






1.mapreduce
MapReduce编辑模型
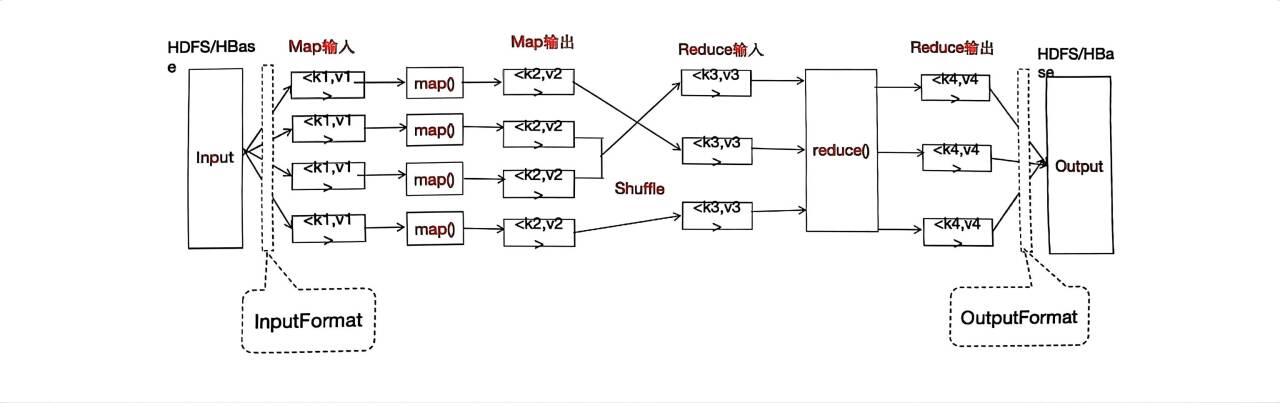
1.1MapReduce定义
MapReduce是一种简化并行计算的编程模型,用于进行大数据量的计算。
MapReduce是一个分布式运算程序的的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
1.2MapReduce优缺点
1.2.1优点
1.MapReduce易于编程
他简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得流行起来。
2.良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3.高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,就是要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由hadoop内部完成的。
4.擅长对PB级以上海量数据进行离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
1.2.2缺点
1.不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2.不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。就是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3.不擅长DAG(有向图)计算
多个应用程序存在一定的依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入磁盘,会造成大量的磁盘IO,导致性能非常的低下。
1.3MapReduce进程
一个完整的MapReduce程序在分布式运算时有三类实例进程:
1.MrAPPMaster:负责整个程序的过程调度以及状态协调。
2.MapTask:负责Map阶段的整个数据处理流程。
3.ReduceTask:负责Reduce阶段的整个数据处理流程。
1.4常用数据序列化类型
常用的数据类型对应的Hadoop数据序列化类型
| Java的数据类型 | Hadoop Writable类型 |
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
1.5MapReduce编程规范
1.Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输出数据是kv对的形式(kv的类型是自定义)
(3)Mapper中业务逻辑写在map()方法中
(4)Mapper的输出数据是kv对的形式(kv的类型可自定义)
(5)map()方法(MapTask进程)对每一个<k,v>调用一次
2.Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应的是Mapper的输出数据类型,也是kv
(3)Reducer的业务逻辑写在reduce()方法中
(4)Reduce Task进程对每一组相同的k的<k,v>组调用一次reduce()方法
3.Drive阶段
相当于YARN集群的客户端,用于提交我们整个程序到yarn集群,提交的是封装了MapReduce程序相关运行参数的job对象。
1.6WordCount案例操作
1.需求
给定文本文件,统计文本文件中单词的个数,输出每个单词出现的总次数
(1)输入数据
I am somebody
I am smart and kind
I am important
I am starve of education
I have places to go
I have people to impress
I have world to change(2)输出数据
2.需求分析
Mapper部分
key代表偏移量,v1这一行的内容,Text
输入<0,I am somebody>,k1=0,v1=“I am somebody”
<14,I am smart and kind>,k1=14,v1=“I am smart and kind”
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | ||||||
| I | a | m | s | o | m | e | b | o | d | y | 换行符 |
3.1将MapTask传给我们的文本内容先转换成String
3.2根据空格将这一行切分成单词
3.3将单词输出为<单词,1>,k2=“1”v2=1 k2的类型是Text,v2是1类型IntWritable
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable Key1,Text value1,Context context) throws IOException, InterruptedException {
//context表示Mapper的上下文 上文:HDFS 下文:Mapper
//1.将数据转成String类型
String data=value1.toString();
//2.分词
String[] words=data.split(" ");
for (String word:words){
//输出key2,value2
context.write(new Text(word),new IntWritable(1));
}
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
Text key2=new Text();
IntWritable value2=new IntWritable(1);
@Override
protected void map(LongWritable Key1,Text value1,Context context) throws IOException, InterruptedException {
//context表示Mapper的上下文 上文:HDFS 下文:Mapper
//1.将数据转成String类型
String data=value1.toString();
//2.分词
String[] words=data.split(" ");
for (String word:words){
//输出key2,value2
key2.set(word);
context.write(key2,value2);
}
}
}
<k2,v2>如下:
<I,1>
<am,1>
<somebody, 1>
<I,1>
<k3.v3>如下:
<I,(1, 1)>
<am,1>
<somebody, 1>
v3是v2的集合
<k4,v4>如下:
<I,2>
<am,1>
<somebody, 1>
Reducer阶段:
输入:<k3.v3>,v3是v2同一个key的集合
<I,(1, 1)>
<am,1>
<somebody, 1>
输出:
<I,2>
<am,1>
<somebody, 1>
1.汇总各个key的个数(把k3对应的v3,集合数字加起来)
2.输出k4,v4
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.yarn.webapp.hamlet2.Hamlet;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text,IntWritable> {
int sum;
IntWritable value4 = new IntWritable();
@Override
protected void reduce(Text key3, Iterable<IntWritable> values3, Context context) throws IOException, InterruptedException {
//1.累加求和
sum=0;
for (IntWritable v3:values3){
sum += v3.get();
}
//2.输出
value4.set(sum);
context.write(key3,value4);
}
}
Driver类
1.获取配置信息,获取job对象实例
2.指定本程序的jar包所在的本地路径
3.关联Mapper,Reducer业务类
4.指定Mapper输出的kv类型
5.指定最终输出的数据的kv类型
6.指定job的输入输出文件路径
7.提交作业
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2.设置jar加载路径(就是他这个类生成的class文件)
job.setJarByClass(WordCountDriver.class);
//3.设置Mapper和Reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4.设置map输出的key和value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IOException.class);
//5.设置最终输出key和value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("/root/IdeaProjects/mapReduceDemo/migu.txt"));
FileOutputFormat.setOutputPath(job,new Path("/root/IdeaProjects/mapReduceDemo/WordCountOutPut"));
//7.提交
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









