和耗时比较
参考了huggingface的transformers包中的bertselfattention源码实现了一版MHA和MQA,代码如下:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "1"
import math
import torch.nn as nn
import torch
from tqdm import tqdm
import time
class MiltiHeadSelfAttention(nn.Module):
def __init__(self, num_attention_heads, hidden_size):
super().__init__()
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(hidden_size, self.all_head_size)
self.key = nn.Linear(hidden_size, self.all_head_size)
self.value = nn.Linear(hidden_size, self.all_head_size)
self.dropout = nn.Dropout(0.1)
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self,hidden_states):
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
return context_layer
class MultiQuerySelfAttention(nn.Module):
def __init__(self, num_attention_heads, hidden_size):
super().__init__()
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(hidden_size, self.all_head_size)
self.key = nn.Linear(hidden_size, self.attention_head_size)
self.value = nn.Linear(hidden_size, self.attention_head_size)
self.dropout = nn.Dropout(0.1)
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self,hidden_states):
# hidden_states (B, L, D)
mixed_query_layer = self.query(hidden_states)
# query_layer (B, h, L, d)
query_layer = self.transpose_for_scores(mixed_query_layer)
# 每个key、value head参数都是一样的,只计算一次
key = self.key(hidden_states)
#key_layer (B, 1, L, d)
key_layer = key.unsqueeze(1)
value = self.value(hidden_states)
# value_layer (B, 1, L, d)
value_layer = value.unsqueeze(1)
# key_layer (B, 1, d, L)
key_layer = key_layer.transpose(-1, -2)
#广播算法 (B, h, L, d) * (B, 1, d, L) => (B, h, L, d) * (B, h, d, L) = (B, h, L, L)
attention_scores = torch.matmul(query_layer, key_layer)
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
attention_probs = self.dropout(attention_probs)
#广播算法 (B, h, L, L) * (B, 1, L, d) =>(B, h, L, L) * (B, h, L, d)= (B, h, L, d)
context_layer = torch.matmul(attention_probs, value_layer)
#(B, h, L, d) => (B, L, h, d)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
# (B,L, h*d) => (B,L,D)
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
# (B,L, h*d) => (B,L,D)
context_layer = context_layer.view(new_context_layer_shape)
return context_layer
if __name__ == '__main__':
seed = 100
num_attention_heads, hidden_size = 32, 4096
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
device = "cuda:0"
embeddings = torch.randn(5, 128, hidden_size).to(device)
multiquery = MultiQuerySelfAttention(num_attention_heads, hidden_size).to(device)
print(multiquery)
total = 0
for name, param in multiquery.named_parameters():
if len(param.size()) == 2:
total += param.shape[0] * param.shape[1]
else:
total += param.shape[0]
print(f"multiquery parameters {total}")
count = 100
start = time.time()
for _ in tqdm(range(count),ncols=50):
input = embeddings.clone()
for _ in range(100):
for i in range(24):
ouput = multiquery(input)
input = torch.cat([input,ouput[:,-1:,:]],dim=1)
end = time.time()
print(f"multiquery time total cost {round(end - start, 8)} mean cost {round((end - start) / count, 8)}")
multihead = MiltiHeadSelfAttention(num_attention_heads, hidden_size).to(device)
print(multihead)
total = 0
for name, param in multihead.named_parameters():
if len(param.size()) == 2:
total += param.shape[0] * param.shape[1]
else:
total += param.shape[0]
print(f"multihead parameters {total}")
count = 100
start = time.time()
for _ in tqdm(range(count) ,ncols=50):
input = embeddings.clone()
for _ in range(100):
for i in range(24):
ouput = multihead(input)
input = torch.cat([input, ouput[:, -1:, :]], dim=1)
end = time.time()
print(f"multihead time total cost {round(end-start,8)} mean cost {round((end-start)/count,8)}")
实现中主要借助矩阵计算的broadcast机制(自动广播机制)并行计算、就不用自己来实现每个头单独计算然后进行cat操作,效率比较高。模拟chatGLM2的设置,hidden_size = 4096、num_heads =32,num_layers=24输入一个维度为(5,128,4096)的向量进行文本解码,生成100个token,耗时对比如下:
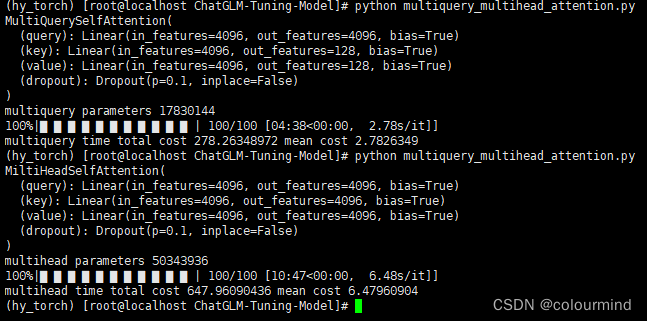
生成100个token时,MQA解码平均耗时2.7826秒,MHA解码平均耗时6.4796秒,简单来看MQA在decoder解码加速了一倍。从模型结构来看原始的MHA一层5034W参数,而MQA只有1783W参数,还是通过压缩参数量来实现显存占用的减少以及推理时间的减少。
总结分析
显存占用和推理耗时减小是显而易见的,因为参数量减少了。至于效果变化得很小,只能说多头attention机制中的多头其实并不是一定,之前的bert模型有人探索了改变head头数目,也会保持效果变化不大。在大模型这,可能只需要有不同的head采用不同的query向量,kv一样来保证每个头提取到不同的特征就够了。
什么时候使用MQA有效呢?
1、采用attention的模型,模型规模越大,那么收益就约明显。
2、decoder生成任务相比较encoder任务收益明显大很大,其实decoder生成任务的收益来源于每一次softmax(QK)V注意力计算微小耗时差异的累积,一次生成任务要生成许多个token,一个token需要经历模型结构层数次的softmax(QK)V注意力的计算。
参考文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









