







原创文章,首发自作者个人博客,转载请务必将下面这段话置于文章开头处。
本文转发自技术世界,原文链接 http://www.jasongj.com/zookeeper/fastleaderelection/
1 Zookeeper是什么
Zookeeper是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等。
这一切的基础,都是Zookeeper提供了一个类似于Linux文件系统的树形结构(可认为是轻量级的内存文件系统,但只适合存少量信息,完全不适合存储大量文件或者大文件),同时提供了对于每个节点的监控与通知机制。
既然是一个文件系统,就不得不提Zookeeper是如何保证数据的一致性的。本文将介绍Zookeeper如何保证数据一致性,如何进行领导选举,以及数据监控/通知机制的语义保证。
2 Zookeeper架构
2.1 角色
Zookeeper集群是一个基于主从复制的高可用集群,每个服务器承担如下三种角色中的一种
- Leader 一个Zookeeper集群同一时间只会有一个实际工作的Leader,它会发起并维护与各Follwer及Observer间的心跳。所有的写操作必须要通过Leader完成再由Leader将写操作广播给其它服务器。
- Follower 一个Zookeeper集群可能同时存在多个Follower,它会响应Leader的心跳。Follower可直接处理并返回客户端的读请求,同时会将写请求转发给Leader处理,并且负责在Leader处理写请求时对请求进行投票。
- Observer 角色与Follower类似,但是无投票权。
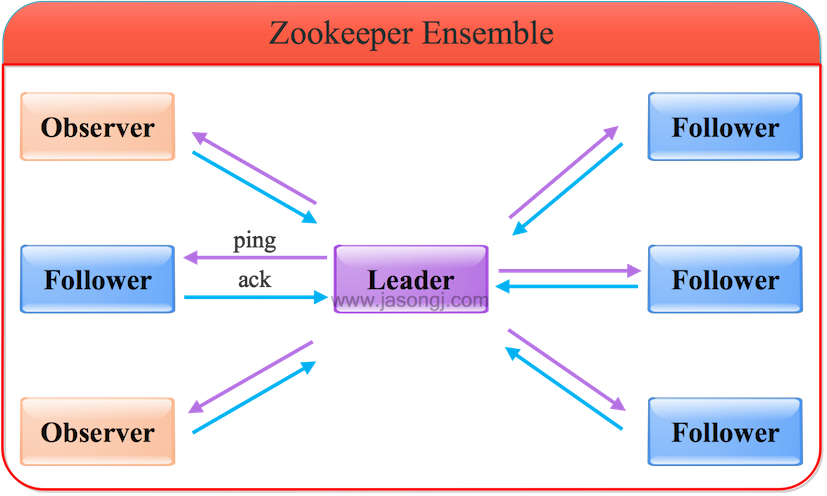
2.2 原子广播(ZAB)
为了保证写操作的一致性与可用性,Zookeeper专门设计了一种名为原子广播(ZAB)的支持崩溃恢复的一致性协议。基于该协议,Zookeeper实现了一种主从模式的系统架构来保持集群中各个副本之间的数据一致性。
根据ZAB协议,所有的写操作都必须通过Leader完成,Leader写入本地日志后再复制到所有的Follower节点。
一旦Leader节点无法工作,ZAB协议能够自动从Follower节点中重新选出一个合适的替代者,即新的Leader,该过程即为领导选举。该领导选举过程,是ZAB协议中最为重要和复杂的过程。
2.3 写操作
2.3.1 写Leader
通过Leader进行写操作流程如下图所示
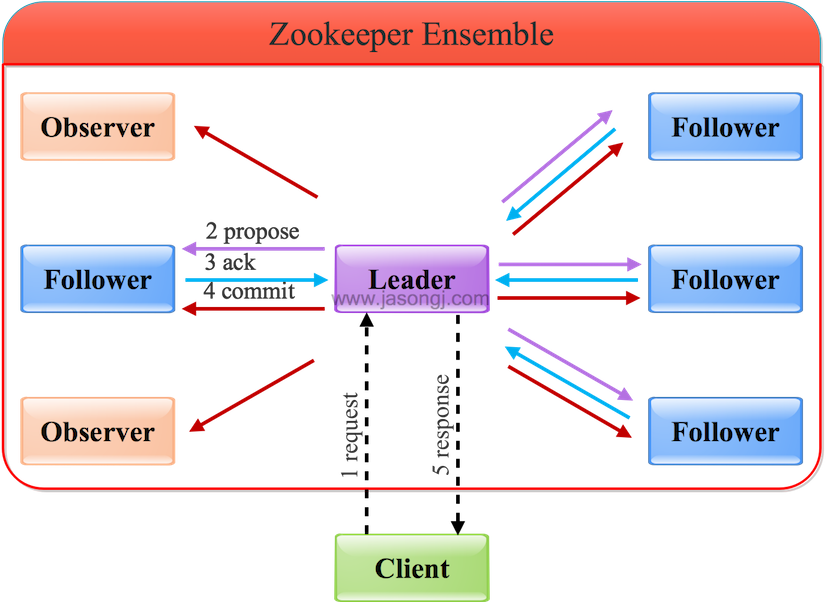
由上图可见,通过Leader进行写操作,主要分为五步:
1. 客户端向Leader发起写请求
2. Leader将写请求以Proposal的形式发给所有Follower并等待ACK
3. Follower收到Leader的Proposal后返回ACK
4. Leader得到过半数的ACK(Leader对自己默认有一个ACK)后向所有的Follower和Observer发送Commmit
5. Leader将处理结果返回给客户端
这里要注意
- Leader并不需要得到Observer的ACK,即Observer无投票权
- Leader不需要得到所有Follower的ACK,只要收到过半的ACK即可,同时Leader本身对自己有一个ACK。上图中有4个Follower,只需其中两个返回ACK即可,因为(2+1) / (4+1) > 1/2
- Observer虽然无投票权,但仍须同步Leader的数据从而在处理读请求时可以返回尽可能新的数据
2.3.2 写Follower/Observer
通过Follower/Observer进行写操作流程如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2311
2311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









