







一、校验和
检验和,在数据处理和数据通信领域中,用于校验目的地一组数据项的和。它通常是以十六进制为数制表示的形式。如果校验和的数值超过十六进制的FF,也就是255. 就要求其补码作为校验和。通常用来在通信中,尤其是远距离通信中保证数据的完整性和准确性。
这些数据项可以是数字或在计算检验的过程中看作数字的其它字符串。校验和(checksum)是指传输位数的累加,当传输结束时,接收者可以根据这个数值判断是否接到了所有的数据。如果数值匹配,那么说明传送已经完成。TCP和UDP传输层都提供了一个校验和与验证总数是否匹配的服务功能。
二、文件结构
hadoop提供了一种顺序文件类型即SequnceFile,里面存放的其实是键值对数据类型,但这里的键值对都可用二进制数据来表示,因此SequenceFile对于处理二进制数据非常合适。
SequenceFile同样也可以作为小文件的容器,即key保存文件名,value存储文件内容,这样可以把许多小文件合并到一个大文件中,尤其适合hadoop处理大文件。
同样提供了MapFile,其实就是已经排序的SequenceFile,并且加入用于搜索键的索引。可以将MapFile视为java.util.Map的持久化形式。MapFile在保存到磁盘上后,会有两个文件,一个数据原数据文件,另一个是index索引文件。
1、SequnceFile
SequenceFile的存储类似于Log文件,所不同的是Log File的每条记录的是纯文本数据,而SequenceFile的每条记录是可序列化的字符数组。
SequenceFile可通过如下API来完成新记录的添加操作:
fileWriter.append(key,value)
可以看到,每条记录以键值对的方式进行组织,但前提是Key和Value需具备序列化和反序列化的功能
Hadoop预定义了一些Key Class和Value Class,他们直接或间接实现了Writable接口,满足了该功能,包括:
Text 等同于Java中的String
IntWritable 等同于Java中的Int
BooleanWritable 等同于Java中的Boolean
.
.
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如图所示:
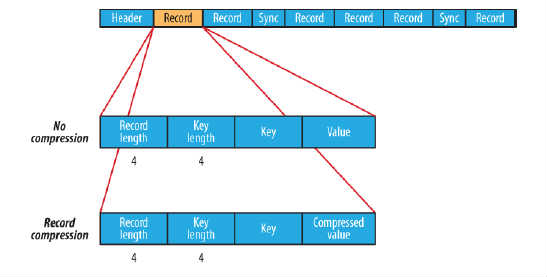
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
block compression是将一连串的record组织到一起,统一压缩成一个block,如图所示:
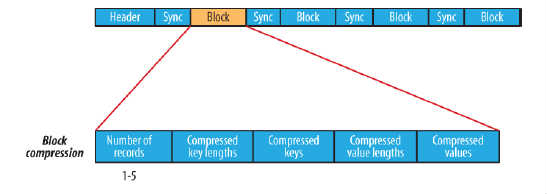
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
2、MapFile
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
三、Hadoop数据类型
- BooleanWritable:标准布尔型数值
- ByteWritable:单字节数值
- DoubleWritable:双字节数值
- FloatWritable:浮点数
- IntWritable:整型数
- LongWritable:长整型数
- Text:使用UTF8格式存储的文本
- NullWritable:当<key, value>中的key或value为空时使用
四、压缩和解压缩
我们可以把数据文件压缩后再存入HDFS,以节省存储空间。但是,在使用MapReduce处理压缩文件时,必须考虑压缩文件的可分割性。目前,Hadoop支持以下几种压缩格式
| 压缩格式 | UNIX工具 | 算 法 | 文件扩展名 | 支持多文件 | 可分割 |
| DEFLATE | 无 | DEFLATE | .deflate | No | No |
| gzip | gzip | DEFLATE | .gz | No | No |
| zip | zip | DEFLATE | .zip | YES | YES |
| bzip | bzip2 | bzip2 | .bz2 | No | YES |
| LZO | lzop | LZO | .lzo | No | No |
| 压缩格式 | 对应的编码/解码器 |
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip | org.apache.hadoop.io.compress.BZipCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |















 1985
1985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









