







 本文深入探讨MapReduce的工作原理,从客户端提交作业到JobTracker协调,再到TaskTracker处理任务,详细解析作业处理流程,包括输入分片、map、combiner、shuffle和reduce阶段。MapReduce在Hadoop中并行处理输入数据块,框架负责任务调度和监控,确保作业顺利完成。
本文深入探讨MapReduce的工作原理,从客户端提交作业到JobTracker协调,再到TaskTracker处理任务,详细解析作业处理流程,包括输入分片、map、combiner、shuffle和reduce阶段。MapReduce在Hadoop中并行处理输入数据块,框架负责任务调度和监控,确保作业顺利完成。
一、MapReduce工作原理
作业执行涉及4个独立的实体
1、客户端,用来提交MapReduce作业
2、JobTracker,用来协调作业的运行
3、TaskTracker,用来处理作业划分后的任务
4、HDFS,用来在其它实体间共享作业文件
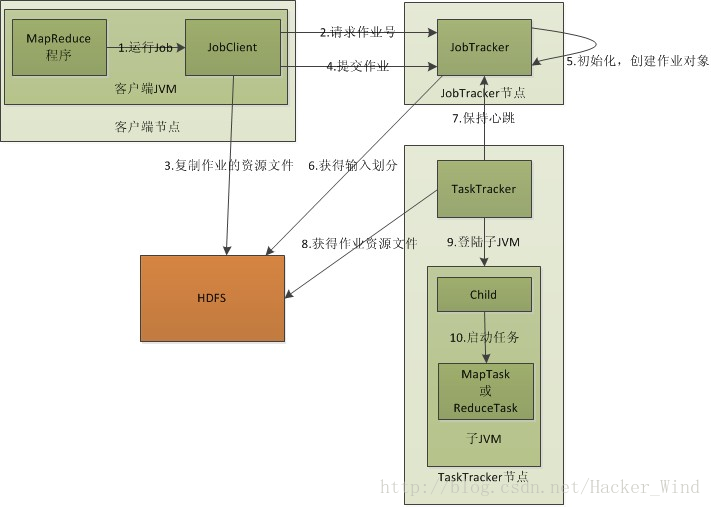
首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,
接下来就是提交job了,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值
接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,至于输入分片我后面会做讲解的,这些都做好了JobTracker就会配置Job需要的资源了。
分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









